CTF misc图片类总结(入门级)
文章目录
misc文件头尾
文件隐写和图片隐写步骤
misc思路
MISC文件隐写总结(图片,音频,视频,压缩包等文件)
misc图片类总结(新赛题)
一、改高宽
打开图片发现下面好像少了什么。

WinHex打开可以看到PNG的文件头
解析:
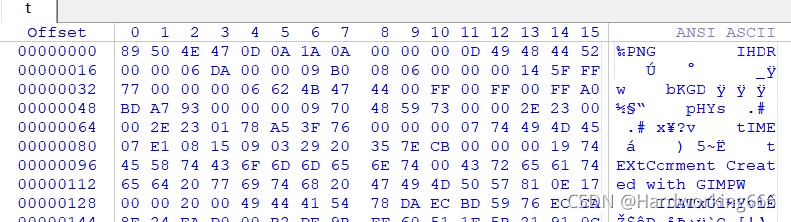
(固定)八个字节89 50 4E 47 0D 0A 1A 0A为png的文件头
(固定)四个字节00 00 00 0D(即为十进制的13)代表数据块的长度为13
(固定)四个字节49 48 44 52(即为ASCII码的IHDR)是文件头数据块的标示(IDCH)
(可变)13位数据块(IHDR)
前四个字节代表该图片的宽
后四个字节代表该图片的高
后五个字节依次为:
Bit depth、ColorType、Compression method、Filter method、Interlace method
(可变)剩余四字节为该png的CRC检验码,由从IDCH到IHDR的十七位字节进行crc计算得到。
文件尾:AE 42 60 82
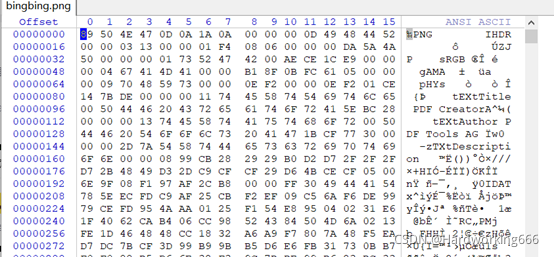
图片尺寸为787x500(高x宽)
00 00 00 0D 说明IHDR头块长为13
49 48 44 52 IHDR标识
00 00 03 13 图像的宽,787像素
00 00 01 F4 图像的高,500像素
发现高宽错误
这里需要注意的是,文件宽度不能任意修改,需要根据 IHDR 块的 CRC 值爆破得到宽度,否则图片显示错误不能得到 flag
import os
import binascii
import struct
crcbp = open("D:\\桌面文件\\bingbing.png", "rb").read() #打开图片
for i in range(2000):
for j in range(2000):
data = crcbp[12:16] + \
struct.pack('>i', i)+struct.pack('>i', j)+crcbp[24:29]
crc32 = binascii.crc32(data) & 0xffffffff
if(crc32 == 0xda5a4a50): #图片当前CRC
print(i, j)
print('hex:', hex(i), hex(j))
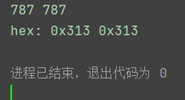
把高宽都改成787保存得flag

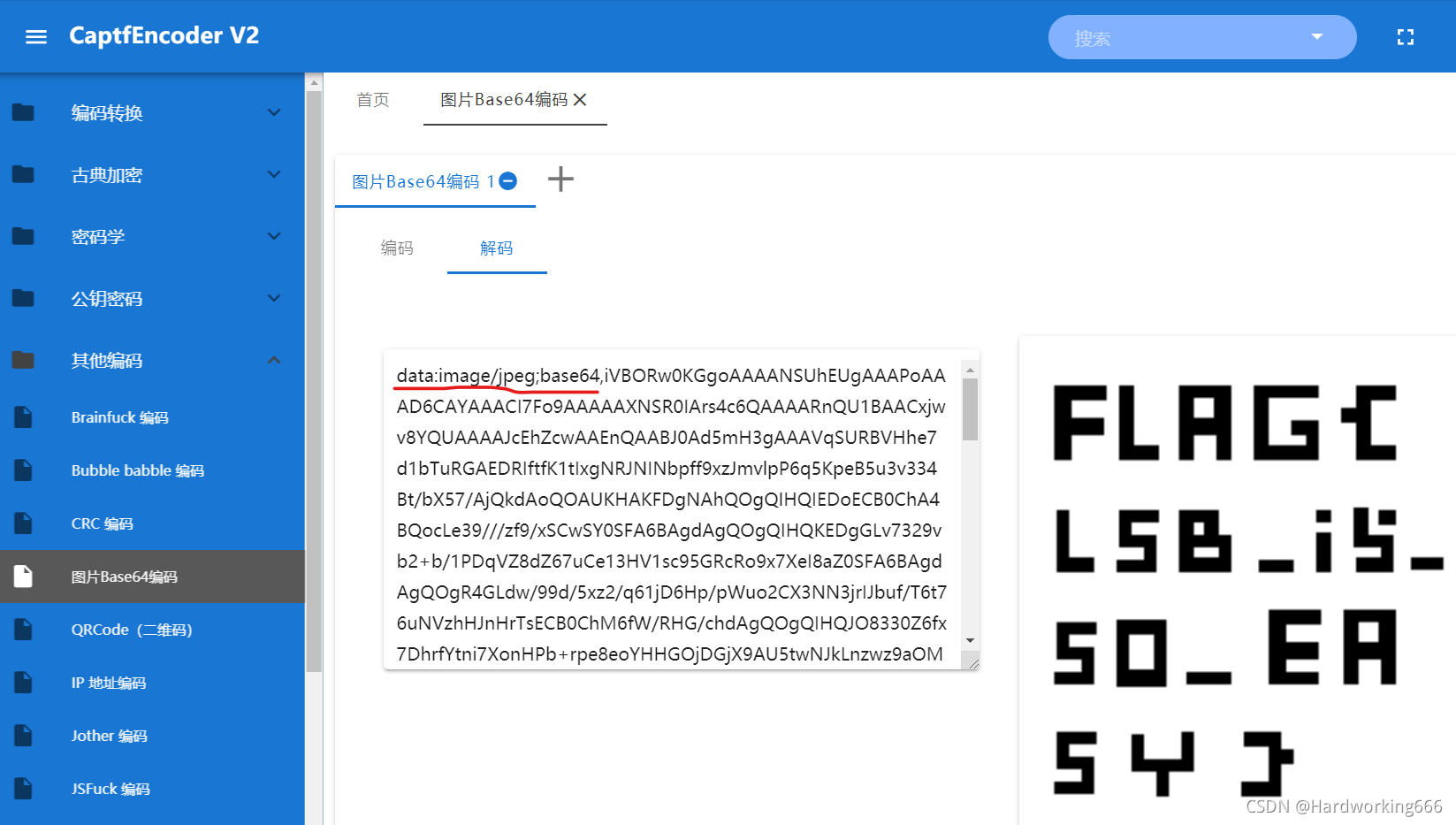
二、lsb(最低有效位)隐写+base64编码图片
攻防世界Misc高手进阶区 3-11
下载png文件,binwalk,发现zlib文件。
binwalk详解

