数据挖掘--复杂网络社团检测代码
聚类技术---复杂网络社团检测
一、实验内容
复杂网络是描述复杂系统的有力工具,其中每个实体定义成一个节点, 实体间的交互关系定义为边。复杂网络社团结构定义为内紧外松的拓扑结构, 即一组节点的集合,集合内的节点交互紧密,与外界节点交互松散。
- 导入karate.gml中的空手道网络数据;
- 根据网络结构特征给出节点相似性度量指标;
- 采用层次聚类过程对网络数据进行聚类;
- 计算模块性指标Q值,当Q值最大时输出聚类结果;
- 采用Cytoscape工具,可视化聚类结果。
二、实验分析与设计
-
导入karate.gml中的空手道网络数据;
利用 igraph 库中的 get_edgelist()函数,取出所有边的列表, 遍历列表计算出数据集的邻接矩阵 A。若𝐴𝑖𝑗 = 1则表示数据集中点 i 和点 j 之间存在一条边
-
根据网络结构特征给出节点相似性度量指标;
给定节点 i,其邻居节点定义为与该节点相连接的所有节点组成
的集合,即N(i) = {𝑗|𝐴𝑖𝑗 = 1,𝑗 = 1,2,…𝑚}。给定一对节点(𝑖 , 𝑗),其 相似性定义为这两个节点的公共邻居节点与邻居节点的并的比值,即:\[similar_{ij}=\frac{|N(i)\cap N(j)|}{|N(i)\cup N(j)|} \]其中相似度度量的分子为两节点邻居节点的交集,分母为两节点邻居节点的并集的元素个数
-
根据相似度矩阵计算不同种类社团的Q值
定义模块度量值为:
\[Q_i={\frac{Q_{real}-Q_{null}}{M}}=\frac{1}{2M}\sum_{ij}(a_{ij}-\frac{k_ik_j}{2M})\delta(C_i,C_j) \]其中
\[M=给定的网络中的边的数量 \]\[k_i,k_j为节点node_i的degreed(度) \]\[\delta(C_i,C_j),如果Ci和C_j属于同一个划分,\delta(C_i,C_j)=1,否则=0 \]\[A=[a_{ij}]为邻接矩阵,所以a_{ij}为邻接矩阵内的值 \] -
采用层次聚类过程对网络数据进行聚类,计算模块性指标Q值,当Q值最大时输出聚类结果
聚类算法步骤:
- 将所有的节点看作一个单独的簇
- 遍历similar矩阵,得到相似度最高的两个簇
- 选取最高相似度,检测最高相似的是否高于某个阈值,如果是就结束聚类输出结果(步骤5)
- 将相似度最高的两个簇合并,并更新similar矩阵,将合并的两个簇中的最小的similar值更新为新的簇的值(MAX全链),记录合并的簇
- 计算模块度量值Q,如果Q值大于当前最大值则输出分类
-
采用Cytoscape工具,可视化聚类结果。
三、具体实现
-
利用 igraph 库函数 get_edgelist()导入 karate.gml 数据集,设 m 为数据 集中节点个数,n 为数据集中边的条数。neighbors 为各个节点的邻居 节点的集合列表。之后计算邻接矩阵 A,设置两层 for 循环来遍历所有 节点,若第 i 个节点的邻居节点中有节点 j,则令A[i, j] = 1,且有 A[j, i] = 1。
def compute_A(): A = np.zeros((m, m), dtype=np.int) for i in range(m): for j in range(m): if i == j: break if j in neighbors[i]: A[i][j] = 1 A[j][i] = 1 return A计算的得到的邻接矩阵为:
-
根据数据集的节点个数m,建立一个m*m大小的矩阵存放相似度,同时维护两个 _list P_和_Q_分别存放节点的邻居节点的交集和并集,遍历两个节点的邻居节点,将其交集和并集的结果存放到 _list P_和_Q_中,最后将由_P_和_Q_计算得到的𝑠𝑖𝑚𝑖𝑙𝑎𝑟,分别将其存放到矩阵的[i, j]及其对称点[j, i],是的相似度矩阵成为对称矩阵
