AWS学习笔记
1.IAM用户、用户组、权限
1)使用根用户名创建IAM用户。
2)为了测试权限,使用根用户创建两个S3桶。#这时候使用IAM用户登录看不到S3桶,因为还没有赋予相应的权限。
3)创建用户组(deploy),把S3桶的可见权限(AmazonS3ReadOnlyAccess)设置到组上。
4)把IAM用户加到组上。
这样该用户组下的所有IAM用户都可以看到S3了。
通过创建"内联策略"给用户组增加权限,从而给用户组内的用户赋予权限。
这里的"内联策略"理解为自定义权限组合,根据自己的需要随意组合。
2.创建单个用户的权限
1)在策略中创建一个策略
2)把这个策略指向用户。#给用户添加权限即可。
3.创建权限边界(用户级别的操作,在组中没有权限边界)
限制单个用户的权限。
1)新建一个策略。2)把该策略通过“添加权限”赋给该用户。#因为是对用户的控制,因此不需要把该策略加给组。
3)在用户的界面下,新建权限边界,使用上述建立的策略。
权限边界的作用:
尽管赋给用户很多权限,但是如果设置了权限边界,那么只有具有权限边界里的权力。
实际使用,一个用户被加到了一个组,该组具有很大的权限。不想把所有权限给某个用户,也不想为该用户重新做一个组。
那么就可以使用权限边界来限制给用户的权力。
4.role
角色相当于一顶帽子,可以戴在用户的头上,也可以戴在EC2的头上。
1)创建一个role。在role里加上权限(例如,AmazonS3FullAccess)。
2)在用户的界面下,创建一个内联策略。该内联策略的ARN 指向Role。
★EC2
1.置放群组
置放群组的作用:
可以通过置放群组将启动的实例尽可能靠近。实例之间离的越近,距离越近,相互通讯所需要过的网络设备越少,延迟就会越低;
或者将启动实例分散放置到不同的底层硬件和机柜,这样的话如果其中一个实例所在的底层硬件或者机柜故障,不会影响到其他的实例,减少故障的影响。
#创建置放群组无需支付费用。
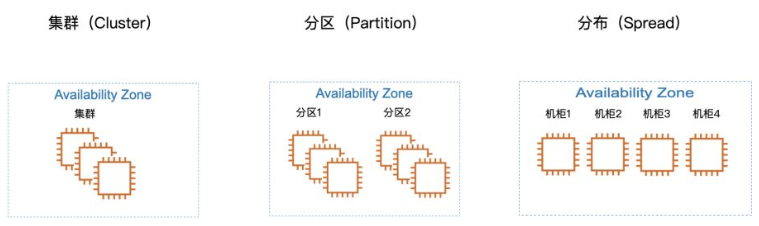
集群:
集群置放群组是将一个可用区中靠近的实例打包在一起。
集群置放群组适用于那些要求低网络延迟或高网络吞吐量的应用程序,如果我们的业务需求是启动多个实例上的应用程序之间的通讯延迟低,
高吞吐量,高网络品质,那么请将这些实例启动到“集群置放群组”。
例如,创建了group-colony,那么如果创建5个EC2实例(置放群组=group-colony)的话,
这时候5个EC2实例将会实例放置到同一底层硬件、同一机柜或者相邻机柜,减少多个实例之间的物理距离。
分区:
我们创建了有2个分区的“分区置放群组”,EC2 确保置放群组中的每个分区具有自己的一组机柜,每个机柜具有自己的网络和电源。
置放群组中的任何两个分区将不会分享相同的机架,从而让您可以在您的应用程序中隔离硬件故障的影响。
一个分区中的实例不与其他分区中的实例共享机架,这使您可以将单一硬件故障的影响限定在相关的分区内,分区1的机柜故障不会影响分区2的实例。
分区策略通常为大型分布式和重复的工作负载所使用,例如,Hadoop、Cassandra 和 Kafka。
在创建分区置放群组的时候选择分区数,在创建EC2实例的时候,可以选择目标分区。
例如,创建了group_parition,分区数是2,那么在创建EC2实例的时候可以选择分区1或者分区2。一般相同的service不放在同一分区内(机柜)。
分布:
“分布置放群组”可以将每个启动的实例放置在不同的机架上,并且每个机柜具有各自的网络和电源。
假设“分布置放群组”启动了4个实例,那么每一个实例都将放置到不同的机柜,4个实例分别会放置在4个不同的机柜,假设机柜1发生故障,剩下的实例将不会受到影响。
我们可以将跑关键业务的多个实例使用分布置放群组,这样可以降低在实例都在相同机柜时同时发生故障的风险。
分布置放群组可以跨越同一区域中的多个可用区,每个群组在每个可用区中最多有 7 个正在运行的实例。
和分区置放群组不同,不需要定义分区数量,只要选择了“分布置放群组”,那么在这个群组内的EC2实例都会被自动创建到不同的机柜。
例如,创建了group-distribution,那么如果创建5个EC2实例(置放群组=group-distribution)的话,这时候5个EC2实例在5个机柜上。
★负载均衡
网络负载均衡器(NLB):不能做轮询
应用程序负载均衡器(ALB):可以做轮询
NLB实验
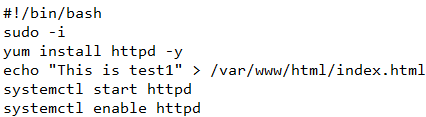
1.创建两个EC2,使用Amazon Linux,在用户数据中输入如下内容,用于测试。
注意:如果对象实例的可用区相同的话 ,那么在创建负载均衡器的时候需要选择该可用区。
如果对象实例的可用区不相同的话,那么需要把这些多个可用区都选择上。
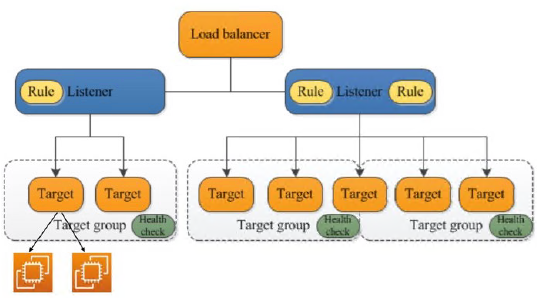
3.在创建负载均衡器的过程中会要求创建目标组,按照指示的步骤创建即可。
创建目标组的过程中会要求选择对象实例。就是分发的对象石实例。
如上负载均衡器就创建完了,复制负载均衡器的DNS名称在浏览器中打开,就能够交替时的打开对象页面。
ALB、NLB、CLB、网关负载均衡器
1.(Application Load Balancer)ALB
应用程序负载均衡器(Application Load Balancer),应用程序级别(第7层)。
