MapReduce学习踩坑指南
MapReduce学习踩坑指南
关于java及jar包的import问题
踩坑1
错误: 程序包org.apache.hadoop.conf不存在
或者其他的类似于程序包org.apache.hadoop.*不存在的问题
如果你出现 找不到org.apache.commons.cli.Options的类文件 这个错误,请在maven\repository\commons-cli\commons-cli找到一个commons-cli.jar并导入!
原因
其实提示这种错误是正确的,当你在使用java -cp提交,并且Configuration configuration = new Configuration(); 没有添加集群配置文件的时候,我们使用的是本地模式,为什么?因为 Configuration加载配置文件的顺序是先添加core-default.xml,core-site.xml这两个文件,但是是使用hadoop jar 或者 yarn jar 才会去hadoop 的 /etc/hadoop 目录下找配置文件。如果你使用java -cp 他是找不到得出,自然就是本地模式了。
简单来讲就是你导入的jar包找!不!到!
解决方法
1.javac -cp 你安装jar包的目录\hadoop-common-3.0.0.jar;hadoop-mapreduce-client-core-3.0.0.jar;hadoop-mapreduce-client-common-3.0.0.jar Name.java一般来讲需要

这几个jar包就可以了
注意:对于.class文件来说,只需要指明包的路径即可;但是对于jar文件来说,必须要指定全路径即路径+文件名的格式,不能只指定一个路径。
2.使用批处理将jar包导入calsspath(待填坑)
输入输出类型不匹配
踩坑2
这个错误并不是什么大的错误,也不具有普遍的意义,记下来主要是提醒自己不要犯同样的简单的错误,并不具有普遍参考价值
Type mismatch in value from map: expected org.apache.hadoop.io.DoubleWritable, received org.apache.hadoop.io.IntWritable
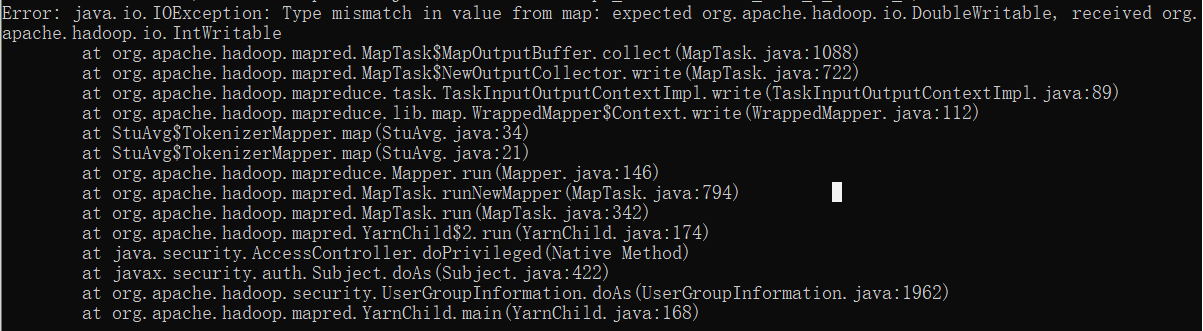
看到这个我都傻了,为啥输入输出不匹配啊,啊,是我的java文件写错了,改!

👆我改的就是它QAQ
改完之后再运行,还是报错???!
实!!际!!上!!
运行用的代码hadoop jar ./Stu.jar StuAvg /input /output运行的其实是这个jar包,所以改这个java文件时没用的!!!!
how foolish ME!!
再贴一下整个的文件
解决方法
改动的应该是Stu.jar,应该通过重新在ide中build再把jar包复制过来才行
这么个破错我改了2个小时.......
