
3、Redis特性和我受伤了
前言
关于redis,我们首先想到的便是它是缓存,比数据库快。
比如为什么比数据库快,很明显,redis缓存的数据放到了内存中,而数据库是在磁盘上,内存当然比磁盘快了呀
Redis特性
1、速度快
1、redis的所有数据都是存在在内存中的,Redis使用C语言实现的,C语言距离操作系统更近,因此速度回相对较快
2、Redis使用了单线程,预防了多线程可能产生的竞争问题
2、基于键值对的数据结构服务器
3、客户端语言多
有Java PHP C C++等
4、持久化
通常情况下降数据放到内存中是不持久的,一旦发送断点或者故障就完犊子了,因此有两种持久化方式RDB和AOP,这个持久化方式,后面解释喽
5、主从复制
Redis提供了复制功能,实现类多个相同数据的Redis脚本
6、高可用和分布式
高可用,Reidis Sentinel 哨兵,他能保证Redis节点的故障发现和故障自动转移,Redis从3.0版本正式出了分布式Redis Cluster,它是Redis真正的分布式实现。提供了高可用、读写和容量的扩展性
2、Redis使用场景
1、缓存,几乎在所有大型的网站都有使用,可以设置键值过期时间
2、排行榜系统,Redis提供了list和Zset有序集合数据结构,合理使用这个就可以构建各种排行榜系统
3、计数器应用,这个我们公司就有用到,用来拦截访问次数的。
4、消息队列,这个在netty和websocket的时候有使用过,通过coverAndSend进行队列的监听并发送
3、redis启动和连接
1、服务端启动
redis-server ../redis.conf2、客户端启动
也就是说可以远程连接其他的redis,-p 默认是6379 -h 默认是 127.0.0.1
redis-cli -p
redis-cli -p 6379 -h 127.0.0.13、停止redis服务
redis-cli shutdown nosave|save 是否生成持久化文件4、单线程架构
为什么单线程还这么牛逼
1、纯内存访问
Redis将数据放到内存中,内存相应时间相当快
2、非阻塞I/O
i/o多路复用技术的实现
3、单线程避免了多线程的切换和资源的竞争
存在的问题:
单线程会有一个问题,那就是每个命令的执行时间是有要求的,如果某个命令执行时间过长,就会造成其他的命令的阻塞,对于redis这种来说是非常致命的。
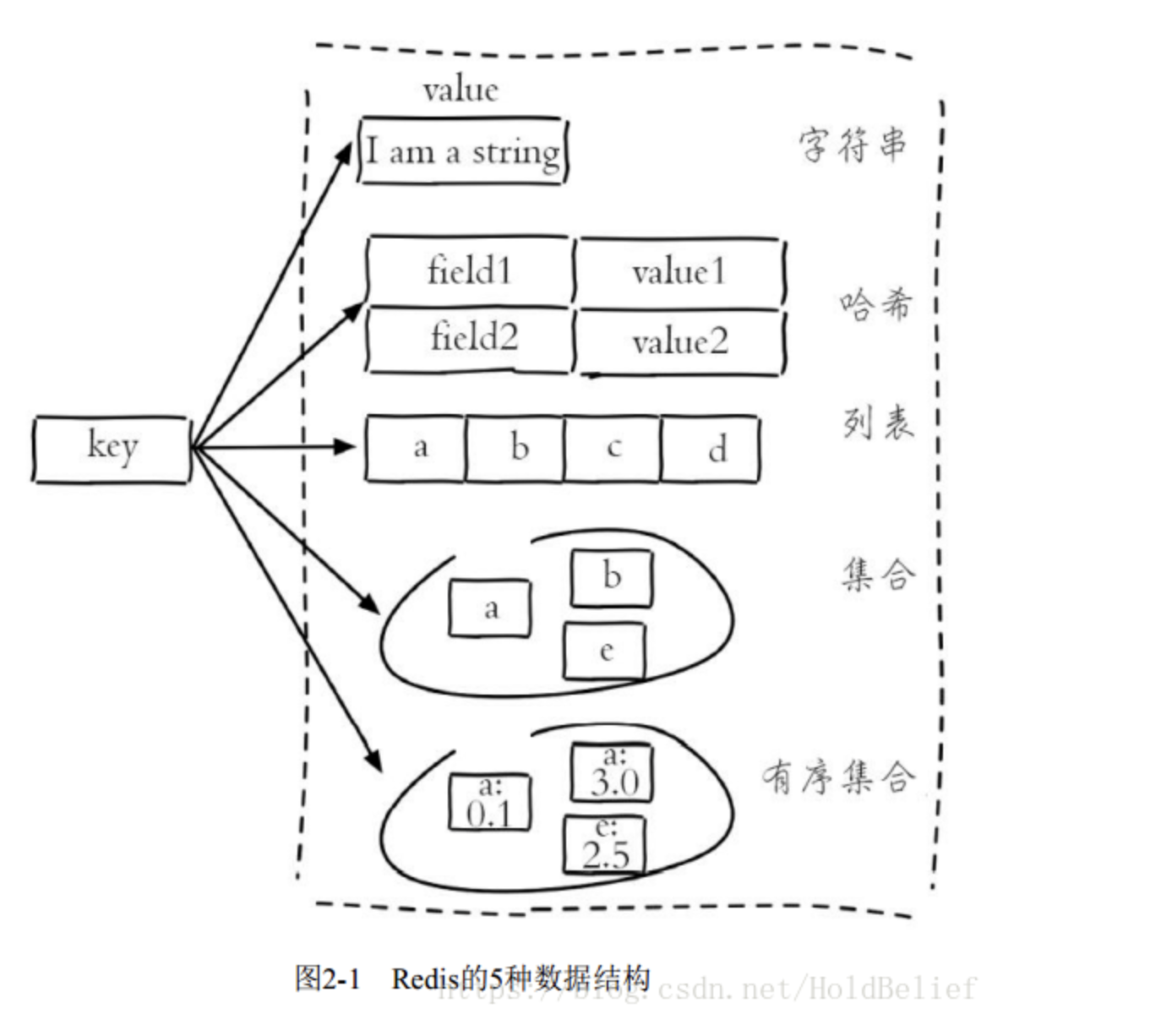
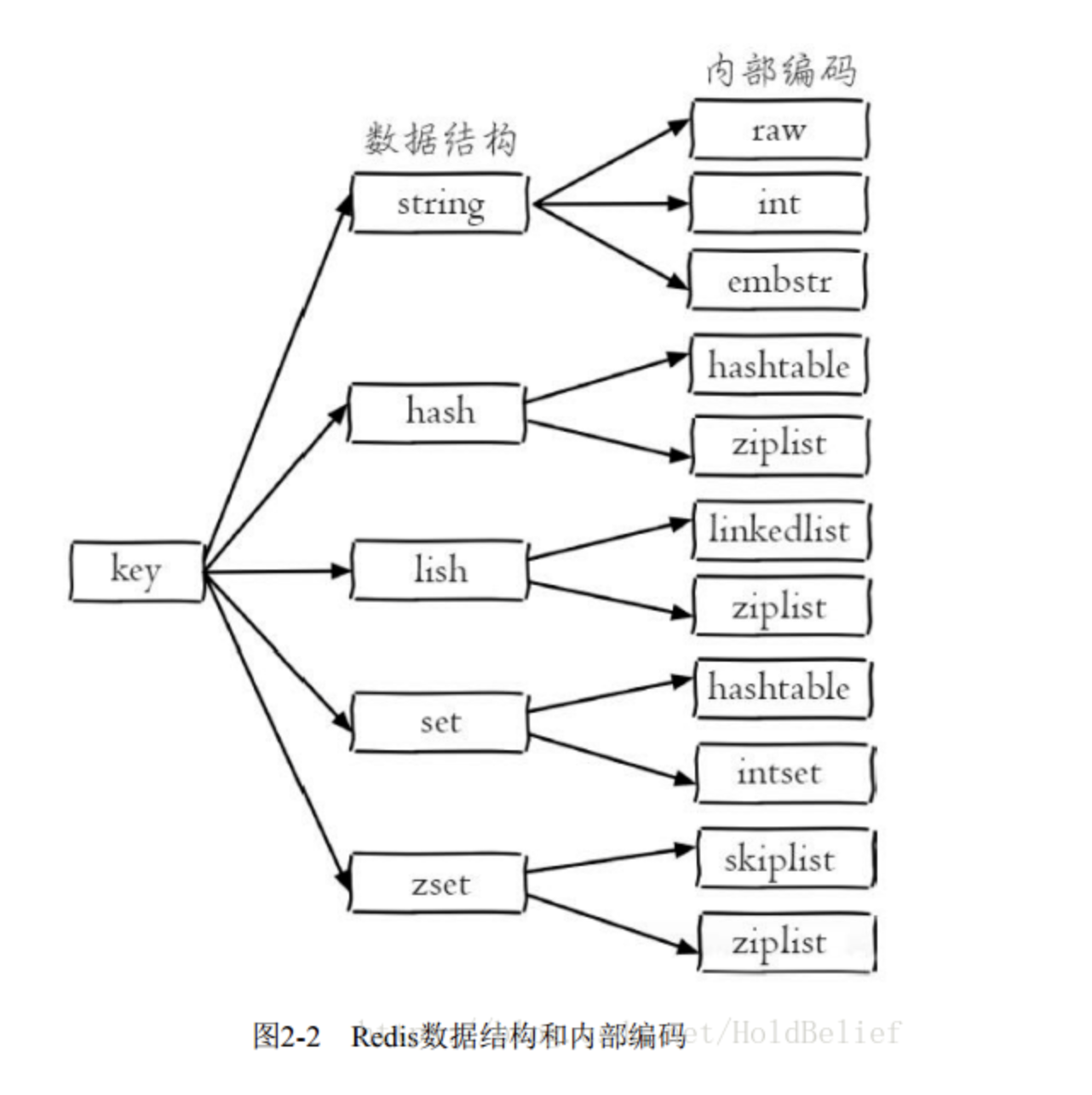
5、数据结构和内部编码
string( 字符串) 、 hash( 哈希) 、 list( 列表) 、 set( 集合) 、 zset( 有序集合)
object encoding key
1、字符串
马勒戈壁的,这里的字符串千万不要以为真的是字符串,可以是字符串,也可以是数字(整数,浮点数,甚至可以是二进制),但是值最大是512M
127.0.0.1:6379> set hello healerjean
OK
127.0.0.1:6379> get hello
"healerjean"
