【论文阅读】Chinese NER using Lattice LSTM[ACL2018]
论文地址:https://www.aclweb.org/anthology/P18-1144.pdf
代码地址(Pytorch):https://github.com/jiesutd/LatticeLSTM
Abstract
我们研究了一个格结构的LSTM模型,该模型对一系列输入字符以及与一个词典匹配的所有潜在单词进行编码。与基于字符的方法相比,我们的模型显式地利用了单词和单词序列信息。与基于词的方法相比,lattice-LSTM不存在切分错误。门控循环细胞允许我们的模型从一个句子中选择最相关的字符和单词以获得更好的结果。在不同数据集上的实验表明,lattice-LSTM的性能优于基于单词和基于字符的LSTM基线,达到了最佳效果。
1 Introduction
命名实体识别作为信息抽取的一项基础性工作,近年来受到了广泛的关注。传统上,这项任务是作为一个序列标签问题来解决的,其中实体边界和类别标签是联合预测的。通过使用LSTM-CRF模型(Lample et al., 2016; Ma and Hovy, 2016; Chiu and Nichols, 2016; Liu et al., 2018),将字符信息整合到单词表示中。
汉语NER与分词相关。特别是,命名实体边界也是单词边界。一种直观的方法是先进行分词,然后再进行词序标注。分割→ NER管道The segmentation → NER pipeline,然而可能会遇到错误传播的潜在问题,因为NEs是分割中OOV的一个重要来源,错误分割实体边界会导致NER错误。这个问题在开放领域可能会很严重,因为跨领域分词仍然是一个未解决的问题(Liu and Zhang, 2012; Jiang et al., 2013; Liu et al., 2014; Qiu and Zhang, 2015; Chen et al., 2017; Huang et al., 2017)。研究表明,基于字符的方法比基于单词的方法更适合于汉语词汇学习(He and Wang, 2008; Liu et al., 2010; Li et al., 2014).。
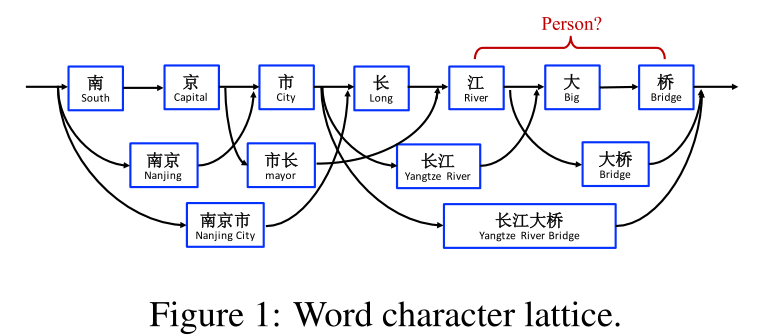
然而,基于字符的NER的一个缺点是没有充分利用显式的单词和单词序列信息,这可能是有用的。为了解决这个问题,我们将潜在的单词信息整合到基于字符的LSTM-CRF中,通过使用格结构LSTM来表示句子中的词汇单词。如图1所示,我们通过将一个句子与一个自动获得的大词典进行匹配来构造一个word-character lattice格。As a result, word sequences such as “长江大桥(Yangtze River Bridge)”, “长江(Yangtze River)” and “大桥(Bridge)” can be used to disambiguate potential relevant named entities in a context消除上下文中潜在相关命名实体的歧义, such as the person name “江大桥(Daqiao Jiang)”.
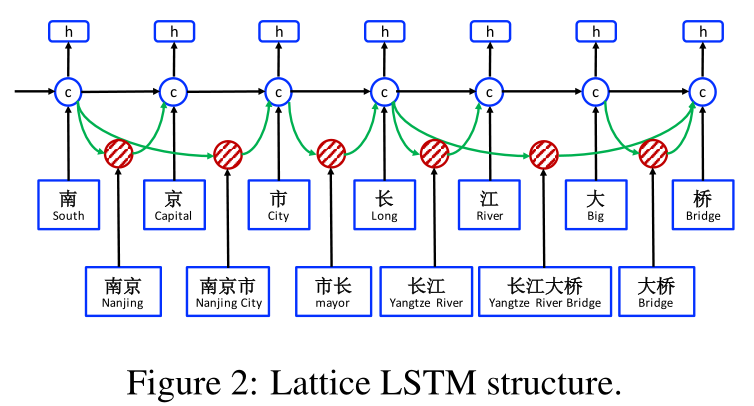
由于格中有指数数量的字字符路径,我们利用格LSTM结构自动控制从句子开始到结束的信息流。如图2所示,选通单元用于将信息从不同路径动态路由到每个字符。经过训练的格LSTM可以自动从上下文中找到更多有用的单词,从而获得更好的NER性能。与基于字符和基于单词的NER方法相比,该模型在不产生分割错误的情况下,利用了显式的单词信息而不是字符序列标注。
结果表明,我们的模型显著优于使用LSTM-CRF的字符序列标记模型和单词序列标记模型,在不同领域的各种中文NER数据集上给出了最好的结果。
2 Related Work
我们的工作与现有的神经网络方法是一致的。Hammerton(2003)试图用单向LSTM来解决这个问题,这是NER的第一个神经模型。Collobert et al.(2011年)使用了CNN-CRF结构,获得了最佳统计模型的竞争结果。dos Santoset al. (2015)使用字符CNN来扩充CNN-CRF模型。最近的工作利用了LSTM-CRF体系结构。Huang et al.(2015)使用手工制作的拼写特征;Ma and Hovy(2016)以及Chiu and Nichols(2016)使用字符CNN来表示拼写特征;Lample et al.(2016)使用character LSTM代替。我们的基于单词word-based的基线系统采用与此工作类似的结构。
字符序列标记一直是中文NER的主要方法(Chen et al., 2006b; Lu et al., 2016; Dong et al., 2016). 有明确的讨论比较了基于单词的统计方法和基于字符的方法,表明后者在经验上是一个更好的选择(He and Wang, 2008; Liu et al., 2010; Li et al., 2014)。我们发现,在适当的表征设置下,同样的结论适用于神经网络。另一方面,与单词和字符LSTM相比,格LSTM是一种更好的选择。On the other hand, lattice LSTM is a better choice compared with both word LSTM and character LSTM.
