
8、Redis阻塞
前言
通过前面那么多我们这里应该很明确知道Rdis单线程结构,在高并发的时候,如果出现阻塞,哪怕是很短时间,都将会是异常噩梦
1、发现阻塞
当Redis阻塞发生的时候,线上应用服务应该最先感知到,这个是,应用房,会收到大量的Redis超时异常,常见的作坊是通过邮件,短信预警。借助于日志系统可以查看异常信息。以及借助Redis监控系统发现阻塞问题
2、内在原因
上面是定位到Redis异常节点后,首先应该排除是不是redis自身原因导致
2.1、API或者数据结构使用不合理
例如,hgetall 包含了成千上万个数据,势必会引发阻塞。不过这种是我们在项目中可以避免的使用hscan ,一般情况下标题的这种情况的发送,是慢查询或者是大对象。
2.1.1、如何发现慢查询
之前我们说过,默认执行超过10毫秒的,会被记录到定长的队列中,显示实际建议即使发现毫秒级以上的命令,如果命令执行时间在毫秒级别。
slowlog get n(n代表最近n条慢查询命令) 发现慢查询后,可以按照下面两个方向去调整
1>修改为低算法命令,如hgetall改为hmget,禁用keys,sort等命令
2>调整大对象,缩减大对象活把大对象拆分为多个小对象。防止一次命令操作度过多的数据
2.1.2、如果发现大对象
redis本身提供发现大对象的工具,对应命令如下,内部原理是采用scan操作。将历史扫描过的最大对象统计出来便于优化,根据汇总结果可以非常方便的获取到最大对象的键,以及不同类型数据结构的使用情况
redis-cli -p 6379 -h 127.0.0.1 --bigkeysJeandeMBP:src healerjean$ redis-cli -p 6379 -h 127.0.0.1 --bigkeys
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far 'hello' with 5 bytes
-------- summary -------
Sampled 1 keys in the keyspace!
Total key length in bytes is 5 (avg len 5.00)
Biggest string found 'hello' has 5 bytes
1 strings with 5 bytes (100.00% of keys, avg size 5.00)
0 lists with 0 items (00.00% of keys, avg size 0.00)
0 sets with 0 members (00.00% of keys, avg size 0.00)
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
0 zsets with 0 members (00.00% of keys, avg size 0.00)
JeandeMBP:src healerjean$ 2.2、CPU饱和
单线程的Redis处理命令只能使用一个CPU,CPU饱和是非常危险的,首先判断当前Redis的并发量是否达到极限。
redis-cli --stat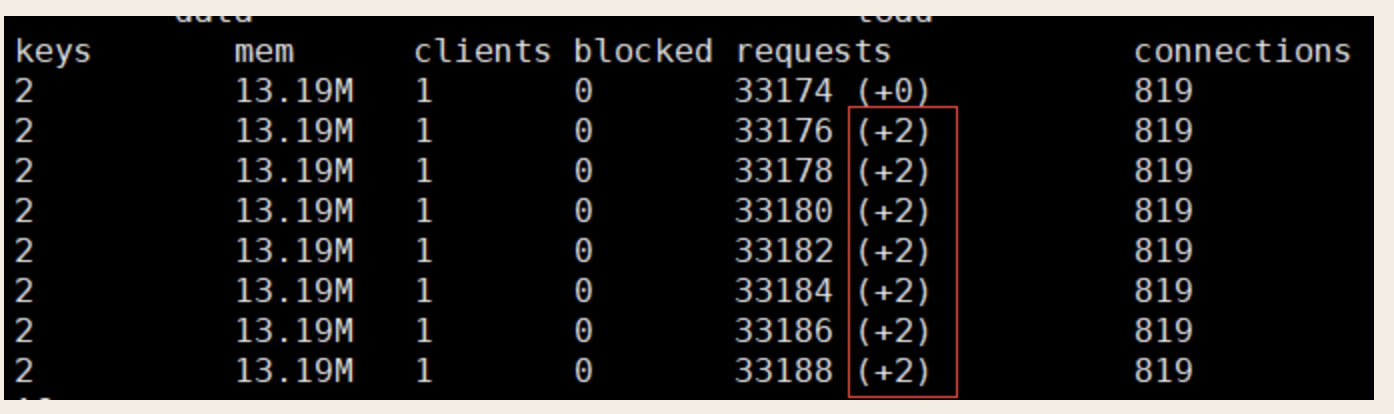
解释:
+为每秒处理请求
2.3、持久化阻塞
2.3.1、fork阻塞
在RDB和AOF重写的时候,Redis主线程调用fork操作产生共享内存的子进程,由于进程完成持久化文件重写工作,如何fork操作本身耗时过长,必然会导致主线程的阻塞。表示最近一次fork的操作耗时,如果耗时很大,比如超过1秒,则需要作出优化调整。info stats
latest_fork_usec:658127.0.0.1:6380> info stats
# Stats
total_connections_received:1
total_commands_processed:2421
instantaneous_ops_per_sec:0
total_net_input_bytes:34608
total_net_output_bytes:915107
instantaneous_input_kbps:0.00
instantaneous_output_kbps:0.04
