数据挖掘--二分网络上的链路预测
分类技术---二分网络上的链路预测
一、实验内容
- 采用二分网络模型,对ml-1m文件夹中的“用户---电影”打分数据进行建模,考虑将用户信息、电影详细信息、以及打分分值作为该网络上的边、点的权重;
- 根据网络结构特征给出节点相似性度量指标;
- 基于相似性在二分网络上进行链路预测;
- 采用交叉验证的方法验证预测结果;
- 画出ROC曲线来度量预测方法的准确性。
二、问题分析及模型设计
-
数据集的电影序号是一个大范围的稀疏序列,考虑将电影序号和用户序号分别存入特定数组,用数组下标唯一对应电影序号和用户序号,并以数组长度为依据,建立二分网络模型
-
将数据分为训练集90%与测试集10%
-
利用训练集计算每个用户看过多少电影和每个电影被多少用户看过,结果分别放入两个数组
-
利用训练集矩阵和分别存放每个用户看过电影数量和存放每个电影看过的用户数量
的数组,按照公式:
\[w_{ij}=\frac{1}{k_j}\sum_{l=1}^m\frac{a_{il}a_{jl}}{k_l} \]计算出对应的资源配置矩阵W
在上面公式中,电影 j 与电影 i 的兴趣关联度𝑤𝑖𝑗显然应该与k𝑗和 𝑘𝑙呈反比。对于k𝑗值,当电影 j 被很多人评价过时,那么这可能就是 个泛化的热门产品,某用户选择了电影 j 并不意味着他有强烈的选择 电影 i 的倾向。同理,对于𝑘𝑙值,用户 l 看了非常多的电影,那么他选 择了产品 j,也并不意味着他对产品 j 非常的专注,相应的推荐度也就不会很高。
-
目标用户的资源分配矢量f。初始时,将他选择过的电影对应项资源设置为1,其他为0,得到初始n维0/1向量。按一下公式计算资源分配矢量:
\[f^{'}=Wf \]并进行数组排序
f′矩阵中第 m 列为对用户 m 的电影推荐向量,排序后把得分最高 的一部分电影对应推荐给用户 m,即完成了电影推荐工作。
-
遍历测试集,对给定的用户 i,假设其有𝐿𝑖个产品是未选择的,如果在测 试集中用户 i 选择的电影 j,而电影 j 依据向量f′被排在第𝑅𝑖𝑗位,则计 算其相对位置:
\[r_{ij}=\frac{R_{ij}}{L_i} \] -
均匀选出 1—0.3 之间的 50 个数作为阈值,计算每个阈值对应的 TP(在推荐集中,用户评分大于 3), FP(在推荐集中,但用户评分小 于等于 3), FN(不在推荐集中,但用户评分大于 3), TN(不在推荐 集中,用户评分小于等于 3)。据此计算出真阳性率和假阳性率,并绘 制出 ROC 曲线
三、具体实现
1.数据导入
将data中的ratings.dat数据利用pandas的read_csv函数导入
import pandas as pd
import numpy as np
filename = "datamining\\movie\\data\\ratings.dat"
# rating.dat文件路径,根据本地修改↑
all_ratings = pd.read_csv(filename, header=None, sep="::", names=["UserID", "MovieID", "Rating", "Datetime"], engine="python")
2.数据处理
利用随机数给已读入的数据添加“class”属性,数值为1-9,方便对于数据的测试集和训练集的分类操作,同时添加Favorite属性,值为“True”或“False”,用于标记用户是否喜欢电影(分数>3记为喜欢)
# 2、对数据进行预处理
all_ratings["Favorable"] = all_ratings["Rating"] > 3.0
# 将分数>3视为用户喜欢此电影
# 3、随机将数据分为训练集与测试集
randum = np.random.rand(len(all_ratings), 1)
for i in range(len(randum)):
randum[i] = int(randum[i]*10)
all_ratings["class"] = randum