如何更好地利用词的信息来进行汉语新词语识别一直受到人们的关注(Gao et al., 2005),其中分词信息被用作新词语识别的软特征soft features for NER(Zhao and Kit, 2008; Peng and Dredze, 2015; He and Sun, 2017a),使用对偶分解dual decomposition研究了联合分割joint segmentation和NER(Xu等人,2014),多任务学习(Peng和Dredze,2016)等进行了研究。我们的工作是一致的in line,重点是神经表征学习。虽然上述方法会受到分词训练数据和分词错误的影响,但我们的方法不需要分词器。由于不考虑多任务设置,该模型在概念上更简单。
外部信息来源已被用于NER。尤其是词汇特征被广泛使用(Collobert et al., 2011; Passos et al., 2014; Huang et al., 2015; Luo et al., 2015). Rei(2017)使用word-level语言建模目标来增强NER训练,在大型原始文本上执行多任务学习。Peters等人(2017)提出了一种字符语言模型character language model,以增强单词表示。Yang et al.(2017b)通过多任务学习开发跨领域和跨语言知识。我们利用外部数据通过预训练单词嵌入词典在自动分割的大文本,而半监督技术,如语言建模是正交的,也可以用于我们的格子LSTM模型。We leverage external data by pretraining word embedding lexicon over large automatically-segmented texts, while semisupervised techniques such as language modeling are orthogonal to and can also be used for our lattice LSTM model.
晶格结构RNNLattice structured RNNs可视为树结构RNN((Tai et al., 2015))到DAG的自然延伸。它们已被用于为NMT编码器建模运动动力学(Sun et al.,2017)、依赖话语dependency-discourse DAG(Peng et al.,2017)以及语音标记化晶格(Sperber et al.,2017)和多粒度分割输出(Su et al.,2017)。与已有的工作相比,我们的格LSTM在动机和结构上都有所不同。例如,设计用于以字符为中心的点阵LSTM-CRF序列标记,它有递归单元,但没有隐藏的字向量。据我们所知,我们是第一个为混合字符和词汇词设计了一个新的格LSTM表示,并且第一个使用一个字-字格来实现无分词的汉语。To our knowledge, we are the first to design a novel lattice LSTM representation for mixed characters and lexicon words, and the first to use a word-character lattice for segmentation-free Chinese NER.
3 Model
We follow the best English NER model (Huang et al., 2015; Ma and Hovy, 2016; Lample et al., 2016), using LSTM-CRF as the main network structure. Formally, denote an input sentence as $s = c_1, c_2, . . . , c_m$, where $c_j$ denotes the $j$th character. $s$ can further be seen as a word sequence $s = w_1, w_2, . . . , w_n$, where $w_i$ denotes the $i$th word in the sentence, obtained using a Chinese segmentor. We use $t(i, k)$ to denote the index $j$ for the $k$th character in the $i$th word in the sentence.我们用 $t(i, k)$来表示句子第$i$个单词中第$k$个字符的索引$j$. Take the sentence in Figure 1 for example. If the segmentation is “南京市 长江大桥”, and indices are from 1, then t(2,1) = 4 (长) and t(1,3) = 3 (市). We use the BIOES tagging scheme (Ratinov and Roth, 2009) for both wordbased and character-based NER tagging.
3.1 Character-Based Model
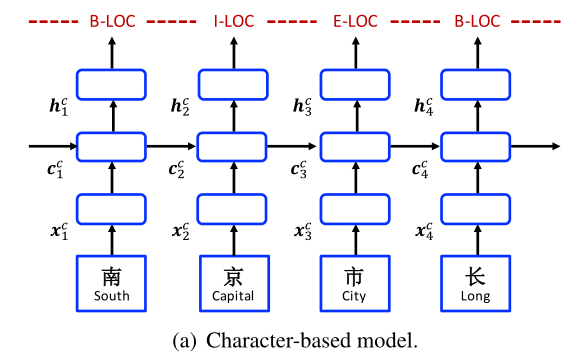
The character-based model is shown in Figure 3(a). It uses an LSTM-CRF model on the character sequence $c_1, c_2, . . . , c_m$. Each character $c_j$ is represented using:
$x_j^c=e^{c}(c_j)$
$e^c$ denotes a character embedding lookup table.