自定义序列化对象输出失败
3.踩坑3
java.io.IOException: Initialization of all the collectors failed. Error in last collector was:java.lang.ClassCast
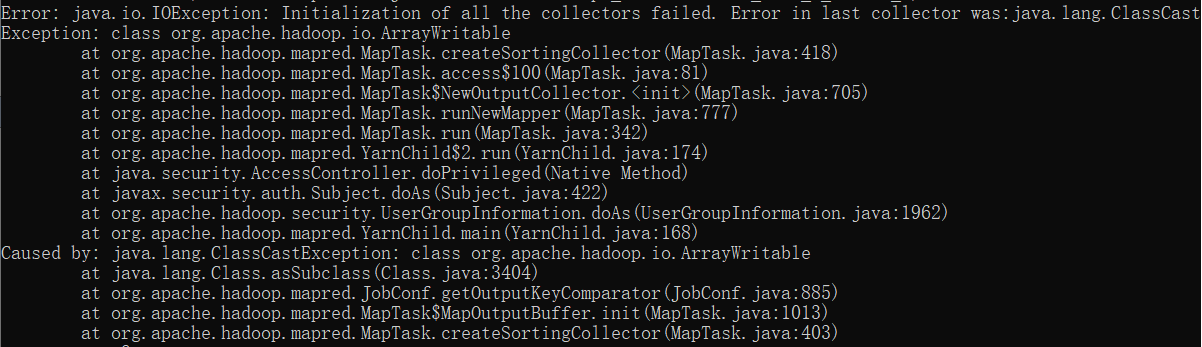
原因
二次排序,说mapreduce内置默认的排序功能,突然恍然大悟,曾经学习TreeMap和TreeSet的时候,也有排序的要求,我们自定义的类,如果没有实现两个对象大小比较的方法,就没有自动排序功能可言,
而以上我自定义的Person作为Map输出的key,也需要这样的比较功能,而Writable只是Hadoop对序列化和反序列化的加强,要能实现比较功能,需要实现的类是WritableComparable接口,
然后重写其compareTo方法.果不其然,修改了代码以后,就可以得到正确的结果了.
简单来说就是我们自己写的TextArrayWritable没有实现实现WritableComparable接口,造成Map序列化失败导致本错误
解决
自定义的序列化对象作为MapReduce的key输出的时候,需要实现WritableComparable接口,从写compareTo方法.
更正:能不要自定义KEY对象就别定义了,太麻烦了……,要实现一大堆接口ArrayWritable也最好别作为KEY使用,会出现序列化失败(java.io.IOException: Initialization of all the collectors failed.)的问题,我最后还是采用了Text作为KEY,简单多了……,我会把原来的错的代码也贴上来,提醒自己不要自己造轮子
示例
public int compareTo(Person o) {
int res = o.getId()-this.id;
return res==0?1:res;//如果返回0,表示这两个对象是相等的,而要求key不能相等.所以如果等于0,就按先来后到存进去咯
}
Ps:我也不想自己实现这个ArrayWritable类的,但是作业要求两个值作为键值,我也没什么办法,头秃,如果看到这句话的你有啥好办法还请务必告诉我QAQ
编码问题(UTF-8与GBK)
踩坑4
map无法正确分类,mainput有数据而mapoutput无输出,经检查是map函数中的字符串比对检查条件出了问题
包括各类hadoop输出中文乱码,控制台输出乱码,条件判断失败等
原因
hadoop内部强制使用UTF-8,而windows的控制台默认使用GBK导致输出乱码
解决方法
1.chcp 65001 将当前窗口强制使用UTF-8的编码,可以解决输出乱码的问题
2.对比条件含中文字符 我也不知道咋办,先挖个坑,会了就回来填坑(笑)
我!回!来!了!
比较的编码问题应该是在java源程序在编译时未指定编码格式造成编译结果中的中文乱码!
解决的话在编译时加上-encoding utf-8就可以了!
一点碎碎念:u1s1我学的是基础的分布式编程方法和思想,在编码问题上出问题也太难受了吧……就没什么道理
官方示例代码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//mapper方法的重写
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
/*继承了Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>类,其中KEYIN,VALUEIN为输入的键和值
KEYOUT,VALUEOUT为输出的键和值,需要注意的是,Java自带的数据类型在序列化时效率较低,为提高序列化效率
应使用hadoop序列化数据类型
Long:LongWritable
String:Text
Integer:IntWritable
NUll:NullWritable
*/
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//Mapper的业务逻辑写在map()方法中,输入一个<key,value>键值对,map()方法对每一个<key,value>调用一次
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//StringTokenizer实际上类似于构造一个以指定的分隔符划分的字符串的子串的集合
//StringTokenizer st=new StringTokenizer(str,","); 其中str为源字符串,“,”为设定的分隔符号,在这里把value转化为String操作
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
System.out.println(word.toString());
}
}
}
//Reduce方法的重写
/*
reducetask调用我们写的reduce方法,reduce收到map阶段的部分数据,所以reducetask的输出类型和maptask是一样的
reduce方法将所有收到的k-v键值对按照k进行分组
*/
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
//Reduce的业务逻辑写在reduce()方法中,输入一个<key,value>键值对,对于key相同的键值对进行一次reduce操作
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
//在本方法中reduce进行sum求和操作
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
System.out.println(sum);
context.write(key, result);
}
}
//main方法,用来启动任务
//主入口,job用来管理和配置程序
/*主要用于管理运行时所需要的大量参数
指定数据读取器和数据输出器
指定哪个类作为map/reduce阶段的业务逻辑类
指定程序的jar包所在的地址
*/
public static void main(String[] args) throws Exception {
//用conf来设定hdfs的相关参数,这里是新建的默认参数
Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://hadoop02:9000"); //设定hdfs主节点
//System.setProperty("HADOOP_USER_NAME","hadoop")
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//新建一个job任务
Job job = Job.getInstance(conf, "word count");
//设置jar包的路径
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);//通过Job对象指定Mapper类,TokenizerMapper类继承了Mapper类
job.setCombinerClass(IntSumReducer.class);//combineClass运行在reduceClass之前,相当于一个小型的reduceClass,key值相同的value合并成集合,然后再交给reduce处理,这样可以减少map和reduce时间传输的数量,减少reduce的压力,对运行时间可能有一定的优势