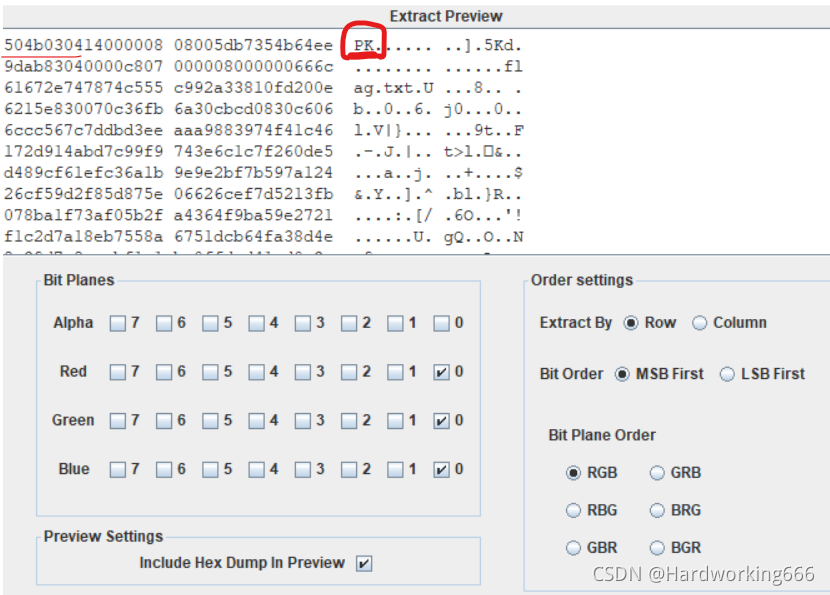
LSB隐写,save bin,改后缀解压,弹出已损坏,用winrar自带的修复

结尾的=号判断是base64编码,开头iVBORw0K说明是base64编码的图片。
用captfencoder加上头,转为图片:FLAG{LSB_i5_SO_EASY}
CRC32碰撞脚本
Misc中的有一类题目是要求我们知道加密后的rar文件中的内容。但是rar文件密码我们不知道,直接爆破密码也不是很现实。
但是当文件的大小比较小,或者字符数量较少时,就可以根据crc校验码来爆破出rar内部文件的内容。

可以看到最后一列是对应文件的CRC校验码。并且每个文件只有4字节,所以可以看作每个CRC校验码都对应了唯一的文件。Python2爆破如下:
import binascii
import string
dic=string.printable #打印出字符表
crc1=0x7DE0AB32
crc2=0xB1441D53
crc3=0x49BD11F5
crc4=0xB42F1DFA
crc5=0x8163F43E
crc6=0x1FC8FEE5
for i in dic:
for j in dic:
for n in dic:
for m in dic:
s=i+j+n+m
if(crc1==(binascii.crc32(s) & 0xffffffff)):
text1=s
if (crc2 == (binascii.crc32(s) & 0xffffffff)):
text2=s
if (crc3 == (binascii.crc32(s) & 0xffffffff)):
text3=s
if (crc4 == (binascii.crc32(s) & 0xffffffff)):
text4=s
if (crc5 == (binascii.crc32(s) & 0xffffffff)):
text5=s
if (crc6 == (binascii.crc32(s) & 0xffffffff)):
text6=s
print text1+text2+text3+text4+text5+text6
三、盲水印+明文攻击
攻防世界Misc的warmup,2017ciscn(全国大学生信息安全竞赛)
下载打开,两个一样的open_forun.png, 明文攻击,将open_forum.png压缩成zip,然后使用ARCHPR的明文攻击