A bidirectional LSTM (same structurally as Eq. 11) is applied to $x_1,x_2, . . . ,x_m$ to obtain $\overrightarrow{h}^c_1, \overrightarrow{h}^c_2, . . . , \overrightarrow{h}^c_m$ and $\overleftarrow{h}^c_1,\overleftarrow{h}^c_2,...,\overleftarrow{h}^c_m$ in the left-to-right and right-to-left directions, respectively, with two distinct sets of parameters. The hidden vector representation of each character is:
$h_j^c=[\overrightarrow{h}^c_j;\overleftarrow{h}^c_j]$
A standard CRF model (Eq. 17) is used on $h^c_1,h^c_2, . . . ,h^c_m$ for sequence labelling.
• Char + bichar. Character bigrams have been shown useful for representing characters in word segmentation (Chen et al., 2015; Yang et al., 2017a). We augment the character-based model with bigram information by concatenating bigram embeddings with character embeddings:
$x_j^c=[e^c(c_j);e^b(c_j,c_{j+1})]$
where $e^b$ denotes a charater bigram lookup table.
• Char + softword. It has been shown that using segmentation as soft features for character-based NER models can lead to improved performance (Zhao and Kit, 2008; Peng and Dredze, 2016).
We augment the character representation with segmentation information by concatenating segmentation label embeddings to character embeddings:
$x_j^c=[e^c(c_j);e^s(seg(c_j))]$
where $e^s$ represents a segmentation label embedding lookup table. $seg(c_j)$ denotes the segmentation label on the character $c_j$ given by a word segmentor. We use the BMES scheme for repre- senting segmentation (Xue, 2003).
$h_i^w=[\overrightarrow{h}_i^w;\overleftarrow{h}_i^w]$
Similar to the character-based case, a standard CRF model (Eq. 17) is used on $h^w_1,h^w_2, . . . ,h^w_m$ for sequence labelling.
3.2 Word-Based Model
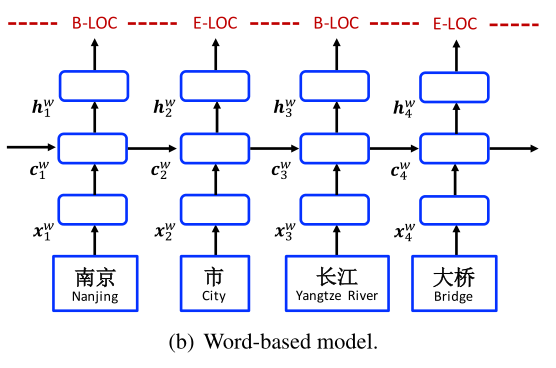
The word-based model is shown in Figure 3(b). It takes the word embedding $e^w(w_i)$ for representation each word $w_i$:
$x_i^w=e^w(w_i)$
where $e^w$ denotes a word embedding lookup table. A bi-directioanl LSTM (Eq. 11) is used to obtain a left-to-right sequence of hidden states $\overrightarrow{h}^w_1, \overrightarrow{h}^w_2, . . . , \overrightarrow{h}^w_n$ and a right-to-left sequence of hidden states $\overleftarrow{h}^w_1,\overleftarrow{h}^w_2,...,\overleftarrow{h}^w_n$ for the words $w_1, w_2, . . . , w_n$, respectively. Finally, for each word $w_i$,$\overrightarrow{h}^w_i$ and $\overleftarrow{h}^w_i$ are concatenated as its representation:
Integrating character representations集成字符表示
Both character CNN (Ma and Hovy, 2016) and LSTM (Lample et al., 2016) have been used for representing the character sequence within a word. We experiment with both for Chinese NER. Denoting the representation of characters within $w_i$ as $x^c_i$, a new word representation is obtained by concatenation of $e^w(w_i)$ and $x^c_i$:
$x_i^w=[e^w(w_i);x^c_i]$
• Word + char LSTM. Denoting the embedding of each input character as $e^c(c_j)$, we use a bi-directional LSTM (Eq. 11) to learn hidden states $\overrightarrow{h}^c_{t(i,1)},...,\overrightarrow{h}^c_{t(i,len(i))}$ and $\overleftarrow{h}^c_{t(i,1)},...,\overleftarrow{h}^c_{t(i,len(i))}$ for the characters $c_{t(i,1)}, . . . , c_{t(i,len(i))}$ of $w_i$, where $len(i)$ denotes the number of characters in $w_i$. The final character representation for $w_i$ is:
$x_i^c=[\overrightarrow{h}^c_{t(i,len(i))};\overleftarrow{h}^c_{t(i,1)}]$ (8)
• Word + char $LSTM^{'}$. We investigate a variation of word + char LSTM model that uses a single LSTM to obtain $\overrightarrow{h}_j^c$ and $\overleftarrow{h}_j^c$ for each $c_j$. It is similar with the structure of Liu et al. (2018) but not uses the highway layer. The same LSTM structure as defined in Eq. 11 is used, and the same method as Eq. 8 is used to integrate character hidden states into word representations.并使用与等式8相同的方法将字符隐藏状态集成到单词表示中。
• Word + char CNN. A standard CNN (LeCun et al., 1989) structure is used on the character sequence of each word to obtain its character representation $x^c_i$. Denoting the embedding of character $c_j$ as $e^c(c_j)$, the vector $x^c_i$ is given by:
$x_i^c=max_{t(i,1)\leq j\leq t(i,len(i))}(W^{T}_{CNN}\left[ \begin{matrix} e^c(c_{j-\frac{ke-1}{2}}) \\ ... \\ e^c(c_{j+\frac{ke-1}{2}}) \end{matrix} \right]\tag{2}+b_{CNN}$
where $W_{CNN}$ and $b_{CNN}$ are parameters, $ke = 3$ is the kernal size and $max$ denotes max pooling.
