
数据库
★★★★★★★★★★★操作数据库★★★★★★★★★★★
1.创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] 数据库名
[DEFAULT] CHARACTER SET字符集名
[DEFAULT] COLLATE 校对规则名;
1)[ ]中内容为可选内容
2)建表语句不区分大小写
IF NOTEXISTS:在创建数据库前判断该数据库是否存在,只有在该数据库不存在时才能执行操作。这是用来避免数据库己存在重复创建的错误。
[DEFAULT] character set:指定数据库的默认字符集,一般为utf8。
[DEFAULT] collate: 指定字符集的默认校对规则,一般为utf8_general_ci。
#字符集和校对规则可以加到数据库,表和字段上。
校对规则:https://www.cnblogs.com/adforce/p/3282404.html
实例1:
CREATE DATABASE IF NOT EXISTS test_db
DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
实例2:
CREATE TABLE‘tbl’ (
‘col_a' int(11) default NULL,
‘col_b' char(20) character set latin1 collate latin1_ general_ci default NULL,
‘col_c' char(20) character set latin1 collate latin1_ german1_ci default NULL,
KEY ‘col_a’ ('col_a'),
KEY 'col_b' ('col_b') ) ENGINE = MyISAM DEFAULT CHARSET=latin1
2 .查询数据库
语法:SHOW DATABASE [LIKE '故据库名中包含的字符串']
实例:SHOW DATABASES LIKE %test%';
3.删除数据库
语法:drop database 数据库名;
实例: drop database testDB;
数据库删除之后,原来分配的空间将被收回。数据库删除之后该数据库中所有的表和数据都将被删除。
因此删除数据库要特别小心。
4.数据库备份和恢复
#备份,要在Dos下执行mysqldump指令其实在mysql安装目录\bin
#这个备份的文件,就是对应的sql语句
mysqldump -u root -p -B test_db > d:\\bak.sql
DROP DATABASE test_db;
#恢复数据库(注意:进入Mysql命令行再执行)
source d:\lbak.sql
#第二个恢复方法:直接将bak.sql的内容放到查询编辑器中执行。
5.SQL语句分类
DDL:数据定义语句[create表,库...]
DML:数据操作语句[增加insert,修改update,删除delete].
DQL:数据查询语句[select]
DCL:数据控制语句[管理数据库;
比如用户权限 grand revo]
★★★★★★★★★★★操作表★★★★★★★★★★★
1.创建表
CREATE TABLE `table_name`
(`id` int NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '主表id' ,
`name` string NOT NULL COMMENT '名称')
ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.修改表
使用ALTER TABLE 语句追加,修改,或删除列的语法。
添加列(ADD):
ALTER TABLE table_test
ADD new_column VACHAR(32) NOT NULL DEFAULT ' ' AFTER column1;
修改列(MODIFY):
ALTER TABLE table_test
MODIFY new_column VACHAR(60) NOT NULL DEFAULT ' '
删除列(DROP):
ALTER TABLE table_test
DROP new_column
修改列名:
ATLTER TABLE table_test
CHANGE 'old_name' 'new_name' VACHAR(32) NOT NULL DEFAULT '';
修改表字符集:
ALTER TABLE table_name
CHARACTER SET utf8;
修改表名:RENAME table 表名 to 新表名;
drop table 表名;
3.查看表
DESC 表名;--可以参考表的所有列
★★★★★★★★★★★操作数据★★★★★★★★★★★
INSERT:
语法: insert into table_name (col1,col2,col3) values (col1value, col2value, col3value)
注意事项:
1)字符和日期型数据应包含在单引号中。
2)列可以插入空值(前提是该字段运行为空),insert into table_name value (null);
3)insert into table_name (列名1,列名2,…) vaules (),(),()的形式添加多条件记录。
4)如果针对表的所有字段添加数据的话,可以不写前面的字段名称。
5)关于有默认值的字段:不给某个字段值的时候,如果有默认值就会自动添加,否则会报错。
#这里是容易犯错的地方,注意默认设置的值,是我们想要的值吗。
UPDATE:
语法:update table_name set col1='test' where id in(1,2,3);
注意事项:
不写where条件会更新表中的所有记录。非常危险的行为。
修改多个字段:set 字段1=值1,字段2=值2....
