5、客户端
前言
1、序列化
Jedis还提供了字节数组的参数,可以将java对象序列化为二进制,当需要的时候,取出来。
2、Jedis连接
1、直接连接
每次使用都会新建TCP连接,每次使用后都会断开连接,对于频繁访问肯定是不好的
static Jedis jedis = null;
static{
jedis = new Jedis("127.0.0.1",6379);
}
2、Jedis连接池
因此生产环境都是使用的Jedis连接池,所有的Jedis对象预先放到池子中,每次都从池子中借,用完了还给池子
admore.redis.max-total=64
admore.redis.max-idle=30
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig" >
<property name="maxTotal" value="${admore.redis.max-total}"/>
<property name="maxIdle" value="${admore.redis.max-idle}"/>
<property name="maxWaitMillis" value="1500"/>
<!-- 永远不要加testOnBorrow 或 testOnReturn这类,不然你会后悔的 -->
</bean>
<bean id="jedisFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory" destroy-method="destroy">
<property name="password" value="${admore.redis.password}"/>
<property name="hostName" value="${admore.redis.host-name}"/>
<property name="port" value="6379"/>
<property name="usePool" value="true"/>
<property name="poolConfig" ref="jedisPoolConfig"/>
</bean>
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate" scope="prototype">
<property name="connectionFactory" ref="jedisFactory"/>
<property name="keySerializer">
<bean class="com.duodian.admore.cache.CustomStringRedisSerializer"/>
</property>
<property name="valueSerializer">
<bean class="com.duodian.admore.cache.CustomJSONStringRedisSerializer"/>
</property>
</bean>
</beans>
3、Redis中的Pipeline的使用方法
1、获取pipeline
Pipeline pipeline = jedis.pipelined();2、命令执行
pipeline和jedis写法完全一致,但是不知在这个时候执行,而是pipeline.sync();
public static void usePipeline(){
Jedis jedis = getJedis();
Pipeline pipeline = jedis.pipelined();
long begin = System.currentTimeMillis();
for(int i = 0;i<count;i++){
pipeline.set("key_"+i,"value_"+i);
}
//执行命令
pipeline.sync();
jedis.close();
}
3、操作结果返回
List<Object> result= pipeline.syncAndReturnAll();
@Test
public void pipeline(){
Pipeline pipeline = jedis.pipelined();
pipeline.set("hello","hello");
pipeline.set("count","1");
pipeline.incr("count");