job.setReducerClass(IntSumReducer.class);//通过Job对象指定Reducer类,IntSUmreducer类继承了Reducer类
//指定reduce类输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//mapreduce程序的输入输出路径由控制台输入,并从文件中读入数据
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
作业
我为什么要写这篇博客呢
因为学校留作业了……
So,干脆把作业也贴上来算了,丢人就丢人吧……

import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class StuAvg {
//mapper方法重写
/*继承了Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>类,其中KEYIN为在inputStream下读取到的数据的**类型**,在inputformat默认输入下是一行文本的起始偏移量,所以此处选择输入LongWringhtable
VALUEIN,默认是一行文本的内容,选择Text
KEYOUT,VALUEOUT为输出的键和值,需要注意的是,Java自带的数据类型在序列化时效率较低,为提高序列化效率
应使用hadoop序列化数据类型
Long:LongWritable
String:Text
Integer:IntWritable
NUll:NullWritable
*/
public static class TokenizerMapper extends Mapper<Object,Text,Text,DoubleWritable> {
private Text name = new Text();
private DoubleWritable score = new DoubleWritable();
private Text majority = new Text("major");
private List<String> mes = new ArrayList<String>();
//Mapper的业务逻辑写在map()方法中,输入一个<key,value>键值对,map()方法对每一个<key,value>调用一次
public void map(Object key,Text values,Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(values.toString(),",");
while (itr.hasMoreTokens()){
mes.add(itr.nextToken());
}
if(mes.get(3).equals(majority.toString())){
name.set(mes.get(1));
score.set(Double.parseDouble(mes.get(4)));
context.write(name,score);
}
mes.clear();
}
}
//Reduce方法的重写
/*
reducetask调用我们写的reduce方法,reduce收到map阶段的部分数据,所以reducetask的输出类型和maptask是一样的
reduce方法将所有收到的k-v键值对按照k进行分组
*/
public static class ScoreAvgReducer extends Reducer<Text,DoubleWritable,Text,DoubleWritable>{
private DoubleWritable avg = new DoubleWritable();
private Text name = new Text();
public void reduce(Text key,Iterable<DoubleWritable> values,Context context) throws IOException, InterruptedException {
double sum = 0;
int num = 0;
name.set(key);
for(DoubleWritable val:values){
sum += val.get();
num++;
}
if(num!=0) {
avg.set(sum / num);
}
System.out.println(name.toString()+" "+avg.toString());
context.write(name,avg);
}
}
//main方法,用来启动任务
//主入口,job用来管理和配置程序
/*主要用于管理运行时所需要的大量参数
指定数据读取器和数据输出器
指定哪个类作为map/reduce阶段的业务逻辑类
指定程序的jar包所在的地址
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//用conf来设定hdfs的相关参数,这里是新建的默认参数
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//新建一个job任务
Job job = Job.getInstance(conf, "StuAvgScore");
//设置jar包的路径
job.setJarByClass(StuAvg.class);
job.setMapperClass(TokenizerMapper.class);//通过Job对象指定Mapper类,TokenizerMapper类继承了Mapper类
job.setCombinerClass(ScoreAvgReducer.class);//combineClass运行在reduceClass之前,相当于一个小型的reduceClass,key值相同的value合并成集合,然后再交给reduce处理,这样可以减少map和reduce时间传输的数量,减少reduce的压力,对运行时间可能有一定的优势
job.setReducerClass(ScoreAvgReducer.class);//通过Job对象指定Reducer类,IntSUmreducer类继承了Reducer类
//指定map的输入类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
//指定reduce类输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//mapreduce程序的输入输出路径由控制台输入,并从文件中读入数据
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
//错误的实现我注释掉了,希望可以给自己一个教训QAQ
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class CourseAvg {
//使用Hadoop数据类型ArrayWritable,ArrayWritable的使用必须自己实现一个类继承ArrayWritable,并重写其构造函数
/*
A Writable for arrays containing instances of a class.