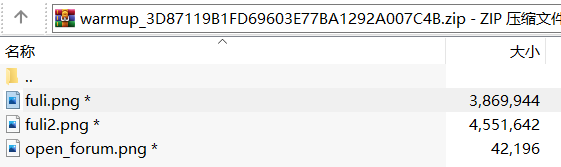
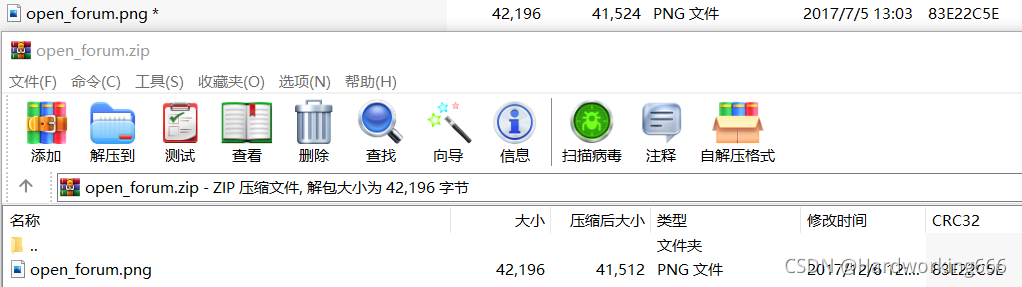
注:两个open_forum.png的crc32的值一样,以及两个文件被压缩之后的大小,满足明文攻击要求。
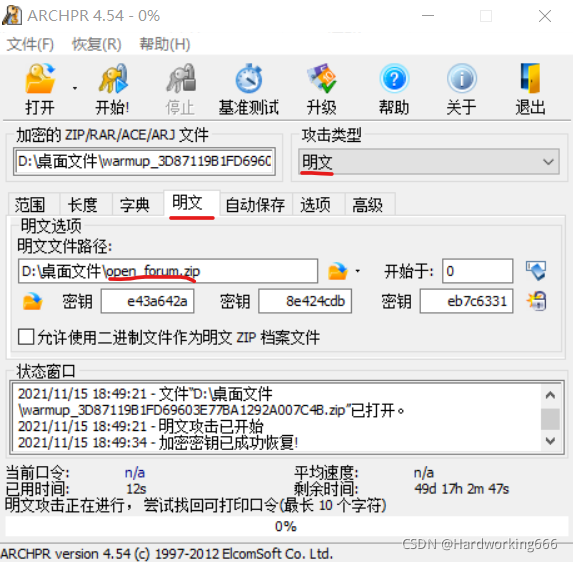
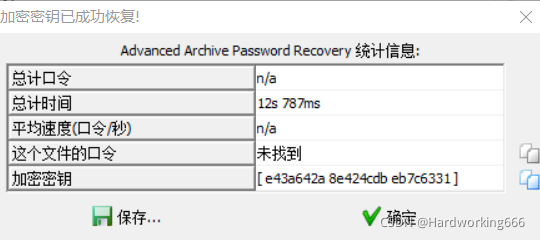
解压出来是这样:
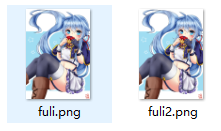
两个图,试试盲水印:
python bwmforpy3.py decode fuli.png fuli2.png flag.png --oldseed
注:如果要让python3兼容python2的random算法请加 --oldseed参数。结果就是flag.png。