# 4、导入函数、数据,预处理数据。
all_ratings.to_csv('classified_ratings.csv')
MovieID_set = set(all_ratings["MovieID"])
MovieID_tuple = tuple(MovieID_set)
UserID_set = set(all_ratings["UserID"])
UserID_tuple = tuple(UserID_set)
M = len(UserID_set) # 用户数量
N = len(MovieID_set) # 电影数量
values = range(N)
MovieID_dict = dict(zip(MovieID_tuple, values)) # 把MovieID从小到大逐一映射
all_ratings = pd.read_csv('classified_ratings.csv',
usecols=[1, 2, 5, 6])
预处理完毕后的数据保存在“classified_ratings.csv”中,预处理之后的格式为
3.计算资源配置矩阵W 资源分配矢量**F ** 以及 TP(真阳性率) FP(假阳性率)
计算矩阵F
# 计算资源分配矢量F
def computeF():
F = []
for x in range(M):
index = UserID_tuple[x] # index = Uid
reviews_set = set(reviews_by_users[index]) # 用户看过的所有电影mid集合
reviews_set_modified = set()
for t in reviews_set:
reviews_set_modified.add(MovieID_dict[t]) # 用户看过的电影对应的索引集合
for y in range(N):
if y in reviews_set_modified:
F.append(1)
else:
F.append(0)
F = np.array(F).reshape((M, N)).transpose()
return F
计算矩阵W
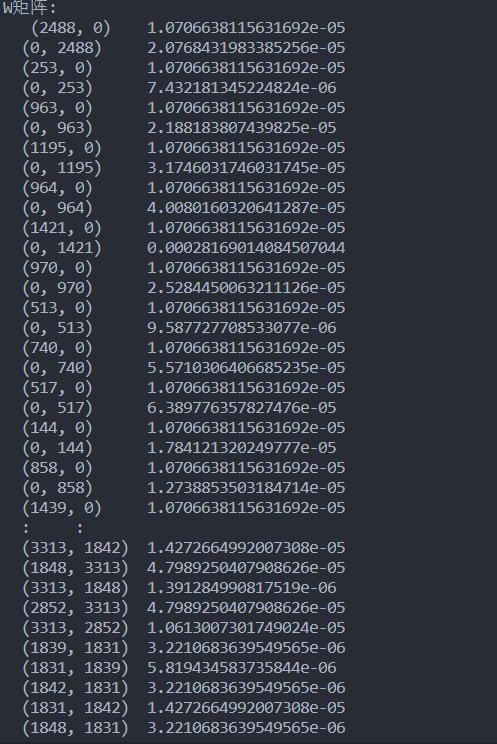
矩阵 W 为一个 n*n 维的矩阵,在数据集中电影数 约有 10,000 个,可以看出矩阵 W 规模非常大,若是存储为一个普通 的矩阵很困难。但是可以看出它其实是一个稀疏矩阵,即其中有很多 元素是 0,所以我利用了稀疏矩阵的数据结构,把 W 矩阵化成稀疏矩阵的形式来存储。
而由分析易知,当用户 l 既给电影 i 评过分也给电影 j 评过分时,
求和符号内部分子为 1,故参与求和的数化为:
减少计算量,简化计算过程
row = []
col = []
data = []
keys_list = favor_reviews_by_users.keys()
# 计算W矩阵
for l in range(M): # print "enter outer iteration %d" % l
index = UserID_tuple[l]
# print l
if index in keys_list:
# movie_favored,临时tuple变量,用来存储用户所喜欢的电影, leng 存储用户喜欢电影的个数
movie_favored = tuple(favor_reviews_by_users[index])
leng = len(movie_favored) # 训练集中用户index=UserID_tuple评分大于3的电影
# ; print "movie_favored number:%d" %leng
kl = len(reviews_by_users[index]) #该用户总评价的电影数量
for x in range(leng):
# x位置的电影ID,j 为该电影在对照表中的位置
mid = movie_favored[x]
j = MovieID_dict[mid]