The elements of this writable must all be instances of the same class.
If this writable will be the input for a Reducer, you will need to create a subclass that sets the value to be of the proper type.
For example: public class IntArrayWritable extends ArrayWritable { public IntArrayWritable() { super(IntWritable.class); } }
*/
/*
public static class TextArrayWritable extends ArrayWritable implements WritableComparable {
public TextArrayWritable() {
super(Text.class);
}
//传入一个字符串数组,并将字符串数组转化成为texts[]存放在本类中
public TextArrayWritable(String[] strings) {
super(Text.class);
Text[] texts = new Text[strings.length];
for (int i = 0; i < strings.length; i++) {
texts[i] = new Text(strings[i]);
}
set(texts);
}
@Override
public ArrayList<String> toArray() {
ArrayList<String> arr = toArray();
for(String str:arr){
arr.add(str);
}
return arr;
}
@Override
public String toString() {
String[] abc = toStrings();
StringBuffer sBuffer = new StringBuffer();
for (String string : abc) {
sBuffer.append(string + ",");
}
if (sBuffer.length()==0) {
return "";
}
sBuffer.deleteCharAt(sBuffer.lastIndexOf(","));
return sBuffer.toString();
}
@Override
public int compareTo(Object o) {
return 0;
}
}
*/
//mapper方法重写
/*继承了Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>类,其中KEYIN为在inputStream下读取到的数据的**类型**,在inputformat默认输入下是一行文本的起始偏移量,所以此处选择输入LongWringhtable
VALUEIN,默认是一行文本的内容,选择Text
KEYOUT,VALUEOUT为输出的键和值,需要注意的是,Java自带的数据类型在序列化时效率较低,为提高序列化效率
应使用hadoop序列化数据类型
Long: LongWritable
String: Text
Integer: IntWritable
NUll: NullWritable
ArrayList: ArrayWritable
*/
//Mapper的业务逻辑写在map()方法中,输入一个<key,value>键值对,map()方法对每一个<key,value>调用一次
/*
public static class TokenizerMapper extends Mapper<Object,Text,ArrayWritable,DoubleWritable> {
private DoubleWritable score = new DoubleWritable();
private List<String> mes = new ArrayList<String>();
private Text[] str = new Text[2];
public void map(Object key,Text values,Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(values.toString(),",");
while (itr.hasMoreTokens()){
mes.add(itr.nextToken());
}
str[0].set(mes.get(2));
str[1].set(mes.get(0));
ArrayWritable K = new ArrayWritable(Text.class);
K.set(str);
score.set(Double.parseDouble(mes.get(4)));
context.write(K,score);
mes.clear();
}
}
*/
//Mapper的业务逻辑写在map()方法中,输入一个<key,value>键值对,map()方法对每一个<key,value>调用一次
public static class TokenizerMapper extends Mapper<Object,Text,Text,DoubleWritable> {
private DoubleWritable score = new DoubleWritable();
private List<String> mes = new ArrayList<String>();
private StringBuilder str = new StringBuilder("");
public void map(Object key,Text values,Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(values.toString(),",");
while (itr.hasMoreTokens()){
mes.add(itr.nextToken());
}
str.append(mes.get(2)+",");
str.append(mes.get(0));
Text K =new Text(str.toString());
score.set(Double.parseDouble(mes.get(4)));
context.write(K,score);
mes.clear();
str.delete(0,str.length());
}
}
//Reduce方法的重写
/*
reducetask调用我们写的reduce方法,reduce收到map阶段的部分数据,所以reducetask的输出类型和maptask是一样的
reduce方法将所有收到的k-v键值对按照k进行分组
*/
/*
public static class ScoreAvgReducer extends Reducer<ArrayWritable,DoubleWritable,Text,DoubleWritable>{
private DoubleWritable avg = new DoubleWritable();
private Text mes = new Text();
public void reduce(ArrayWritable key,Iterable<DoubleWritable> values,Context context) throws IOException, InterruptedException {
double sum = 0;
int num = 0;
ArrayList<String> str = new ArrayList<String>();
for(DoubleWritable value:values){
sum+=value.get();
num++;
}
avg.set(sum/num);
mes.set(key.toString());
System.out.println(mes.toString()+" "+avg.toString());
context.write(mes,avg);
}
}
*/
public static class ScoreAvgReducer extends Reducer<Text,DoubleWritable,Text,DoubleWritable>{
private DoubleWritable avg = new DoubleWritable();
private Text mes = new Text();