支持基于内容的路由和在容器中运行的应用程序。聚焦TCPUDP和TCPSSL协议,面向网络层交付。
2.(Network Load Balancer)NLB
网络负载均衡器,在连接级别运行(第4层)
适合实现传输控制协议(TCP)流量负载均衡,且能多在每秒处理数百万请求的同时保持超低延迟。
聚焦HTTP、HTTPS和QUIS应用层协议,面向应用层交付。
【使用场景】
Network Load Balancer:
对网络/传输协议(第4层-TCPUDP)以及极端性能/低延迟的应用程序进行负载均衡,使用 Network Load Balancer
Application Load Balancer:
对HTTP请求进行负载均衡,建议使用Application Load Balancer (ALB)。
Classic Load Balancer:
应用程序在 Amazon Elastic Compute Cloud (Amazon EC2)Classic网络中构建而成,建议使用 Classic Load Balancero
网关负载均衡器:
如果需要部署和运行第三方虚拟设备,可以使用网关负载均衡器。
★Auto Scaling
1.创建模板用于自动做成实例。
2.创建负载均衡器,用于在该负载均衡器下面自动添加实例。
3.创建Auto Scaling Group,设置所需容量等参数,匹配上模板。
弹性负载均衡可以监控实例是否可用于处理请求。若某个实例报告为运行状况不佳,则 EC2 Auto Scaling 可以在下一次定期检查时替换该实例。
测试:如果手动关掉一个实例,那么Auto Scaling Group会识别到,自动启动新的实例。
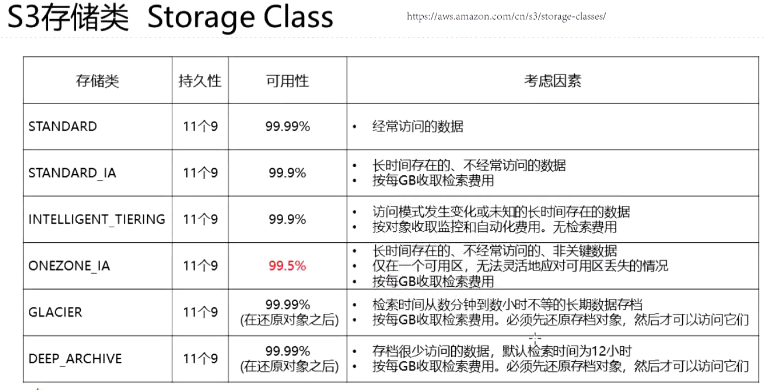
★存储
在存储需要修改非常精确内容的文件时选择EBS,需要共享存储的时候选择EFS,存储不经常访问但又不能不要的数据时选择S3 Glacier,一般情况下则选择S3。
原文链接:https://blog.csdn.net/weixin_57022929/article/details/124428794
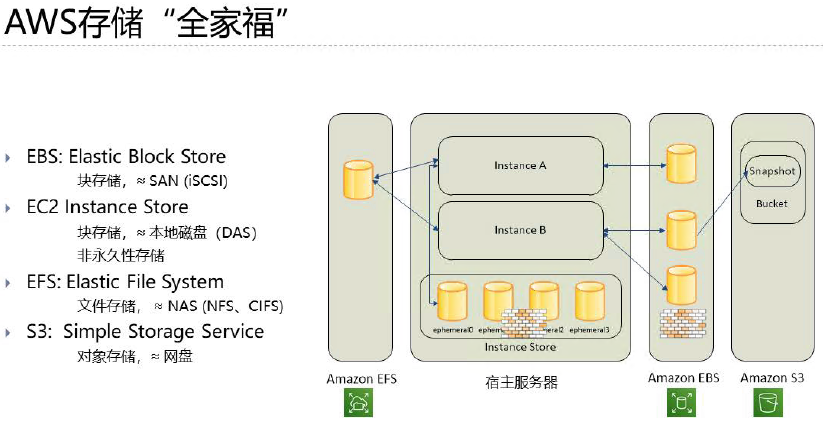
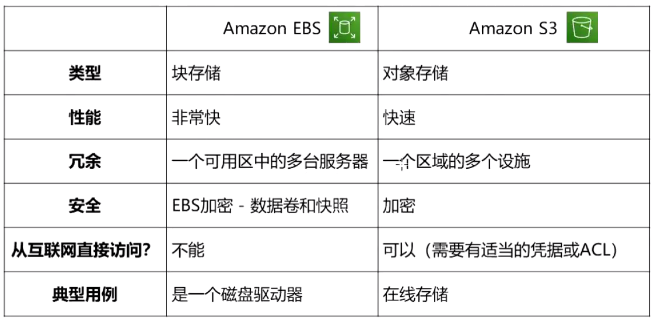
①Amazon EBS
Amazon EBS是一种易于使用且可扩展的高性能数据块存储服务,Amazon EBS 专为 Amazon EC2 中运行的任意规模吞吐率密集型和事务密集型工作负载设计。
此外,它是块区域存储模式,举个例子——如果一个文件里有1000个字节,如果要更改部分字节,用EBS则可仅需更改要更改的字节,从而避免造成不必要的浪费。
因此,EBS适合存储经常需要更改、且更改具体内容的东西。
②Amazon EFS
Amazon EFS可随着您添加和删除文件自动增大或收缩,无需管理或预置。它是一个简单的设置即用式无服务器弹性文件系统,
让您无需预置或管理存储即可共享文件数据。
③Amazon S3
Amazon S3是一种对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能。
它是一个单元存储模块,同样用到上面的例子,若想要更改某文件的部分字节,S3需要对整个文件进行更改,但要是想要更改整个文件,
S3更改的成本要比EBS低得多。
④Amazon Glacier
Amazon Glacier是一种数据存档服务,旨在实现安全性、持久性和极低成本。
分离和挂载EBS存储块
1)新建一个EC2实例。#自动生成EBS。2)进入卷管理页面,基于该EBS创建快照。3)基于快照做成新的卷。
4)分离该新建EC2实例的卷。#需要关闭实例。5)选择新建的卷,进行挂载卷。
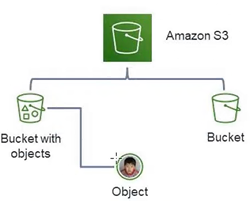
◆S3
存储桶:Bucket 对象:Object 键:Key 区域:Region
存储桶(Bucket)是S3中用于存储对象的容器。每个对象都存储在一个容器中。
用途:
‐S3命名空间的最高等级。
‐识别负责存储是数据传输费用的账户。
‐在访问控制中发挥作用。
‐使用率汇报的汇总单位。
Amazon S3的优势
1)可以在桶中存储无限数量的对象对象大小最高可达5TB。
2)标准型的S3可以达到99.999999999%(11个9)的持久性和99.99%的可用性。
3)可以使用HTTP/HTTPS端点随时从Web上的任何位置存储和检索任何数量的数据。
4)可以使用AWS或客户管理提供的客户端加密来使用可选的服务器端加密。
5)访问日志提供审核。
6)提供基于标准的REST和SOAP接口。
S3托管静态网站
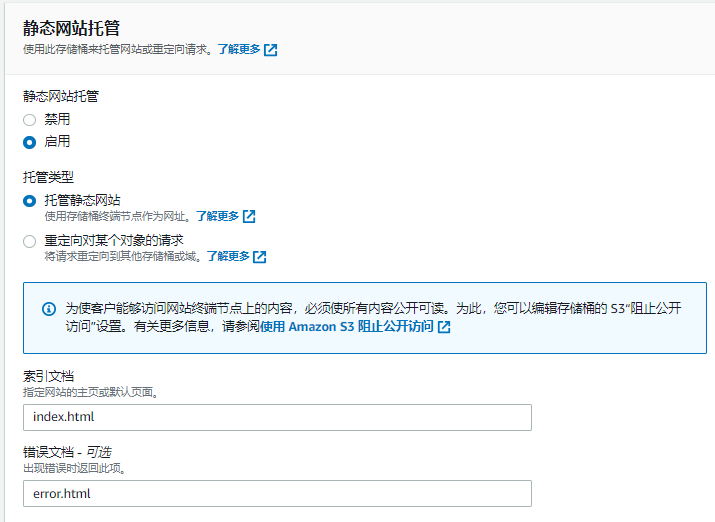
通过设置限制访问权限

★CloudFront
什么是AWS CDN
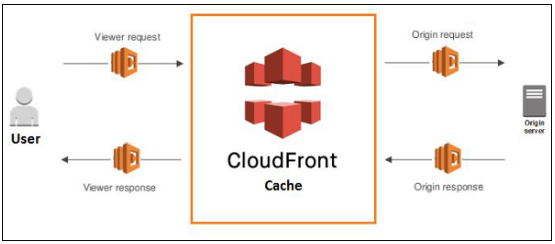
CloudFront是CDN (Content Delivery Network)。它从AmazonS3存储桶中检索数据并将其分发到多个数据中心位置。
它通过称为edoe locations的数据中心网络提供数据。
当用户请求数据时,最近的边缘位置被路由,导致最低证迟,低网络流量,快速访回数据等。 AWS CDN如何提供内容?