3.3 Lattice Model
The overall structure of the word-character lattice model is shown in Figure 2, which can be viewed as an extension of the character-based model, integrating word-based cells and additional gates for controlling information flow.
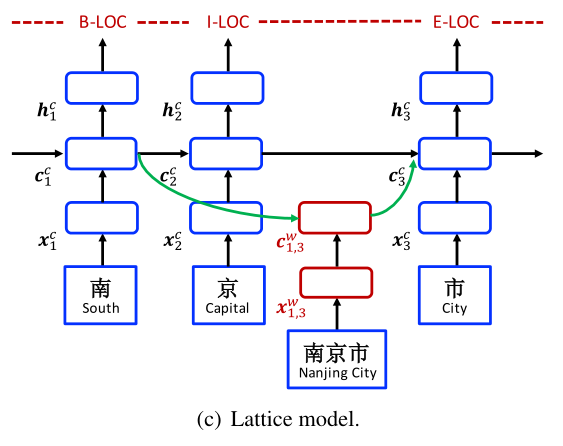
Shown in Figure 3(c), the input to the model is a character sequence $c_1, c_2, . . . , c_m$, together with all character subsequences that match words in a lexicon $\cal{D}$以及与词典D中的单词匹配的所有字符子序列. As indicated in Section 2, we use automatically segmented large raw text for buinding $\cal{D}$. Using $w^d_{b,e}$ to denote such a subsequence that begins with character index $b$ and ends with character index $e$, the segment $w^d_{1,2}$ in Figure 1 is “南 京 (Nanjing)” and $w^d_{7,8}$ is “大桥 (Bridge)”.
Four types of vectors are involved in the model, namely $input vectors$, $output hidden vectors$, $cell vectors$ and $gate vectors$. As basic components, a character input vector is used to represent each chacracter $c_j$ as in the character-based model:
$x_j^c=e^c(c_j)$
The basic recurrent structure of the model is constructed using a character cell vector $c^c_j$ and a hidden vector $h^c_j$ on each $c_j$, where $c^c_j$ serves to record recurrent information flow from the beginning of the sentence to $c_j$ and $h^c_j$ is used for CRF sequence labelling using Eq. 17.
Different from the character-based model, however, the computation of $c^c_j$ now considers lexicon subsequences(词汇子序列) $w^d_{b,e}$ in the sentence. In particular, each subsequence $w^d_{b,e}$ is represented using
$x_{b,e}^w=e^w(w_{b,e}^d)$
where $e^w$ denotes the same word embedding lookup table as in Section 3.2.
In addition, a word cell $c_{b,e}^w$ is used to represent the recurrent state of $x_{b,e}^w$ from the beginning of the sentence. The value of $c_{b,e}^w$ is calculated by:
$\left[ \begin{matrix} i_{b,e}^w\\f_{b,e}^w\\\tilde{c}_{b,e}^w \end{matrix} \right] = \left[ \begin{matrix} \sigma \\\sigma\\tanh \end{matrix} \right]({W^w}^T)\left[ \begin{matrix} x_{b,e}^w\\h_b^c \end{matrix} \right] +b^w$
$c_{b,e}^w=f_{b,e}^w\bigodot c_b^c+i_{b,e}^w\bigodot \tilde{c}_{b,e}^w$
where $i_{b,e}^w$ and $f_{b,e}^w$ are a set of input and forget gates. There is no output gate for word cells since labeling is performed only at the character level.
With $c_{b,e}^w$, there are more recurrent paths for information flow into each $c_j^c$. For example, in Figure 2, input sources for $c_7^c$ include $x_7^c$ (桥 Bridge), $c_{6,7}^w$ (大桥 Bridge) and $c_{4,7}^w$(长江大桥 Yangtze River Bridge).【We experimented with alternative configurations on indexing word and character path links, finding that this configuration gives the best results in preliminary experiments. Single-character words are excluded; the final performance drops slightly after integrating single-character words.】We link all $c_{b,e}^w$ with $b ∈ {b^{'}|w_{b^{'},e}^d \in \cal{D}}$ to the cell $c_e^c$. We use an additional gate $i_{b,e}^c$ for each subsequence cell $c_{b,e}^w$ for controlling its contribution into $c_{b,e}^c$:
$i_{b,e}^c=\sigma(W^{lT}\left[ \begin{matrix} x_e^c\\c_{b,e}^w \end{matrix} \right])$
The calculation of cell values $c_j^c$ thus becomes
$c_j^c=\sum_{b\in \{b^{'}|w_{b^{'},j}^d\in \cal{D}\}}\alpha_{b,j}^c\bigodot c_{b,j}^w+\alpha_j^c\bigodot \tilde{c}_j^c$ (15)
In Eq. 15, the gate value $i_{b,j}^c$ and $i_j^c$ are normalised to $\alpha_{b,j}^c$ and $\alpha_j^c$ by setting the sum to 1
$\alpha_{b,j}^c=\frac{exp(i_{b,j}^c)}{exp(i_j^c)+\sum_{b^{'}\in \{ b^{''}|w_{b^{''},j}^d\}}exp(i_{b^{'},j}^c) }$
$\alpha_{j}^c=\frac{exp(i_{j}^c)}{exp(i_j^c)+\sum_{b^{'}\in \{ b^{''}|w_{b^{''},j}^d\}}exp(i_{b^{'},j}^c) }$
The final hidden vectors $h_j^c$ are still computed as described by Eq. 11. During NER training, loss values back-propagate to the parameters $W_c,b_c,W_w,b_w,W_l$ and $b_l$ allowing the model to dynamically focus on more relevant words during NER labelling.