傅里叶盲水印
VNCTF021 冰冰好像藏着秘密
傅里叶盲水印原理:
图片经过傅里叶变换后,水印图片直接按像素覆盖到频率域,因为频谱是中心对称的,所以加水印也要对称的加,具体就是图片分上下两部分,左上加了什么,右下也要加同样的内容。之后傅里叶反变换回去。解水印的时候变换到傅里叶变换提取就可以了。
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
img = cv.imread('D:\\CTF\\FFT.png', 0) #直接读为灰度图像,不过此题已经是灰度图片了
f = np.fft.fft2(img) #做频率变换
fshift = np.fft.fftshift(f) #转移像素做幅度谱
s1 = np.log(np.abs(fshift))#取绝对值:将复数变化成实数取对数的目的为了将数据变化到0-255
plt.subplot(121)
plt.imshow(img, 'gray')
plt.title('original')
plt.subplot(122)
plt.imshow(s1,'gray')
plt.title('center')
plt.show()
四、IDAT块隐写
提数据+zlib解压+625二维码
图像数据块 IDAT(image data chunk):它存储实际的数据,在数据流中可包含多个连续顺序的图像数据块。IDAT 块只有当上一个块充满时,才会继续一个新的块。
pngcheck.exe -v sctf.png
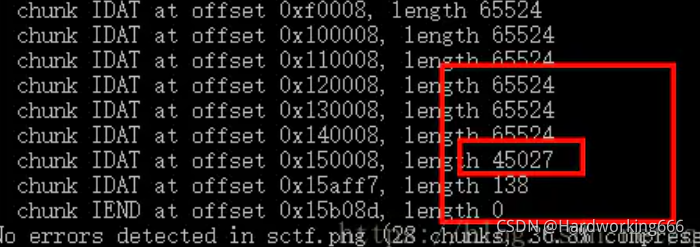
前面的块都是65524,到了0x150008变为45027,再到0x15aff7的138。
很明显最后一个 IDAT 块是有问题的,因为他本来应该并入到倒数第二个未满的块里。
0x150008中的45027位数据是正常的图片信息。0x15aff7的138位数据是人为录入的,且所在的数据块也是人为创建的。
IDAT中的数据采用 LZ77 算法的派生算法进行压缩,所以可以用 zlib 解压缩。
可以用010 editor直接提取出数据,然后扔进zlib解压脚本里解压获得原始数据。
查看异常数据块的情况,使用010editor/winhex打开,导出异常数据块:
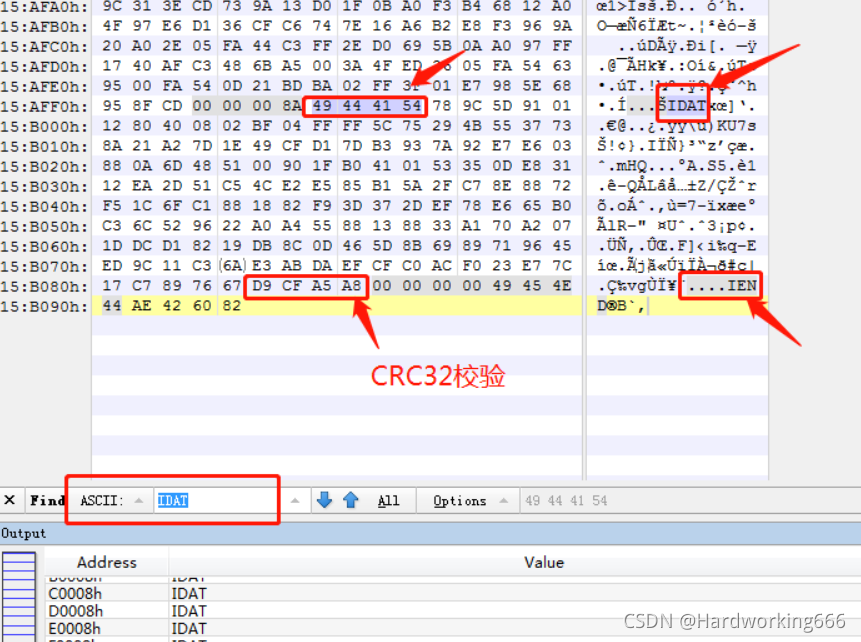
查找78 9C文件头标志,zlib。
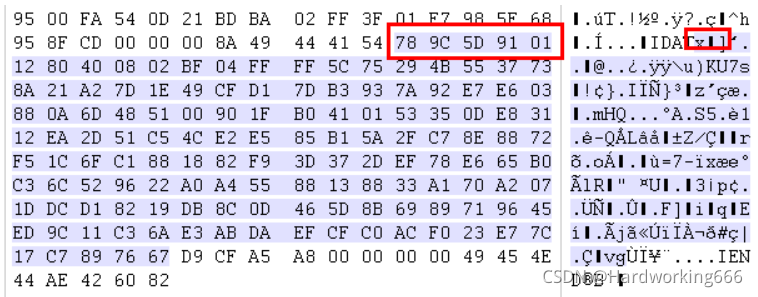
将异常的IDAT数据块斩头去尾之后使用脚本解压,在python2代码如下:
import zlib
import binascii
IDAT = "789C5D91011280400802BF04FFFF5C75294B5537738A21A27D1E49CFD17DB3937A92E7E603880A6D485100901FB0410153350DE83112EA2D51C54CE2E585B15A2FC78E8872F51C6FC1881882F93D372DEF78E665B0C36C529622A0A45588138833A170A2071DDCD18219DB8C0D465D8B6989719645ED9C11C36AE3ABDAEFCFC0ACF023E77C17C7897667".decode('hex')
result = binascii.hexlify(zlib.decompress(IDAT))
print (result.decode('hex'))
print (len(result.decode('hex')))
得到压缩后的文件:
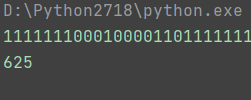
发现是625,是一个二维码的矩阵,使用python2代码做成二维码:
from PIL import Image
MAX = 25
pic = Image.new("RGB",(MAX,MAX))
str ="1111111000100001101111111100000101110010110100000110111010100000000010111011011101001000000001011101101110101110110100101110110000010101011011010000011111111010101010101111111000000001011101110000000011010011000001010011101101111010101001000011100000000000101000000001001001101000100111001111011100111100001110111110001100101000110011100001010100011010001111010110000010100010110000011011101100100001110011100100001011111110100000000110101001000111101111111011100001101011011100000100001100110001111010111010001101001111100001011101011000111010011100101110100100111011011000110000010110001101000110001111111011010110111011011"
i=0
for y in range(0,MAX):
for x in range(0,MAX):
if(str[i] == '1'):
pic.putpixel([x,y],(0,0,0))
else:pic.putpixel([x,y],(255,255,255))
i = i+1
pic.show()
pic.save("flag.png")
运行得到二维码
png末尾藏zip
PNG (png),文件头:89504E47 文件尾:49454E44AE426082
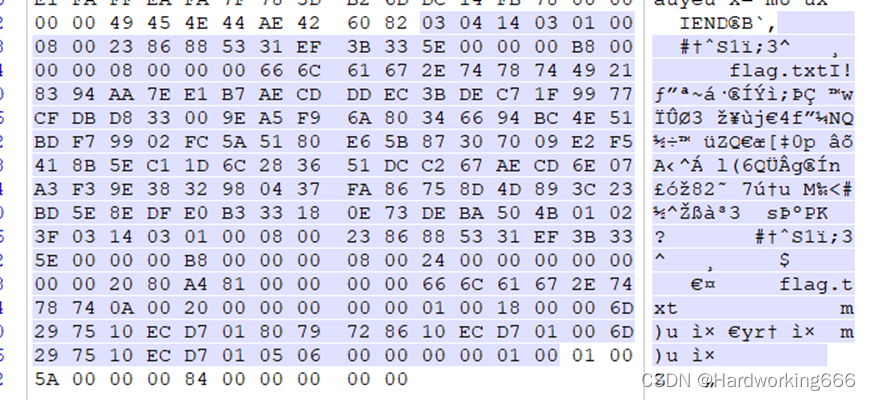
从0304后全部保存,在前面和后面加上504B,后保存为zip

用stegpy得到zip密码:

五、分离与拼接
convert分离gif+montage拼接
攻防世界MISC进阶:glance-50,mma-ctf-2nd-2016
下载拿到一个gif图片,很窄(宽2px)。
(1)用kali的convert命令先把gif分解开:
convert glance.gif flag.png
补充:
水平镜像反转图片
convert -flop reverse.jpg reversed.jpg
垂直镜像反转图片
convert -flip reverse.jpg reversed.jpg
总共分离出来200个图片。用工具:montage合成,命令:
montage flag*.png -tile x1 -geometry +0+0 flag.png
-tile是拼接时每行和每列的图片数,这里用x1,就是只一行
-geometry是首选每个图和边框尺寸,我们边框为0,图照原始尺寸即可
flag:TWCTF{Bliss by Charles O’Rear}
(2)也可以直接用网站。GIF动态图片是由多张静态图片组合而成,按照一定的顺序和时间进行播放。该网站将GIF图片反向分解成一张张静态图。GIF图片有多少帧,就有多少张静态图片。
GIF分解网站
(3)也可以写脚本
import os
from PIL import Image
im = Image.new('RGB', (2*201,600))#new(mode,size) size is long and width
PATH = 'E:/ctf/glance.gif'
FILE_NAME = [i for i in os.listdir(PATH)]
width = 0
for i in FILE_NAME:
im.paste(Image.open(PATH+i),(width,0,width+2,600))#box is 左,上,右,下
width += 2
im.show()
六、像素点合成
1、PPM格式+多种文件转换网站
攻防世界 Misc Miscellaneous-200 defkthon-ctf
miscellaneous
adj. 混杂的; 各种各样的;
(1)提供的flag.txt文件每行包含由三个逗号分隔的值组成的元组。这看起来像一个给定RGB值的图像。

总共有61366行:
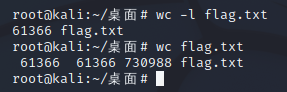
注:Linux wc命令用于计算字数。
-l或–lines 显示行数。
-w或–words 只显示字数。
-c或–bytes或–chars 只显示Bytes数。
flag.txt文件的行数为61366、单词数61366、字节数730988
图像的尺寸是这个数字(61366)的等分,所以可能是:1,2,61,122,503,1006,30683,61366。
最可能的图像大小是 122×503px 或 503×112px 。
注:px是分辨率的单位,是英语单词pixel的缩写,意为像素(组成屏幕图像的最小独立元素)。
将文本文件转换为图像的最可以将其转换为PPM格式,其标题如下:
P3
122 503
255
注:PPM(Portable PixMap,便携式像素映射)。这些图片格式都相对比较容易处理,跟平台无关,所以称之为portable,简单理解,就是比较直接的图片格式,比如PPM,其实就是把每一个点的RGB分别保存起来。所以,PPM格式的文件是没有压缩的,相对比较大,但是由于图片格式简单,一般作为图片处理的中间文件(不会丢失文件信息),或者作为简单的图片格式保存。
PPM文件
PPM文件格式详解
然后是flag.txt的内容,逗号用空格替换。(快捷键ctrl+h 实现替换的功能)

TXT到PPM转换器
这个网站可以转换许多东西!
结果是flag.ppm。用极速看图软件打开(kali中可以直接打开):