AWS CloudFront按以下步骤提供内容。
Step1-用户访问网站并请求像图像文件一样下载对象。
Step2-DNS将您的请求路由到最近的CloudFront边缘位置以提供用户请求。
Step3-在边缘位置,CloudFront检香其缓存中是否有所请求的文件。如果找到,则将其返回给用户,否则执行以下操作一。第一个CloudFront将请求与规范进行比较,
并将其转发到适用的原始服务器以获取相应的文件类型。。源服务器将文件发送回CloudEront边缘位置。
一旦第一个字节从原点到达,CloudFront就会开始将其转发给用户,并在有人再次请求同一文件时将文件添加到边缘位置的缓存中。
Step4-对象现在位于边缘缓存中24小时或文件头中提供的持续时间。CloudFront执行以下操作
CloudFront将对象的下一个请求转发到用户的源,以检查边缘位置版本是否已更新。如果更新了边缘位置版本,则CloudFront会将其传递给用户。
如果未更新边缘位置版本,则origin会将最新版本发送到CloudFront。CloudFront将对象传递给用户,并将最新版本存储在该边缘位置的缓存中
知识点:
边缘站点EdgeLocation :
边缘站点是内容缓存的地方,它存在于多个网络服务提供商的机房,
它和 AWS 区域和可用区是完全不一样的概念。截至 2018 年中,AWS 目前一共有 100 多个边缘站点。
源(Origin):
这是 CDN 缓存的内容所使用的源,源可以是一个 S3 存储桶,可以是一个 EC2 实例,一个弹性负载均衡器(ELB)或Route53,
甚至可以是AWS之外的资源。
分配(Distribution):
AWS CloudFront 创建后的名字分配分为两种类型,分别是
Web Distribution:一般的网站应用
RTMP(Real-Time MessagingProtocol:媒体流
你不只是可以从边缘站点读取数据,你还可以往边缘站点写入数据(比如上传一个文件),
边缘站点会将你写入的数据同步到源上在 CloudFront上的文件会被缓存在边缘节点,缓存的时间是TTL(Time ToLive)。
文件存在超过这个时间,缓存会被自动清除如果在到达 TTL 时间之前,你希望更新文件,那么你也可以手动清除缓存,但你将会被 AWS 收取一定的费用。
★BeanStalk
可以在云中快速部署和管理应用程序,而不必了解这些应用程序的基础设施。
只需要上传应用程序,Elastic Bean Stalk将自动处理有关容量预配置,负载均衡,扩展和应用程序运行状况监控的部署细节。
#上传的应用程序保存在S3。
在构建部署应用程序的时候,BeanStalk会选定应用平台,会预定一个或多个AWS资源(EC2)来运行应用程序。
AWS Lambda 与 AWS Elastic Beanstalk 的区别
| 参数 | AWS Elastic Beanstalk | AWS Lambda |
|---|---|---|
| 主要任务 | 在 AWS 云上部署和管理应用程序,无需担心运行这些应用程序的基础设施。 | AWS Lambda 用于运行和执行你的后端代码。你不能使用它来部署应用程序。 |
| AWS 资源的选择 | 它让你可以自由选择 AWS 资源;例如,出可以根据你的应用选择最佳的 EC2 实例。 | 你无法选择 AWS 资源,例如某种类型的 EC2 实例,Lambda 根据你的工作负载提供资源。 |
| 系统类型 | 它是一个有状态的系统。 | 它是一个无状态系统。 |
比Beanstalk能做的事更多和更复杂。
个人理解的顺序:Lambda(代码级别)<Beanstalk(程序级别)<ECS-Fargate(容器)<ECS-EC2(容器)
★ECS-Fargate