127.0.0.1:6379> object encoding hello
"embstr"
127.0.0.1:6379> 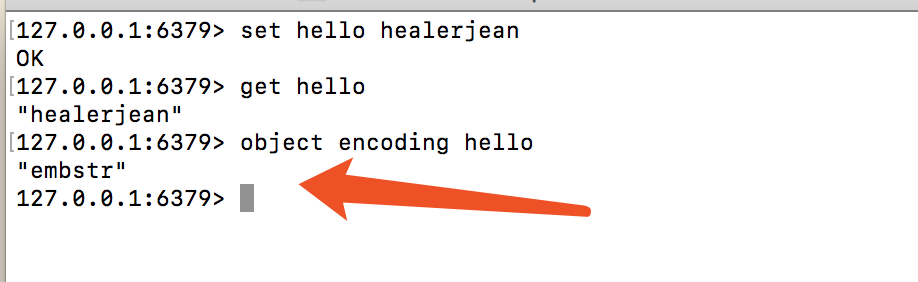
字符串 -使用场景
计数,共享session,限速,用户信息
2、hash
hash的内部编码有两种 一种是ziplist(压缩列表)和hashtable(哈希表)
1、field个数比较少(少于512),并且没有大的value时(64字节),内部编码为ziplist
127.0.0.1:6379> hmset healerjean name zhangyj age 24
OK
127.0.0.1:6379> OBJECT ENCODING healerjean
"ziplist"
127.0.0.1:6379>
2、当value大于64字节
127.0.0.1:6379> hset healerjean name 张宇晋十大好人确实时还是会fasdfasdfadsfdsffsdfdsf发大水发的说法的所发生的发多少
(integer) 0
127.0.0.1:6379> OBJECT encoding healerjean
"hashtable"
127.0.0.1:6379> hash使用场景
存储用户信息,更加直观,节省空间
缺点 要控制在ziplist和hashtable两种内部编码的转化,hashtable会消耗跟单内存
3、list
内部编码 ziplist(元素个数最大512个,个数不超过64字节) linkedlist
这个其实并没有什么,相当于是一个栈(lpush_lpop),里面可以是一个阻塞队里(lpush+rpop)。具体自己看看吧,我这边还没有生产中用到,但是它的使用场景真的是值得以后注意
使用场景
1、消息队列,Reids的 lpush (左侧放)和brpop (右侧拿)就可以实现消息队列,生产中使用lpush从从列表左侧放入元素,多个消费者客户端使用broop命令阻塞式抢列表元素
2、文章列表
我的想法,先判断查找条件,根据查找条件找出data,然后将查找条件添加放到缓存库中,并将这个查找条件制作为hmset的key,将data放到库里面,再制作成list,开始分页。这样每次判断查找条件就可以了 。
1、每篇文件采用hash作为存储结构(这样存储太麻烦了,不如来个序列化字符串,直接遍历mget取出来的data,序列化)
hmset user:article:1 title xx timestamp 147512225 content xxxx
hmset user:article:2 title xx timestamp 147512225 content xxxx
2、向用户文件列表添加文件
lpush user:1:articles user:article:1 user:acticle:3
3、分页获取,例如获取id为1的10篇文件
articles = lrange user:1:article 0 9
for(user:article in articles){
hgetall(article)
}文章列表缺点:如果列表较大,使用lrange 使用 中间的数字区间查询,性能会变差。
