【THM】Google Dorking(利用谷歌搜索发现敏感信息)-学习
 解释搜索引擎大概是如何工作的,并利用谷歌搜索引擎来查找一些隐藏的敏感内容。
解释搜索引擎大概是如何工作的,并利用谷歌搜索引擎来查找一些隐藏的敏感内容。
本文相关的TryHackMe实验房间链接:https://tryhackme.com/room/googledorking
本文介绍:解释搜索引擎大概是如何工作的,并利用谷歌搜索引擎来查找一些隐藏的敏感内容。

搜索引擎简介
谷歌搜索引擎可以说是“搜索引擎”中最著名的一个,我们可以把像谷歌这样的“搜索引擎”理解为一个巨大的索引器——具体来说,它是一个遍布万维网的内容索引器。
搜索引擎是上网必备品,它们实际上是使用“Crawlers-爬虫”或者“Spiders-蜘蛛”在万维网上搜索具体内容的。
Crawlers(爬虫)的基本原理
爬虫(Crawlers)如何工作?
网络爬虫能够通过各种方式发现网站内容:一种方式是通过纯粹的发现找到内容--爬虫访问 URL,并将有关网站内容类型的信息返回给搜索引擎,事实上,现代爬虫抓取了很多信息,我们稍后会讨论如何使用这些信息;另一种方式是跟踪所有从以前爬取过的网站中找到的 URL,就像病毒的传播模式一样,网络爬虫会遍历到它可以遍历的一切地方。
理解爬虫工作原理
下图是对这些网络爬虫(Crawlers)如何工作的高级抽象,一旦网络爬虫(Crawlers)发现了诸如 mywebsite.com 之类的域,它将索引(index)该域的全部内容,寻找关键字和其他杂项信息——我们稍后会讨论这些杂项信息。
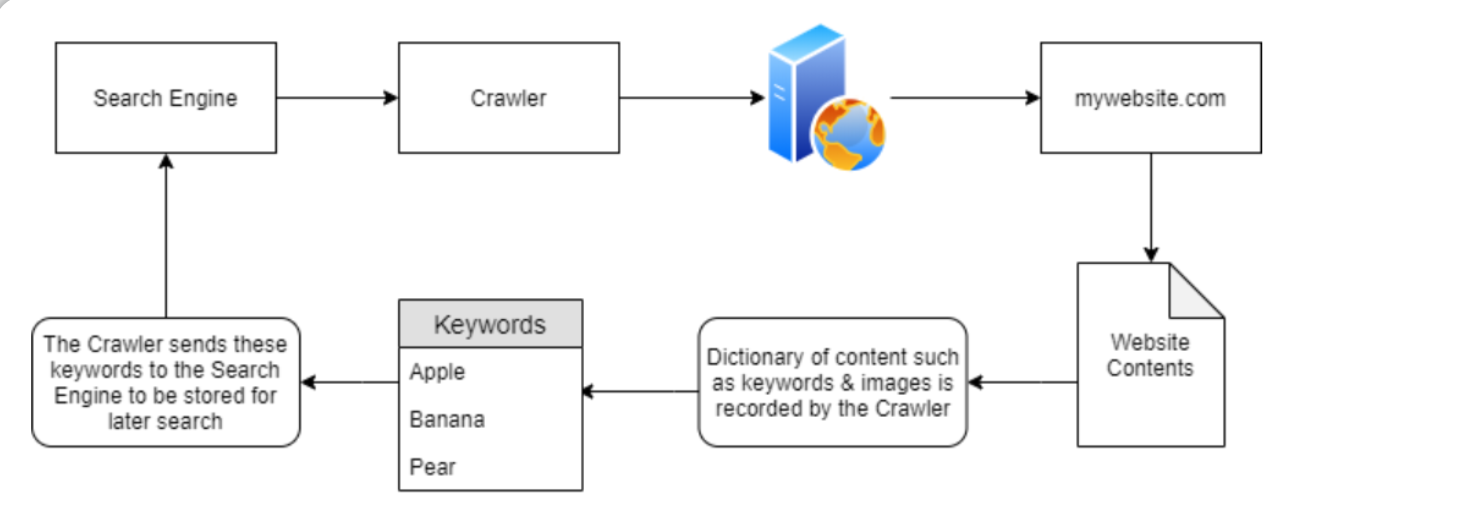
在上图中,“mywebsite.com”已被网络爬虫抓取了关键字“Apple”、“Banana”和“Pear”;这些关键字会由爬虫存储在字典中,然后爬虫再将这些关键字返回给搜索引擎,比如Google搜索引擎;由于上述过程具有持续性,谷歌就能够知道“mywebsite.com”域有一些关键字“Apple”、“Banana”和“Pear”。