List<Object> result= pipeline.syncAndReturnAll();
for(Object o :result){
System.out.println(o);
}
}
OK
OK
25、客户端管理和异常分析
5.1、客户端API
5.1.1、client list
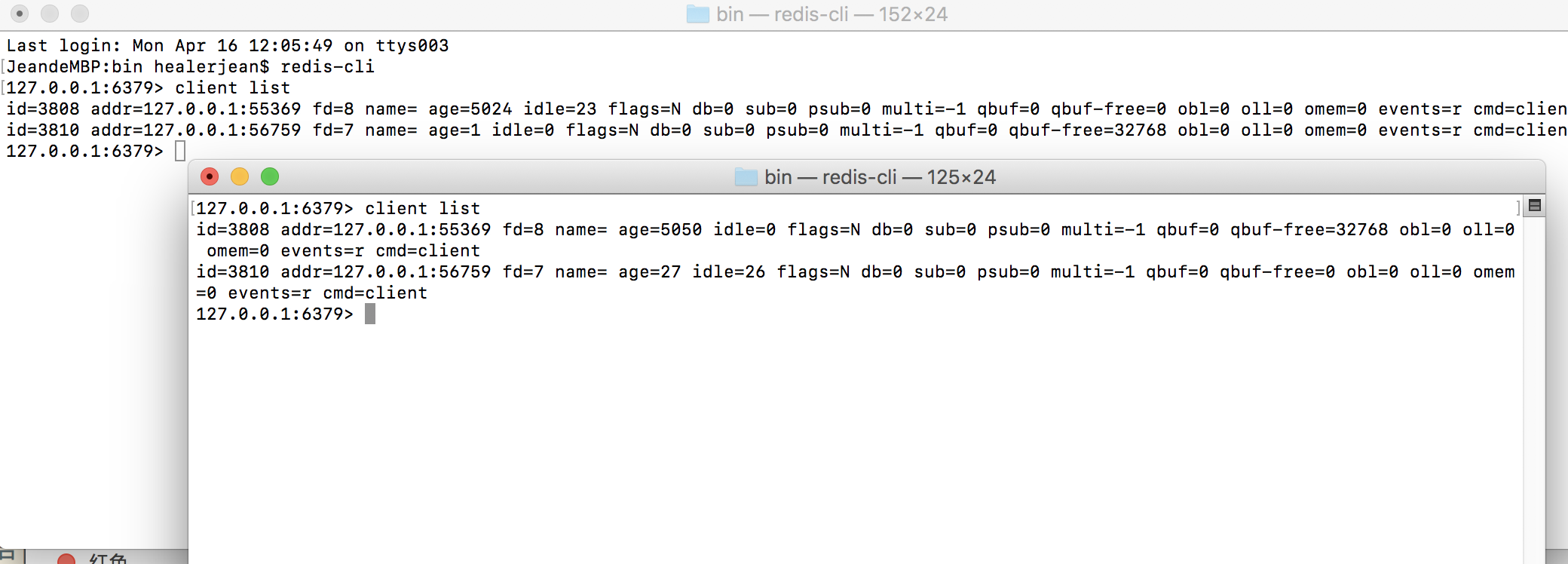
这里我同一个redis开启了两个客户端
127.0.0.1:6379> client list
id=3808 addr=127.0.0.1:55369 fd=8 name= age=5050 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
id=3810 addr=127.0.0.1:56759 fd=7 name= age=27 idle=26 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=client解释下信息:
(1)标识、
id 客户端连接的唯一标识
addr 客户端链接的ip和标识
name 客户端的名字(2)输入缓冲区
redis为每个客户端分配了输入缓冲区,它的作用是将客户端发送的命令临时保存,同时Redis会从缓冲区拉去命令并执行,输入缓存区为客户端发送命令到Redis提供了缓存功能。
输入缓冲区会根据输入内容的大小而动态调整,只是要求缓冲区的大小不超过1G,超过后客户端将关闭
qbuf 输入缓冲区总容量
qbuf-free 输入缓冲区剩余容量
1、输入缓冲区使用不当会产生两个问题
1、一旦某个输入缓冲区大小超过1G,客户端将会被关闭。
2、输入缓冲区不受maxmemory控制,加上一个Redis实例上得知了maxmemory为4G,已经存储了2G数据,但是如果此时输入缓冲区使用了3G。已经超过maxmemory限制,可能会产生数据丢失,键值淘汰、OOM(内存泄漏)
2、那么造成缓冲区过大的原因
1、Redis的处理速度跟不上输入缓冲区的输入速度,并且每次进入缓冲区的命令包含了大量bigkey
2、Redis发生了阻塞,短期内不能处理命令,造成客户端输入的命令积压在缓冲区
3、如何快速发现和监控
1、通过定期执行client list命令,手机qbuf和qbuf-free找到异常的连接记录并分析,最终找到可能出问题的客户端
2、通过info命令的info clients模块,找到最大的输入缓冲区client_biggest_input_buf:0,例如,可以设置10M就开始报警
127.0.0.1:6379> info clients
# Clients
connected_clients:2
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
127.0.0.1:6379>
| 命令 | 优点 | info clients |
|---|---|---|
| client list | 能精准分析每个客户端来定位问题 | 执行速度较慢,尤其是在连接数较多的情况下,频繁执行可能阻塞Redis |
| info clients | 执行速度比client list快,分析过程较为简单 | 不能精准定位到客户端,不能显示所有输入缓冲区的总量,只能显示最大量 |
(3)输出缓冲区
redis为每个客户端分配了输出缓冲区,它的作用是保存命令执行的结果返回给客户端。
与输入缓冲区不同,它的容量是可以通过参数配置的,。并且按照客户端的不同分为三种,普通客户端,发布订阅客户端,slave客户端。
<class> 客户端缓冲区超过<hard limit> ,客户端会立即关闭;如何客户端缓冲区的输出缓冲区超过了<soft limit> ,并且持续了 <soft secontds>秒,客户端会被立即关闭
默认
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 8mb 2mb 60
相同的是,它的大小不会受到maxmemory的限制,^,也会造成数据丢失,键值淘汰,OOM等情况。
1、输出缓冲区的组成
实际上输出缓冲区由两部分组成,固定缓冲区和动态缓冲区,其中固定缓冲区返回比较小的执行结果,而动态缓冲区返回比较大的结果,例如大的字符串,hgetall,smembers 命令的结果。
固定缓冲区使用的是字节数组,动态缓冲区使用的是列表。当固定缓冲区存满后会将Redis新的返回结果存放到动态缓冲区的队列中。队列中每个对象就是每个返回结果
obl 固定缓冲区的长度