转换为PNG,并翻转+旋转它,使它更容易阅读,结果如下图所示:
convert -flip -rotate 90 flag.ppm flag.png

(2)分析文本发现是道画图题,直接编写 python 程序
from ast import literal_eval as make_tuple
from PIL import Image
f = open('flag.txt', 'r')
corl = [make_tuple(line) for line in f.readlines()]
f.close()
img0 = Image.new('RGB', (270, 270), '#ffffff')
k=0
for i in range(246):
for j in range(246):
img0.putpixel ([i , j], corl[k])
k=k+1
img0.save("result.png")
flag{ youc@n’tseeme }
七、流量类
1、wireshark提取数据流//tcpxtract
攻防世界misc进阶Cephalopod
用wireshark搜索flag字符串,可以看到
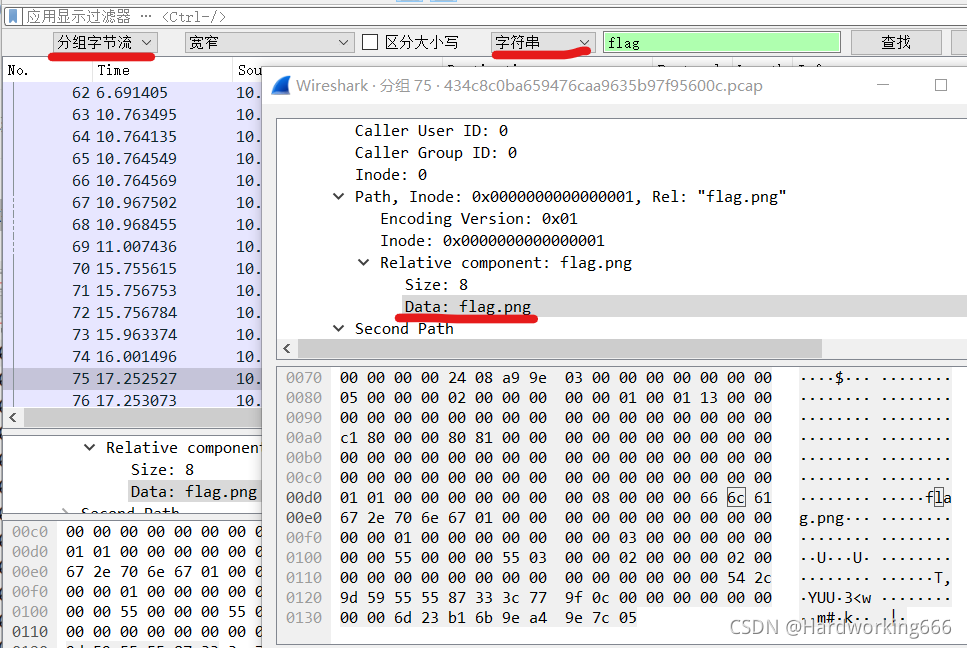
PNG头的16进制为89504E47,然后搜索该16进制,找到一条TCP报文,然后追踪TCP流。
可以看到这是一个图片数据流。尾为:文件尾:AE 42 60 82。保留原始数据。
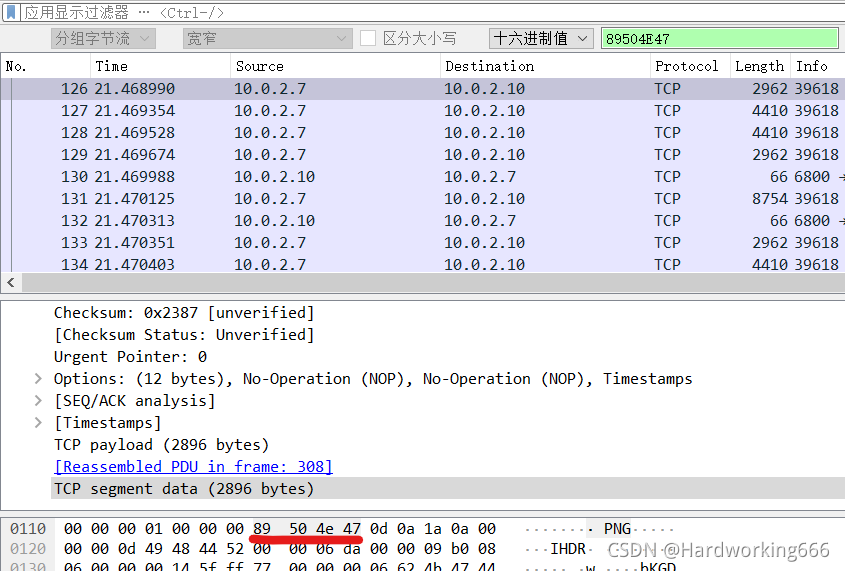
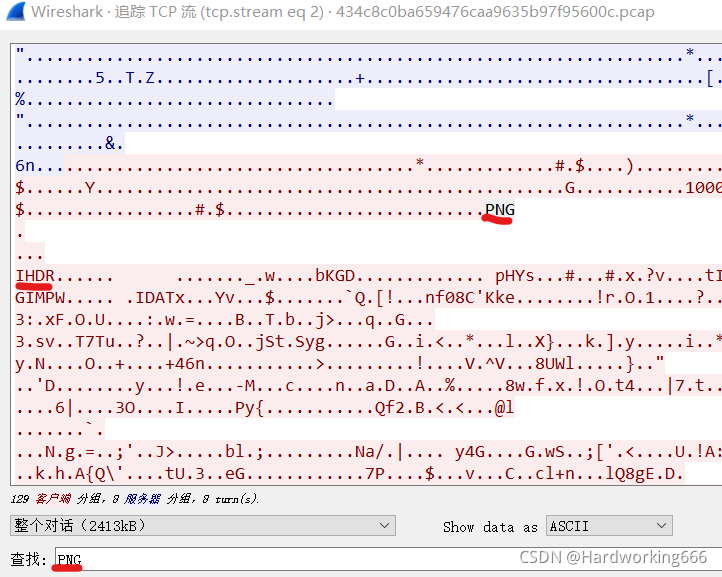
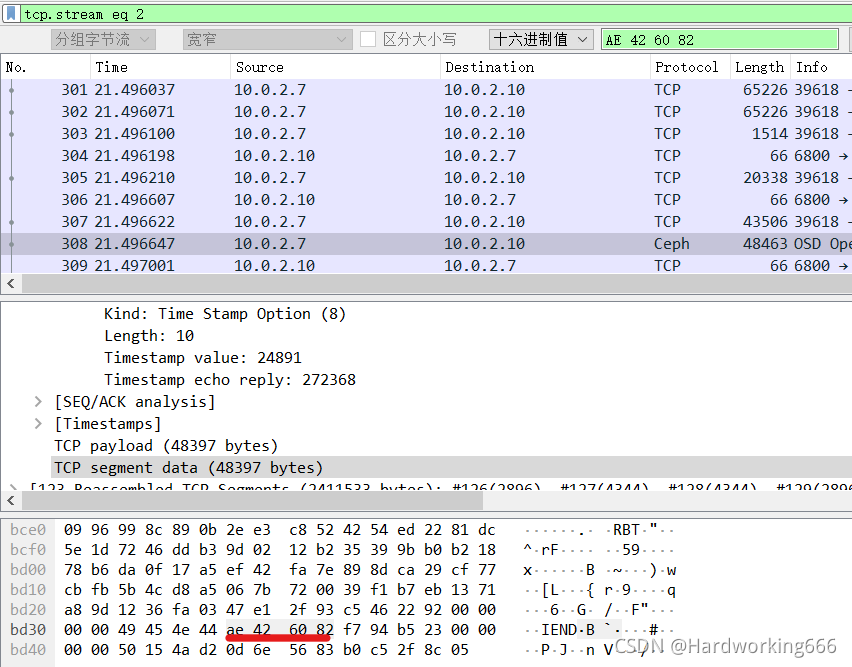
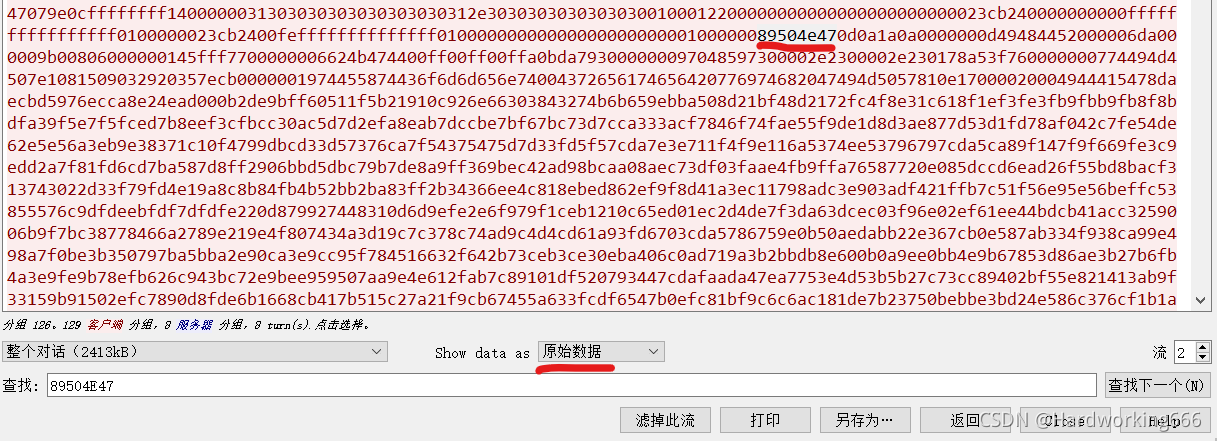
然后复制进去winhex只保留png头尾数据,然后修改文件后缀名为png,就可以得到flag图片
tcpxtract
也可以直接
tcpxtract -f 1.pcap
得到一张png图片 得到flag :HITB{95700d8aefdc1648b90a92f3a8460a2c}
Tcpxtract是用来从网卡抓包并将其还原成文件的一个开源软件,它的基本原理是在抓取的数据包中匹配文件的特征头和特征尾。
strings
strings webshell.pcapng | grep {
strings命令在对象文件或二进制文件中查找可打印的字符串。字符串是4个或更多可打印字符的任意序列,以换行符或空字符结束。 strings命令对识别随机对象文件很有用。 grep 命令用于查找文件里符合条件的字符串
strings xxx.png
有时可以出flag
2、协议分级+导出HTTP对象
攻防世界-互相伤害!!!
wireshark打开,协议分级,基本都是TCP流量,又以超文本传输协议为主,导出HTTP对象。
八、二维码类
1、bmp转二维码
攻防世界 Misc高手low
下来一个bmp文件,用stegsolve分析无果,但是通过观察发现是RGB的通道有问题,利用的是图片中最低位的奇偶性。
实验吧原题直接用画图另存为png格式,用StegSolve打开后,调到RGB红色位置。这里有所变化
转QR Code,即二维码(Quick Response Code)
# lsb隐写
import PIL.Image as Image
img = Image.open('low.bmp')
img_tmp = img.copy()
pix = img_tmp.load()
width,height = img_tmp.size
for w in range(width):
for h in range(height):
if pix[w,h]&1 == 0:
pix[w,h] = 0
else:
pix[w,h] = 255
img_tmp.show()

