【神经网络】LSTM在Pytorch中的使用
先附上张玉腾大佬的内容,我觉得说的非常明白,原文阅读链接我放在下面,方面大家查看。
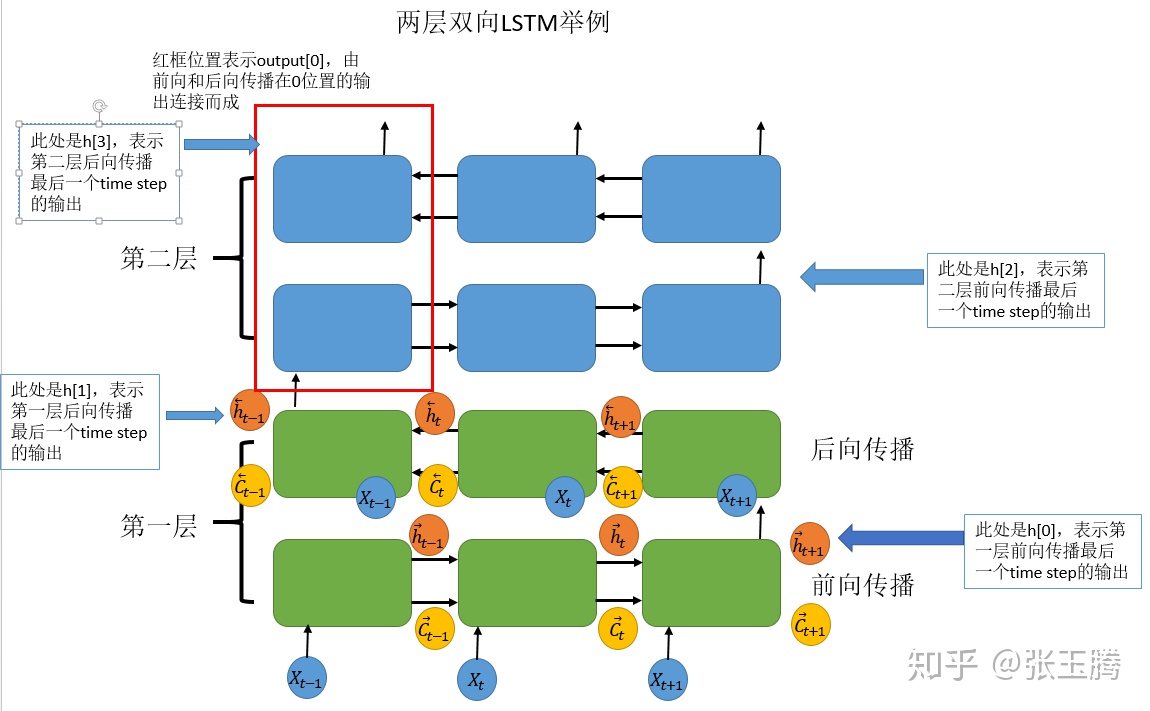
LSTM的输入与输出:
- output保存了最后一层,每个time step的输出h,如果是双向LSTM,每个time step的输出h = [h正向, h逆向] (同一个time step的正向和逆向的h连接起来)。
- h_n保存了每一层,最后一个time step的输出h,如果是双向LSTM,单独保存前向和后向的最后一个time step的输出h。
- c_n与h_n一致,只是它保存的是c的值。
1.output是一个三维的张量,第一维表示序列长度,第二维表示一批的样本数(batch),第三维是 hidden_size(隐藏层大小) * num_directions ,num_directions根据是“否为双向”取值为1或2。因此,我们可以知道,output第三个维度的尺寸根据是否为双向而变化,如果不是双向,第三个维度等于我们定义的隐藏层大小;如果是双向的,第三个维度的大小等于2倍的隐藏层大小。为什么使用2倍的隐藏层大小?因为它把每个time step的前向和后向的输出连接起来了。
这里引入一个问题为什么LSTM鼓励我们第一维不是batch,这与我们常规输入想悖,可以阅读 https://www.cnblogs.com/yuqinyuqin/p/14100967.html 这篇文章,醍醐灌顶
2.h_n是一个三维的张量,第一维是num_layers*num_directions,num_layers是我们定义的神经网络的层数,num_directions在上面介绍过,取值为1或2,表示是否为双向LSTM。第二维表示一批的样本数量(batch)。第三维表示隐藏层的大小。第一个维度是h_n难理解的地方。首先我们定义当前的LSTM为单向LSTM,则第一维的大小是num_layers,该维度表示第n层最后一个time step的输出。如果是双向LSTM,则第一维的大小是2 * num_layers,此时,该维度依旧表示每一层最后一个time step的输出,同时前向和后向的运算时最后一个time step的输出用了一个该维度。
举个例子,我们定义一个num_layers=3的双向LSTM,h_n第一个维度的大小就等于 6 (2*3),h_n[0]表示第一层前向传播最后一个time
step的输出,h_n[1]表示第一层后向传播最后一个time step的输出,h_n[2]表示第二层前向传播最后一个time step的输出,h_n[3]表示第二层后向传播最后一个time step的输出,h_n[4]和h_n[5]分别表示第三层前向和后向传播时最后一个time step的输出。
3. c_n与h_n的结构一样,就不重复赘述了
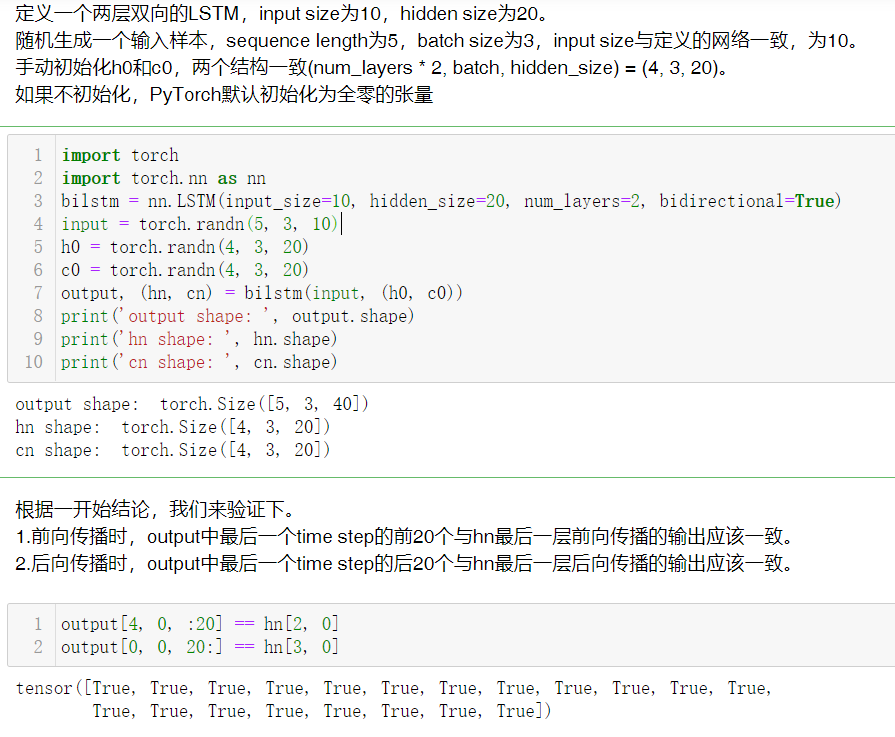
使用jupyter notebook代码验证下,发现确实如此:
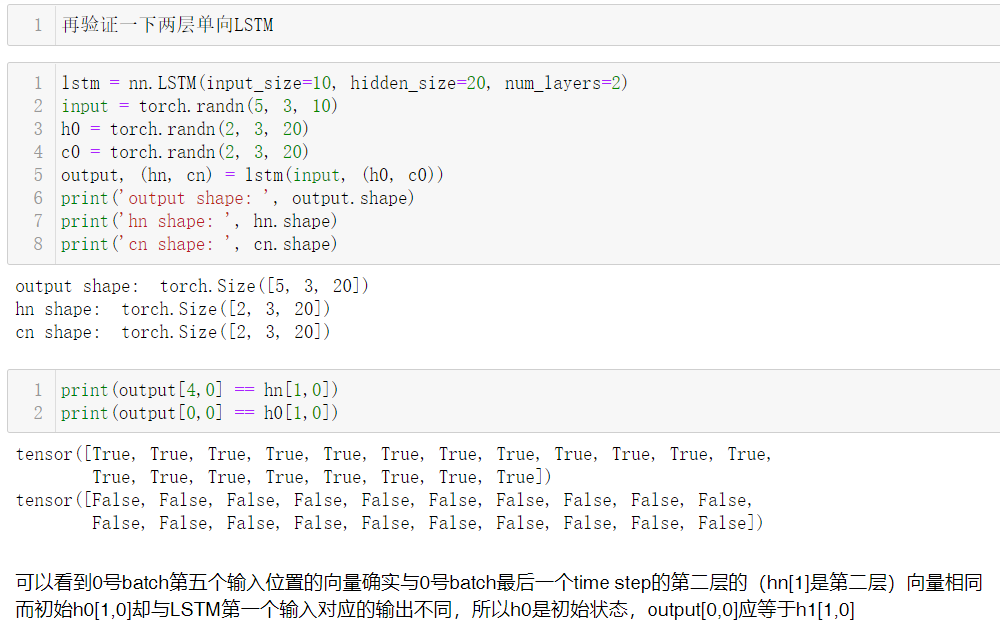
双向改为单向再验证一次:
下面在介绍我今天论文阅读的LSTM代码前,复习一个tensor.data操作:
如果我们想要修改tensor的数值,但是又不希望被autograd记录(即不会影响反向传播),那么我么可以对tensor.data进行操作。
1 x = torch.ones(1,requires_grad=True) 2 print(x.data) # 还是一个tensor 3 print(x.data.requires_grad) # 但是已经是独立于计算图之外 4 y = 2 * x 5 x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播 6 y.backward() 7 print(x) # 更改data的值也会影响tensor的值 8 print(x.grad) 9 #tensor([1.]) 10 #False 11 #tensor([100.], requires_grad=True) 12 #tensor([2.])