oll 动态缓冲区的长度
omen 使用的字节数 举例
下面表示为固定缓冲区长度为0,动态缓冲区有4869个对象,两个部分共使用了133081288字节=126M内从
obl=0 oll=4869 omem=1330812882、监控输出缓冲区的方法
1、定期执行client list 模块命令,手机……
2、通过info命令的info clients模块,找到输出缓冲区列表的最大对象数client_longest_output_list
127.0.0.1:6379> info clients
# Clients
connected_clients:2
client_longest_output_list:0
client_biggest_input_buf:0
blocked_clients:0
127.0.0.1:6379> 3、发现和预防输出缓冲区出现异常
1、进行上述监控,设置阀值及时处理
2、限制普通客户端输出缓冲区参数的<hard limit> <soft limit > ,<soft seconds>,把错误扼杀在摇篮中,例如可以进行如下设置
client-output-buffer-limit normal 20mb 10mb 1203、适当增大slave的输出缓冲区的<hard limit> <soft limit > ,<soft seconds>,如果master节点写入较大,slave客户端的输出缓冲区可能也会比较大,一旦slave客户端链接因为输出缓冲区溢出而别杀死,会造成重复重连
(4)客户端的存活状态
age=27 客户点已经链接的时间 ,连接redis的时间为27秒
idle=26 最近一次的空闲时间 redis空闲了26秒
1、异常分析
1、当Redis连接的时间等于空闲时间的时候,就说明连接一直处于空闲,这种情况就是不正常的
正常情况下当,当再次使用jedis的时候,idle会再次重新从0开始计数
(5)客户端的限制macclients和timeout
1、查看maxclients和timeout属性值
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "10000" //默认10000
127.0.0.1:6379> config get timeout
1) "timeout" //默认是0
2) "0"
127.0.0.1:6379>
2、maxclients maxTotal
Redis提供了maxclients参数来限制最大客户端连接数,一旦超过maxclients,新的连接将会被拒绝。maxclients默认值是10000,可以通过info clients来查看当前的连接数
127.0.0.1:6379> info clients
# Clients
connected_clients:2 //当前的连接数
client_longest_output_list:0 //客户端输出缓冲区列表最大对象数
client_biggest_input_buf:0 //客户端输入缓冲区最大值
blocked_clients:0
127.0.0.1:6379>
3、timeout
一般情况下来说maxclients=10000在大部分场景已经绝对够用,但是某些情况由于业务方使用不当,例如,没有主动关闭连接,可能存在大量的idle空闲连接,无论是从网络连接成本还是超过maxclients的后果来说都不是什么好事,因此Redis提供了一个timeou来限制最大空闲连接,一旦空闲连接超过了timeout,连接将会被关闭
举例下面设置最大空闲时间设置为30秒将会抛出异常
public void testString() throws InterruptedException {
Jedis jedis = new Jedis("127.0.0.1",6379);
//-----添加数据----------
jedis.set("name","xinxin");//向key-->name中放入了value-->xinxin
System.out.println(jedis.get("name"));//执行结果:xinxin
TimeUnit.SECONDS.sleep(31);
System.out.println(jedis.ping());
}
xinxin
Exception in thread "main" redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream.