rejected_connections:0
sync_full:0
sync_partial_ok:0
sync_partial_err:0
expired_keys:0
evicted_keys:0
keyspace_hits:1
keyspace_misses:0
pubsub_channels:0
pubsub_patterns:0
latest_fork_usec:658
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
127.0.0.1:6380>
2.3.2、AOF刷盘阻塞
当我们开启AOF持久化功能的时候,文件刷盘的方式一般采用每秒一次,当硬盘压力过大的时候,fsync操作需要等待,知道写入完成。info persistence
127.0.0.1:6380> info persistence
# Persistence
loading:0
rdb_changes_since_last_save:0
rdb_bgsave_in_progress:0
rdb_last_save_time:1523958029
rdb_last_bgsave_status:ok
rdb_last_bgsave_time_sec:0
rdb_current_bgsave_time_sec:-1
rdb_last_cow_size:0
aof_enabled:0
aof_rewrite_in_progress:0
aof_rewrite_scheduled:0
aof_last_rewrite_time_sec:-1
aof_current_rewrite_time_sec:-1
aof_last_bgrewrite_status:ok
aof_last_write_status:ok
aof_last_cow_size:0
127.0.0.1:6380>
2、外在原因
2.1、CPU竞争
1、进程竞争:Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务部署到一起,当其他进程过度消耗CPU的时候,将严重影响Redis
2、绑定CPU:对于开启持久化或者复制的主节点不建议绑定CPU。否则父进程和子进程就会相互竞争
2.2、内存交换
Redis保持高性能最重要的一个原因是它的数据保存到内存中,如果保存一部分到硬盘上,会由于读写速度相差太大而出现很大的问题:
查看redis进程号info server
process_id:8313通过进程号查找 cat /proc/8313/smaps | grep Swap
如果Swap都是0Kb或个别是4kb,则是正常现象,说明Redis进程内存没有被交换。
127.0.0.1:6380> info server
# Server
redis_version:4.0.8
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:ad83a037ffc67071
redis_mode:standalone
os:Darwin 16.7.0 x86_64
arch_bits:64
multiplexing_api:kqueue
atomicvar_api:atomic-builtin
gcc_version:4.2.1
process_id:8313
run_id:d2099de68745a3bba3c7643535a5a47a8957f18b
tcp_port:6380
uptime_in_seconds:82858
uptime_in_days:0
hz:10
lru_clock:14083679
executable:/usr/local/redis-4.0.9_2/src/redis-server
config_file:/usr/local/redis-4.0.9_2/redis.conf
127.0.0.1:6380> 2.3、网络问题
2.3.1、连接拒绝
如果满意,请打赏博主任意金额,感兴趣的请下方留言吧。可与博主自由讨论哦
| 支付包 | 微信 | 微信公众号 |
|---|---|---|
 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号