如果上述爬虫只抓取了“mywebsite.com”这一个网站,那么只要用户一搜索“Apple”关键字则能够很快检索到“mywebsite.com”域;同样,如果用户选择搜索“Banana”关键字,也将导致“mywebsite.com”域被检索到;这是因为当用户使用搜索引擎输入关键字之后,网络爬虫的索引内容会报告目标域具有关键字,因此目标域(在此处为mywebsite.com)将作为搜索引擎找到的结果返回给用户。
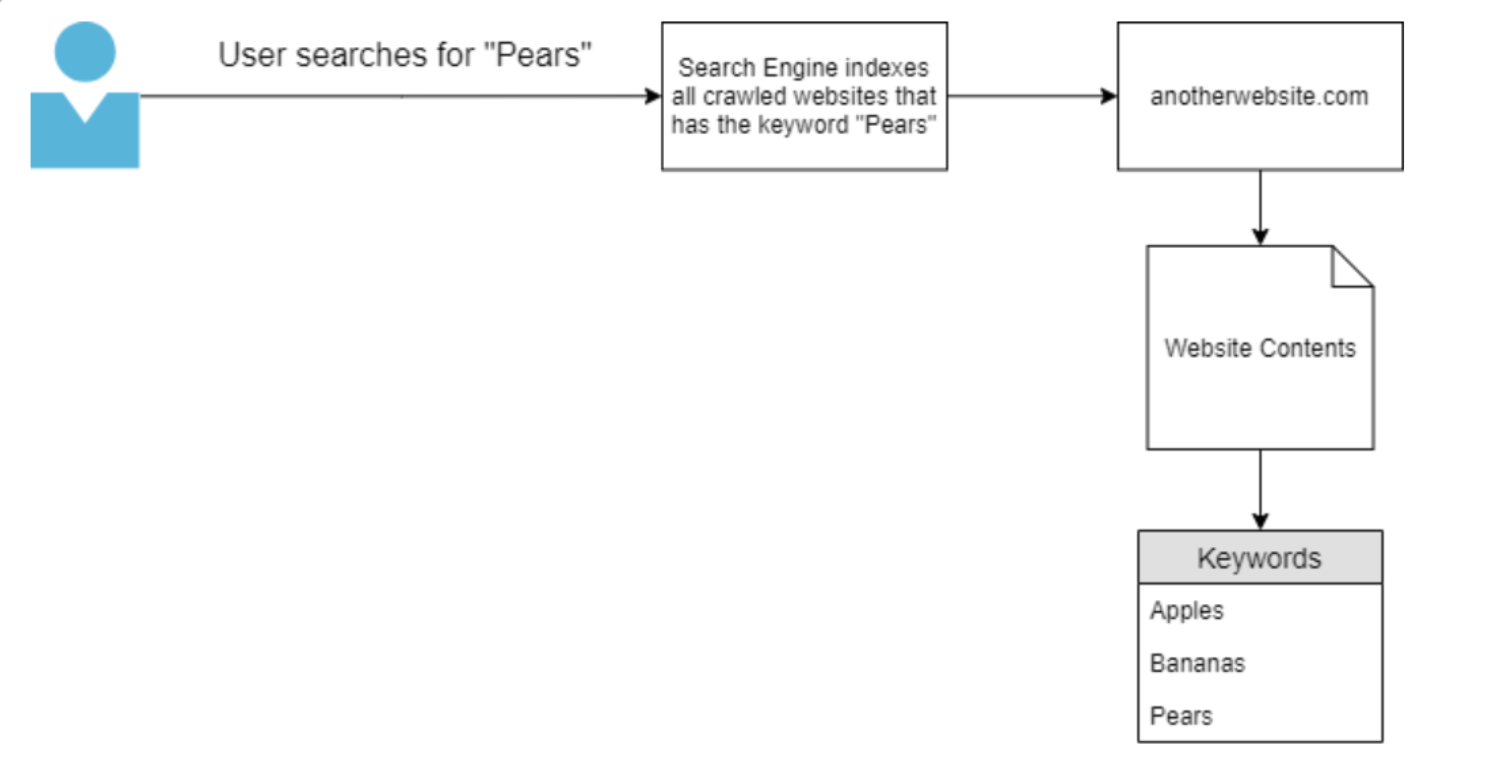
如下图所示,用户向搜索引擎提交并查询关键字“Pears”,因为搜索引擎只找到一个网站的内容是以“Pears”为关键词被抓取的,所以它(在本例中是下图中的 anotherwebsite.com)会是唯一呈现给用户的域 。
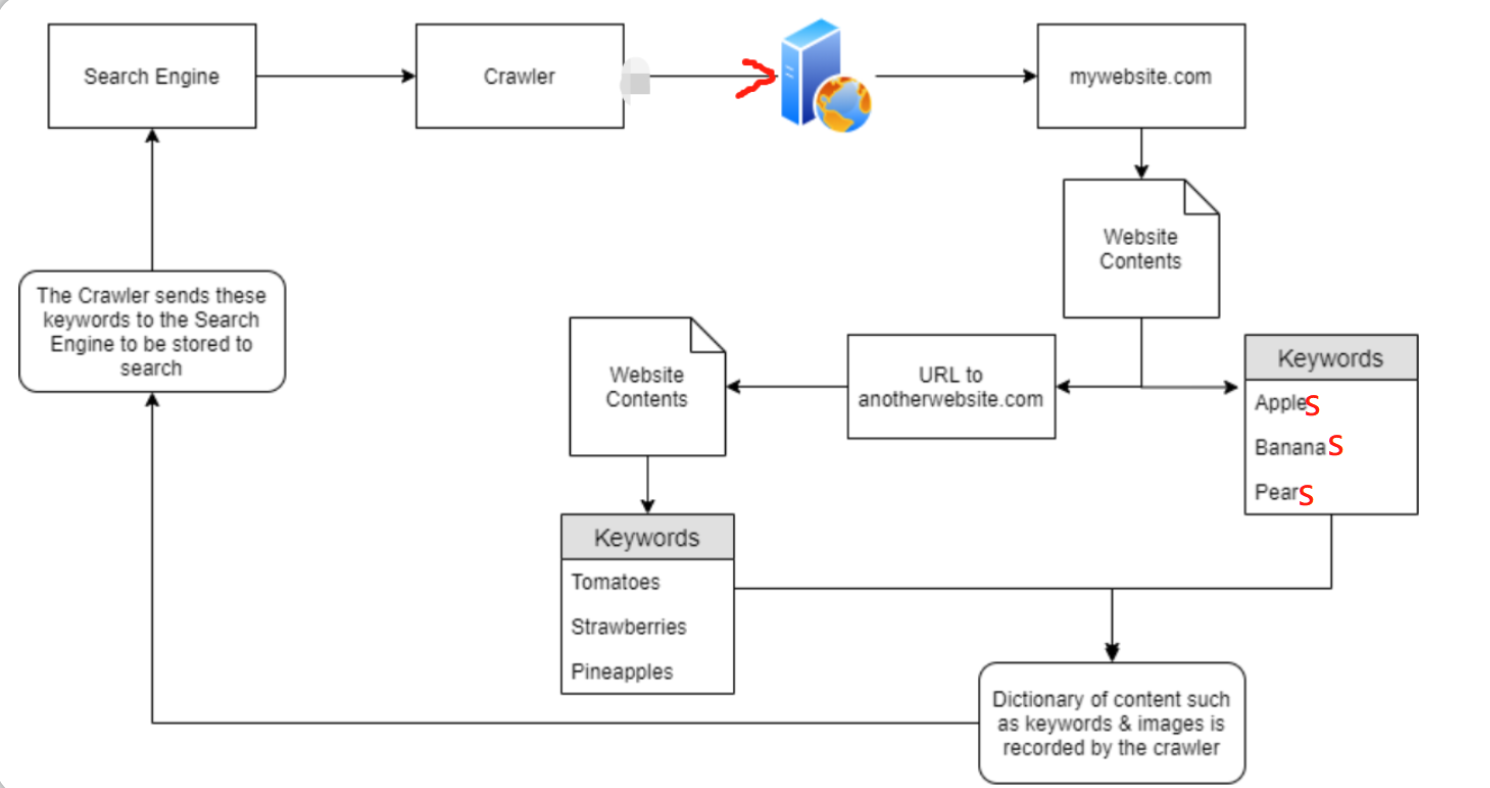
正如我们之前所提到的,爬虫会试图遍历(也被称为爬行-crawling)它们可以找到的每个 URL 和文件,假设“mywebsite.com”的关键字是Apples、Bananas以及Pears,但是现在“mywebsite.com”的网站内容中还有一个指向其他网站(anotherwebsite.com)的URL,那么当爬虫爬取到“mywebsite.com”之后,就能够发现此网站内容中的URL,然后爬虫就会尝试遍历这个URL(anotherwebsite.com)中的所有内容。(最终结果是爬虫会尝试遍历前述两个域中的所有内容)
下图对此种情况进行了说明:爬虫最初找到了“mywebsite.com”,它在那里爬取了网站的内容 - 找到关键字(“Apples”、“Bananas”和“Pears”),同时它还找到了一个外部 URL(指向);由于爬虫发现了目标网站中还包含一个外部URL,所以在“mywebsite.com”上完成爬取之后,爬虫将继续爬取那个外部URL所指向的网站内容,即“anotherwebsite.com”站点,然后就能爬取到以下关键字-“Tomatoes”、“Strawberries”和“Pineapples”;最后在爬虫所形成的字典中将包含“mywebsite.com”和“anotherwebsite.com”两个域的内容,这些内容最终将存储并保存在搜索引擎中。