at redis.clients.util.RedisInputStream.ensureFill(RedisInputStream.java:199)
at redis.clients.util.RedisInputStream.readByte(RedisInputStream.java:40)
at redis.clients.jedis.Protocol.process(Protocol.java:151)
at redis.clients.jedis.Protocol.read(Protocol.java:215)redis给出timeout的默认值是0,永不超时,就是说,及时空闲也不会断掉,在这种情况下客户端基本不会出现上面的异常,这是基于对客户端开发的一种保护,但是在JedisPool时不会对连接池对象做空闲检测和验证,如果设置了timeout大于0(这样就可能渠道已经过时的JedisPool),可能就会出现上面的异常,如果Redis的客户端使用不当,没有及时释放,后果很严重
解决方法:
可以将timeout设置为300秒,同事客户端加上空闲检测和验证等措施
| 参数名字 | 内容 | 默认值 |
|---|---|---|
| minEvictableIdleTimeMillis | 连接的最小空闲时间,达到这个值后空闲连接将被移除timeBetweenEvictionRunsMillis大于0时才有意义; | 默认30分钟 |
| timeBetweenEvictionRunsMillis | 空闲检测周期(单位毫秒) | -1,表示永不检测 |
| testWhileIdle | 向连接池借用连接时是否做连接空闲检测,空闲超时的连接将会被移除 | false |
(6)、客户端类型
addr : 客户端的地址和端口
fd : 套接字所使用的文件描述符
age : 以秒计算的客户端已连接时长
idle : 以秒计算的空闲时长
flags : 客户端 flag
db : 该客户端正在使用的数据库 ID
sub : 已订阅频道的数量
psub : 已订阅模式的数量
multi : 在事务中被执行的命令数量
qbuf : 查询缓冲区的长度(字节为单位, 0 表示没有分配查询缓冲区)
qbuf-free : 查询缓冲区剩余空间的长度(字节为单位, 0 表示没有剩余空间)
obl : 输出固定缓冲区的长度(字节为单位, 0 表示没有分配输出缓冲区)
oll : 输出动态列表包含的对象数量(当输出缓冲区没有剩余空间时,命令回复会以字符串对象的形式被入队到这个队列里)
omem : 输出缓冲区和输出列表占用的内存总量
events : 文件描述符事件
cmd : 最近一次执行的命令
<font color="red">cmd : 最近一次执行的命令</font>
4、客户端命名、杀死、暂停
1、命名
这样比较容易标识出客户端的来源
127.0.0.1:6379> client setName clent1
127.0.0.1:6379> client getName
"client1"
127.0.0.1:6379>
观察下面的name
127.0.0.1:6379> client list
id=3818 addr=127.0.0.1:62540 fd=7 name= age=4 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
127.0.0.1:6379> client setName clent1
OK
127.0.0.1:6379> client list
id=3818 addr=127.0.0.1:62540 fd=7 name=clent1 age=15 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
127.0.0.1:6379>
2、杀死指定ip地址和端口的客户端
client kill 127.0.0.1:62569127.0.0.1:6379> client list
id=3819 addr=127.0.0.1:62555 fd=7 name=client1 age=153 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=client
id=3820 addr=127.0.0.1:62569 fd=8 name= age=102 idle=102 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=client
127.0.0.1:6379> client kill 127.0.0.1:62569
OK
127.0.0.1:6379> 3、客户端暂停阻塞
127.0.0.1:6379> client pause 10000
……使用范围:只对普通发布者和订阅发布者有效,对于主从复制是无效的,生产环境中成本非常高
4、monitor 用于监控Redis正在执行的命令
另一个客户端B输入命令,则客户端A,monitor可以监听到正在执行的命令,并且记录了详细的时间戳