AWS Fargate 是一种适用于容器的无服务器计算引擎,可与 Amazon Elastic Container Service (ECS) 和 Amazon Elastic Kubernetes Service (EKS) 一起使用。
通过 AWS Fargate 可以轻松专注于构建应用程序。使用 Fargate,您无需预置和管理服务器,而且可以为每个应用程序指定资源并为其付费,
并通过设计隔离应用程序来提高安全性。借助 AWS Fargate,您能够专注于应用程序。
您可规定应用程序的内容、联网、存储和扩展要求,无需实施预置、修补、集群容量管理或基础设施管理。
创建ECS时在画面上显示的信息:AWS用Fargate开始使用 Amazon Elastic Container Service(Amazon ECS)
注:不必纠结ECS和Fargate之间的关系,Fargate只是ECS的一种启动类型。
集群→服务→任务(任务中有容器,镜像地址等一系列设置)
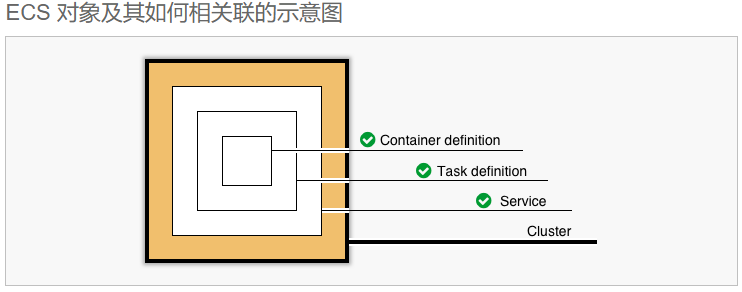
预先创建任务定义
1)任务定义(和docker的image相似)
需要往集群内添加任务,因此需要预先定义任务。
任务定义指定哪些容器包含在任务中,以及它们之间如何相互影响。还可以指定供容器使用的数据卷。
在任务定义中指定任务的容器信息(既应用程序通过任务部署),任务定义的主要作用就是承载容器image。
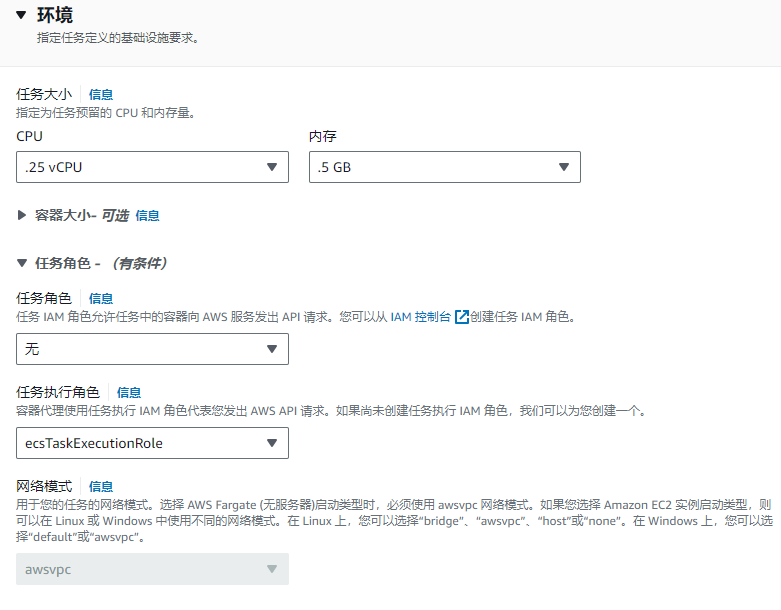
任务定义(Task)里需要描述「配置环境、存储、监控和日志记录」等信息。
注意:即便fargate是无服务器,但是在配置任务(TASK)的时候,会指定硬件资源,比如CPU和内存的大小。
因此,即便应用程序的性能不佳,也不会出现无限使用资源的情况。
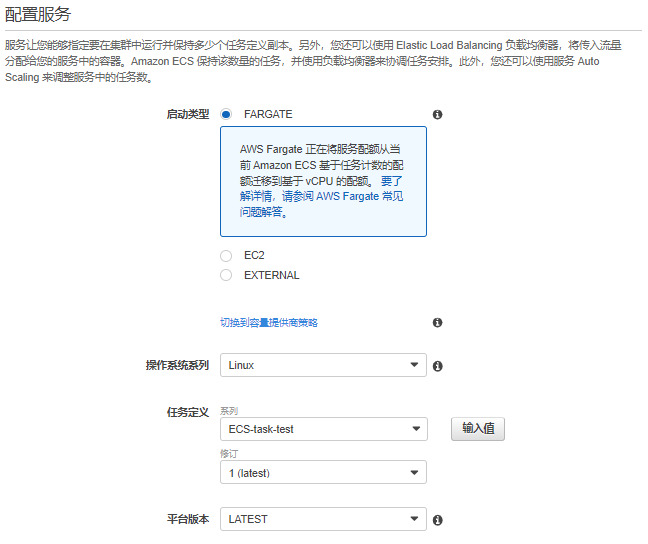
#在一个集群中可以启动多个服务。
#服务有启动类型,可以选择fargate或者ES2。也可以在执行集群的时候选择。
#ECS中的服务(service)是任务(Task)的载体,服务会基于被指定的任务定义,创建任务实例,实例的数量在创建服务的时候被定义。
服务能够指定要在集群中运行并保持多少个任务定义副本。
另外,还可以使用Elastic Load Balancing负载均衡器,将传入流量分配给服务中的容器。
Amazon ECS 保持该数量的任务,并使用负载均衡器来协调任务安排。
此外,还可以使用服务Auto Scaling来调整服务中的任务数。
在服务中可以设置:
需要执行的任务定义、预期任务数、最小运行任务数、最大运行任务数、VPC、配置负责均衡器、Auto Scaling等。
3.在创建集群的时候把任务添加进去,在服务中可以启动多个任务。
#不创建服务,在ECS中任务也可以单独启动,弊端就是如果想启动多个任务实例,需要手动操作。
ECS中Farget和EC2的区别
ECS还有两个启动容器image的形式,就是Fargate和EC2。
如果ECS使用EC2形式运行容器,则需要管理和运行主机,例如容器环境的操作系统和Docker Engine,以便在主机上启动容器。
此外,还必须自己选择主机类型以及容器数量等。
但是,如果使用AWS Fargate代替EC2启动容器的话,则可以在不考虑主机的情况下运行容器。
Fargate没有VM实例的概念,集群完全交给AWS负责。因此使用farget形式的话 ,不需要配置集群,不需要定义EC2的类型。
#在集群里运行任务(TASK)的时候,填写预期任务数就可以,之后AWS自动在ALB下启动多个任务实列,实现集群机制。
任务具体在哪里运行不需要关心,系统工程师和运维工程师不需要考虑集群,运维工作非常少。
EC2形式启动容器的时候,需要配置集群信息,需要选择实列类型。
并且,在集群中启动任务实例的时候,需要指定实列的放置规则,比如AZ均衡分散、每个主机放置一个任务、随机等。
另外,关于费用