进一步理解
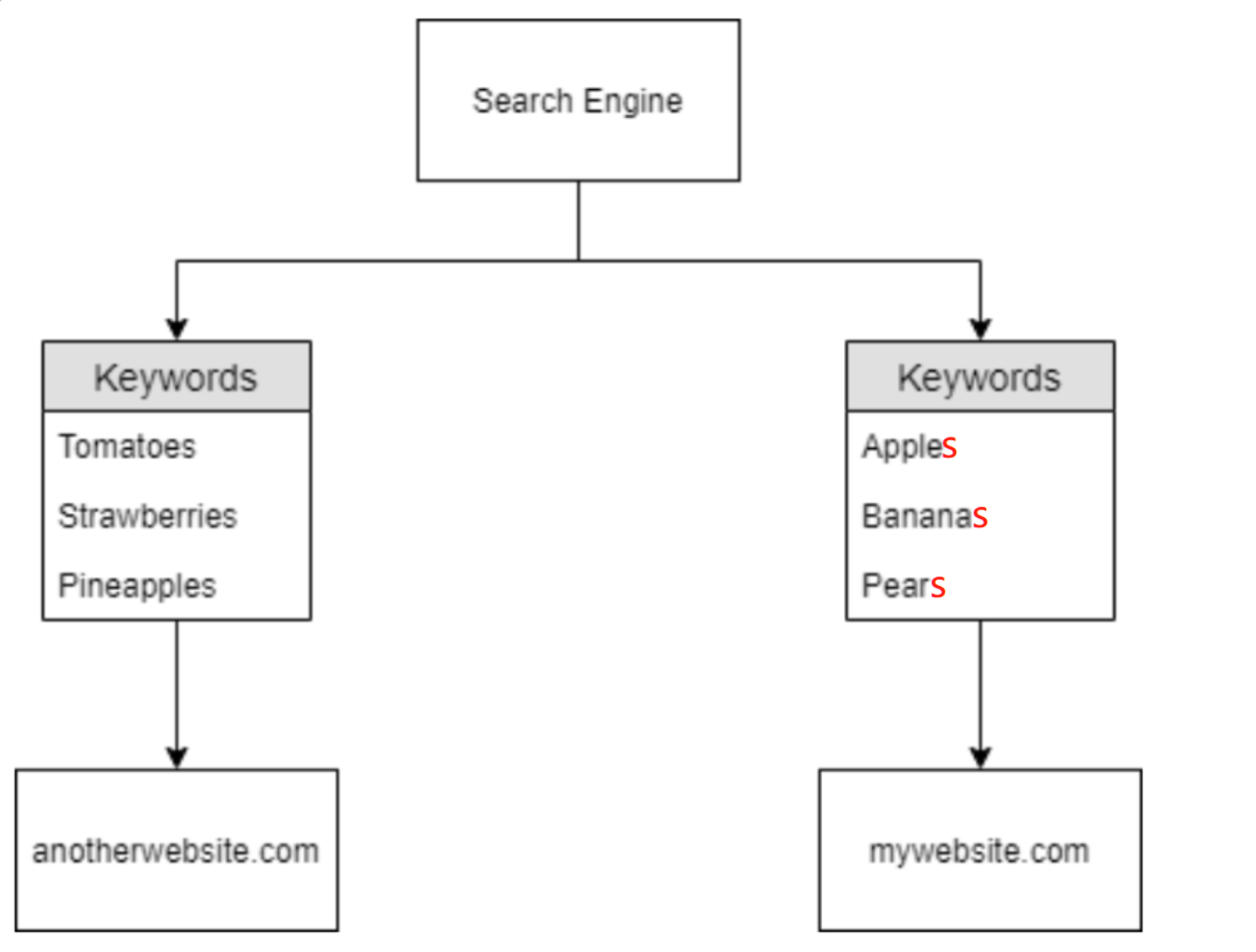
现在回顾一下,搜索引擎已经知道了两个已被抓取的域:
- mywebsite.com
- anotherwebsite.com
其中“anotherwebsite.com”是因为被第一个域“mywebsite.com”引用而被爬虫抓取,由于此引用,搜索引擎最终能够了解到有关这两个域的以下信息:
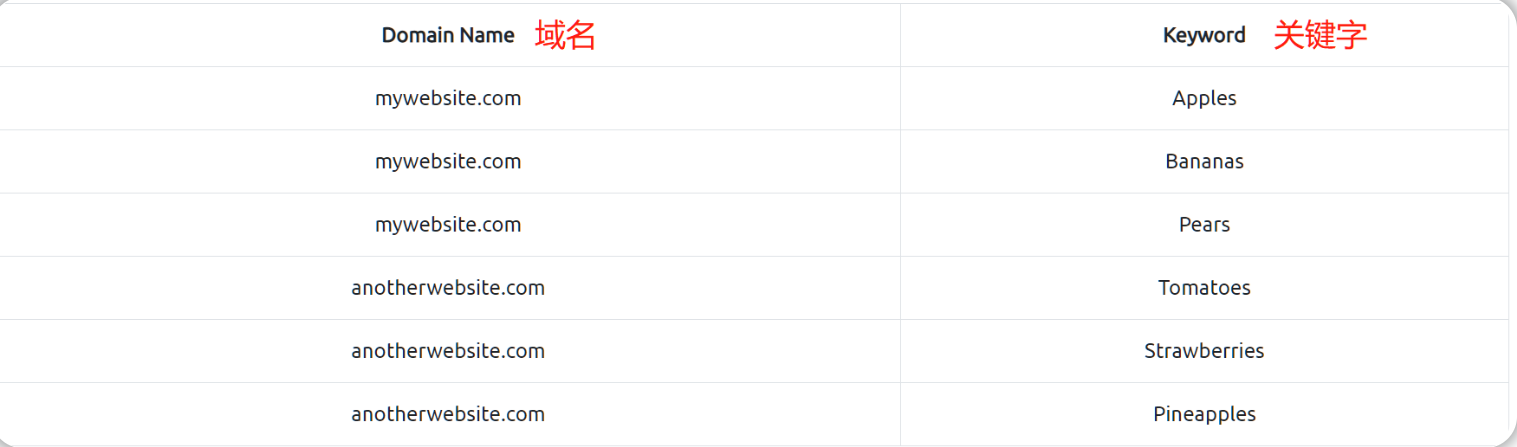
或者如下图所示:
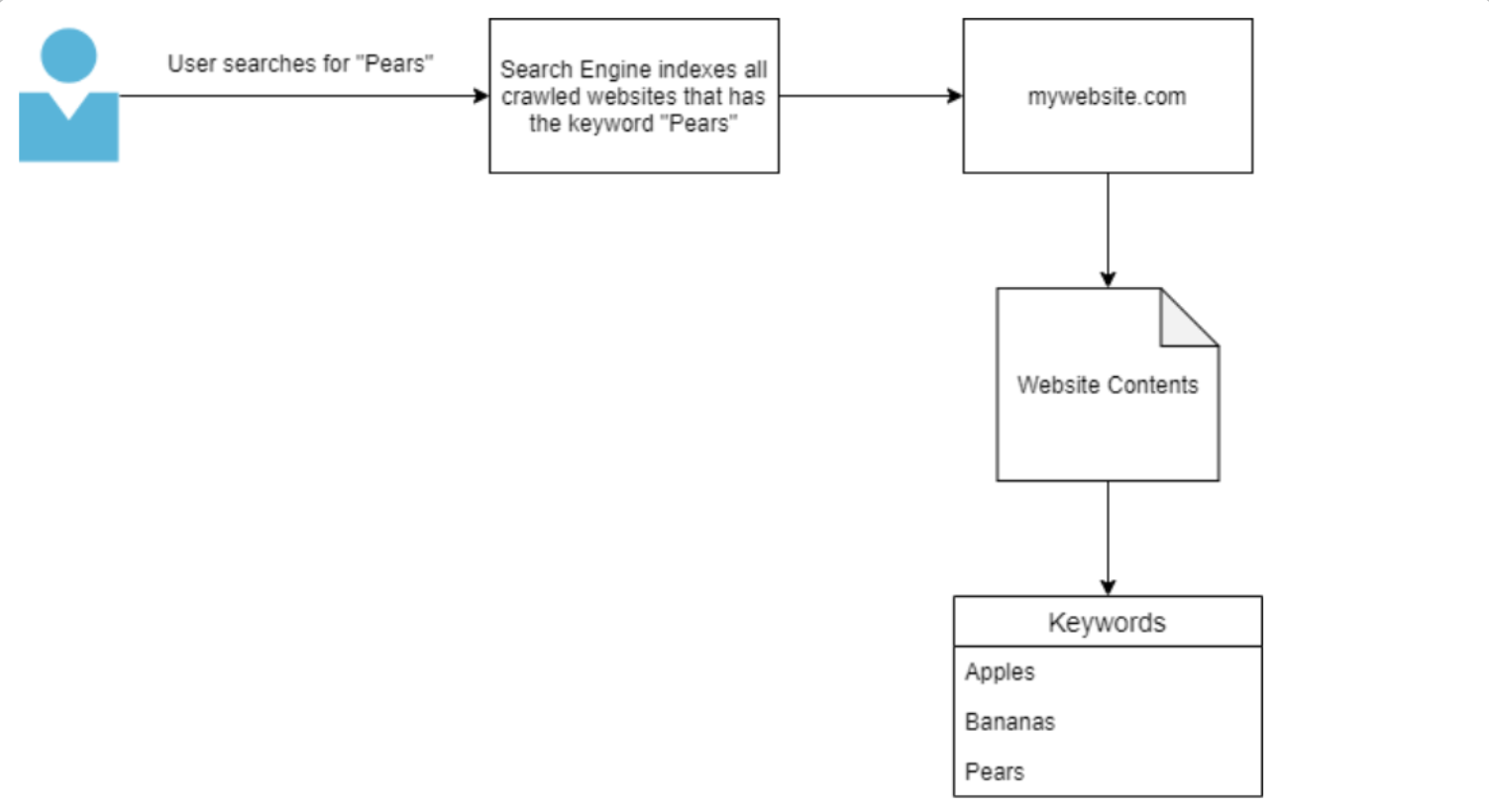
现在搜索引擎对关键字有了一些了解,假设用户此时搜索“Pears”,那么搜索结果将显示“mywebsite.com”域——因为它是唯一包含“Pears”的被爬取域:
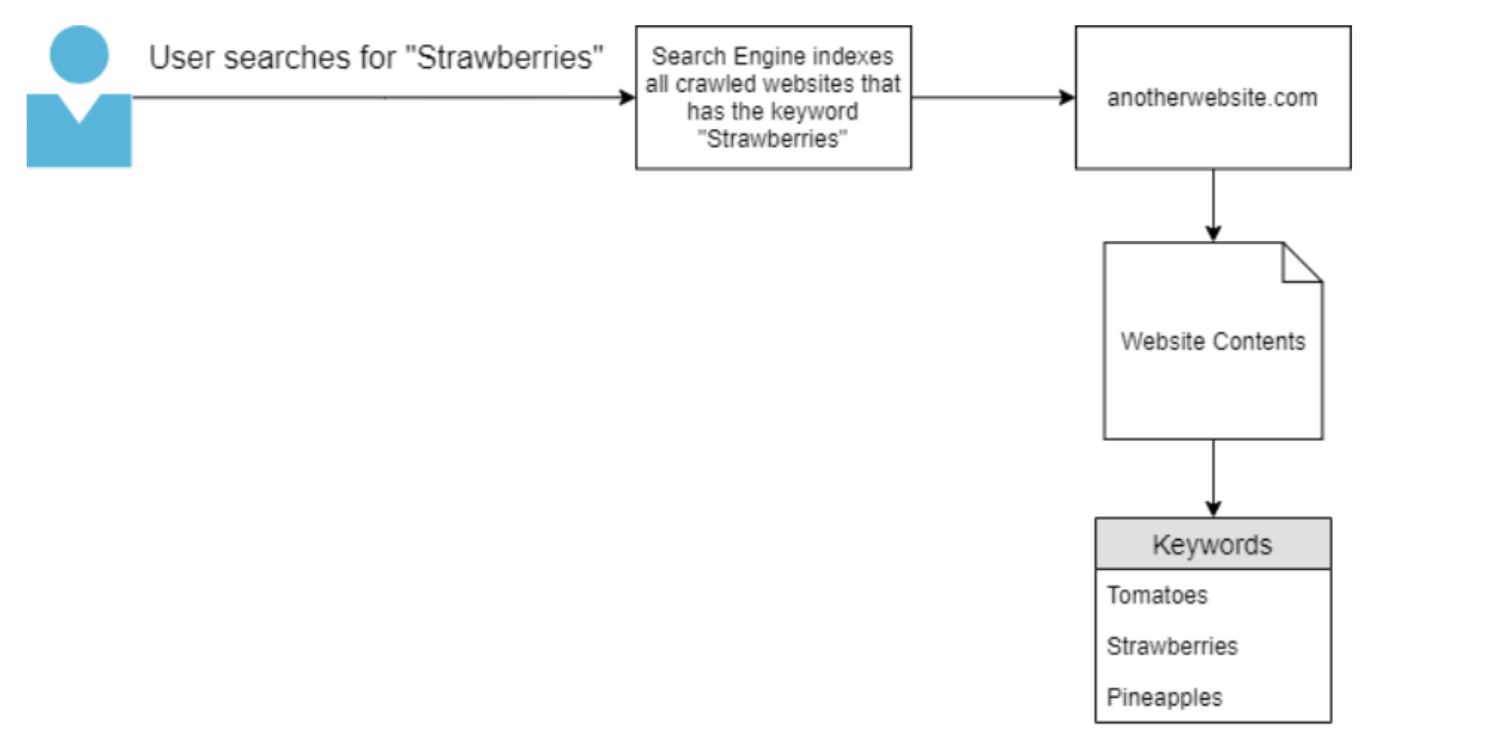
同样,假设用户现在搜索“Strawberries”,则搜索结果将显示“anotherwebsite.com”域,因为它是搜索引擎抓取的唯一包含关键字“Strawberries”的域:
但是在实际网络环境下,情况有时候会更复杂,因为如果一个网站有多个外部 URL(网站开发者经常这样做),那么爬虫就需要进行大量的爬行操作,而且爬虫所爬取的一个网站也有可能拥有一些与其他被抓取网站相似的信息 - 那么“搜索引擎”如何决定向用户显示的域的层次结构呢?我们可参考下图结构:
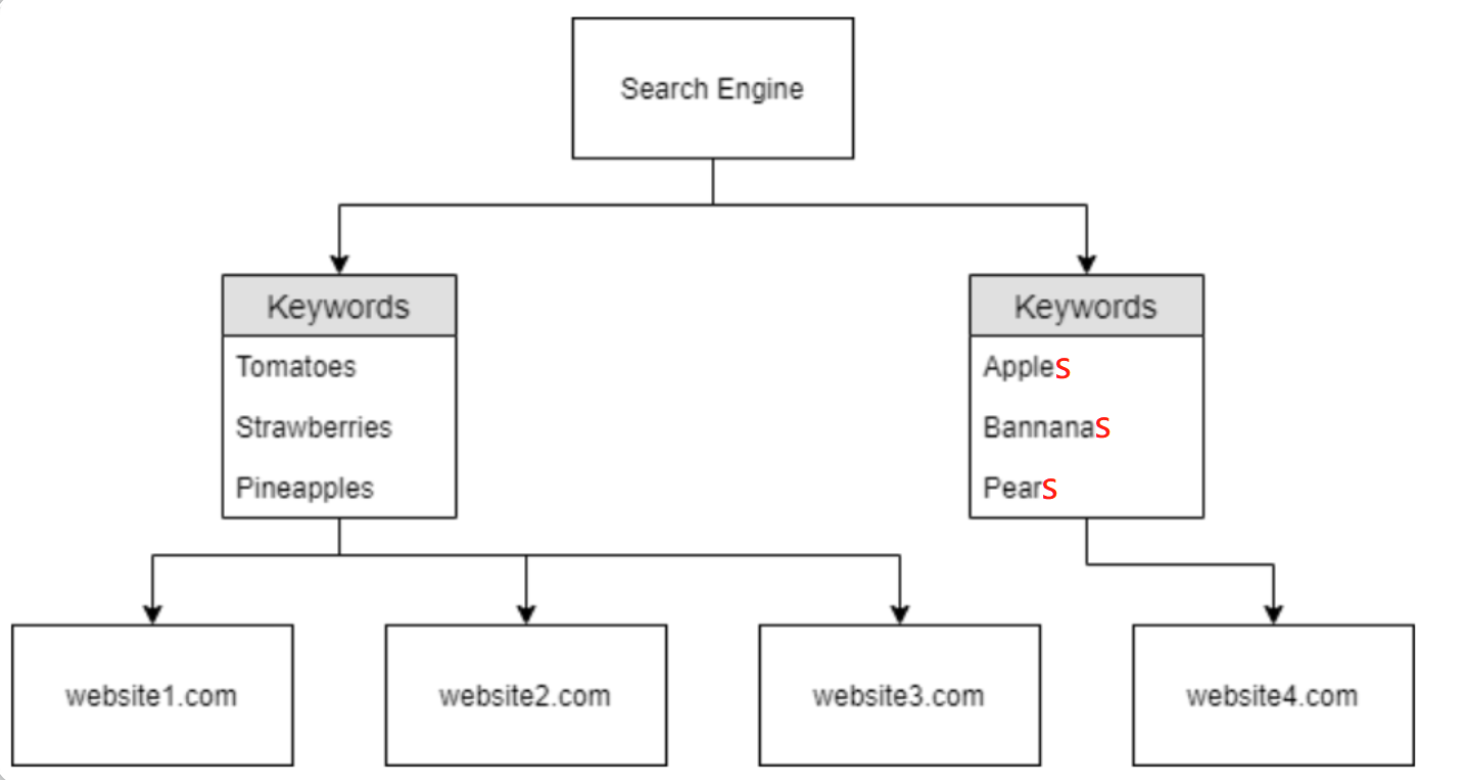
一个合乎逻辑的假设是:当用户搜索一些共同关键字(如上图中的Tomatoes)时--上述website1、website2、website3 都将显示在搜索结果中(此处案例仅方便理解,并不代表现实世界中域的工作、命名方式)
答题
问题:关于“爬虫”的用途的关键术语是?