打开两个客户端,一个客户端A输入 monitor
127.0.0.1:6379> monitor
^
另一个客户端B输入命令,则客户端A可以监听到正在执行的命令,并且记录了详细的时间戳
客户端B
127.0.0.1:6379> keys *
1) "name"
2) "count"
3) "age"
4) "hello"
5) "qq"
127.0.0.1:6379> set m girl
OK
127.0.0.1:6379>
客户端A
127.0.0.1:6379> monitor
OK
1523876898.815455 [0 127.0.0.1:62628] "keys" "*"
1523876908.519187 [0 127.0.0.1:62628] "set" "m" "girl"
每个客户端都有自己的输出缓冲区,既然monitor能监听到所有的命令,则一旦并发量过大,则monitor的输出缓存就会暴涨,瞬间占用大量内存
5、客户端常见异常分析,从源头上找
5.1、无法从连接池池获取到连接
could not get a resourse1、Jedis连接池连接个数是有限的,默认是8个,这里假设使用的默认配置,如果有8个对象被占用,并没有归还,此时还要借用,就需要等待(如果设置了maxWaitMIlls>0),如果超时,则会发生异常
2、连接池设置数量过小,并发量太大,8个也不够用
3、没有正确使用连接池,使用了8次,都没有释放
4、存在慢查询操作,这些慢查询持有的Jedis对象归还速度会比较慢,造成池子满了
5.2、客户端读写超时
Read time out1、读写超时时间设置过段,
2、命令本身比较慢
3、网络连接不正常(我的代码就是)
4、Redis自身发生阻塞
5.3、客户端链接超时
Connect time out1、设置超时时间过短,
2、网络不正常
3、Redis发送阻塞
5.4、客户端缓冲区异常
unexpected end of stream1、输出缓冲区满,例如将普通客户端的输出缓冲区设置成了 1M 1M 60,
2、不正常的并发读写,Jedis对象呗多个线程并发操作
5.5、客户端连接数过大
如果客户端连接数超过了maxclients,就会抛出异常,遇到这个问题就麻烦了,因为肯定是不能再输入命令进行修复了
1、客户端方面,如果应用方是分布式结果的话,下线部分应用节点。让Redis连接数降下来,再通过查找程序bug或者调整maxclients进行修复
2、服务端,使用高可用模式主从复制和集群,将当期Redis做故障转移
6、客户端案例分析
Redis内存陡增
1、现象
服务端现象 :Redis主节点内存陡增,几乎用满maxmemory,而从节点没有变化(主从复制,内存使用主从节点基本相同)
客户端现象:客户端产生了OOM,也就是Redis主节点使用的内存已经超过了maxmemory,无法写入新的数据
2、原因
1、确实有大量写入 ,通过查看主节点的dbseze和从节点的dbsize相同
2、输出缓冲区数量数量过大,造成内存陡增
1、查看到输出缓冲区数量过大
127.0.0.1:6379> info clients
# Clients
connected_clients:2
client_longest_output_list:225698
client_biggest_input_buf:0
blocked_clients:0
127.0.0.1:6379>
发现输出缓冲区的队列已经超过了20万个对象2、通过 client list 找到不正常的连接,一般来说大部分客户端的omem(输出缓存区占用字节为0,以为其他的客户端都已经执行完事了),通过下面的查找发现最后一次执行的命令是monitor,很明显就知道是通过monitor造成的
redis-cli client list | grep -v “omem=0”
id=3822 addr=127.0.0.1:64244 fd=7 name= age=0 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=224551255844 events=r cmd=monitor
3、处理方法
只要使用 client kill就可以杀掉这个连接,但是我们以后如果及时发现并且避免
1、禁止在生成环境中使用monitor命令
2、限制输出缓冲区的大小
2、客户端周期性超时
redis.clients.jedis.exceptions.JedisConnectionException
java.net.SocketException :connect time out
通过慢查询查看时间点,就可以判断出是哪里出了问题
解决方法:运维层面,监控慢查询,一旦超过阀值,就发出报警,开发层面看,加强对Redis的理解,避免不挣钱的使用方式
如果满意,请打赏博主任意金额,感兴趣的请下方留言吧。可与博主自由讨论哦
| 支付包 | 微信 | 微信公众号 |
|---|---|---|
 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号