模型代码如下,主要任务是实现关系分类,LSTM是Encode部分中的一个组件:
1 class LSTM(nn.Module): 2 def __init__(self, config): 3 super(LSTM, self).__init__() 4 self.config = config 5 #ori_model = model_pattern(config = self) 接受传递来的参数 6 word_vec_size = config.data_word_vec.shape[0] #glove处理的词向量 7 self.word_emb = nn.Embedding(word_vec_size, config.data_word_vec.shape[1]) 8 #生成一个形状与 config.data_word_vec相同的Embedding,值是瞎J8生成的 9 self.word_emb.weight.data.copy_(torch.from_numpy(config.data_word_vec)) 10 # 将glove处理过的单词的权重拷贝入word_emb中 11 self.word_emb.weight.requires_grad = False 12 #预训练向量表中单词对应的权重不进行权重更新 13 14 self.coref_embed = nn.Embedding(config.max_length, config.coref_size, padding_idx=0) 15 self.ner_emb = nn.Embedding(7, config.entity_type_size, padding_idx=0) 16 '''句子长度不够的句子进行填充,比如用值0进行填充,当用nn.Embedding()''' 17 '''进行词向量嵌入时,对应的索引为0的向量将变为全为0的向量。这样就减少了填充值对模型训练的影响''' 18 '''把padding_idx设置为填充的值,如padding_idx=0,训练过程中索引为0的将始终设置为0,不进行参数更新''' 19 input_size = config.data_word_vec.shape[1] + config.coref_size + config.entity_type_size #+ char_hidden 20 hidden_size = 128 21 # EncoderLSTM初始化需要的参数(self, input_size, num_units, nlayers, concat, bidir, dropout, return_last) 22 self.rnn = EncoderLSTM(input_size, hidden_size, 1, True, False, 1 - config.keep_prob, False) 23 self.linear_re = nn.Linear(hidden_size, hidden_size) # *4 for 2layer 24 self.bili = torch.nn.Bilinear(hidden_size+config.dis_size, hidden_size+config.dis_size, config.relation_num) 25 self.dis_embed = nn.Embedding(20, config.dis_size, padding_idx=10) 26 27 #model(context_idxs, context_pos, context_ner, context_char_idxs, input_lengths, h_mapping, t_mapping, relation_mask, dis_h_2_t, dis_t_2_h) 28 def forward(self, context_idxs, pos, context_ner, context_char_idxs, context_lens, h_mapping, t_mapping,relation_mask, dis_h_2_t, dis_t_2_h): 29 #self.word_emb(context_idxs).shape = [40,512,config.data_word_vec.shape[1]] 30 #self.coref_embed(pos) = [40,512,config.coref_size] 31 #self.coref_embed(pos) = [40,512,config.coref_size] 32 sent = torch.cat([self.word_emb(context_idxs) , self.coref_embed(pos), self.coref_embed(pos)], dim=-1) 33 context_output = self.rnn(sent, context_lens) 34 #context_lens含有一个batch中句子多少个单词[510,456,389,...]已按句子长度顺序排好 [40,512,hidden_size=128] 35 context_output = torch.relu(self.linear_re(context_output)) 36 start_re_output = torch.matmul(h_mapping, context_output) #[40,1800,512]*[40,512,128]->[40,1800,128] 37 end_re_output = torch.matmul(t_mapping, context_output) 38 39 s_rep = torch.cat([start_re_output, self.dis_embed(dis_h_2_t)], dim=-1) 40 t_rep = torch.cat([end_re_output, self.dis_embed(dis_t_2_h)], dim=-1) 41 # self.dis_embed(dis_h_2_t).shape = [40,1800,20] 拼接过后s_rep.shape = [40,1800,128+20] 42 predict_re = self.bili(s_rep, t_rep) #predict_re.shape = [40,1800,97] 43 return predict_re
执行过程中真正用到LSTM的实际上是EncoderLSTM模块:
1 class LockedDropout(nn.Module): 2 def __init__(self, dropout): 3 super().__init__() 4 self.dropout = dropout 5 6 def forward(self, x): 7 dropout = self.dropout 8 if not self.training: 9 return x 10 m = x.data.new(x.size(0), 1, x.size(2)).bernoulli_(1 - dropout) #有(1-0.dropout)的几率某些元素置为1 11 mask = Variable(m.div_(1 - dropout), requires_grad=False) 12 mask = mask.expand_as(x) 13 return mask * x 14 15 class EncoderLSTM(nn.Module): 16 #(input_size, hidden_size, 1, True, False, 1 - config.keep_prob, False) 17 def __init__(self, input_size, num_units, nlayers, concat, bidir, dropout, return_last): 18 super().__init__() 19 self.rnns = [] 20 for i in range(nlayers): 21 if i == 0: 22 input_size_ = input_size 23 output_size_ = num_units 24 else: 25 input_size_ = num_units if not bidir else num_units * 2 26 output_size_ = num_units 27 self.rnns.append(nn.LSTM(input_size_, output_size_, 1, bidirectional=bidir, batch_first=True)) 28 self.rnns = nn.ModuleList(self.rnns) 29 self.init_hidden = nn.ParameterList([nn.Parameter(torch.Tensor(2 if bidir else 1, 1, num_units).zero_()) for _ in range(nlayers)]) 30 self.init_c = nn.ParameterList([nn.Parameter(torch.Tensor(2 if bidir else 1, 1, num_units).zero_()) for _ in range(nlayers)]) 31 self.dropout = LockedDropout(dropout) 32 self.concat = concat 33 self.nlayers = nlayers 34 self.return_last = return_last 35 # self.reset_parameters() 36 37 def reset_parameters(self): 38 for rnn in self.rnns: 39 for name, p in rnn.named_parameters(): 40 if 'weight' in name: 41 p.data.normal_(std=0.1) 42 else: 43 p.data.zero_() 44 45 def get_init(self, bsz, i): 46 return self.init_hidden[i].expand(-1, bsz, -1).contiguous(), self.init_c[i].expand(-1, bsz, -1).contiguous() 47 48 def forward(self, input, input_lengths=None): 49 bsz, slen = input.size(0), input.size(1) 50 output = input 51 outputs = [] 52 #获取输入batch的所有数据的长度 53 if input_lengths is not None: 54 lens = input_lengths.data.cpu().numpy() 55 56 for i in range(self.nlayers): 57 hidden, c = self.get_init(bsz, i) 58 output = self.dropout(output) #输入input进行dropout 59 if input_lengths is not None: 60 output = rnn.pack_padded_sequence(output, lens, batch_first=True) 61 #pack_padded_sequence 是先补齐到相同长度 再压紧,详见下方学习链接,batch_first = True只对input与output起作用 62 output, hidden = self.rnns[i](output, (hidden, c)) 63 if input_lengths is not None: 64 output, _ = rnn.pad_packed_sequence(output, batch_first=True) 65 #反过来,对压紧后的序列,进行扩充补齐操作。 66 if output.size(1) < slen: # used for parallel 67 padding = Variable(output.data.new(1, 1, 1).zero_()) 68 #output.data.new(1, 1, 1)意义:继承output维度的新Tensor,shape为(1,1,1) 69 output = torch.cat([output, padding.expand(output.size(0), slen-output.size(1), output.size(2))], dim=1) 70 #从数据长度那维度(第二维)padding,把pack,pad过程损失的output.shape还原出来 71 if self.return_last: 72 outputs.append(hidden.permute(1, 0, 2).contiguous().view(bsz, -1)) 73 #shape:[seq_len,bsz,count_dim]->[bsz,seq_len,count_dim]->[b,seq_len*count_dim] 74 #另外如果这里没有contiguous(),View无法工作,因为permute操作将重新定义下标与元素的对应关系 75 #内部数据的布局方式和从头开始创建一个这样的常规的tensor的布局方式不一样了 76 else: 77 outputs.append(output) 78 if self.concat: 79 return torch.cat(outputs, dim=2) #需要拼接,将每一层得到的output的最后一维hidden进行拼接 80 return outputs[-1] #返回最后一层的output input.shape = [40,512,100+20+20] output.shape = [40,512,hidden_size=128]
参考:
关于nn.embedding的中padding_idx的含义: https://blog.csdn.net/weixin_40426830/article/details/108870956
pytorch中的nn.Bilinear的计算原理详解 : https://blog.csdn.net/nihate/article/details/90480459
梯度:torch的.data方法: https://tangshusen.me/Dive-into-DL-PyTorch/#/chapter02_prerequisite/2.3_autograd
PyTorch中LSTM的输出格式: https://zhuanlan.zhihu.com/p/39191116
Pytorch—tensor.expand_as()函数示例: https://blog.csdn.net/wenqiwenqi123/article/details/101306839
torch.nn.utils.rnn.pack_padded_sequence解读: https://www.cnblogs.com/yuqinyuqin/p/14100967.html
torch.matmul()用法介绍: https://blog.csdn.net/qsmx666/article/details/105783610


 浙公网安备 33010602011771号
浙公网安备 33010602011771号