索引(index)
问题:“搜索引擎”用来检索网站有关信息的技术是什么?
爬行(crawling)或者遍历
问题:可以从网站收集的内容类型是什么?请举一例。
关键字(keywords)
回答:
SEO(搜索引擎优化)原理
SEO简介
搜索引擎优化即 SEO(Search Engine Optimisation)是现代搜索引擎中一个普遍且有利可图的话题,事实上,有很多企业都在通过提高 域的SEO“排名” 获利。从抽象的角度来看,搜索引擎将“优先考虑”那些更容易索引的域,而一个域的“最佳”程度受很多因素影响 - 从而产生了用于评估域的类似于评分系统的东西。
有一些因素能够影响搜索引擎对域的“评分”,例如:
- 你的网站对不同类型浏览器的响应情况,如以下浏览器:Google Chrome、Firefox 和 Internet Explorer - 也包括手机端的这些浏览器。
- 通过使用“站点地图-Sitemaps”来抓取你的网站是否很容易(或者是否允许通过使用站点地图来抓取某些内容)?
- 你的网站中有什么关键字?(示例:假设用户搜索“Colours”关键字,结果却没有返回任何域 - 说明此时的搜索引擎尚未抓取具有“Colours”关键字的域 )
各种搜索引擎如何单独对域“评分”或对这些域进行排名——这包括大量算法同时也非常复杂,自然地,运行这些搜索引擎的公司(例如 Google)并不会确切地分享关于搜索引擎中的域的分层视图是如何形成的;但是你可以选择付费宣传你的网站 或者 付费提高你的域在搜索引擎的查询结果中的显示顺序。
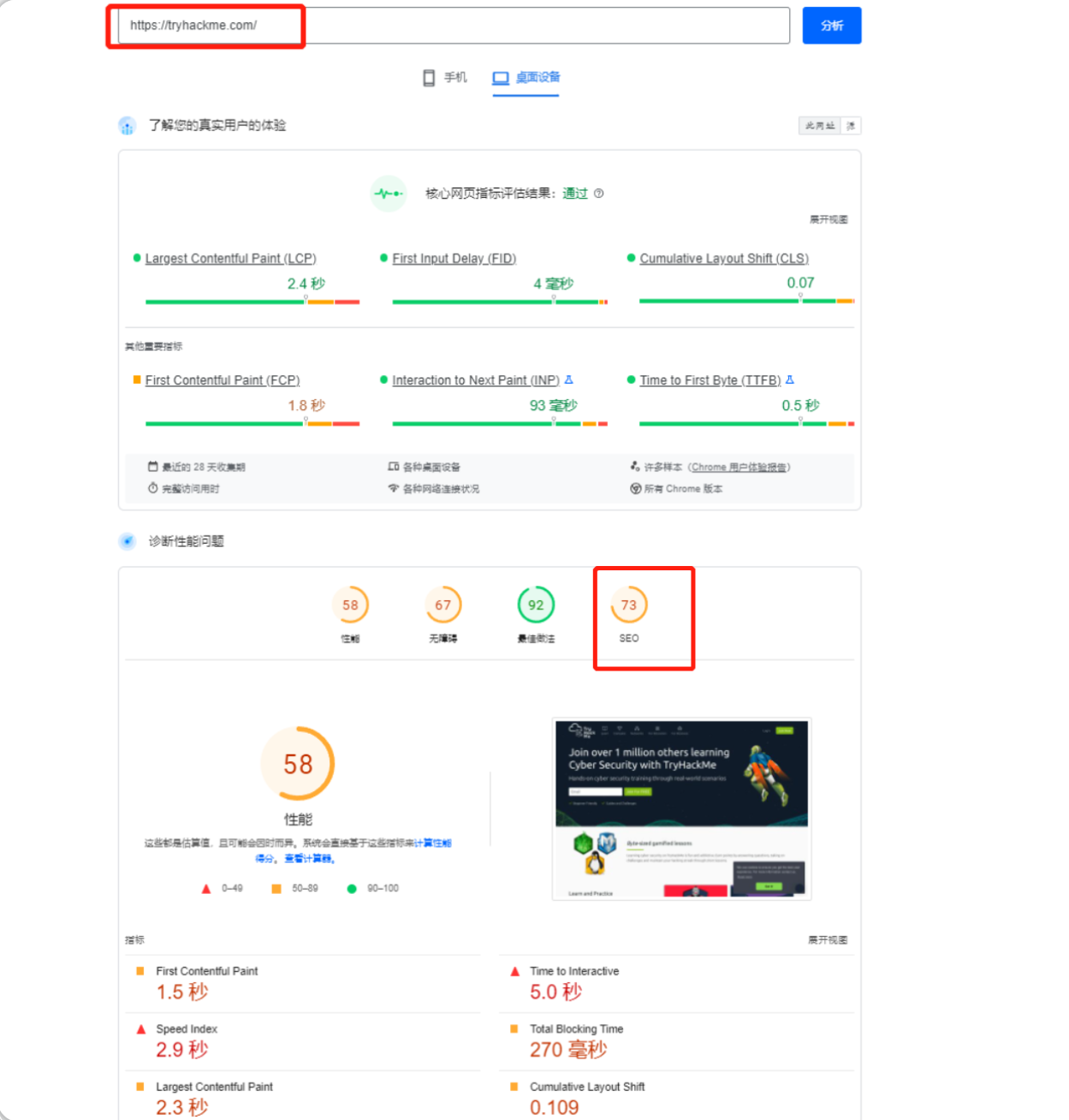
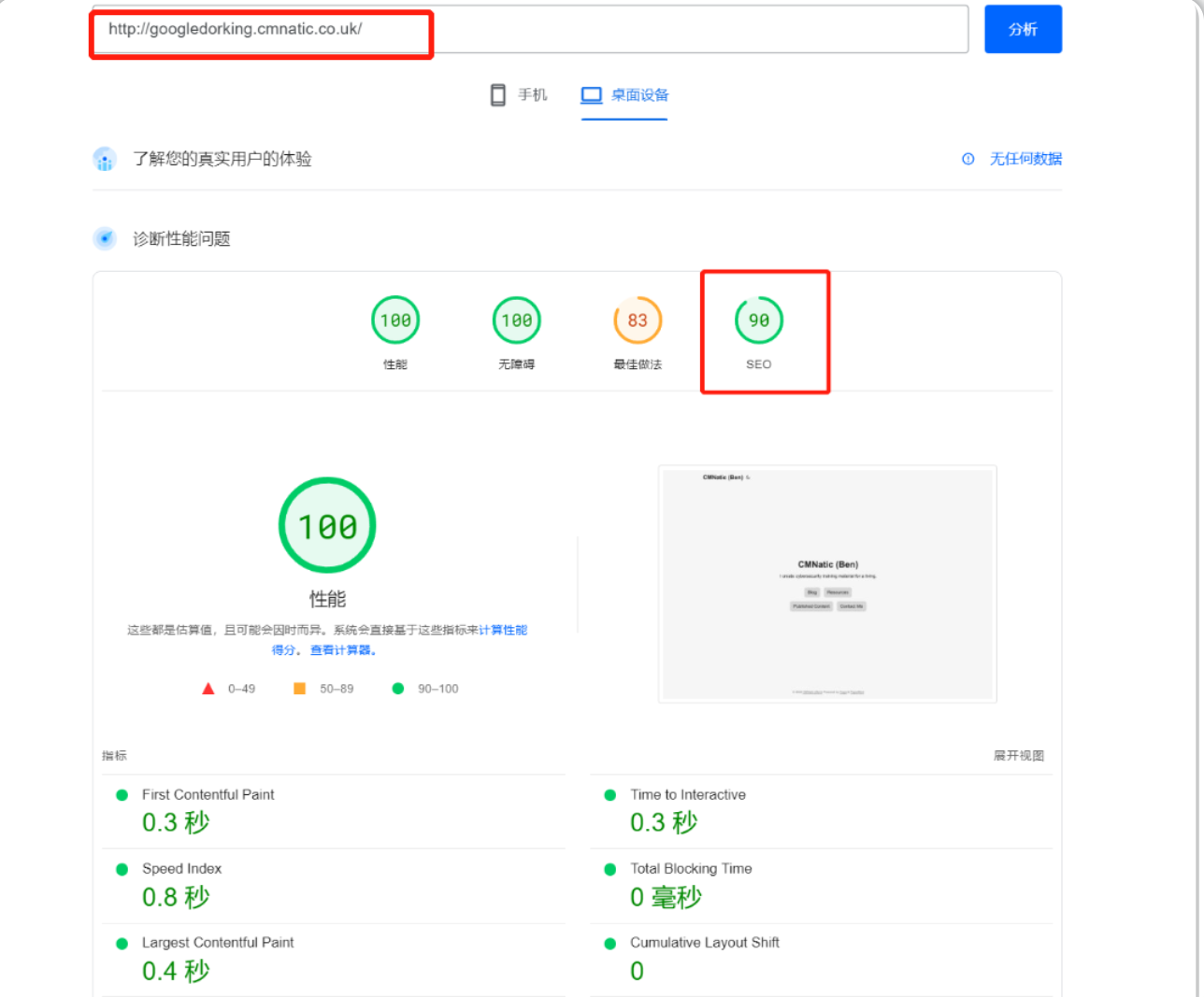
有多种在线工具(有时由搜索引擎提供商自己提供) 可以向你展示域的优化程度,例如,我们可以使用以下站点分析器来检查某个网站的评级:
但是由谁来监管这些搜索引擎所使用的“爬虫”呢?