3.4 Decoding and Training
A standard CRF layer is used on top of $h_1,h_2, . . . ,h_τ$, where $τ$ is $n$ for character-based and lattice-based models and $m$ for word-based models. The probability of a label sequence $y = l_1, l_2, . . . , l_τ$ is
$P(y|s)=\frac{exp(\sum_i(W_{CRF}^{l_i}h_i+b_{CRF}^{(l_{i-1},l_i)}))}{\sum_{y^{'}}exp(\sum_i(W_{CRF}^{l_i^{'}}h_i+b_{CRF}^{(l_{i-1}^{'},l_i^{'})}))}$ (17)
Here $y^{'}$ represents an arbitary label sequence, and $W_{CRF}^{l_i}$ is a model parameter specific to $l_i$, and $b^{(l_{i−1},l_i)}_CRF$ is a bias specific to $l_{i−1}$ and $l_i$.
We use the first-order Viterbi algorithm to find the highest scored label sequence over a word-based or character-based input sequence. Given a set of manually labeled training data $\{(s_i, y_i)\}|^N_{i=1}$, sentence-level log-likelihood loss with $L_2$ regularization is used to train the model:
$L=\sum_{i=1}^Nlog(P(y_i|s_i))+\frac{\lambda}{2}||\theta||^2$
where $λ$ is the $L_2$ regularization parameter and $Θ$ represents the parameter set.
4 Experiments
我们进行了一系列广泛的实验来研究word-character 格LSTM在不同领域的有效性。此外,我们还对不同背景下word-based and character-based的神经网络进行了实证比较。以标准精密度(P)、召回率(R)和F1得分(F1)作为评价指标。
4.1 Experimental Settings
Data.
本文使用了四个数据集,包括OntoNotes 4(Weischedel et al.,2011)、MSRA(Levow,2006)、Weibo NER(Peng and Dredze,2015);He and Sun, 2017a)和一个我们注释的中文简历数据集。数据集的统计数据如表1所示。我们采用与Che等人(2013)在OntoNotes上相同的数据分割。OntoNotes的开发集用于报告开发实验。虽然OntoNotes和MSRA数据集是在新闻领域,但微博的NER数据集是从社交媒体网站新浪微博中提取的。
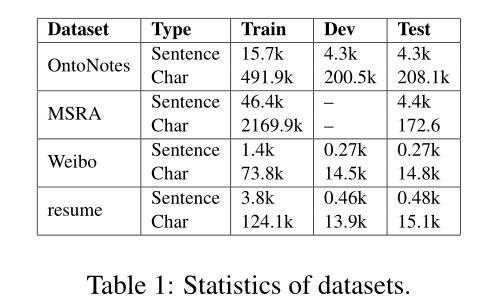
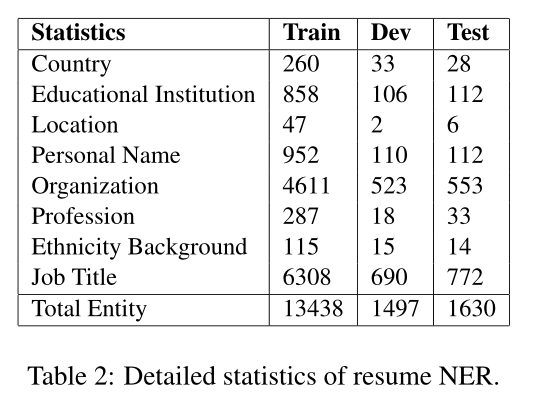
为了让测试领域更加多样化,我们从新浪财经号收集了一份简历数据集,其中包括中国股市上市公司高管的简历。我们随机选取1027份简历摘要,并手工标注了8种类型的命名实体。数据集的统计数据如表2所示。注释者之间的一致性为97.1%。我们发布这个数据集作为进一步研究的资源。
Segmentation.
对于OntoNotes和MSRA数据集,培训部分提供了黄金标准分割。对于OntoNotes,黄金分割也可用于开发和测试部分。另一方面,MSRA测试部分和微博/简历数据集都没有细分。因此,OntoNotes被用于研究oracle的黄金分割情况。我们使用Yang等人(2017a)的神经分词器自动分割基于单词的NER的开发集和测试集。特别是,对于OntoNotes和MSRA数据集,我们在各自的训练集上使用黄金分割来训练分割器。对于微博和简历,我们采用了Yang et al.(2017a)的最佳模型,该模型使用CTB 6.0(Xue et al.,2005)进行训练。
Word Embeddings.