如果不用上门的分页查找,直接取出data,在将它放入redis中,key值包含的一些关键信息,前缀(是不是普遍的用户)+当前的页数+每页数据的大小等
4、集合
内部编码
intset(整数集合)当集合中元素都是整数且元素个数小于512,使用ta
hashtable
使用场景
集合类型最典型的使用场景就是标签(tag)例如一个用户可能对娱乐,体育比较感兴趣,另一个用户可能对历史新闻比较感兴趣,有了这些数据就可以喜欢同一个标签的人了(相当于是两张表关联起来了)
上面这个两个应该放到同一个事物中执行
1、给用户添加标签
sadd user:1:tags tag1 tag2
2、给标签添加用户
sadd tag1:users user:1 user:2
同一个事物中执行
3、删除用户下的标签
srem user:1:tags tag1
4、删除标签下的用户
srem tag1:user:1 user1
共同感兴趣的标签
sinter user:1:tags user:2:tags5、zset有序集合
看到这个可能会有一点陌生,确实,我也刚开始看到时候头大呢,他和索引下标排序作为依据不同,他给每个元素设置一个分数,作为排序的依据,它给我们提供了获取指定的分数和元素范围查询,计算成员排名等功能。
给有序集合添加用户haelerjean和分数250
zadd user:ranking 250 healerjean
内部编码 ziplist(压缩列表)、skiplist(跳跃表)
使用场景
排行榜系统
例如,视频网站需要对用户上传的视频做排行榜,榜单的维度可能是多个方面的,按照时间,按照播放数量,按照获得的赞数。这里使用赞数,记录每天用户上传视频的排行榜
1、添加用户赞数
例如用户healerjean上传了一个视频,并获得了3个赞,可以使用有序集合的zadd和zincrby功能
zadd user:rank_2018 3 healejean
之后获得一个赞就加1
zincrby user:rank_2018 1 healerjean
2、取消用户赞数
由于各种原因,(用户注销,用户作弊),将用户删除,此时需要将用户从榜单中删除掉,
zrem user:ranke_2018 healejrean
3、展示获取赞数最多的10个用户 (revente为从score大到小排列)
zrevengebyranke user:rank_2018 0 9
4、展示用户信息以及分数
这个功能,将用户名作为键后缀,将用户信息放到了hash表中,
hgetall user:info healerjean //用户信息
zscore user:rank_2018 healerjean //用户的点赞数
zrank user:ranke_2018 healerjean //用户排名
6、键管理
1、单个键管理
什么都不考虑,二愣子的情况下
rename healejrean zhangyj
上面的有个问题,如果zhangyj 也是一个存在的key,那么就会覆盖掉zhangyj以前的值,为了防止被强行rename redis提供了renamenex,确保只有 newkey不存在时候才覆盖
注意事项