def similarity(): # 计算相似度 similar = np.zeros((m, m), dtype=np.float) for i in range(m): for j in range(m): p = [] q = [] for k in range(m): if(i in neighbors[k] and j in neighbors[k]): p.append(k) if(i in neighbors[k] or j in neighbors[k]): q.append(k) l1 = len(p) l2 = len(q) similar[i][j] = l1/l2 similar[j][i] = l1/l2 print('similar矩阵:\n', similar) return similar -
根据相似度矩阵进行层次聚类,这里采用全链聚类,全链聚类比单链聚类更是适合于现实问题,对离群点和噪声更不敏感,同时更新相似度矩阵,进行一次分类,返回合并的两个簇x ,y(这里的x y 为要合并的两个簇的某个节点,用这两个节点更新簇的集合)
# ----------------------层次聚类函数--------------------------------------# def cluster(sim): m = len(sim) max_s = 0 x = 0 y = 0 # 选出最大相似度 for i in range(m): for j in range(m): if(sim[i][j] > max_s): x = i y = j max_s = sim[i][j] # 全链算法更新相似度矩阵 for i in range(m): sim[x][i] = min(sim[x][i], sim[y][i]) sim[y][i] = min(sim[x][i], sim[y][i]) return x, y -
计算模块化量值Q并与阈值进行比较,输出完成聚类的簇,设分类标签_clusters_为一维List,clusters[i]的值表示节点__i__属于簇__clusters[i]__,初始将clusters置为-1,表示所有的点都未分类
同时对于模块化量值Q的计算,利用sum_cluster和counter 进行计算
# -------------------------模块化度量值----------------------------------# def init_compute_clusters(clusters, m): # 初始化clusters列表,将clusters的每一位置为-1,表示未分类 for i in range(m): clusters.append(-1) return clusters # 模块度Q计量 def compute_Q(f, adjacency): Q = 0 for i in range(M): for j in range(M): if f[i] == f[j]: Q += (adjacency[i][j]-(k[i]*k[j]/(2*N)))/(2*N) else: Q += 0 Q_list.append(Q) return Q -
主函数负责定义初始变量及对聚类函数返回的x ,y 值进行聚类更新及clusters聚类标签的更新
# -------------------------主函数-----------------------------------# A = compute_A(M) similar = similarity(M) clusters = [] cluster_complete = [] clusters = init_compute_clusters(clusters, M) i = 0 flag = 0 Q = 0 q_max = -1 while(i < 100): x, y = cluster(similar) if clusters[x] != -1 and clusters[y] != -1: # x,y都已经分类,则将x, y的聚类合并成为一个,这里采用合并树的思想,将相同簇的节点遍历并进行修改 temp = clusters[y] for j in range(M): if clusters[j] == temp: clusters[j] = clusters[x] if clusters[x] == -1 or