


【scrapy】流程大致分析
Scrapy流程分析
Scrapy 是一个重型爬虫框架。主要分为5部分:引擎(Engine)、调度器(Scheduler)(这个不太熟悉)、下载器(Downloader) 、爬虫(Spider)、管道(Item Pipeline)。
- Engine是scrapy的核心,主要负责调度各个组件,保证数据流转。其中包括每五秒自动运行的呼吸函数。
- Scheduler负责管理任务、过滤任务、输出任务的调度器,存储、去重(中间件??)
- Downloader 负责从网页上下载网页数据,吐给调度器处——吐给spider处理——吐给pipeline进行存储处理
- Spider 爬虫
- Item Pipeline负责输出结构化数据,可自定义输出位置(文件、MYSQL、MangoDB..)
- 中间件:除了以上五个部分,还有中间件也是非常重要的。中间件主要分为两种:Downloader Middlewares(下载中间件)、Spider Middlewares(爬虫中间件)。主要用于过滤、处理下载的数据或者爬虫的返回值
流程图如下:
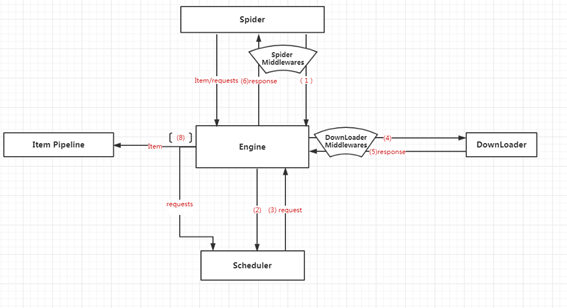
scrapy流程图(自己瞎画的)
流程概述:
- Engine从爬虫中获取初始化请求(种子URL)
- Engine把该请求放入Scheduler中, 同时获取下一个请求(这两为异步)
- Scheduler返回给Engine一个待下载的请求
- Engine发送请求给下载器,中间会经过Downloader Middlewares的过滤
- 这个请求通过下载器下载完成后,生成一个相应对象(response),这个对象将被返回给Engine,中间需要经过一次Downloader Middlewares。
- Engine接受到对象之后,发送给爬虫,中间会经过一系列的Spider Middlewares。
- 在爬虫中执行相应的自定义逻辑。执行完逻辑之后,爬虫执行相应的回调方法,处理得到的数据或者新的request请求。将这个结果发送给Engine,中间经过一系列Spider Middlewares
- Engine得到返回值,若是requests则再执行2, 若是对象则交由Pipeline处理
- 从1开始重复,直到调度器中没有新的请求。
参考: Scrapy源码阅读分析<一>
跟着大佬走了一遍,还是似懂非懂,但是受益匪浅。
自己修为还差得远..再走几遍再走几遍