Farget的话,是任务启动,到任务停止为止的费用。即便程序不被使用,因为占用了资源,所以会产生费用。
#所谓的被暂用的资源,指的是定义TASK的时候指定的CPU和内存大小。
如下图,选择Fargate的时候,很简单,不需要配置集群和EC2实列属性。
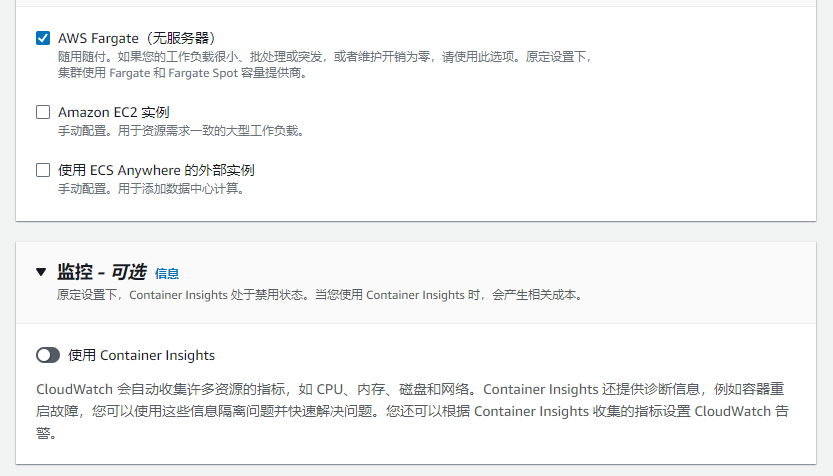
如下图,选择EC2的时候,需要自己配置集群,EC2放置的子网等属性。
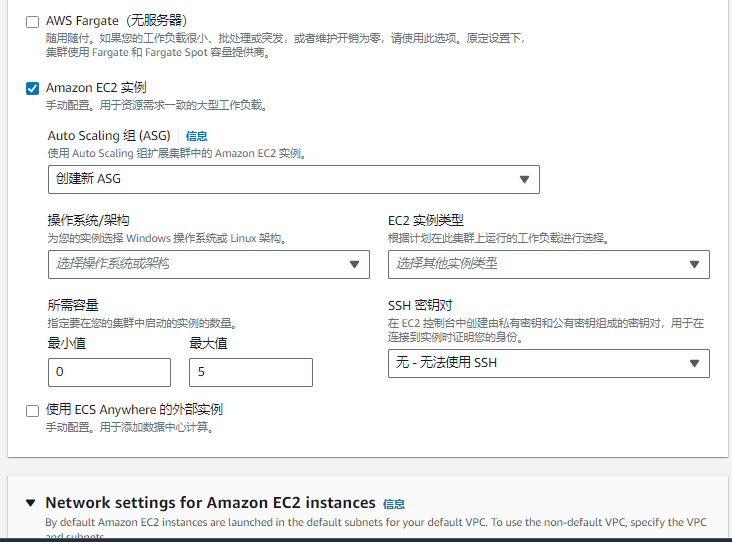
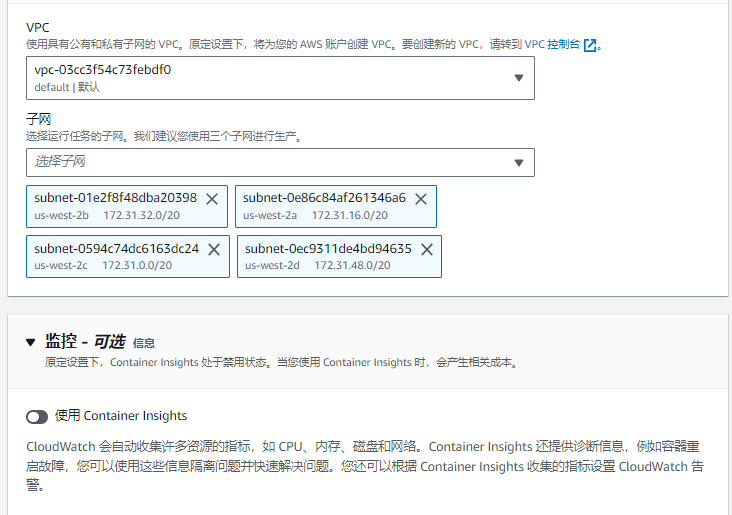
EC2形式启动任务实例时候的放置规则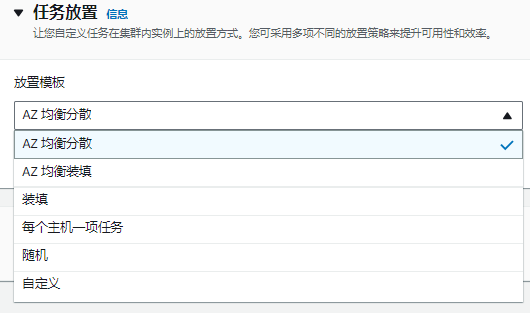
★★★关于使用Fargat的优劣势,这篇文章介绍的比较好★★★
https://business.ntt-east.co.jp/content/cloudsolution/column-171.html
#使用场景:企业内部call center的辅助工具;组织内部信息查询;
Kendra是一项易于使用的企业级搜索服务,可向应用程序中添加搜索功能,保证最终用户得以轻松从企业内部存储的不同数据源中查找信息,
具体包括收据、业务文档、技术手册、销售报告、公司内部词汇表以及内部网站等等。
可以从Amazon Simple Storage Service(AmazonS3)以及OneDrive等存储解决方案当中获取这些信息。
也可以面向SalesForceSharePoint及ServiceNow等应用程序,或者Amazon Relational Database Service(AmazonRDS)等关系数据库执行搜索。
在输入问题时,该服务将使用机器学习(ML)算法理解上下文,并返口相关度最高的结果-包括准确答案或者完整文档。
更重要的是无需具备任何机器学习经验即可完成操作。
创建Kendra
1.在Machine Learning之下,选择Amazon Kendra,在Amazon Kendra主页面中,选择Create an Index一步步按照指示操作建立一个index。
#需要IAMrole,可以新建。
数据源是指存储文档以进行索引的位置。
Amazon Kendra支持六种数据源举型:Amazon S3.SharePoint Online. ServiceNow. OneDrive, Salesforce online以及Amazon RDS。
选择事先做好的S3存储桶,存储桶中放入信息文件,作为信息检索的源文件。#注意:Kendra和S3存储桶要在一个区域,否则识别不到。
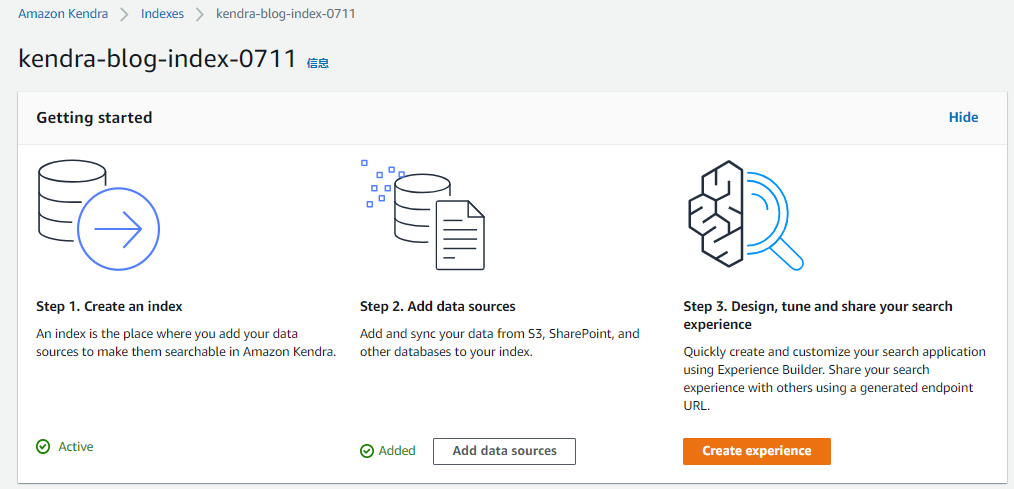
3.在Kendra的data source下点击sync now从S3存储桶同步数据到Kendra索引。(可以设置数据定期同步,比如每小时,每天,每周)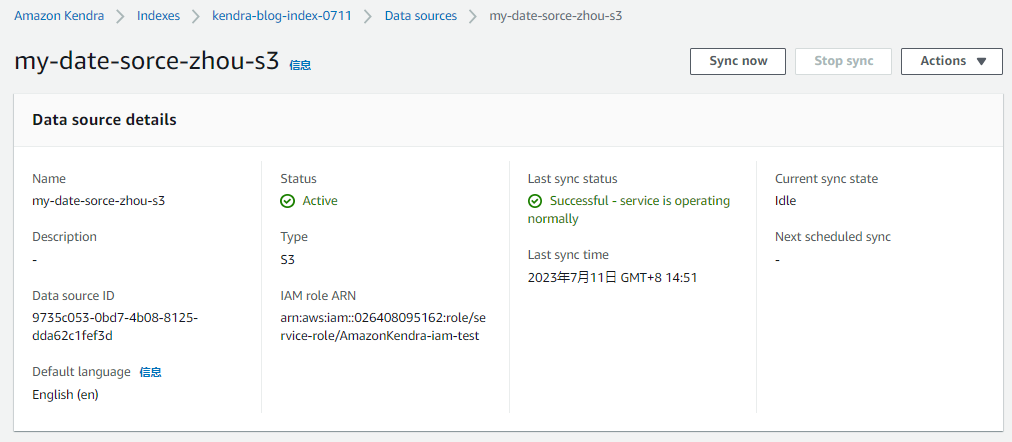
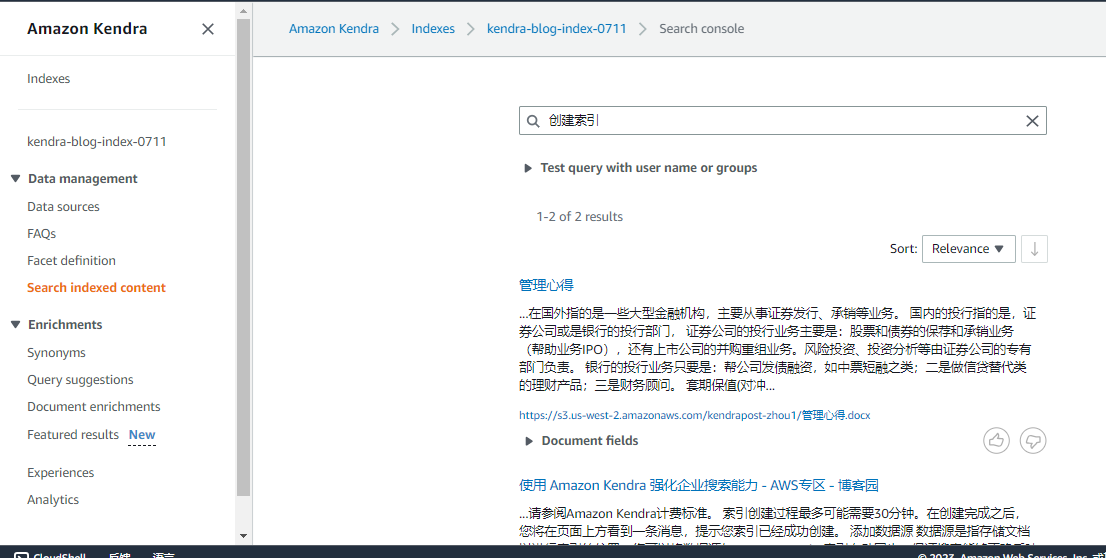
4.点击左侧栏的Search indexed content,进入Search console页面。在检索栏输入关键字,获得信息一览。
★SQS
SQS是AWS提供的队列产品,可以集成和分离分布式软件系统。
Amazon SQS典型应用:
◆操作缓冲
・分布式应用程序的组件可能无法同时处理相同的工作量
・将请求放入处理队列,后续组件慢慢处理
・应对临时性峰值,而不会丢失消息或增加延迟
・提高架构的可扩展性和可靠性
◆扩展触发
・与其他的AWS服务集成
・使用Amazon SQS队列来帮助确定应用程序的负载
・示例:搭配使用AutoScaling,根据流量来扩展EC2实例的数量
实操SNS+SQS:
1.创建一个SNS,命名为New-orders。
