Spark使用踩坑完全(并不)指南
1.java编译报错
错误
Error: A JNI error has occurred, please check your installation and try again
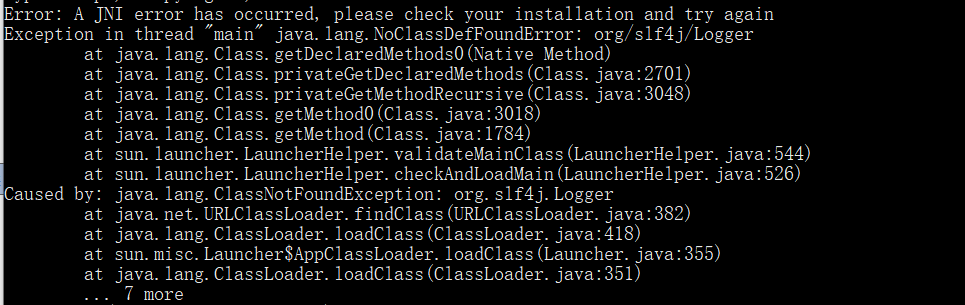
👆下面还有其他报错但我没有截到,但问题的原因都是这个👆
这个错误一般情况是由于java 版本 与javac 版本不同所导致的报错,即在cmd命令下分别使用java -version和javac -version得到的版本号是不一样的
如果你是这种原因的话,使用旧版本java卸载工具将旧版本卸载即可
但是!!! 我们(我)并没有用这种办法解决问题QAQ
所以我的问题在于Hadoop的JAVA_HOME版本设置未更改,关于Hadoop的JAVA_HOME修改可以参考:
编辑文件C:\Hadoop\etc\hadoop\hadoop-env.cmd,将语句:
“set JAVA_HOME=%JAVA_HOME%”
修改为“set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_192”。
(注意:此处有坑。如果将hadoop-env.cmd中的JAVA_HOME设置为“C:\Program Files\Java\jdk1.8.0_192”,将会出错,因为路径中不能含有空格。)
但但但是!!我的问题依然没有解决,那么咋办呢?
修改spark的启动脚本就可以了!,具体位置在:
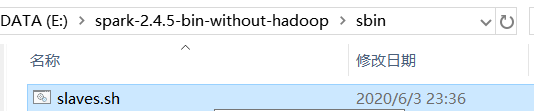
修改slaves.sh文件,在文件的顶端添加:
# 解决方法:
在启动脚本最前边添加系统参数,指定Java版本
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/jre //这里使用你自己的JAVA_HOME
就可以了!
常用函数
其实spark的开发过程除了一开始的配置过程以外的编程还比较简单,尽在这里列出一些自己用过的函数,粗浅至极,仅仅作为自己学习的记录,如有错漏之处还希望看到的各位能留言指正
RDD.map(func)
'''
对于RDD类型的数据,将每一组数据出入函数,根据你的函数的返回值进行map,在你的函数func里你可以返回一个元组(KEY,VALUES),如果你不太明白这里的KEY和VALUES的意思的话我建议可以先从
MapReduce的原理了解一下,然后map()函数会返回一个迭代器,这里你可以使用.collect()将迭代器输出为list对象
'''
RDD.flatmap(func)
'''
与map方法类似,不过flatmap方法会将输入的数据全部按照某钟方式分开,返回一些“碎片”,譬如你输入了一行"1 ,2 , 3, 4, 5"经过faltmap(lambda line: line.split(","))返回的可能就是[1 2 3 4 5]的列表
'''
RDD.reduceByKey(func)
'''
这里我理解的也也较模糊,reduceByKey()函数与原来的Reduce函数的区别似乎在于reduceByKey()在每次找到相同的KEY不是进行聚合而实返回两个相同的组的VALUE进行计算,好处是这样可以提高计算速度,坏处显而易见,对于某些操作比较繁琐,例如求平均值,同样也是在func的位置定义自己的具体操作函数
'''
RDD.groupByKey()
'''
这个函数就更类似于原始的Reduce函数,返回的是一个(KEY,VALUES),这里的VALUES是所有的KEY相同的值的集合,那么你就可以很方便的进行对于数据的处理了!,缺点也很明显,在处理大量数据时效
率低
'''
# 未完待续,如果我有时间应该回继续写吧,大概(2020.06.10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号