public void reduce(Text key,Iterable<DoubleWritable> values,Context context) throws IOException, InterruptedException {
double sum = 0;
int num = 0;
ArrayList<String> str = new ArrayList<String>();
for(DoubleWritable value:values){
sum+=value.get();
num++;
}
avg.set(sum/num);
context.write(key,avg);
}
}
//main方法,用来启动任务
//主入口,job用来管理和配置程序
/*主要用于管理运行时所需要的大量参数
指定数据读取器和数据输出器
指定哪个类作为map/reduce阶段的业务逻辑类
指定程序的jar包所在的地址
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//用conf来设定hdfs的相关参数,这里是新建的默认参数
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//新建一个job任务
Job job = Job.getInstance(conf, "StuAvgScore");
//设置jar包的路径
job.setJarByClass(CourseAvg.class);
//通过Job对象指定Mapper类,TokenizerMapper类继承了Mapper类
job.setMapperClass(TokenizerMapper.class);
//combineClass运行在reduceClass之前,相当于一个小型的reduceClass,key值相同的value合并成集合,然后再交给reduce处理,这样可以减少map和reduce时间传输的数量,减少reduce的压力,对运行时间可能有一定的优势
job.setCombinerClass(ScoreAvgReducer.class);
//通过Job对象指定Reducer类,IntSUmreducer类继承了Reducer类
job.setReducerClass(ScoreAvgReducer.class);
//指定map的输入类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DoubleWritable.class);
//指定reduce类输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
//mapreduce程序的输入输出路径由控制台输入,并从文件中读入数据
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class GrandChild {
//mapper方法重写
/*继承了Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>类,其中KEYIN为在inputStream下读取到的数据的**类型**,在inputformat默认输入下是一行文本的起始偏移量,所以此处选择输入LongWringhtable
VALUEIN,默认是一行文本的内容,选择Text
KEYOUT,VALUEOUT为输出的键和值,需要注意的是,Java自带的数据类型在序列化时效率较低,为提高序列化效率
应使用hadoop序列化数据类型
Long:LongWritable
String:Text
Integer:IntWritable
NUll:NullWritable
*/
public static class myMapper extends Mapper<Object, Text, Text, Text> {
// 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String temp=new String();// 左右表标识
String values=value.toString();
String words[]=values.split(",");
//Tom Lucy
// 输出左表
temp = "1";
context.write(new Text(words[1]), new Text(temp +"+"+ words[0] + "+" + words[1]));
//(Lucy,1+Tom+Lucy)
// 输出右表
temp = "2";
context.write(new Text(words[0]), new Text(temp +"+"+ words[0] + "+" + words[1]));
//(Tom,2+Tom+Lucy)
}
}
public static class myReducer extends Reducer<Text, Text, Text, Text> {
// 实现reducer函数
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
List<String> grandchild = new ArrayList<String>();
List<String> grandparent = new ArrayList<String>();
for (Text value : values) {
char temp=(char) value.charAt(0);
String words[]=value.toString().split("[+]"); //1,Tom+Lucy
// +、*、|、/等符号在正则表达示中有相应的不同意义,一般来讲只需要加[]、或是\\即可
if(temp == '1'){
grandchild.add(words[1]);
}
if(temp == '2'){
grandparent.add(words[2]);
}
}
//求笛卡尔儿积
for (String gc : grandchild) {
for (String gp : grandparent) {
context.write(new Text(gc),new Text(gp));
}
}
}
}
//main方法,用来启动任务
//主入口,job用来管理和配置程序
/*主要用于管理运行时所需要的大量参数
指定数据读取器和数据输出器
指定哪个类作为map/reduce阶段的业务逻辑类
指定程序的jar包所在的地址
*/
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//用conf来设定hdfs的相关参数,这里是新建的默认参数
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
//新建一个job任务
Job job = Job.getInstance(conf, "GrandChild");
//设置jar包的路径
job.setJarByClass(GrandChild.class);
job.setMapperClass(myMapper.class);//通过Job对象指定Mapper类,SelfMapper类继承了Mapper类
//job.setCombinerClass(SelfReducer.class);//combineClass运行在reduceClass之前,相当于一个小型的reduceClass,key值相同的value合并成集合,然后再交给reduce处理,这样可以减少map和reduce时间传输的数量,减少reduce的压力,对运行时间可能有一定的优势
job.setReducerClass(myReducer.class);//通过Job对象指定Reducer类,IntSUmreducer类继承了Reducer类
//指定map的输入类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//指定reduce类输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//mapreduce程序的输入输出路径由控制台输入,并从文件中读入数据
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
//提交任务
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
相关知识点(有时间就写)
1.Iterable
2.MapReduce的基本原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号