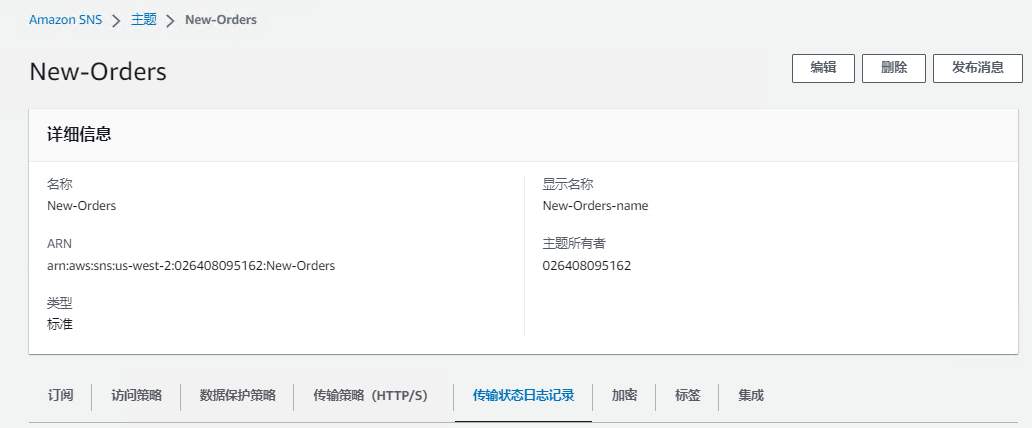
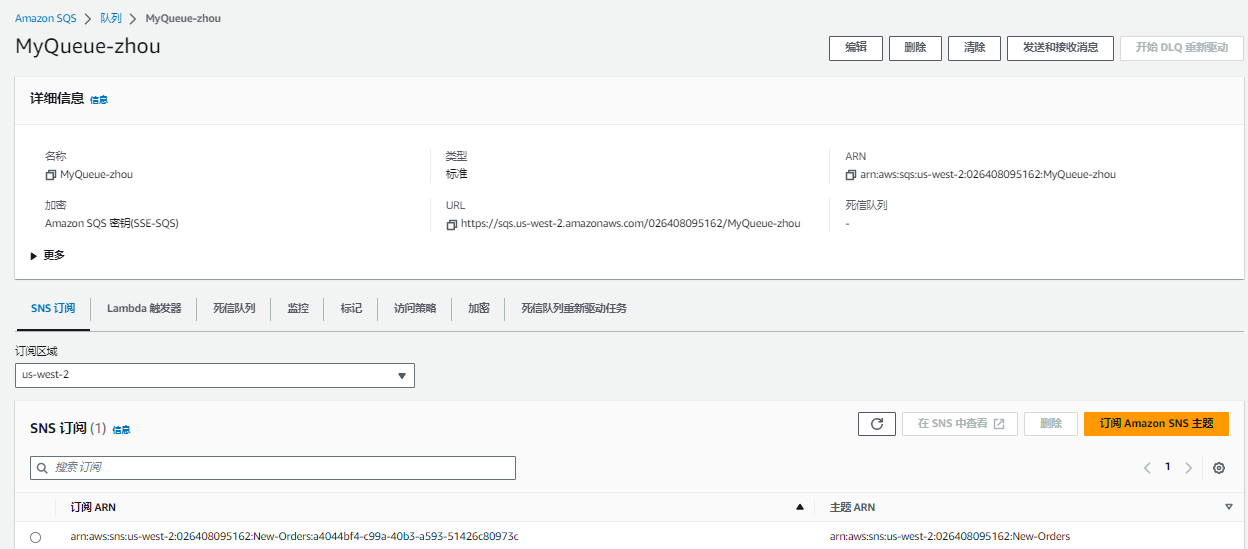
3.在MyQueue-z队列下点击「订阅AmazonSNS主题」,把事先定义好的SNS主题绑定过来。
4.在SNS主题中发布信息。
5.在MyQueue-zh队列中接收消息。
AWS SQS 和JAVA代码
有JMS和AWS JavaSDK两种方式操作SOS的配置。
JMS方式通过控制台来对队列进行操作(新增、配置),对消息的操作简便易用,但是灵活性较差。
采用AWS SDK for Java 2.0 对[Amazon SQS]进行编程则更加灵活,可以代替控制台部分的工作。
代码实现请参照:
https://docs.aws.amazon.com/zh_cn/sdk-for-java/v1/developer-guide/examples-sqs-message-queues.html
创建DynamoDB表
1.填写表名称、分区键、排序键等信息。
表名称:用于标识表。
分区键:分区键是表的主键的一部分。它是一个哈希值,用于从表中检索项目,以及跨主机分配数据以提高可扩展性和可用性。
排序键(可选):可以使用排序键作为表主键的第二部分。排序键允许在共享同一分区键的所有项目之间进行排序或搜索。
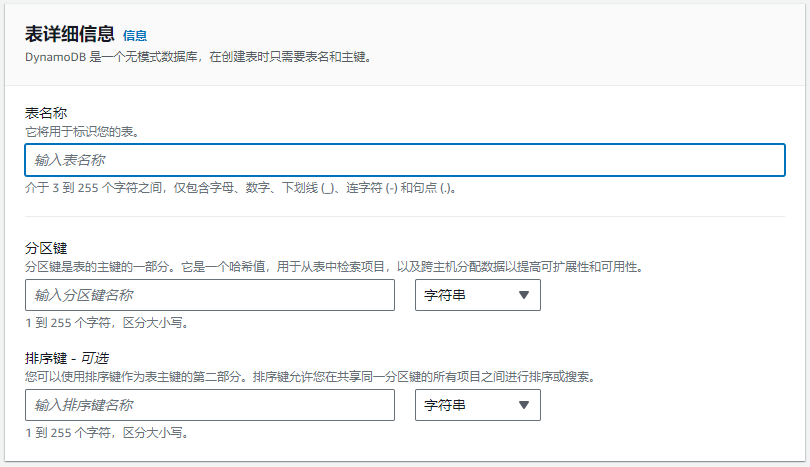
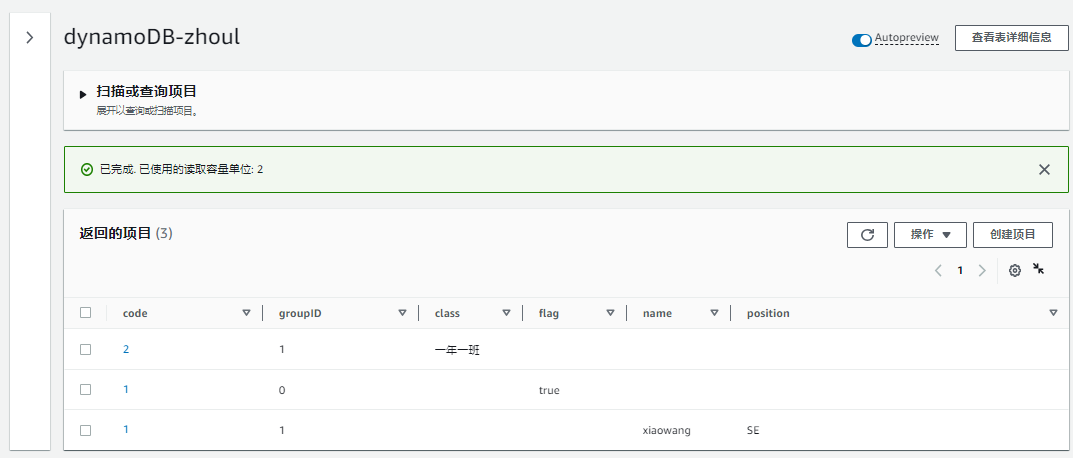
分区键和排序建作为表主键,是必须填写项。在同一表中可以随意添加项目。数据行之间,和所添加项目没有必然关系。
★AWS batch
AB的功能侧重于实现某个批处理功能。比如,每天晚上要处理100万件数据,那么使用AB可以对这些数据进行集群式的并行处理。
★Eventbridge
是任务总线有调度的作用,可以实现定时调用task的功能。
★Step Functions
用于把几个机能串联到一起,实现一个workflow比如,打开冰箱内,放进大象,关上冰箱门。
这三部可以在一个程序内事项,如果使用SFN的话,就可以实现最大化解耦,把情力集中在程序内部。尽管我认为这样做并不是最佳实践。
SFN串联的对象是AWS的服务,例如,1amabda,SNS等。如果希望把自己的程序加入workflow的话,需要把程序装载到task里。
SFN可以和eventbridge配合使用,让SEN的start被调用,执行整个WE。
如果你之前用过开源的解决方案,例如ApacheAirflow,那你应该对workflowmanagementplatform这个概念不陌生,SFN不过是AWS平台上的Airflow。
什么叫工作流(workflow),就是一连串需要执行的操作。
比如你需要洗一个原始数据,
第一步需要加载数据到53。
第二部用Spark来批处理。
第三步送处理好的数据到sQS或者Kafka。
第四步载入数据仓库。
第五步载入完成后SNS(邮件)通知开发运维人员。
过去如果不想重复这些手工的操作,我们会写一个longrun的守护讲程来,在每一步完成之后损眼程序的返口值成功或者失败再调用下一步。
而SFN则是一套造好的轮子,让我们直接写json来定义我们的工作流,而不是用自己的DSL或者硬编码在代码中。
实际案例:
使用Eventbridge调用Step Functions中的workflow,执行预定程序。
★EC2实例
注:https://blog.csdn.net/defonds/article/details/119870210
1. 按需实例
这是在 AWS 中启用 EC2 实例最灵活的选项之一。按秒来支付你启动的计算能力。
如果你不能确定是否会在 5 分钟后决定终止 ec2 实例,这个选项无疑是适合你的。
你完全可以控制 ec2 实例的生命周期,例如何时启动、停止、休眠、重新启动或终止。你只需要支付当实例处于运行状态时的秒数。
