

VGG的迁移学习
原代码运行

生成数据集中图片顺序不是1-20000顺序的。
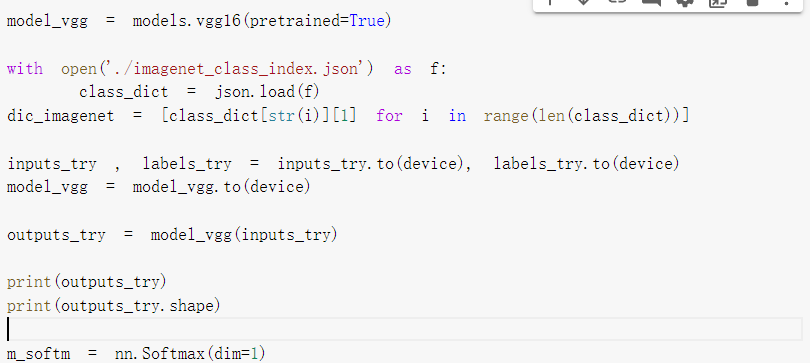
载入了预训练的权重,引入softmax模块
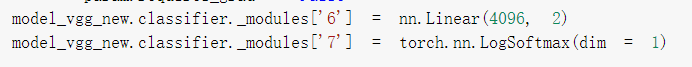
改分类输出,适应数据集
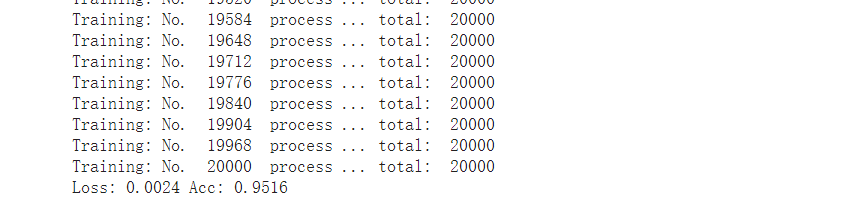
训练结果
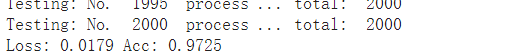
验证集运行结果

可视化检查
迁移学习
由于线上跑有点慢,在本地跑的
为了依然能使用torvhvision中的imagefolder方法,在test文件夹下建了一个新的文件夹
loader_test=torch.utils.data.DataLoader(dsets['test'], batch_size=1, shuffle=False, num_workers=0)
建立相应的dataloader实例
import xml.etree.ElementTree as ET
from os import getcwd
import os
wd = getcwd()
filesbox = os.listdir('cat_dog/test/cat')
filesid = [i[:-4] for i in filesbox]
list_file = open('train_retinex.txt', 'w')
for image_id in filesid:
list_file.write('%s'%(image_id))
list_file.write('\n')
list_file.close()
为了解决在dataset中图片并非1-2000顺序的问题,我们将文件顺序存在了train_retinex.txt文件中。
index=[]
kiss=open("train_retinex.txt")
for ki in kiss:
fu=ki.replace('\n','')
fu=fu.replace(' ','')
ah=int(fu)
index.append(ah)
在main.py中读取文件中的内容并存在index列表中。
model_vgg_new.eval()
ans = [0 for _ in range(2000)] #也可以b = [0]*10
ints=0
for inp,cla in loader_test:
inp = inp.to(device)
cla = cla.to(device)
outputs = model_vgg_new(inp)
_, preds = torch.max(outputs.data, 1)
pud=preds.to('cpu').numpy()
for kpp in pud:
ans[index[ints]]=kpp
ints=ints+1
ints=0
list_file = open('ans.csv', 'w')
cnt=0
for i in ans:
jj=str(cnt)
ii=str(i)
#ans =jj+","+ii+"\n"
list_file.write(jj)
list_file.write(',')
list_file.write(ii)
list_file.write('\n')
cnt=cnt+1
list_file.close()
按dataset中的顺序进行预测,但在ans数组中按index中的下标存储并写入ans.csv中。

提交结果
在该任务中,在建个ResNet,GoogleNet,再一起vote应该会有不小的提升