clusters[y] == -1: # 两个簇中至少有一个未分类 if clusters[x] == -1 and clusters[y] == -1: # 两个簇都未分类 flag += 1 # 新建一个分类保存此簇 clusters[x] = clusters[y] = flag elif clusters[x] == -1: # x未分类y已分类,将x并到y上去 clusters[x] = clusters[y] elif clusters[y] == -1: # x已分类y未分类,将y并到x上去 clusters[y] = clusters[x] Q = compute_Q(clusters, A) if(Q > q_max): # 输出Q值最大的情况的分类 outputData(clusters, edgelist) q_max = Q print(clusters) i += 1 draw() -
输出函数,将分类与无向图分别保存在graph.csv和class.csv并输出
def outputData(clusters, edges): # 输出无向图的连接关系,输出分类结果 edge_out = [] graph_file = data_source+'grafh.csv' name1 = ['nodea', 'edgetype', 'nodeb'] for edge in edges: edge_out.append((edge[0]+1, 1, edge[1]+1)) out1 = pd.DataFrame(columns=name1, data=edge_out) out1.to_csv(graph_file) attribute_file = data_source+'class.csv' name2 = ['node', 'class'] attribute_out = [] for i in range(1, M+1): attribute_out.append((i, clusters[i-1])) out2 = pd.DataFrame(columns=name2, data=attribute_out) out2.to_csv(attribute_file) -
画图函数
# ---------------------画图函数------------------------------------# def draw(): plt.figure(1) plt.plot(range(len(Q_list)), Q_list, color="b", linewidth=2) plt.xlabel('merge times') plt.ylabel("Q") plt.scatter(range(len(Q_list)), Q_list, linewidths=3, s=3, c='b') f1 = plt.gcf() plt.show()
四、实验结果
未分类前的karate节点数据:
最终分类结果:
[9, 9, 9, 9, 4, 4, 4, 9, 3, 3, 4, 9, 9, 9, 3, 3, 4, 9, 3, 9, 3, 9, 3, 3, 5, 5, 3, 3, 3, 3, 3,
5, 3, 3]
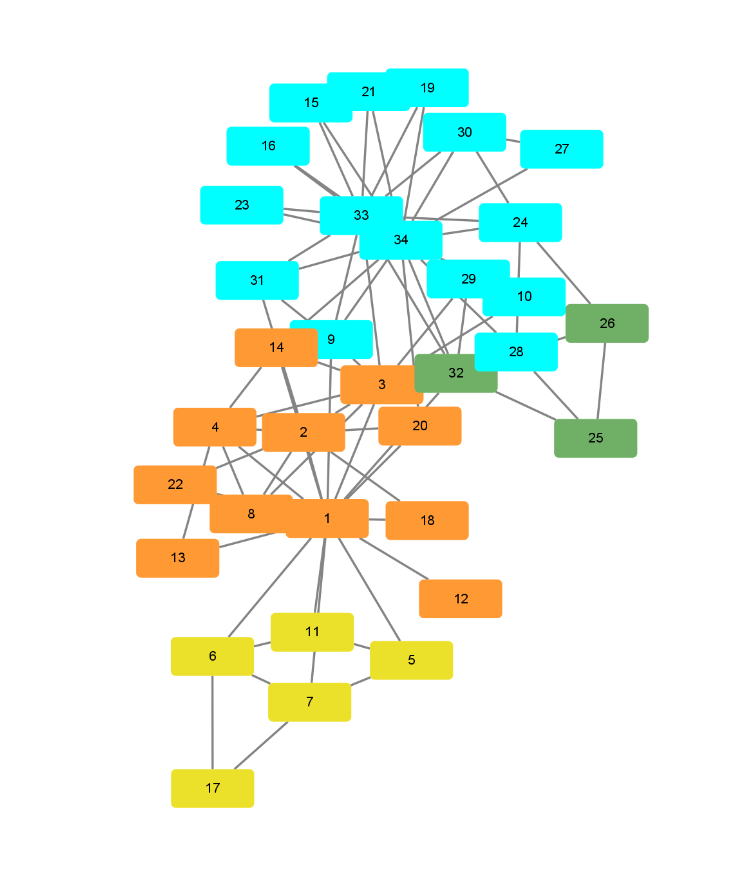
分类后的簇(使用cytoscape进行可视化)
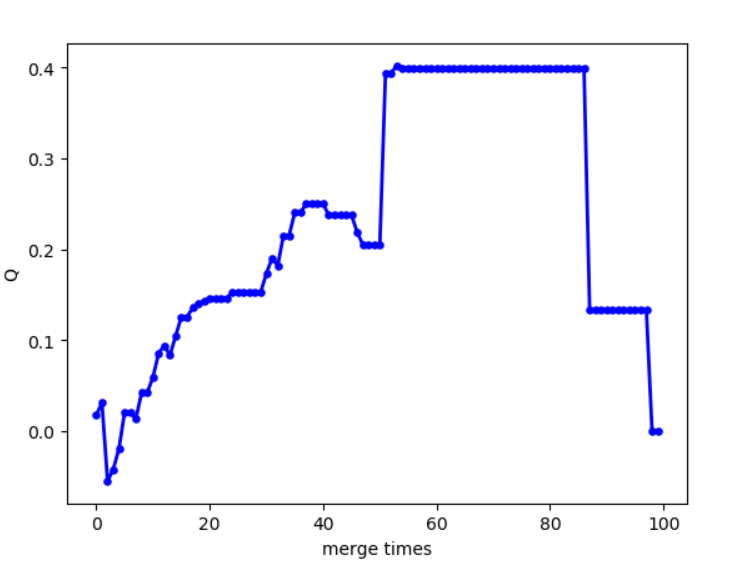
mergeTimes-Q图像
五、实验总结
经过本次实验我初步理解了基本的层次聚类技术及其应用,更好的掌握了数据挖掘的相关知识与模型,代码实现较实验一较为简单,较好的应用了已学知识,更好的理解了本学习学习的理论知识的应用,同时有机会应用了 igraph 库和 pandas 库等很简洁好用的库函数,这大大简化了我的实验过程。对于分类结果我个人认为符合我的预期,但在定义模块化量值Q时遇到了很多困难,ppt中的各个参数的意义不明,,最后在与其他同学交流与网络查询中基本解决,希望在以后的实验中可以做的更好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号