我们使用word2vec(Mikolov等人,2013)对自动切分的中文Giga-Word进行预训练,在最终的词典中获得704.4k个单词。特别是单字、双字、三字字数分别为5.7k、291.5k、278.1k。嵌入词典与我们的代码和模型一起发布,作为进一步研究的资源。单词嵌入在NER训练过程中进行了微调。使用word2vec对汉字和汉字双字嵌入进行预训练,并在模型训练时进行微调Character and character bigram embeddings are pretrained on Chinese Giga-Word using word2vec and finetuned at model training.。
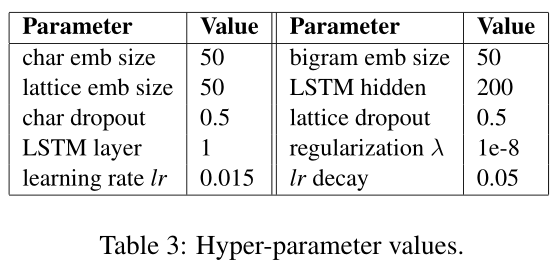
Hyper-parameter settings.
表3显示了我们模型的超参数值,这些值是根据文献中以前的工作固定的,没有对每个数据集进行网格搜索调整。特别地,嵌入大小被设置为50,LSTM模型的隐藏大小被设置为200。Dropout(Srivastava et al.,2014)以0.5的速率应用于单词和字符嵌入。采用随机梯度下降法(SGD)进行优化,初始学习率为0.015,衰减率为0.05。
4.2 Development Experiments
我们比较了OntoNotes开发集上的各种模型配置,以便为基于单词和基于字符的NER模型选择最佳设置,并了解格词信息对基于字符的模型的影响。
Character-based NER.
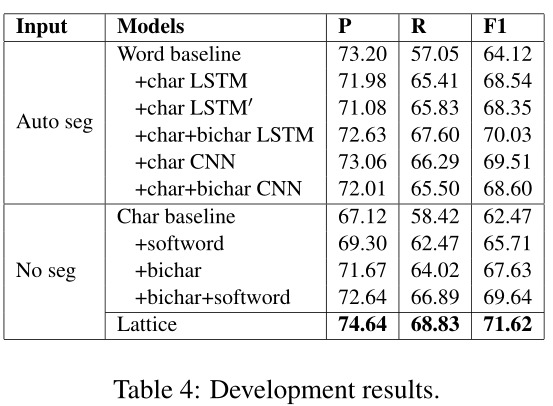
如表4所示,在不使用分词的情况下,基于字符的LSTM-CRF模型的发展得分为62.47%。如第3.1节所述,添加字符二元图和软词表示法可将F1分数分别提高到67.63%和65.71%,表明这两种信息来源的有用性。此外,两者的结合给出了69.64%的F1分数,这是各种字符表示中最好的。因此,我们在剩下的实验中选择了这个模型。
Word-based NER
表4显示了基于单词的中文NER的各种不同设置。通过自动分词,基于单词word-based 的LSTM-CRF基线给出了64.12%的F1分数,这比基于字符的基线更高。这说明文字信息和文字信息对汉语词汇学习都是有用的。第3.2节中使用字符LSTM丰富单词表示的两种方法,即word+char LSTM和word+char $LSTM^{'}$,导致了类似的改进。
与LSTM字符表示法相比,CNN字符序列表示法给出的F1分数略高。另一方面,进一步使用字符二元图信息character bigram information会导致F1得分高于word+charLSTM,而F1得分低于word+charCNN。一个可能的原因是CNN固有地捕捉字符n-gram信息。因此,在剩下的实验中,我们使用word+char+bichar-LSTM作为基于word的NER,得到了最好的发展结果,并且在结构上与文献中最先进的英语NER模型是一致的。
Lattice-based NER.
图4显示了基于角色和基于晶格的character-based and lattice-based 模型相对于训练迭代次数的分数。我们包括使用连接字符和字符双随机嵌入的concatenated character and character bigram embeddings模型,其中双随机可以在消除字符歧义方面发挥作用bigrams can play a role in disambiguating characters。从图中可以看出,格字信息有助于提高基于字符character-based的NER,将最佳开发结果从62.5%提高到71.6%。另一方面,bigram增强的格点模型bigram-enhanced lattice model与原格点模型相比没有得到进一步的改进。
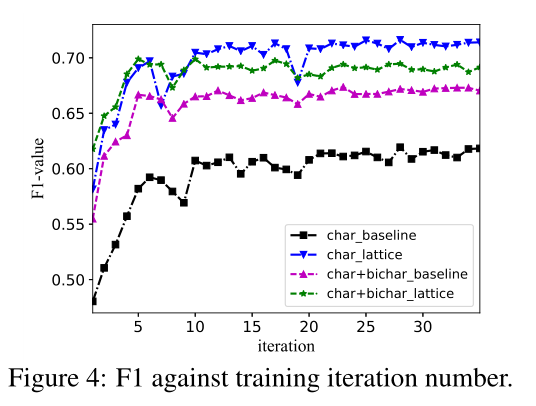
这可能是因为单词是字符消歧的更好的信息来源,而双字元也是模糊的。
如表4所示,lattice LSTM-CRF模型的发展F1得分为71.62%,与基于单词和基于字符的方法相比显著提高,尽管它不使用字符bigrams或分词信息。事实上,它明显优于char+softword,显示了格词信息相对于分词词信息的优势。
4.3 Final Results
OntoNotes.