AWS 并不保证你的实例将被启动。尽管 AWS 总是尝试启动你的实例,老实说,我从来没有遇到过这样的情况,即我请求了一个按需实例,但它没有启动,但当您的实例没有按请求启动时,AWS端仍然会有峰值负载
它非常适合不能中断的短期或不定期的工作。
你可以将其用于应用程序开发/测试的场景。
2. 预留实例
相比较按需实例,预留实例能够节省高达 72% 的成本。你只需提交特定的实例配置、实例类型和可以是1年或3年的持续时间。
非常适合持续的工作负载,例如数据库。
换句话说,你可以使用此选项保留计算容量,并承诺持续时间和配置。
订期限可以是1年或3年。请不要讲这不是 1-3 年,不是 1 年就是 3 年。别无选择。
如果你想中途更改实例类型,可以使用可转换的保留实例,但在这种情况下折扣会较少。
每个 region 下预留的运行实例数限制为20个。但是,如果需要的话,你可以随时请求增加限额。
重要提示:以前在预留实例中还有一个计划预留实例选项。它允许你在一年的期限内保留计划在指定的开始时间和持续时间内每天、每周或每月重复出现的容量。
但到目前为止,AWS 还没有提供这种服务。
所获得折扣的大小取决于使用的是标准 RI 还是可转换 RI:
・标准 RI 通过长期合同为特定实例类型提供最高额度的折扣。
・可转换 RI 的折扣额度较小,但允许您在合同期间更改实例类型。
3. Savings Plans
这是AWS较新的计划,如果你承诺将在 1 年或 3 年的特定时期内使用它,它将帮助你降低EC2成本。听起来有点类似于预留实例。但跟预留实例相比,它的额外优势是允许你中途更改实例配置/类型。
与按需实例相比,Savings Plans 可显著节约成本,同时还具有足够的灵活性,允许更改配置/实例类型
对运行实例的数量没有限制。
在AWS提出 Savings Plans 后,我认为没有必要使用预留实例了。Savings Plans 要灵活得多。
4. Spot 实例
Spot 实例是在 AWS 上启动 EC2 实例的最具成本效益的选项之一。
理想情况下,你可以请求未使用的EC2实例,这就是它们最具成本效益的原因,并且与按需实例相比可以节省 90% 的成本。
你出价并在平台出价低于该价格时获得实例。
一旦另有出价超过你的出价,你的实例将在通知你后的 2 分钟后从你那里收回。
实例可以随时从你那里被收回。
适用于能够以最便宜的价格提供计算,从而很好地处理中断的工作负载。
不适用于关键工作负载或无法处理中断的工作负载。
5. 专用主机
专用主机是你可以预订的真正的物理服务器。这意味着它的 EC2 的全部容量仅供你使用。其他任何人都不能在该服务器上启动 EC2 实例。
专用主机允许你使用现有的服务器许可证(带上您自己的许可证-BYOL)。
让你满足法规/合规性要求。
你可以完全查看并控制实例在服务器上的放置方式。
6. 专用实例
专用实例为您的 EC2 实例提供专用硬件。
可以与您帐户中的实例共享硬件。
但没有像专用主机那样的对实例放置的控制。
7. 容量保留
正如按需实例一节中所述,AWS 并不能 100% 保证你的实例将被启动。如果你需要保留一些容量,但不想继续进行 1 年或 3 年的长期承诺,该怎么办?
在这种情况下,你可以使用预留容量,如果不需要了,你还可以取消掉它。它不会为你产生任何成本,但可以确保你不会耗尽容量。
不需要任何承诺。你可以在需要时创建预留容量,在不需要时取消容量预留。就这么简单。
容量预留只能在特定的可用性 zone 中。
不提供任何帐单折扣。
★Amazon Macie
是一项数据安全和数据隐私服务,它利用机器学习(ML)和模式匹配来发现和保护敏感数据。
使用场景:
终端用户通过WEB页面,将一些信息上传到S3。因为有上传违规信息的风险,所以使用Amazon Macie检测文件的内容。
需要配置Amazon Macie的定义,制定风险词汇/内容。
★Amazon Lambda@edge
Lambda@Edge 是 AWS Lambda 计算服务的补充,用于自定义 Cloudfront 提供的内容。
Lambda@Edge 用于以下目的
・在请求和响应时更改标头。
・将 cookie 详细信息添加到标题中。根据请求和响应执行 AB 测试。
・根据标题详细信息将 URL 重定向到另一个站点。
・我们可以从标头中获取用户代理并找出浏览器、操作系统等的详细信息。
方案场景
某个Web 应用会部署在美西和新加坡,静态资源利用 S3 部署。
美西和新加坡的用户通过 S3 读取图片/文本等静态信息。目前 S3 部署在新加坡,虽然 CF 可以缓存静态资源,
但资源的首次加载或缓存过期、仍旧会增加美西用户的访问耗时。希望提供方案解决多个 Region 用户的访问体验。
解决方案
可以在美西和新加坡 2 个区域均部署 S3 存储桶,当客户端请求访问 CloudFront 时未命中时后访问 Origin 源站时,
利用 Lambda@edge 在 Origin Request 阶段可以对 Request 请求进行 Domain 和 Host 的修改的特性,
动态去修改源站的域名从而达到就近访问的目的,提高用户体验。
★AWS Config
AWS Config服务提供了跟踪 AWS 资源清单以及更改,并评估 AWS 资源配置的能力。
持续监控
持续监控和记录AWS 资源的配置更改。
一旦检测到原有状态发生了更改,系统将发送 Amazon Simple Notification Service (SNS) 通知,以便用户查看更改并采取相应措施。
运行问题排查
借助 AWS Config,可以获取一份 AWS 资源配置更改的完整历史记录。
Config与AWS CloudTrail 集成,将配置更改与特定事件关联起来。
持续评估
使用 AWS Config 定义预置和配置 AWS 资源的规则,持续审计和评估 AWS 资源配置。
违反规则的资源配置或配置更改会自动触发 Amazon Simple Notification Service (SNS) 通知和 Amazon CloudWatch 事件。
可以利用可视化控制面板来查看整体合规性状态并快速识别不合规的资源。
企业级合规监控
借助多账户、多区域数据聚合,可以查看整个企业的合规状态。
变更管理
可以追踪资源之间的关系并在做出更改前查看资源依赖关系。
发生更改后,可以快速查看资源的配置历史记录并确定过去任一时间点上的资源配置详情。
支持第三方资源
可以将第三方资源(例如 GitHub 存储库、Microsoft Active Directory 资源或任何本地服务器)的配置发布到 AWS 中。
可以使用 AWS Config 控制台和 API 查看和监视资源库存和配置历史记录。
可以创建 AWS Config 规则或一致性包,以根据最佳实践、内部策略和监管策略评估这些第三方资源。
最佳实践
1.log管理
如果把Accesslog和APLog都由CloudWatch管理的话,因为log的数据量大,会产生较高的费用。
因此可以使用fluent,区分Accesslog和APLog,进行分别管理。
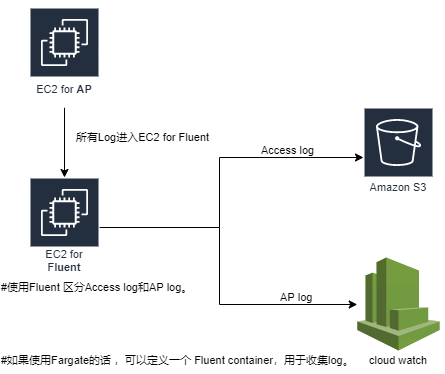
【Accesslog】
AccessLog是apache或者Nginx等webservice生成的日志。
对应于网页的每一次请求,包含有大量的信息,分析好accesslog可以对网站的运行情况有一个整体的认识,
在出现问题的情况下,也可以通过对Accesslog的数据分析结果,大致定位出问题所在。
负责网站的运维、架构相关的工程师需要对Accesslog非常熟悉,策略效果相关的工程师也可以通过对Accesslog的分析,得到用户的行为数据。
AWS Config

 浙公网安备 33010602011771号
浙公网安备 33010602011771号