除了提供这些“爬虫”的搜索引擎之外,网站/网络服务器所有者自己也可以规定“爬虫”能够被允许抓取哪些内容;搜索引擎当然是希望 能够从目标网站中检索所有内容,但是在某些情况下,我们也可能不希望自己的网站的所有内容都被爬虫所索引,比如网站的管理员登录页面,我们不希望每个人都能找到该目录——尤其是通过谷歌搜索。
所以下一小节我们将介绍Robots.txt文件。
答题
使用相同的SEO检查工具-https://pagespeed.web.dev/ 或者其他在线替代工具来比较 https://tryhackme.com/ 和http://googledorking.cmnatic.co.uk/
SEO检查的结果如下:

Robots.txt文件介绍
Robots.txt简介
概念介绍
robots.txt文件是“爬虫”访问网站时首先索引的内容,这与我们稍后将讨论的“站点地图-Sitemaps”类似。
Robots.txt是什么?
robots.txt文件必须在网站根目录下提供——由web服务器本身指定;根据 .txt 这个文件扩展名,我们可以想到它是一个文本文件。
该文本文件定义了“爬虫”对网站的爬取权限,例如,允许哪种类型的“爬虫”爬取(即 你可能只希望 Google的爬虫为你的站点编制索引,而不是 MSN的爬虫),此外,robots.txt 还可以指定我们希望或者不希望被“爬虫”索引的某些文件和目录。
关于robots.txt文件的一个基本内容格式将如下例所示:
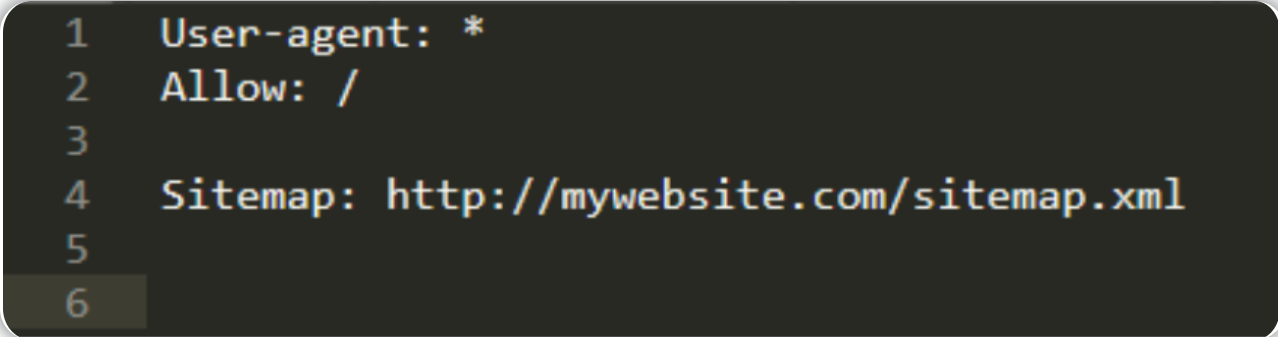
以下是robots.txt中的几个关键字:

在上述的robots.txt例子中:
User-agent:*——任何“爬虫”都可以索引该站点。Allow:/——允许“爬虫”对网站的全部内容进行索引。Sitemap:http://mywebsite.com/sitemap.xml——“站点地图”位于:http://mywebsite.com/sitemap.xml 。
如果我们想对“爬虫”隐藏某些目录或文件,那么robots.txt 将在“黑名单”的基础上进行工作,除非另有说明,爬虫将索引它能找到的任何东西。
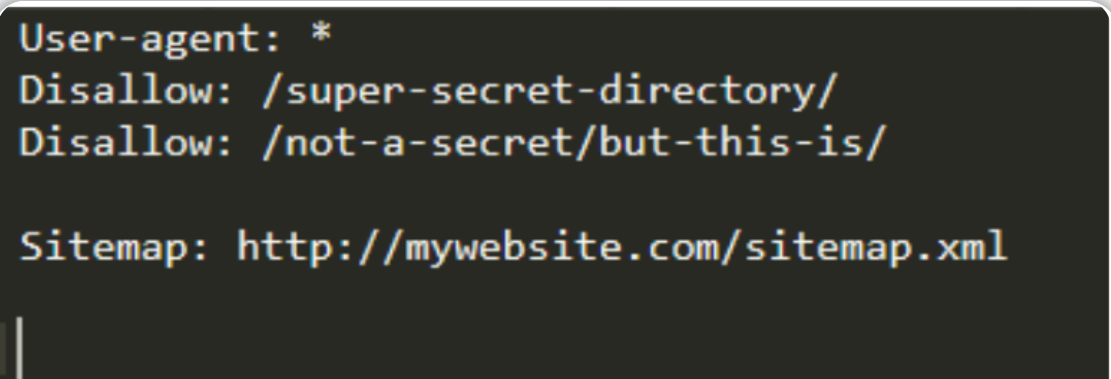
根据上图的robots.txt文件内容可知:
- 任何“爬虫”都可以为网站编制索引。
- “爬虫”不会索引包含在目录“/super-secret-directory/”中的任何内容,爬虫能够知道子目录、目录和文件之间的区别,所以“Disallow:/not-a-secret/but-this-is/”表示“爬虫”将索引目录“/not-a-secret/”中的所有内容,但不会索引子目录“/but-this-is/”中包含的任何内容。
- “站点地图”位于:http://mywebsite.com/sitemap.xml
指定所允许的爬虫类型
如果我们只希望某些“爬虫”为我们的网站编制索引,那么我们可以进行规定,如下图所示:
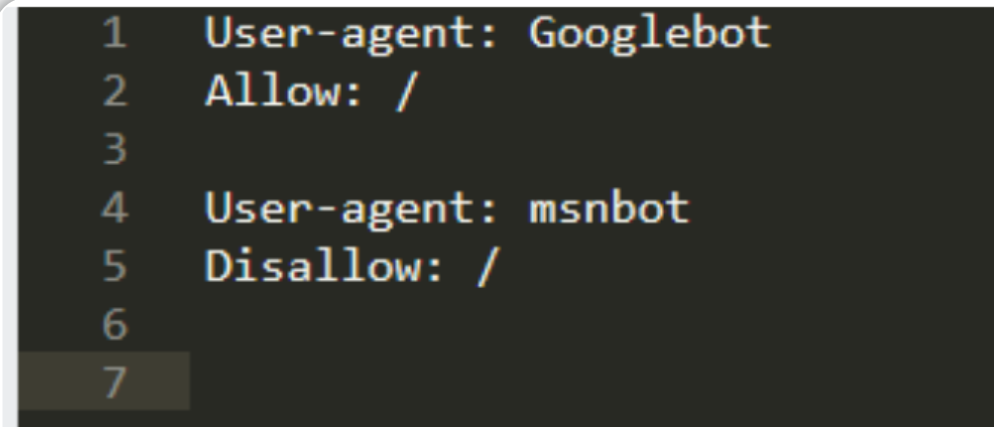
根据上图的robots.txt文件内容可知:
我们允许爬虫“Googlebot”对整个站点进行索引(Allow: /)
我们不允许爬虫“msnbot”为站点编制索引 (Disallow: /)
防止某些文件被索引
你可以手动输入每个不想被索引的文件扩展名,但你还必须提供它所在的目录以及完整的文件名,如果你有一个大型网站,这会非常麻烦,所以此处我们可以使用正则表达式。(正则表达式备忘单:https://www.rexegg.com/regex-quickstart.html )
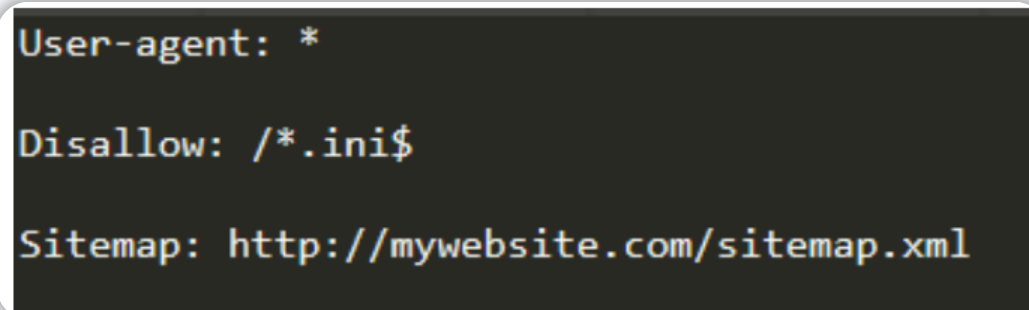
根据上图的robots.txt文件内容可知:
- 任何类型的“爬虫”都可以为网站编制索引。
- “爬虫”无法索引任何根目录下扩展名为 .ini 的文件。(此处使用“$”表示不允许访问某目录下某个后缀的文件)
- “站点地图”位于:http://mywebsite.com/sitemap.xml
tips:我们为什么要隐藏 .ini 文件,因为.ini是配置文件 像这样的文件会包含一些敏感的配置细节,另外还有其他可能包含敏感信息的文件格式我们也要注意。
答题
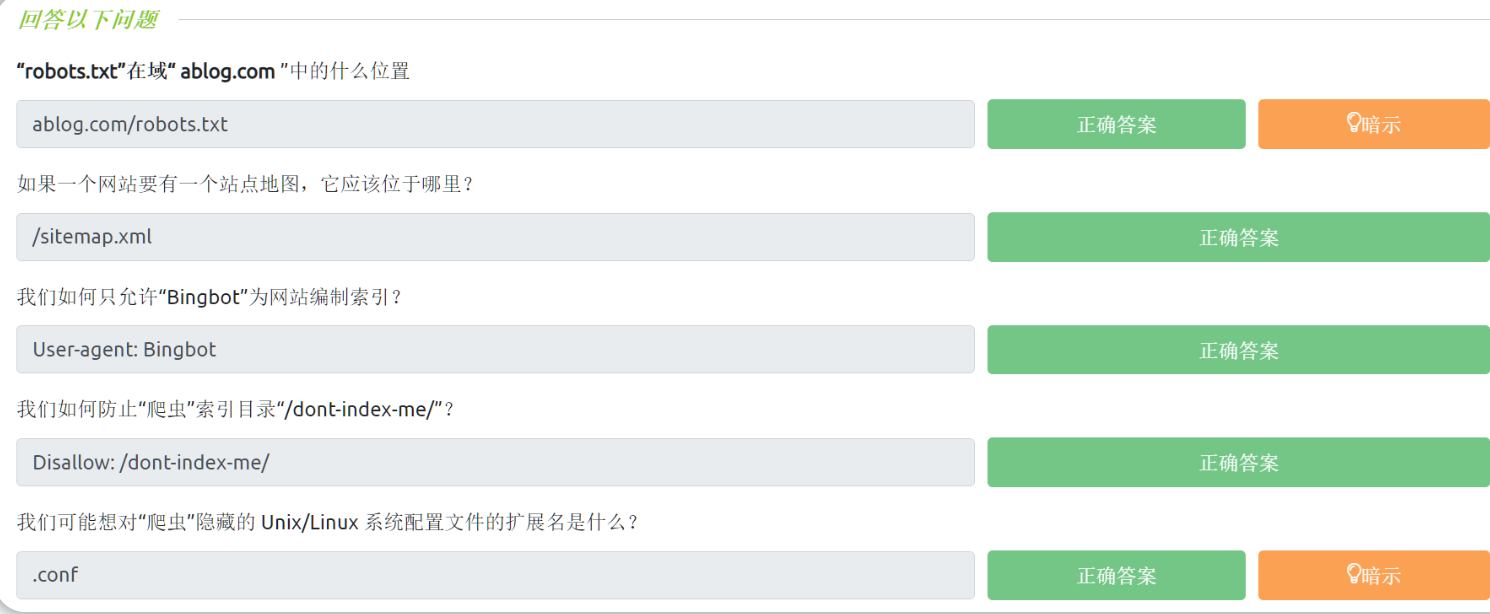
问题: "robots.txt" 在"ablog.com"域的什么位置?
robots.txt文件必须在网站根目录下提供,此题中的robots.txt文件路径为:ablog.com/robots.txt
问题:如果网站有一个站点地图-sitemap,那么它应该位于哪里?