试验结果见表5。使用黄金分割标准,我们基于单词的方法在数据集上提供了与最新技术相竞争的结果(Che等人,2013;Wang等人,2013),利用双语数据。这表明LSTM-CRF对于基于词的汉语NER是一个有竞争力的选择,对于其他语言也是如此。
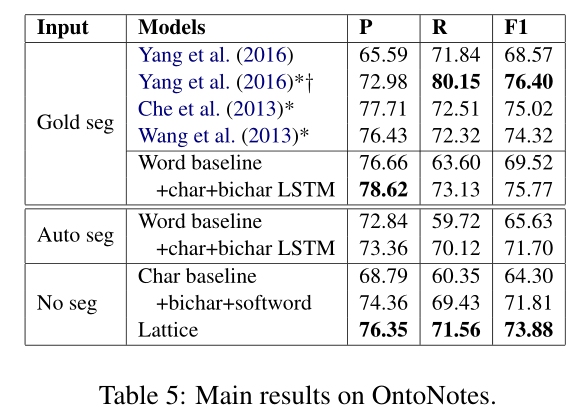
此外,结果显示,我们的基于词的模型可以作为高度竞争的基线。自动分词后,word+char+bicharlstm的F1得分从75.77%下降到71.70%,显示了分词对NER的影响。与开发集的观察结果一致,添加格词信息导致88.81% → 93.18%F1成绩较人物基线提高93.18%,高于88.81%→ 91.87%添加bichar+softword。格点模型在自动分割上给出了最好的F1分数。
MSRA.
MSRA数据集的结果如表6所示。对于这个基准,测试集上没有可用的goldstandard分段。我们选择的分节器在5倍交叉验证训练集上的准确率为95.93%。数据集上的最佳统计模型利用了丰富的手工特征(Chen等人,2006a;张等,2006;Zhou等人,2013)和字符嵌入特征(Lu等人,2016)。Dong等人(2016)利用具有激进特征的神经LSTM-CRF。
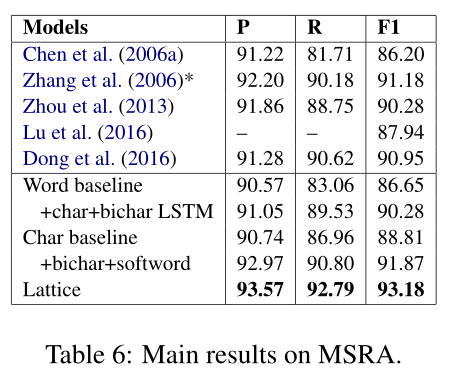
与现有的方法相比,我们的基于文字和基于字符的our wordbased and character-based LSTM-CRF模型具有较高的精度。格模型显著优于基于字符和基于单词的模型(p<0.01),在这个标准基准上取得了最好的结果。
Weibo/resume.
Weibo-NER数据集的结果如表7所示,其中NE、NM和Overall分别表示命名实体、标称实体(不包括命名实体)和两者的F1分数。黄金标准分割不适用于此数据集。现有最先进的系统包括Peng和Dredze(2016)以及He和Sun(2017b),他们探索了丰富的嵌入特征、跨域和半监督数据,其中一些与我们的模型正交
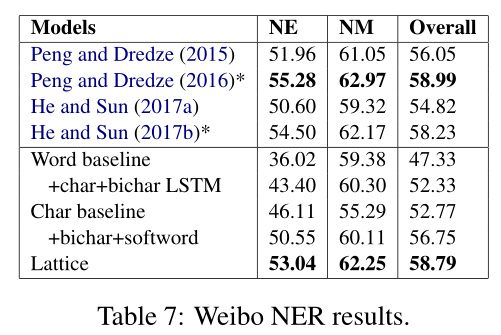
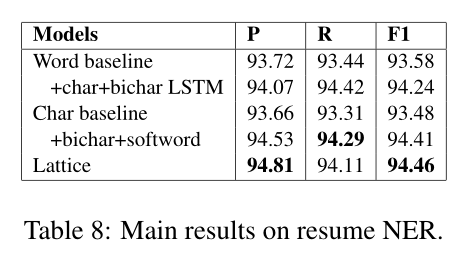
试验数据的结果如表8所示。与OntoNotes和MSRA的观察结果一致,lattice模型在微博和简历中的表现显著优于word-based mode and the character-based model(p<0.01),给出了最新的结果。
4.4 Discussion
F1 against sentence length.