kj = len(movie_reviewed[mid]) # 训练集中电影j被评价的总次数
for y in np.arange(x+1, leng):
i = MovieID_dict[movie_favored[y]] # y位置对应电影的ID,去检索,得到该ID对应的索引
ki = len(movie_reviewed[movie_favored[y]])
row.append(i)
col.append(j)
data.append(1.0/kl/kj)
# 行列反转,顺势计算对称位置上的W[i][j]
row.append(j)
col.append(i)
data.append(1.0/kl/ki)
row = np.array(row)
col = np.array(col)
data = np.array(data)
W = sparse.coo_matrix((data, (row, col)), shape=(N, N), dtype=float) # 使用稀疏矩阵对W进行存储
print("W矩阵:\n", W)
计算F‘及其修正(代码中记为F2)
利用矩阵W与矩阵F的点乘法计算F2,同时考虑推荐算法不推荐用户已看过的电影,所以进一步处理将用户已看过的并评分的项置0
# 计算F矩阵, shape=(N,M), 存放用户看过那些电影
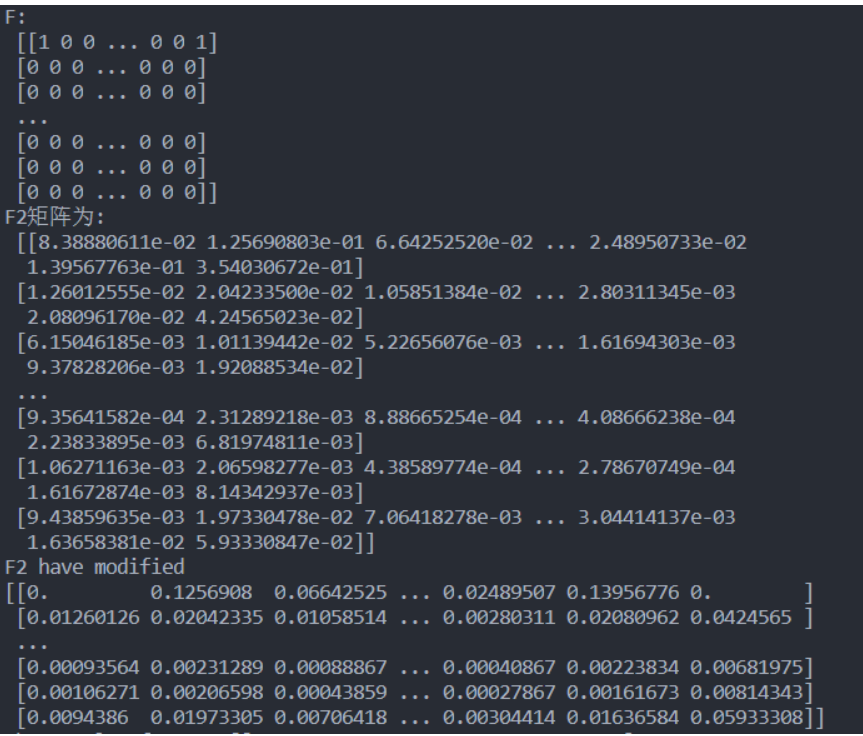
F = computeF()
print("F:\n", F)
F2 = W.dot(F)
print("F2矩阵为:\n", F2)
# 修正F2矩阵,归零那些用户已经看过的电影
for i in range(M):
slic = F[:, i]
for j in range(N):
if slic[j] == 1:
F2[j][i] = 0
print("F2 have modified")
print(F2)
计算R矩阵并计算r的均值
def calculate_r():
global sort_result
global test_by_users
global M
global N
print("enter")
sum = 0.0
for i in range(M):
index = UserID_tuple[i] # uid
if ((index in favor_in_test_by_users) == False): # 这里的 == 不能改成 is ,下面的也一样,pandas的问题会报错
# print "uid %d " % index
continue
mv_set = favor_in_test_by_users[index]
slic_dict = dict(zip(sort_result[:, i], range(N)))
for m in mv_set:
mindex = MovieID_dict[m]
sum += slic_dict[mindex]+1
sum = float(sum) / (N - len(reviews_by_users[index]))
# print "sum=%f, count=%d" % (sum, i)
return sum
# 计算r
R = []
r = calculate_r()
R.append(r)
print("r: %f" % r)
绘制ROC曲线(计算FPR TPR)
选取 1—0.5 之间的 50 个数作为阈值,统计测试集里推荐给 用户的电影集。对某条测试集中的“用户—电影”数据,若用户 i不在 测试集评分大于 3 的集合中,电影 mem 在推荐集中,则 FP+1;电影 mem 不在推荐集中,则 TN+1。若用户 i 在测试集评分大于 3 的集合 中,电影 mem在推荐集中且评分大于 3,则 TP+1;电影 mem 在推荐 集中但评分小于等于 3,则 FP+1;电影 mem 不在推荐集中但评分大 于 3,则 FN+1;电影 mem 不在推荐集中且评分小于等于 3,则 TN+1。 计算出相应的 TPR 和 FPR,利用 matplotlib 中的函数来绘制 ROC 曲线,度量该方法预测的准确性