站点地图的具体路径为:/sitemap.xml
问题:我们如何设置robots.txt只允许使用“Bingbot”类型的爬虫为网站编制索引?
在robots.txt中添加内容: User-agent: Bingbot
另外还要在下一行再添加内容: Allow: /
问题:我们如何防止“爬虫”索引目录“/dont-index-me/”? (这里的“索引”是动词)
在robots.txt中添加内容: Disallow: /dont-index-me/
问题:我们可能想对“爬虫”隐藏的 Unix/Linux 系统配置文件的扩展名是什么?
Unix/Linux系统配置文件的扩展名为:.conf
回答:
Sitemaps(站点地图)介绍
Sitemaps简介
Sitemaps即站点地图适用于网站,它的概念和现实生活中的地理地图类似。
“站点地图”是对爬虫有帮助的指示性资源,因为它们指定了在域中查找内容的必要路径,下图是一个基于“站点地图”来展现网站结构的例子:
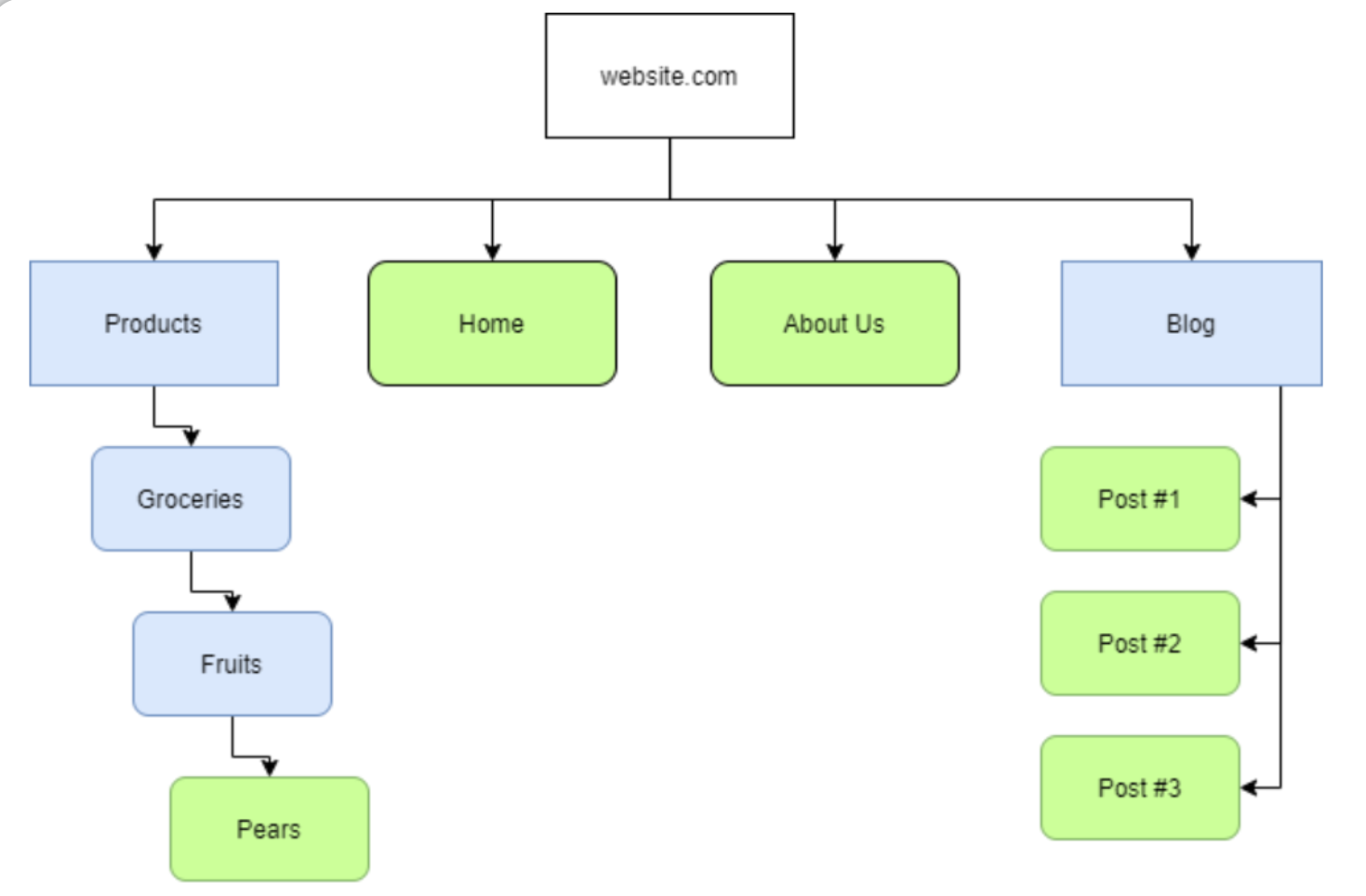
上图中的蓝色矩形代表包含嵌套内容的路径(route),类似于目录;而绿色圆角矩形则代表一个实际页面。当然,Sitemaps(站点地图)的实际内容并不是上图这样,Sitemaps文件的实际内容应该如下图所示:
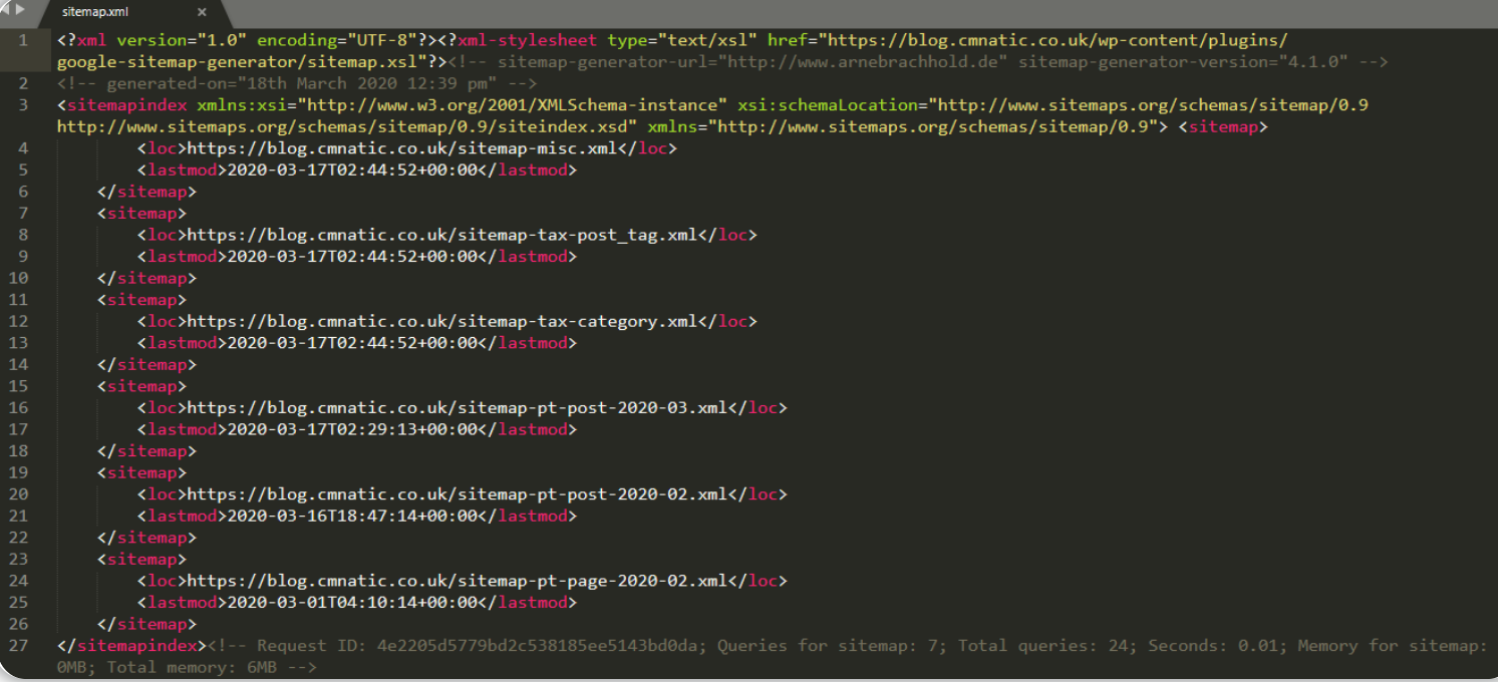
“站点地图”是 XML 格式的,“站点地图”在影响网站的搜索引擎“优化”和受欢迎程度方面具有相当大的分量,正如我们在“搜索引擎优化”一节中所提及的那样,这些站点地图能够使爬虫更容易地遍历网站内容。
“站点地图”为什么对搜索引擎有利:搜索引擎有大量数据需要处理,如何提高收集这些数据的效率至关重要,而“站点地图”等资源对“爬虫”非常有帮助,它能够提供通往网站内容的必要路径,爬虫所要做的就是直接抓取这些网站内容——而不用经历先手动查找再抓取的过程;我们可以把通过使用“站点地图”进行爬行 想象成使用单词表来查找文件而不是先随机猜测文件名称再去查找文件。
tips:一个网站越容易被“抓取”,则代表它对应的“搜索引擎”优化程度越高。
答题
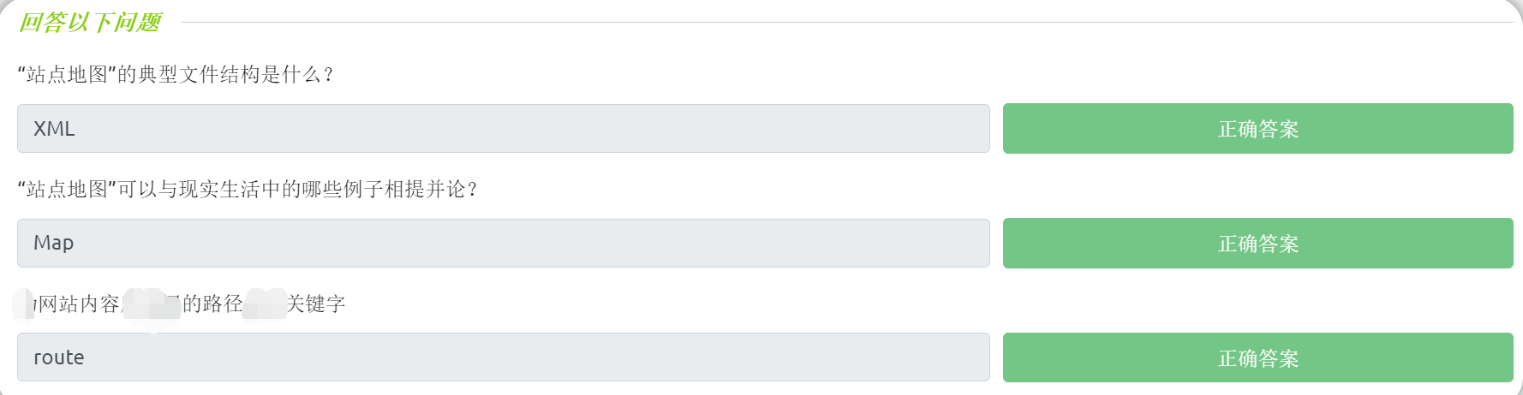
问题:“Sitemap-站点地图”的典型文件结构是什么?