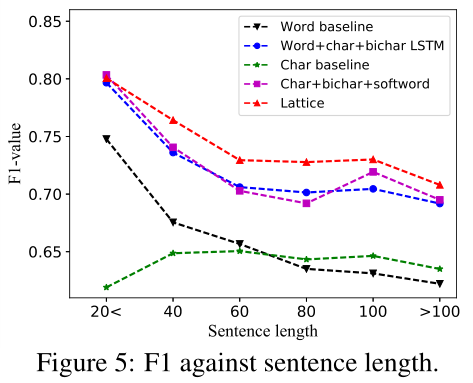
图5显示了OntoNotes数据集上基线模型和lattice LSTM-CRF的F1分数。基于字符的基线给出了相对稳定的F1分数在不同的句子长度,虽然表现相对较低。基于单词的基线在短句中给出了更高的F1分数,但在长句中给出了更低的F1分数,这可能是因为在长句中分词准确率较低。与各自的基线相比,word+char+bichar和char+bichar+softword具有更好的性能,这表明单词和字符表示对NER是互补的。格的准确度也随着句子长度的增加而降低,这可能是由于格中的词组合数呈指数增长所致。与word+char+bichar和char+bichar+softword相比,格模型对句子长度的增加表现出更强的鲁棒性,显示出对单词信息的更有效利用。
F1 against sentence length.
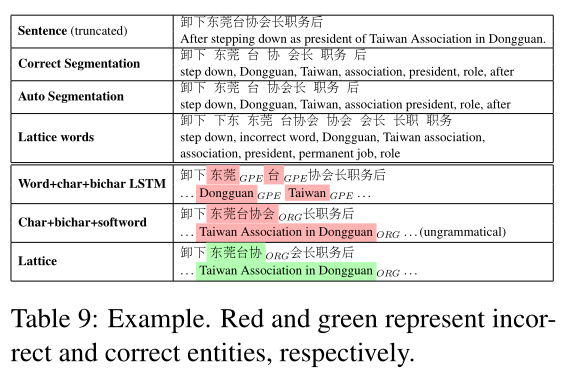
Table 9 shows a case study comparing char+bichar+softword, word+char+bichar and the lattice model. In the example, there is much ambiguity around the named entity “东莞台协 (Taiwan Association in Dongguan)”. Word+char+bichar yields the entities “东 莞 (Dongguan)” and “台 (Taiwan)” given that “东 莞台协 (Taiwan Association in Dongguan)” is not in the segmentor output. Char+bichar+softword recognizes “东 莞 台 协 会 (Taiwan Association in Dongguan)”, which is valid on its own, but leaves the phrase “长职务后” ungrammatical. In contrast, the lattice model detects the organization name correctly, thanks to the lattice words “东莞 (Dongguan)”, “会长 (President)” and “职 务 (role)”. There are also irrelevant words such as “台协会 (Taiwan Association)” and “下东 (noisy word)” in the lexicon, which did not affect NER results.
注意,word+char+bichar和lattice使用相同的单词信息源,即相同的预训练单词嵌入词典。然而,word+char+bichar首先在分词器中使用词汇,这对其子序列在NER中的使用施加了硬约束(即固定词)。相比之下,lattice-LSTM可以自由地考虑所有词汇词。
Entities in lexicon
表10显示了词典中实体的总数和它们各自的匹配比率。最后给出了基于最佳特征法(即“+bichar+softword”)的格点模型的误差缩减率。可以看出,错误减少在词典中匹配实体之间具有相关性。在这方面,我们的自动词典在某种程度上也起到了地名索引的作用(Ratinov和Roth,2009;Chiu和Nichols,2016),但还不完全清楚,因为词典中没有明确的知识表明哪些标记是实体。最终的消歧能力仍然在于格型编码器和监督学习。
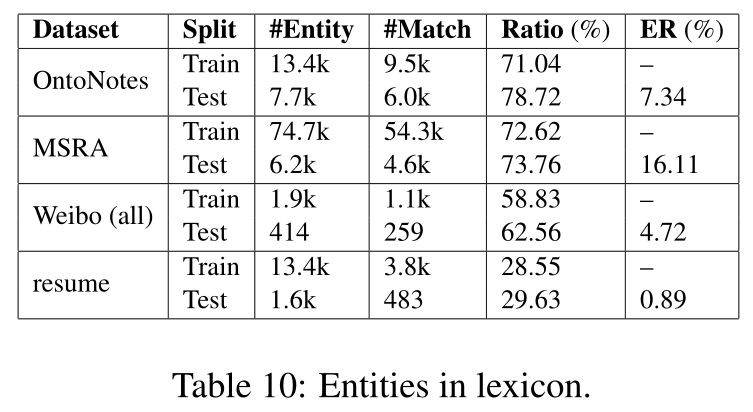
词典的质量可能会影响我们的NER模型的准确性,因为噪声词可能会混淆NER。另一方面,我们的格模型可以在训练过程中学习选择更正确的单词。我们把这种影响的调查留给今后的工作。
5 Conclusion
我们实证研究了一种适用于汉语NER的格型LSTM-CRF表示法,发现它在不同领域的表现都优于基于单词和基于字符的LSTM-CRF。格方法完全独立于分词,但由于可以在上下文中自由选择词汇进行消歧,因此在使用词汇信息时更为有效。yet more effective in using word information thanks to the freedom of choosing lexicon words in a context for NER disambiguation


 浙公网安备 33010602011771号
浙公网安备 33010602011771号