用QR research解码得:
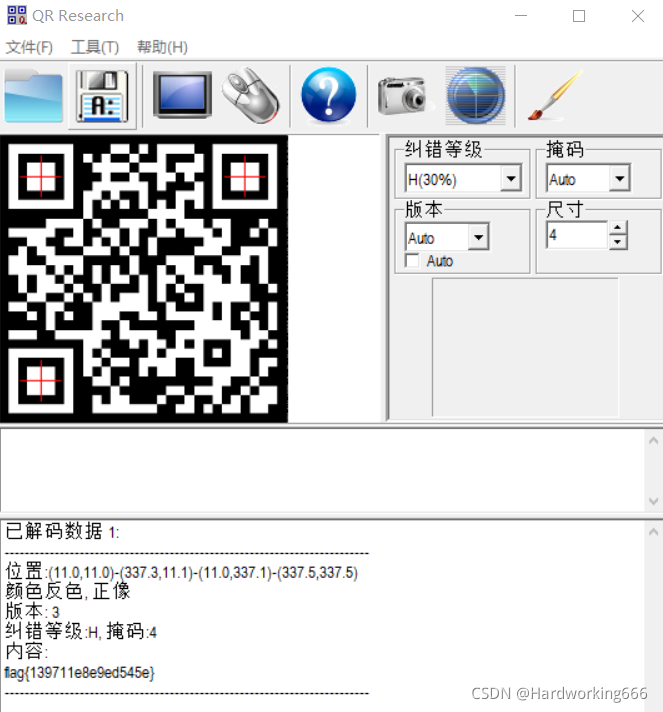
2、16进制转pyc
攻防世界 MISC 适合作为桌面(世安杯)
使用stegsolve发现在绿色的低位通道中有二维码
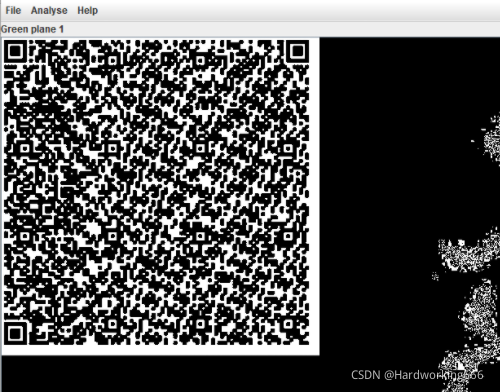
使用二维码扫描器扫描,并将16进制数字结果在winhex中打开
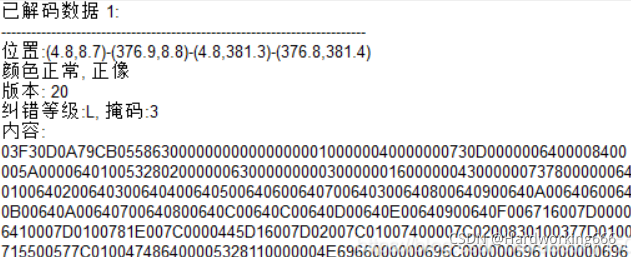
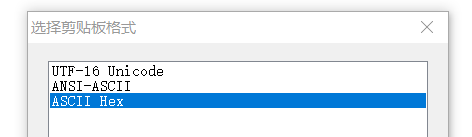
注:如果错选中间这个(ANSI-ASCII),则再ASCII码转二进制(快捷键Ctrl+R)