XML文件格式
问题:“Sitemap-站点地图”可以与现实生活中的什么例子相提并论?
Map(地图)
表示网站内容的路径的关键字名称为?
route(路径)
回答:
Google Dorking介绍
Google Dorking简介
使用Google进行高级搜索
正如我们之前所提及的那样,当我们使用谷歌搜索引擎进行搜索时,会有很多网站被爬虫抓取和索引以便我们能够得到一些搜索结果。
除了普通的信息检索之外,搜索引擎还有多种用途,例如,我们可以添加来自编程语言的运算符来增加或减少我们的搜索结果 - 或者也可以直接执行算术等操作。
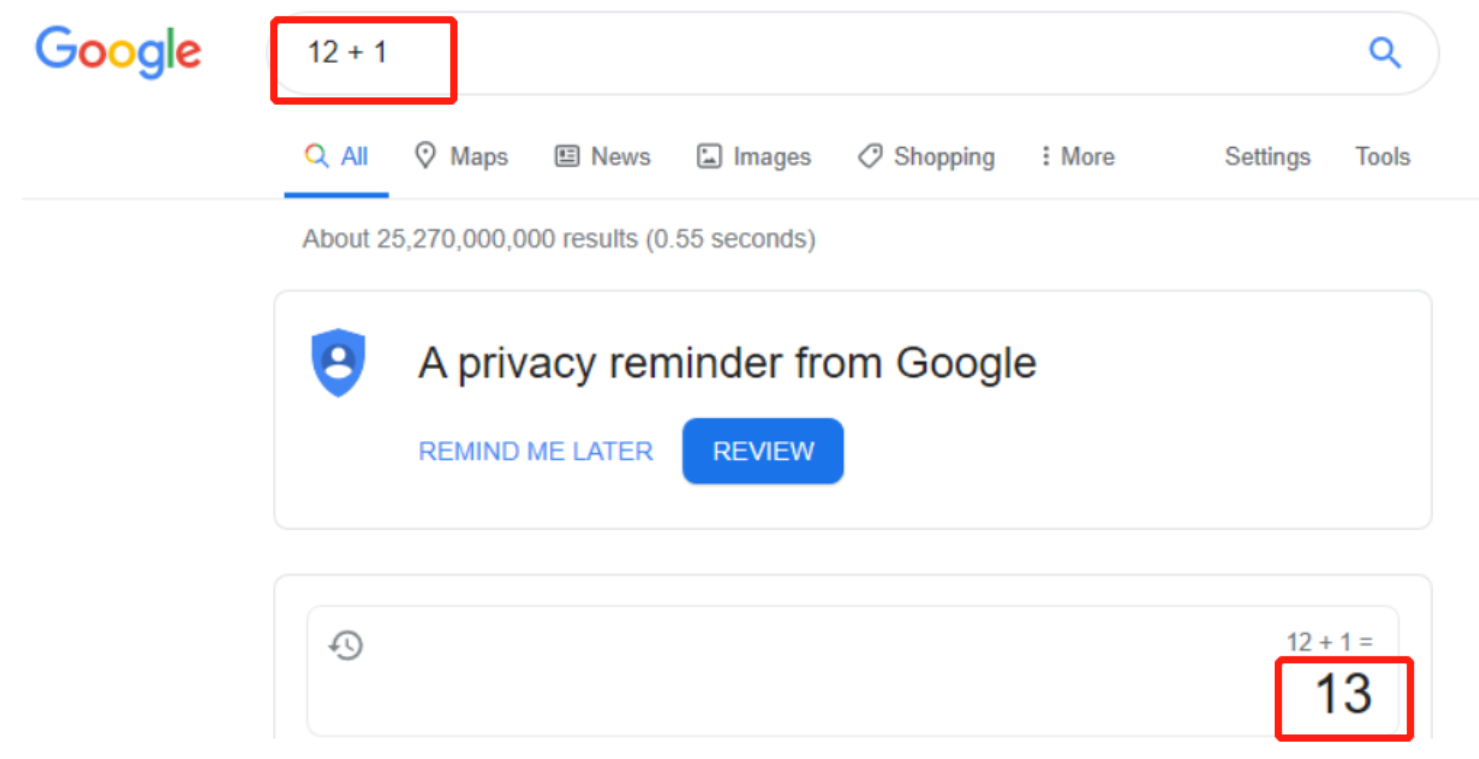
假设我们想缩小搜索范围,我们可以使用引号,谷歌会将引号之间的所有内容解释为需要进行精确查询,然后只会返回包含我们所提供的确切短语的结果,这对于过滤掉我们不需要的垃圾信息非常有用:
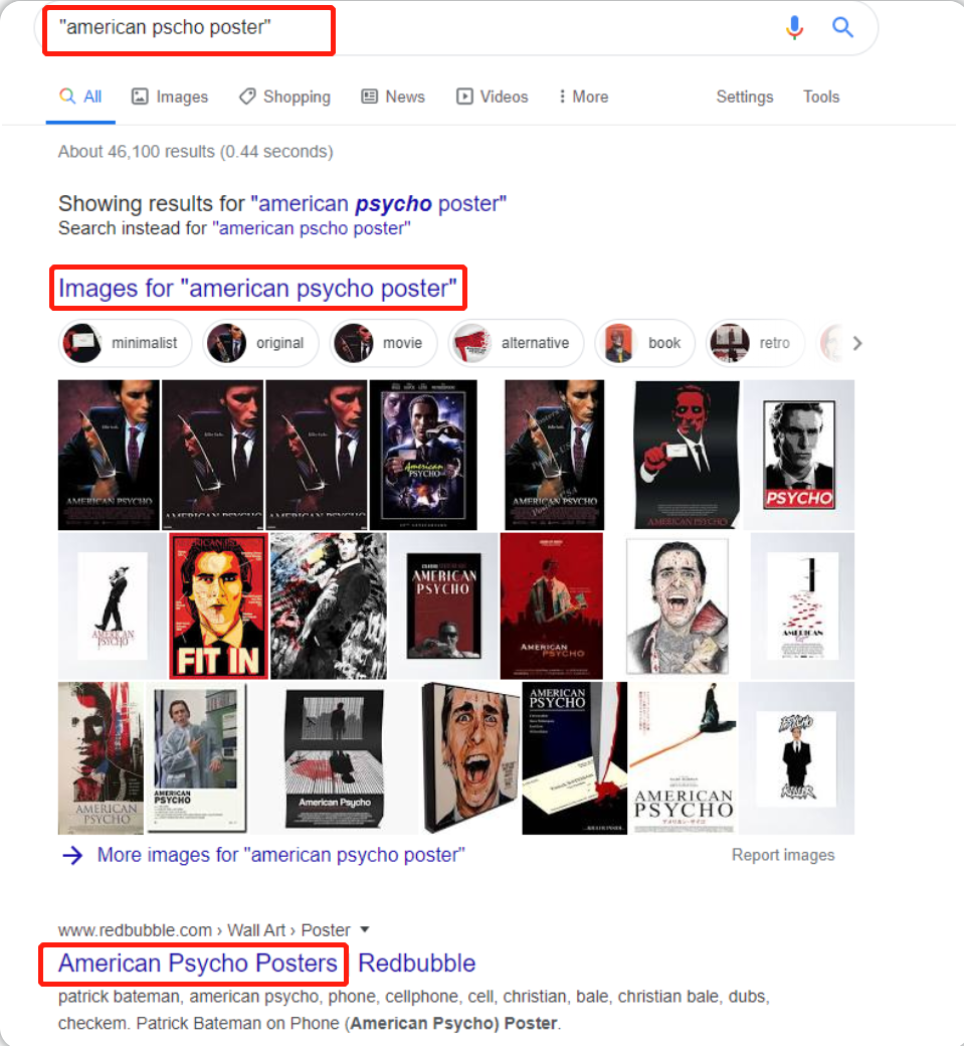
优化我们的查询
我们可以使用诸如 site (例如bbc.co.uk)加上一个确切的查询(例如gchq news)这样的语法,在指定的站点中搜索我们所提供的关键字 这能过滤掉一些我们不需要的内容;例如,我们可以使用 bbc 、 gchq 作为 site + query ,相比于直接搜索关键字 gchq 而言,我们能够优化Google搜索所返回结果的顺序。
在下面的截图中,我们可以看到搜索“gchq news”会从 Google 返回大约 1,060,000 个结果,而我们想要的网站其实排在 gchq 网站的后面:
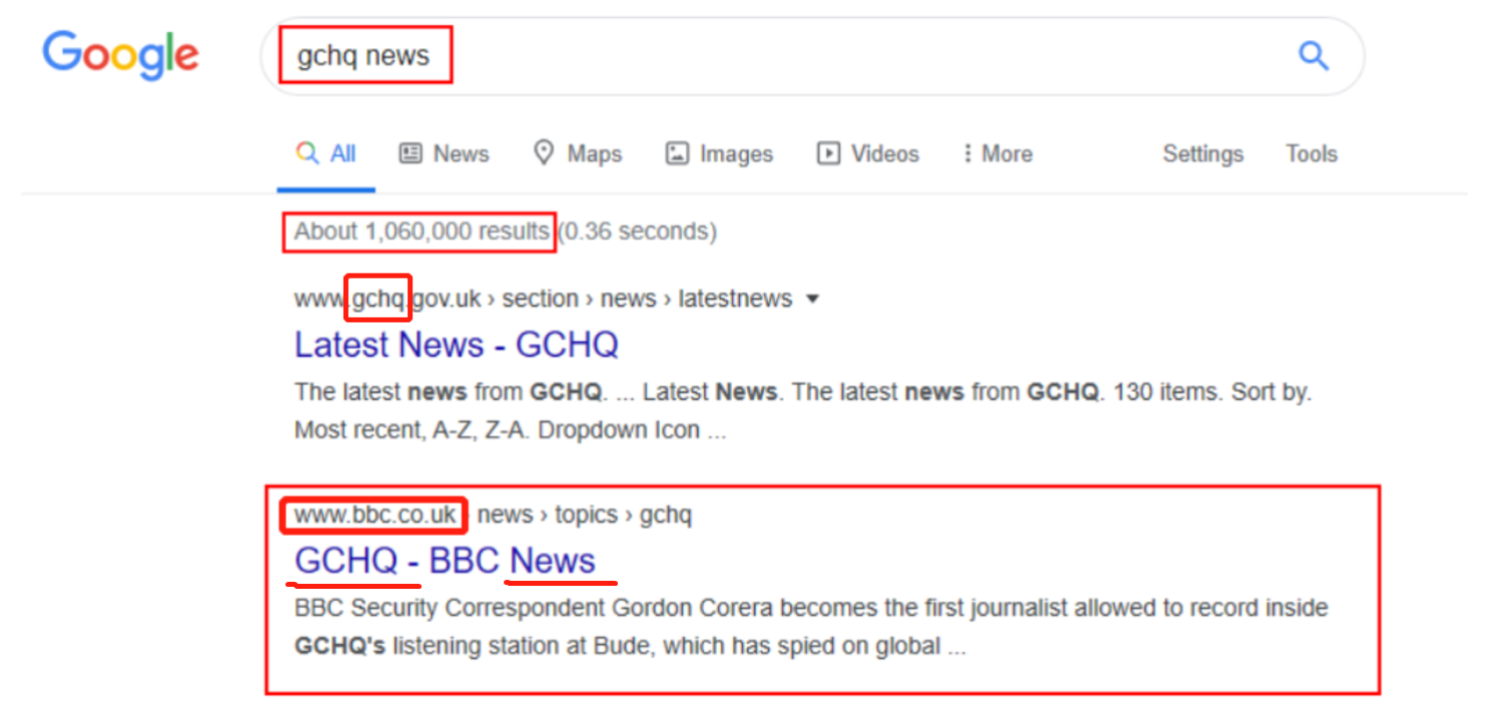