重命名期间会删除旧的key,如果键的值比较大,会存在阻塞Redis的可能性,这点千万不能忽视
2、键过期
1、设置键的过期时间
expire hello 10 10秒过期
expireat hello 1512552122 时间戳秒过期
pexpire hello 毫秒过期
pexpireat hell 时间戳毫秒过期
2、将过期时间清除
persist hello
注意事项,
1、在字符串执行set命令的时候,看源码就会知道,会去除过期时间,这点非常重要
3、迁移键
这个功能可以说是相当牛逼了,,因为有的时候我们需要将一个redis迁移到两一个redis。redis提供了几种方法,但是使用场景有所区别
1、move
只用于在Redis内部进行数据迁移,Redis内部可以邮多个数据库,但是在数据上不是共通的
move key db
2、dump+restore
dump key value
restore key ttl value
实现在不同的redis实例之间进行数据迁移的功能,只要分为两步
1> 在源redis上dump命令将键值序列化,格式采用的是RDB格式,
2> 在目标Redis奖上面的序列化的值进行复原,其中ttl参数表示过期时间 ttl=0表示没有过期时间
原理探究:这个过程不是原子性质的,而是在通过两个客户端完成的的,一个dump,一个restore
3、migrate (移动)
这个是相当于是进行了3个命令 dump+restore+del 这个是原子性的
目标redisip,端口,key、目标的索引库、迁移的超时时间
127.0.0.1:6380>migrate 127.0.0.1 6379 hello 0 1000
迁移多个key
127.0.0.1:6380>migrate 127.0.0.1 6379 "" 0 5000 keys key1 key2 问题:后面还可以配置copy和replace 复制还是移动、以及是否取代目前redis的存在的相同的key
三个命令的比较
| 命令 | 作用域 | 原子性 | 支持多个键 |
|---|---|---|---|
| move | redis实例内部的库 | 是 | 否 |
| dump + restore | redis实例之间 | 否 | 否 |
| migrate | redis实例之间 | 是 | 是 |
7、键遍历
redis提供了两个命令遍历所有的键分别是keys scan
1、全量遍历键
1、匹配遍历
*匹配任意字符
keys *
?匹配一个字符
127.0.0.1:6379>keys h?ll*
hello
* [] 匹配部分字符 [1,3] 匹配1或者3 [1-10] 匹配1到10之间的任意数字
keys *2、如果想删除我们查找到的相关key
删除vedio开头的键
keys vedio* | xargs redis-cli del存在问题
再强调redis是单线程的,如果redis中存在了大量的键就不太美妙了,可能会造成redis阻塞,所以一般不建议在生产环境使用keys命令,但是假如有时候不得不使用怎么办 ,使用scan命令
2、渐进式遍历
scan cursor [match patten] [count number]
