第十一章:性能和可伸缩性——Java并发编程实战
线程的最主要目的是提高程序的运行性能,但性能的提升会导致复杂性的提升,又会导致安全性和活跃性的风险
一、对性能的思考
- 提升性能意味着用更少的资源做更多地事情。要想通过并发来获得更好的性能,就要更有效地利用现有处理资源
- 线程使用的额外的性能开销:线程之间的协调(例如加锁、触发信号以及内存同步等),增加的上下文切换,线程的创建和销毁,以及线程的调度等
1、性能与可伸缩性(多块vs多少)
性能通过服务时间、延迟时间、吞吐率、效率、可伸缩性以及容量等衡量
当进行性能调优时,其目的通常是用更小的代价完成相同的工作
可伸缩性指的是:当增加计算资源时(例如CPU、内存、存储容量或I/O带宽),程序的吞吐量或者处理能力响应地增加
在进行可伸缩性调优时,其目的是设法将问题的计算并行化,从而能利用更多地计算资源来完成更多的工作。
我们通常会接受每个工作单元执行更长的时间或消耗更多的计算资源,以换取应用程序在增加更多资源的情况下处理更高的负载。(多少更重要)
2、评估各种性能权衡因素
- ”更快“的含义是什么?
- 该方法在什么条件下运行得更快?在低负载还是高负载的情况下?大数据集还是小数据集?能否通过测试结果来验证你的答案?
- 这些条件在运行环境中的发生频率?能否通过测试结果来验证你的答案?
- 在其他不同条件的环境中能否使用这里的代码?
- 在实现这种性能提升时需要付出哪些隐含地代价,例如增加开发风险或维护开销?这种权衡是否合适?
在对性能的调优时,一定要有明确的性能需求
二、Amdahl定律
Amdahl定律描述的是:在增加计算资源的情况下,程序在理论上能够实现最高加速比,这个值取决于程序中可并行组件与串行组件所占的比重。
Speedup <= 1 / (F + (1 - F) / N) ------- F是必须被串行执行的部分所占比例,N是机器中含有处理器的个数
- 当N趋近无穷大时,最大的加速比趋近于1/F
- 如下图,串行比例越高的程序到达瓶颈需要的处理器数越少,瓶颈的处理器利用率越低
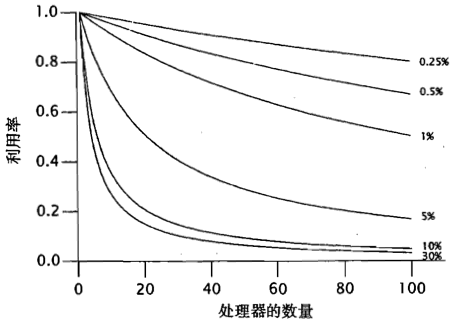
在所有并发程序中都存在串行部分(例:存储结果的共享容器,从共享队列中取出任务)
1、框架中隐藏着串行部分
通过比较当增加线程时吞吐量的变化,推断出框架中串行部分所占比例
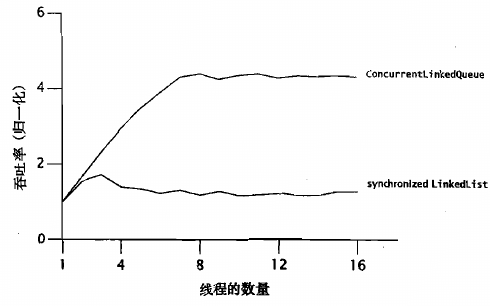
- synchronizedLinkedList有更高的串行比例,更容易到达瓶颈,最高加速比更低
- 到达瓶颈后小幅的下降表示增多线程时加速比的提高已经小于由于线程切换带来性能的损失
2、Amdahl定律的应用
串行执行比例 => 最大加速比 => 达到最大加速比的线程数量
三、线程引入的开销
多个线程的调度和协调过程总都需要一定的性能开销:对于为了提升性能而引入的线程来说,并行带来的性能提升必须超过并发导致的开销
1、上下文切换
过程:保存当前运行线程的执行上下文,并将新调度进来的线程的上下文设置为当前上下文
- 切换上下文需要一定的开销,而在线程调度过程中需要访问操作系统和JVM共享的数据结构
- 上下文切换将导致一些缓存缺失,因而线程在首次调度运行时会更加缓慢
2、内存同步
内存栅栏:在synchronized和volatile提供的可见性保证中可能会使用一些特殊指令
- 内存栅栏可以刷新缓存,在内存栅栏中,大多数操作都是不能被重排序的
解决:
- JVM优化去掉不会发生竞争的锁
- 找出不需同步的本地栈元素
- 锁粒度粗化,将近邻的锁合并,减少锁请求和锁释放的次数
3、阻塞——当在锁上发生竞争时,竞争失败的线程肯定会阻塞
自旋等待——通过循环不断地尝试获取锁
挂起——产生额外上下文开销
四、减少锁的竞争
并发程序中,对可伸缩性的最主要威胁就是独占方式的资源锁。(锁的请求频率 + 每次持有该锁的时间)
1、缩小锁的范围(“快进快出”)
目标:尽可能缩短持有锁的时间
方法:超出共享变量,只对操作共享变量的代码加锁
理论:根据Amdahl定律,减少了必须串行执行的部分
注意:必要的原子操作不能分别加锁;锁粒度细化造成更多的同步开销,JVM会自动进行锁粒度粗化
2、减少锁粒度——是不同组对象持有不同的锁
锁分解:如果一个锁需要保护多个相互独立的状态变量,那么可以将这个锁分解为多个锁,并且每个锁只保护一个变量,从而提高可伸缩性,并最终降低每个锁被请求的频率。
对锁分解后每个新的细粒度锁上的访问将减少,分摊到两个锁上