03F3开头,pyc文件。保存为.pyc然后反编译,在脚本后加上flag(),运行之后即可得到flag。
或者,使用“uncompyle6 文件路径\文件名.pyc > 文件路径\文件名.py”命令
D:\Python385\Lib\site-packages\uncompyle6\bin
pyc隐写Stegosaurus

Stegosaurus 是一款隐写工具,它允许我们在 Python 字节码文件( pyc 或 pyo )中嵌入任意 Payload 。由于编码密度较低,因此我们嵌入 Payload 的过程既不会改变源代码的运行行为,也不会改变源文件的文件大小。 Payload 代码会被分散嵌入到字节码之中,所以类似 strings 这样的代码工具无法查找到实际的 Payload 。 Python 的 dis 模块会返回源文件的字节码,然后我们就可以使用 Stegosaurus 来嵌入 Payload 了。
pyc文件存在无效空间,修改后大小不变,不影响运行,可以隐藏信息。
stegosaurus.py可以隐藏和解密pyc文件中隐藏的信息。
只能利用pyc文件中的无效空间(Python3.6后参数会占1字节,如果没有参数用0x00填充,运行时被忽
略,修改不影响),编码密度较低,嵌入 Payload 后不会改变源代码的正常运行和大小,不容易被发现。
同时 Payload 会被分散嵌入到字节码之中,类似 strings 这样的代码工具无法查找到实际的 Payload 。
通过github下载后(https://github.com/AngelKitty/stegosaurus)运行 python stegosaurus.py -h
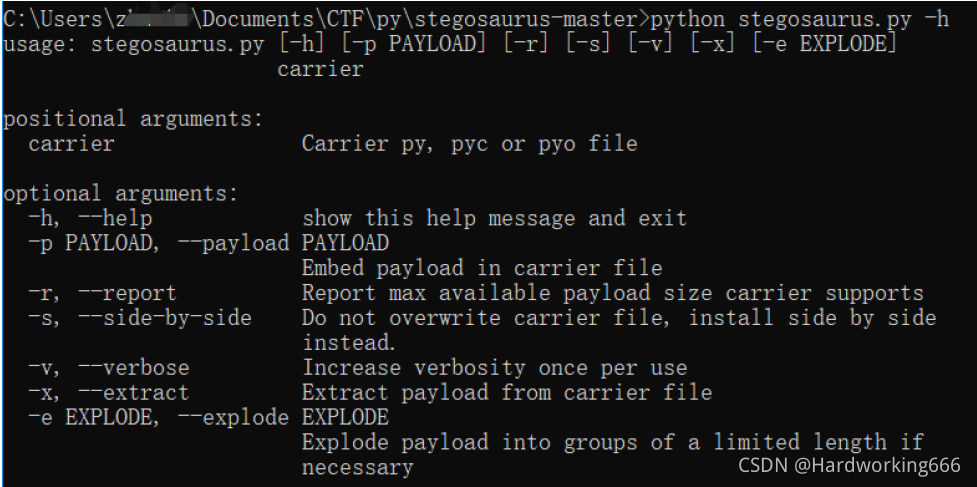
可以发现有很多参数,-p 要隐藏的文本,-r 显示最大隐藏字节,-x可以解密。
stegosaurus解密
使用 python stegosaurus.py py_py_py.pyc -x 得到如下结果 Extracted payload: Flag{HiD3_Pal0ad_1n_Python} 。
3、二进制作二维码
攻防世界 Misc很普通的数独
下载发现是一堆数独图片,把有数字的记为1,没有数字的记为0,结果保存在txt文本中。也可以调节文件位置后用画图拼接,并将有数字的格涂黑。
# -*- coding:utf-8 -*-
from PIL import Image
x = 45
y = 45
im = Image.new("RGB", (x, y)) # 创建图片
file = open('1.txt', 'r') # 打开rbg值文件
for i in range(0, x):
line = file.readline() # 获取一行
for j in range(0, y):
if line[j] == '0':
im.putpixel((i, j), (255, 255, 255)) # rgb转化为像素
else:
im.putpixel((i, j), (0, 0, 0)) # rgb转化为像素
im.show()
扫描得到一串字符串,base64多次解码得到flag:flag{y0ud1any1s1}
4、4个值转二维码
2019西湖论剑网络安全技能大赛(大学生组)–奇怪的TTL字段
发现ttl.txt中的ttl只有4个值63,127,191,255,写出他们的二进制表示后发现只有最高两位不同(高两位比特的数在数据传输中不容易受影响),拿下来,每4个TTL值凑出一个字节的二进制数来
63=00111111
127=01111111
191=10111111
255=11111111
于是考虑做如下转换,发现写出来的16进制数开头是ffd8,应该是jpg,于是写入文件中:
fp = open('ttl.txt','r')
a = fp.readlines()
p = []
for i in a:
p.append(int(i[4:]))
s = ''
for i in p:
if i == 63:
a = '00'
elif i == 127:
a = '01'
elif i == 191:
a = '10'
elif i == 255:
a = '11'
s += a
# print(s)
import binascii
flag = ''
for i in range(0,len(s),8):
flag += chr(int(s[i:i+8],2))
flag = binascii.unhexlify(flag)
wp = open('res.jpg','wb')
wp.write(flag)
wp.close()
写完之后发现只有二维码的一部分,应该是不止一张图,用foremost直接分开就好了,之后用PPT拼在一块,扫描之后得到如下信息:
key:AutomaticKey cipher:fftu{2028mb39927wn1f96o6e12z03j58002p}
是AutoKey加密,用在线网站解密得flag
autokey解密
自动密钥密码(Autokey Cipher)也是多表替换密码,与维吉尼亚密码密码类似,但使用不同的方法生成密钥。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号