cursor必须参数,是一个游标,第一次遍历从0开始,每次scan遍历都会返回当前游标的值
match pareetn 匹配模式,和上面的keys * 匹配模式基本一致
count 显示多少个,默认是10
下面这个6就是下次遍历的游标
127.0.0.1:6379> scan 0
1) "6"
2) 1) "key:12"
2) "key:8"
3) "key:4"
4) "key:14"
5) "key:16"
6) "key:17"
7) "key:15"
8) "key:10"
9) "key:3"
10) "key:7"
11) "key:1"
127.0.0.1:6379> scan 6
1) "11"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"
6) "key:13"
7) "key:6"
8) "key:9"
9) "key:11"
127.0.0.1:6379> scan 11
1) "0"
2) 1) "key:5"
2) "key:18"
3) "key:0"
4) "key:2"
5) "key:19"redis为了解决阻塞问题可是想了很多奇招呐
比如哈希类型,集合类型,有序集合 hgetall smembers zrange 对应的命令是hscan sscan zscan
这里手下sscan set
String key ="myset"
String patten="old:user*";
String cursor = "0";
while(true){
ScanResult scanResult = redis.sscan(key,cursor,patten)
List emelemts = scanResult.getResult();
redis.srem(key,elements);
//获取新的游标
cursor =scanResult.getStringCursor();
if("0".equals(cursor)){
break; /、结束循环
}
}注意问题,游标式遍历相当于是分布执行命令,如果中间有添加数据,新增的键可能没有便利到,这个是开发时候,需要考虑的
8、数据库管理
redis具有16个数据库,正常情况下我们使用的只是0号数据库,例如Redis Cluester中只允许使用0号数据库,只不过为了向下兼容老版本的数据库功能,没有废弃掉罢了,
那么为什么要废弃它呢
redis是单线程的,如果使用这些数据库,那么还是使用的同一个cpu,相互之间会有影响,如果分配不同的任务,加入有一个数据库太慢,那么其他的任务就会受到影响
建议:
使用多个数据库,完全可以在一台机器上部署多个redis,因为现在计算机都是有多个cpu的,这样保证了业务直接不会受到影响,又合理的利用了资源
这里最需要记住的就是reids是单线程的,尽量不要操作批量数据,防止发生阻塞
如果满意,请打赏博主任意金额,感兴趣的请下方留言吧。可与博主自由讨论哦
| 支付包 | 微信 | 微信公众号 |
|---|---|---|
 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号