我们实际想要的是bbc.co.uk站点上的GCHQ News页面(见上图),所以我们可以使用" site " 来优化我们的查询,这将返回比上图少很多的搜索结果 并且让我们想要找到的网站链接顺序变得更加靠前一点。
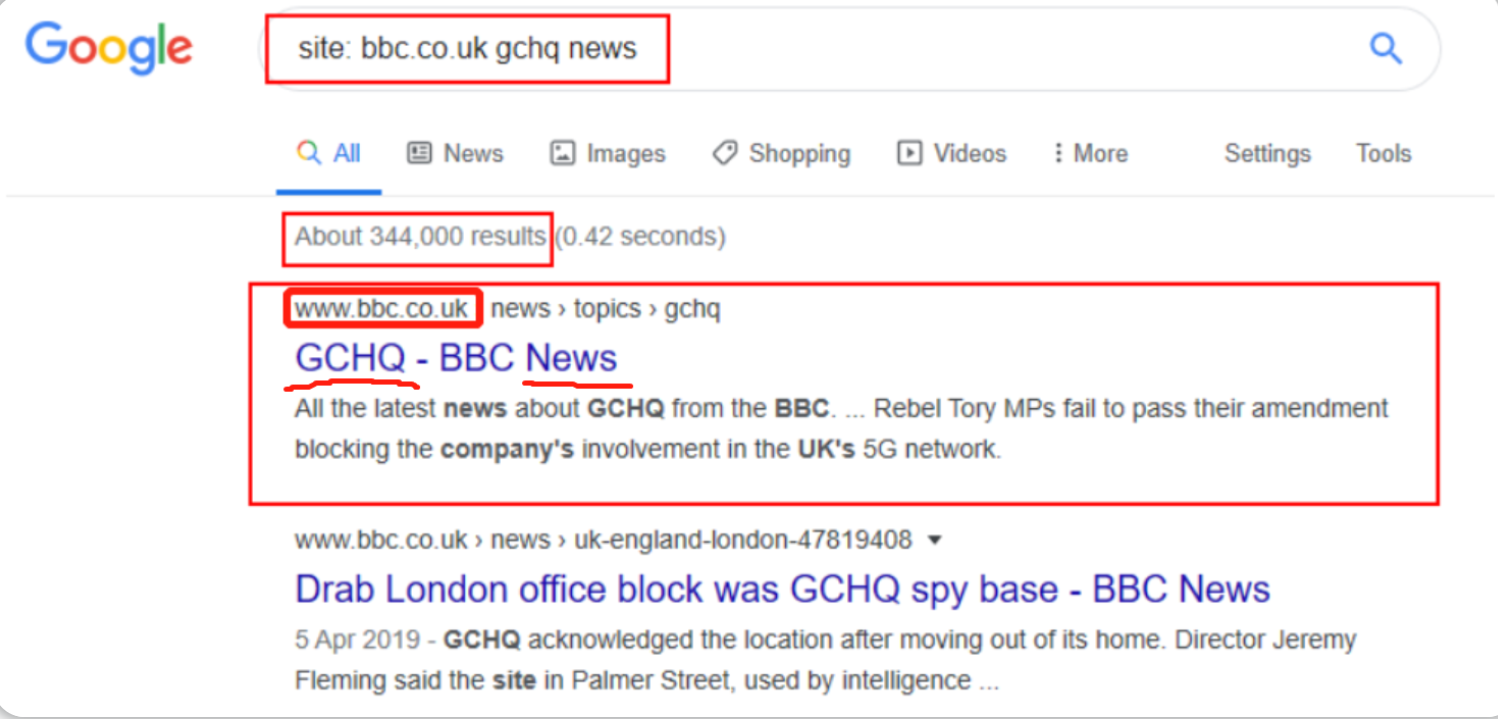
Google Dorking 语法
首先Google Dorking(也被称为Google Hacking)是合法的,我们得到的搜索结果都是能够被搜索引擎索引的、公开可用的信息,而怎么使用这些信息则有可能会导致一些非法结果。
我们可以用于搜索和组合的一些常见Google Dorking术语包括以下几个(实际上还有更多):

例如,假设我们想使用 Google 搜索 bbc.co.uk 上的所有 PDF,我们可以使用以下语法:site:bbc.co.uk filetype:pdf
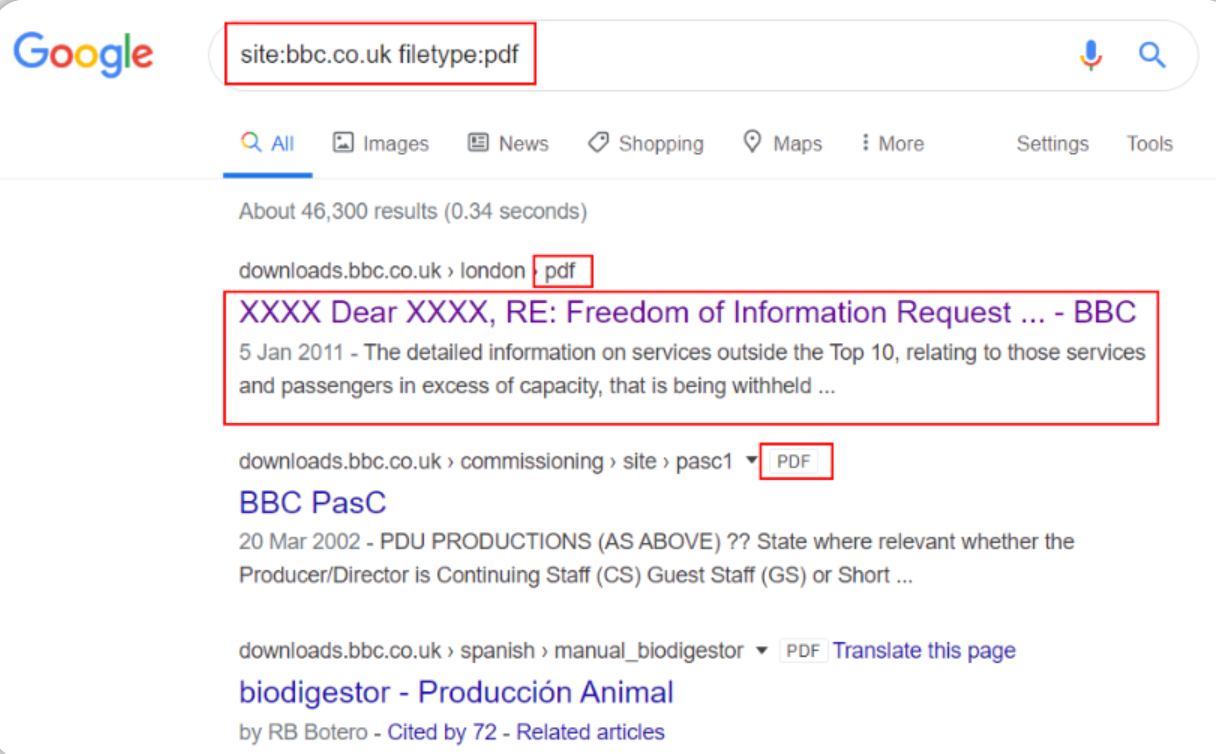
由上图结果可知:我们已经成功改进了搜索结果,我们查询到了“bbc.co.uk”网站上所有可公开访问的 PDF文件。
tips:除了pdf之外,我们还可以指定使用其他敏感文件格式 以便我们找到更多可以公开访问的敏感文件。
我们也可以使用Google Dorking语法来进行简单的目录遍历,具体效果参考下图:

答题
问题:用于查询 bbc.co.uk 站点上包含flood defences关键字的页面的语法是什么?
site: bbc.co.uk flood defences
问题:使用什么术语来按文件类型搜索?
filetype:
问题:我们可以使用什么术语来查找网站登录页面?(查找网站标题中包含login字段的网站页面)
intitle: login
回答:


