

Unix网络编程 3.9 readline函数
其实看APUE时就想试着写些简单的stdio函数了,但是一直没实践,看到这里时发现书上写得不完整,便敲代码试了下。
第1个readline速度非常慢原因在于每次读取字符都执行了系统调用read(),而系统调用意味着内核态和用户态之间的切换,系统调用数量太多会导致切换过程非常费时。因此为了快速的进行I/O,往往会定义一个缓冲区,即第2个readline中的char read_buf[MAXLINE];以及记录读取数量的int read_cnt;和记录当前读取指针的char *read_ptr;这三个静态变量都是static类型,也就是当前文件可用,外部文件无法访问static变量。
static ssize_t my_read(int fd, char* ptr)
{
if (read_cnt <= 0) {
again:
if ((read_cnt = read(fd, read_buf, sizeof(read_buf))) < 0) {
if (errno == EINTR)
goto again;
return -1;
} else if (read_cnt == 0)
return 0;
}
read_cnt--;
*ptr = *read_ptr++;
return 1;
}
关键在于用my_read来替换read。my_read是从缓冲区中(而不是从文件中)逐个读取数据。
由于一开始缓冲中什么都没有,对应的状态即read_cnt=0(读取数量为0),read_ptr指向read_buf首部。所以最开始需要填满缓冲区,读取MAXLINE(行缓冲区大小),将文件的数据读到缓冲区中。然后read_cnt初始化为read函数实际读取的数量。
比如我这里MAXLINE是4096,但是若文件实际总大小没有这么多,返回的read_cnt就小于MAXLINE。
然后read_cnt大于0就意味着缓冲区有未读的数据,于是每次调用my_read只需要从read_buf中读取1个字符,然后移动指针read_ptr到下个字符,并减少read_cnt。
由于read_cnt记录的是read函数实际读取的数量,所以归0时代表缓冲区元素已经读完了,需要再次调用read函数读取最多MAXLINE个字符。
这里采用了goto,原因就像书上所说的,在字节流套接字上调用read/write输入或输出的字节数可能比请求的数量少,此时并不一定是出错,而是因为内核中用于套接字的缓冲区已经到达了极限,需要再次(反复)调用read/write函数来输入或输出剩下的字节。
而errno被设置为EINTR的原因如下
EINTR The call was interrupted by a signal before any data was read;
被信号打断,此时需要反复读取至成功为止。
原理说完了,测试代码如下
#define MAXLINE 4096
static int read_cnt = 0; static char read_buf[MAXLINE]; static char* read_ptr = read_buf; // ... // UNPv3 P74-75的readline.c代码 // ... int main(void) { char buf[MAXLINE]; for (int i = 0; i < 5; i++) { ssize_t n = readline(STDIN_FILENO, buf, MAXLINE); write(STDOUT_FILENO, buf, n); } return 0; }
测试代码如上,从输入流中读取了5行并打印出来
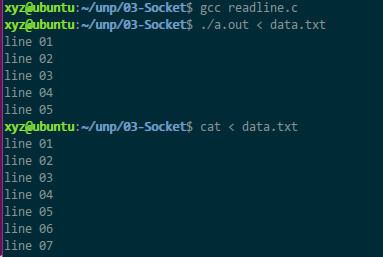
用strace查看系统调用如下
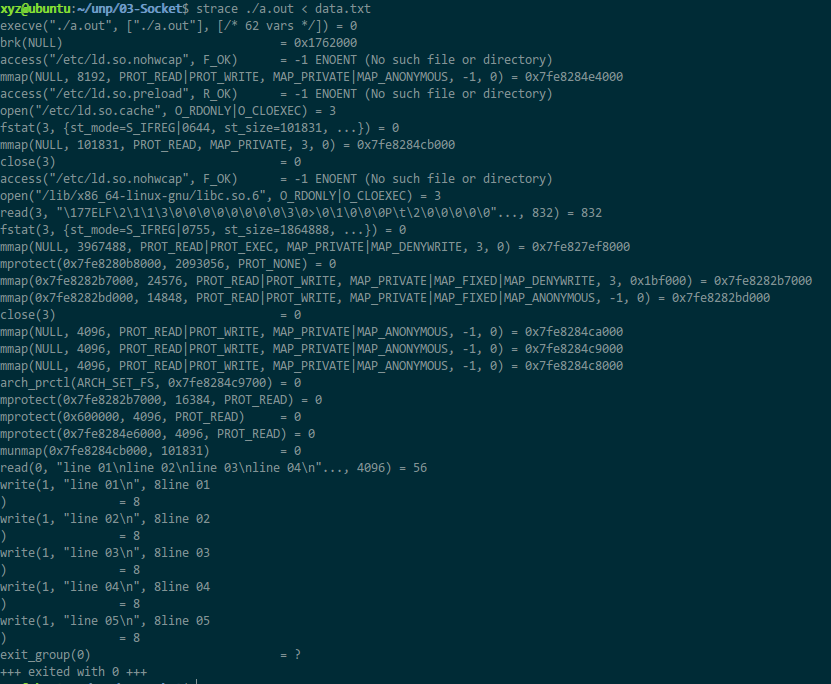
可以发现只调用了1次read(不包含进入main前的部分),然后write了5次。
如果把if ((rc = my_read(fd, &c)) == 1) 改成if ((rc = read(fd, &c, 1)) == 1) 再调用strace
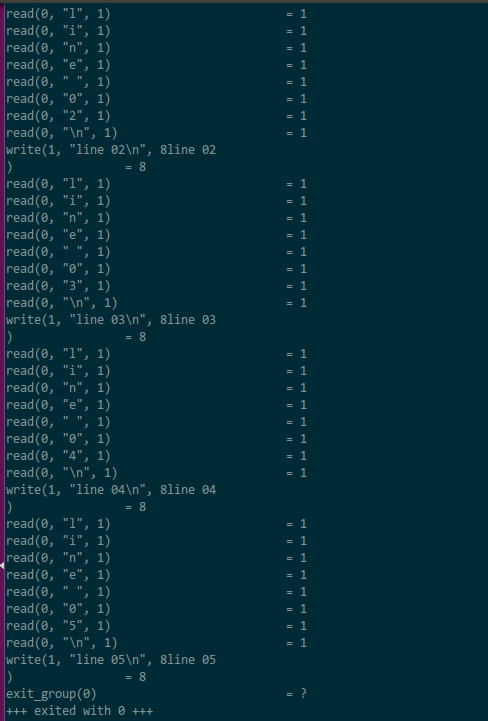
可见系统调用数量之多

