Simple Neural Network Practice
1.代码截图
import matplotlib.pyplot as plt
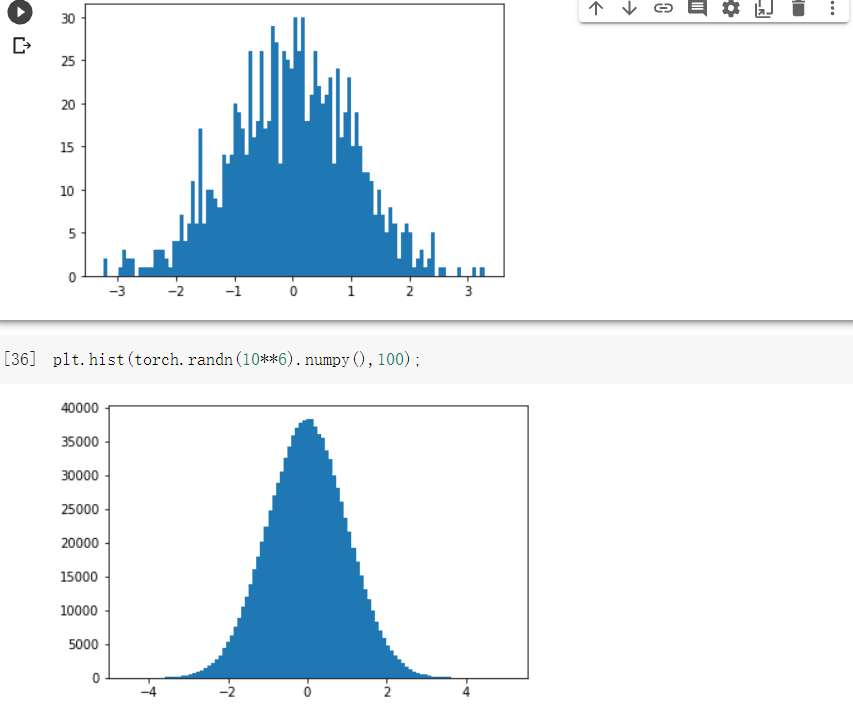
plt.hist(torch.randn(1000).numpy(),100)
plt.hist(torch.randn(10**6).numpy(),100);
learning_rate = 1e-3
lambda_l2 = 1e-5
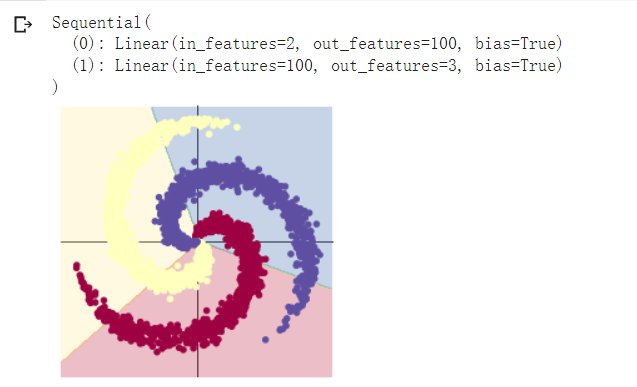
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(model)
plot_model(X, Y, model)
learning_rate = 1e-3
lambda_l2 = 1e-5
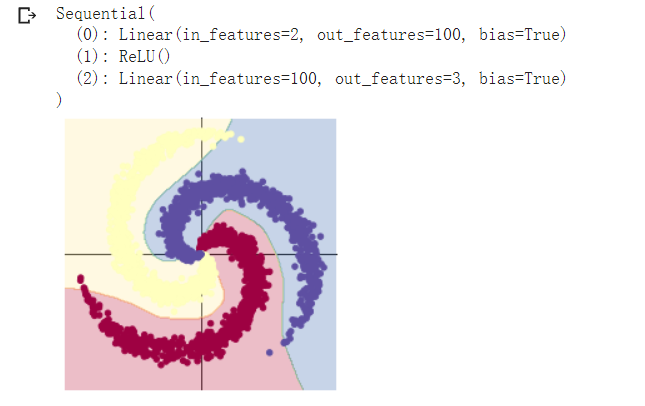
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(model)
plot_model(X, Y, model)
2.运行截图

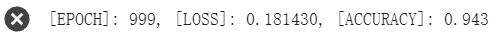
3.感想
由于现实中多是非线性的关系,线性模型往往不能有很好的拟合。引入epoch在规模不大的网络上有效避免了欠拟合。
对于简单的问题,往往不需要大规模的复杂网络。GPU计算效率远高于CPU的计算效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号