# 绘制ROC曲线所需相关参数
# 计算TP、FP
TPR = []
FPR = []
area = []
TP = 0 # 在推荐集中,实际也给了好评
FN = 0 # 不在推荐集中,实际却给了好评
FP = 0 # 在推荐集中,实际给了差评
TN = 0 # 不在推荐集中,实际给了差评
# 为每个用户选取推荐一定比例的电影的电影
recommend_rate = np.linspace(0.001, 0.5, 50) #设置阈值在1-0.5之间的50个值
for rate in recommend_rate:
recommend_dict = recommend(rate)
for uid, reviews in test_by_users.items():
recommend_movies = recommend_dict[uid]
if ((uid in favor_in_test_by_users) == False):
# print "uid = %d" % uid
for m in reviews:
if m in recommend_movies:
FP += 1
else:
TN += 1
continue
for m in reviews:
if m in recommend_movies and m in favor_in_test_by_users[uid]:
TP = TP + 1
elif m in recommend_movies and m not in favor_in_test_by_users[uid]:
FP = FP + 1
elif m not in recommend_movies and m in favor_in_test_by_users[uid]:
FN = FN + 1
else:
TN = TN + 1
TPR.append(float(TP)/(TP+FN))
FPR.append(float(FP)/(FP+TN))
area.append(float(TP)/(TP+FN) * (1-float(FP)/(FP+TN)))
best_index = int(np.argmax(np.array(area)))
# 画图
plt.figure(1)
plt.plot(FPR, TPR, 'bx', linewidth=20)
plt.plot(np.linspace(0, 1, 200), np.linspace(0, 1, 200), 'r--', )
plt.xlabel('FPR rate')
plt.ylabel("TPR rate")
plt.scatter(FPR, TPR, linewidths=3, s=3, c='b')
plt.legend(("points with changing recommend rate", "reference curve"))
title = "ROC Curve"
plt.title(title)
f1 = plt.gcf()
plt.show()
四、实验结果
W矩阵
F矩阵&&F2矩阵
r值
本次r值为: 0.845882
*由于每次的训练与测试集不一样所以 r 值不唯一
ROC_Curve
五、实验心得
通过本次实验我更好的学习了数据挖掘的基础知识,同时实践了python中numpy库与pandas库中的各种该函数,提高了自己的动手能力与实践能力,更好的了解了数据挖掘知识的应用领域与方法,在实验过程中一开始没有考虑到本实验较大的数据量,直接采用矩阵存储会爆炸,经过学习改用稀疏矩阵存储,同时在数据处理和读入的过程中经常导致由于算力不足造成各种问题,给debug工作也造成了一定的困难,同时我的二分类模型并不是十分优秀,ROC曲线显然性能非常一般,希望在今后的学习中可以更好的提高自己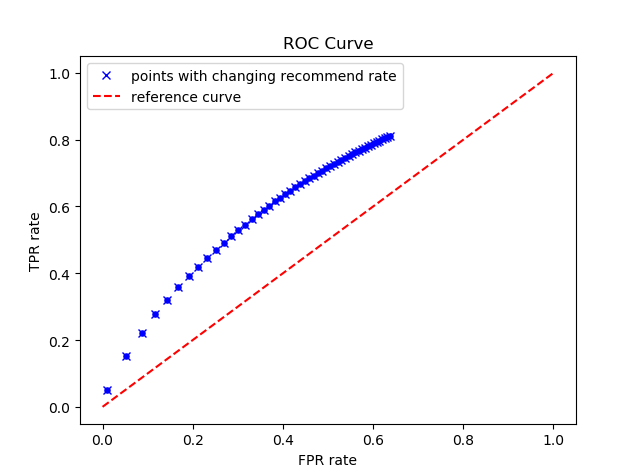

 浙公网安备 33010602011771号
浙公网安备 33010602011771号