对竞争适中的锁进行分解时,实际上是把这些锁转变为”非竞争“的锁,从而有效地提高性能和可伸缩性。
1 @ThreadSafe 2 public class ServerStatusAfterSplit { 3 @GuardedBy("users") public final Set<String> users; 4 @GuardedBy("queries") public final Set<String> queries; 5 6 public ServerStatusAfterSplit() { 7 users = new HashSet<String>(); 8 queries = new HashSet<String>(); 9 } 10 11 public void addUser(String u) { 12 synchronized (users) { 13 users.add(u); 14 } 15 } 16 17 public void addQuery(String q) { 18 synchronized (queries) { 19 queries.add(q); 20 } 21 }
3、锁分段——对一组独立对象上的锁分解
对竞争激烈的锁进行分解时,两个锁可能竞争仍很激励,性能提高不明显
例:在ConcurrentHashMap的实现中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。
挑战:有些操作需要独占整个对象,即需要全部的锁,这样开销更大。但有些操作即使需要获得全部的锁,但也不需要同时获得
1 public Object get(Object key) { 2 int hash = hash(key); 3 synchronized (locks[hash % N_LOCKS]) { 4 for (Node m = buckets[hash]; m != null; m = m.next) 5 if (m.key.equals(key)) 6 return m.value; 7 } 8 return null; 9 } 10 11 public void clear() { 12 for (int i = 0; i < buckets.length; i++) { 13 synchronized (locks[i % N_LOCKS]) { 14 buckets[i] = null; 15 } 16 } 17 }
4、避免热点区域
如果程序采用锁分段或分解技术,那么一定要表现出在锁上的竞争频率高于在锁保护的数据上发生竞争的频率(例:ConcurrentHashMap和Map中的每一項)
热点域:数据上发生很高频率的竞争(例:HashMap.size())
解决:ConcurrentHashMap为每个分段都维护一个独立的size计数,并通过每个分段的锁来维护总size
5、代替独占锁的方法
ReadWriteLock:如果多个读取操作都不会修改共享资源,那么这些读取操作可以同时访问该共享资源,但在执行写入操作时必须以独占方式来获取锁
原子变量:降低更新“热点域”时的开销,例如竞态计数器、序列发生器、或者对链表数据结构中头节点的引用。原子变量类提供了在整数或者对象引用上的细粒度原子操作(因此可伸缩性更高),并使用了现代处理器中提供的底层并发原语(例如比较并交换)
6、监控CPU利用率
linux命令:vmstat或mpstat
cpu利用不充分的原因:
- 负载不充足。
- I/O密集。*nix可用iostat, windows用perfmon。
- 外部限制。如数据库服务,web服务等。
- 锁竞争。可通过jstack等查看栈信息。
如果CPU的利用率很高,并且总会有可运行的线程在等待CPU,那么当增加更多地处理器时,程序的性能可能会得到提升。
7、对对象池说不
当线程分配新的对象时,基本上不需要在线程之间进行协调,因为对象分配器通常会使用线程本地的内存块,所以不需要在堆数据结构上进行同步。然而,如果这些线程从对象池中请求一个对象,那么就需要通过某种同步来协调对象池数据结构的访问,从而使某个线程被阻塞。
对象分配操作的开销比同步的开销更低。
五、减少上下文切换的开销
减少锁的持有时间,因为持有时间越长,就越容易发生竞争,就月容易发生阻塞。当任务在运行和阻塞这两个状态之间转换时,就相当于一次上下文切换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号