DELETE:
语法:detele from table_name where id = 1;
注意事项:
不写where条件,会删除表中的所有数据。
Select:
在where字句中经常使用的运算符
比较运算符:
< , > , <= , >= , <> , != ※两个都是不等于,一般使用<>,因为可移植性强。
Between... and... , in(set) , like 'zhang' , not like ,is NULL
逻辑运算符:
and , or , not ※不成立:where not(salary >100)
例:select * from student where id between 1 and 100; ※等价于 id >= 1 and id <=100;
Distinct:
select distinct name from table_test where id=1;根据name去重。
select distinct name,id from table_test ;根据name和id两个字段去重。
Order by:
select name , id from student where id between 1 and 100 order by id DESC;
DESC:降序。ASC升序(默认)
count:
count(*)和count(列)的区别:
count(*)返回满足条件的所有数据。
count(列)统计满足条件的某列的个数,但是会排除该列的值为null的数据。
【统计没有获得补助的员工】
select COUNT(*) , COUNT(IF(comm IS NULL , 1 , NULL)) from emp;
COUNT是统计所有数据,COUNT( comm)是统计去掉NULL的数据合计。这里的1没有具体意义,可以是其他任意数值。
SUM:
select sum(chinese), sum(math),sum(english) from student ※计算各科的成绩合计。
select sum(chinese)/count(*) from student ※计算语文成绩平均分
没有group的话,只能有一条,是所有数据的合计。有group的话是按照分组合计。
AVG:
select AVG(chinese) from student ※计算语文成绩平均分
select AVG(chinese + English + math) from student ※计算总成绩的平均分
MAX和MIN:
select MAX(chinese),MIN(chinese) from student ※求最高分和最低分
【显示雇员工资的最大差额】
select MAX(sal) - MIN(sal) from emp group by deptno;
统计各个部门group by的平均工资。
字段运算:
select name , (chinese + english + math) as total_score from student;
Group By:
Group By子句对列进行分组,用于对查询的结果分组显示结果。
比如,如何显示各部内的平均工资和最高工资。
需要使用Group By进行分组之后,在组内得出平均工资(AVG)和最高工资(MAX)。
Select AVG(salary), MAX( salary), department
From info_ member Where belongto= ' beijing' Group By department having Onjob = 1;
执行顺序
在select语句中的执行顺序是group by ⇒ having ⇒ order by ⇒ limit
SELECT column1 , column2 , ... , columnN FROM table
GROUP BY column
HAVING condition
ORDER BY column
LIMIT start , rows;
例:select deptno, AVG(sal) AS avg_sal from emp
group by depyno
having avg_sal>1000
order by avg_sal DESC
limit 0,10
笛卡尔集
Select * from emp_tb, dept_tb;
从第一张表取出一行和第二张表的每一行进行组合,返回结果包含两张表的所有列。
一共返回的记录数,第一张表行数 * 第二张表的行数。
这样多表查询的默认返回结果,称为笛卡尔集。
子查询
1)单行子查询
select * from empl where deptno =
(select deptno from emp where ename= 'wang' );
检索和小王同一个部内的所有成员信息。
2)多行子查询
select * from empl where job in
(select DISTINCT job from emp where deptno=10) and deptno <>10;.
例1:
【取出价格最高的数据信息】
select goods_id, ecs_goods.cat_id, goods_name, shop_price
from(
select cat_id, MAX(shop_price) as max_price from ecs_goods group by cat_id
) temp, ecs_ goods
where temp.cat_id = ecs_goods.cat_id and max_price =eCs_goods. shop_price
#通过group By和MAX类的语句能够取出最大price,但是不能该条记录的其他信息。
3)子查询-ALL和ANY语句
【查找比所有人薪资高的人】
select ename, sal, deptno from emp where sal > ALL (select sal from emo where deptno = 30)
【查找比任何一个人薪资高的人。#比最低薪资高的人】
select ename, sal, deptno from emp where sal > ANY (select sal from emo where deptno = 30)
4)多列子查询
select deptno, job,name from emp where (deptno , job)
= (select deptno, job from emp where ename= 'wang') and ename <>'wang';
表复制
自我复制数据(蠕虫复制)
有时为了对某个SQL语句进行效率测试,需要海量的数据,可以使用此法为表创建海量数据。
1)先把emp表的记录复制到my_tab01
insert into my_tab01 (id ,name , sal, job ) select deptno, name, sal, job from emp;
2)自我复制
insert into my_tab01 select * from my_tab01 ;
这样每执行一遍my_tab01 表中的数据就会增长一倍 。
去重表中的记录
1)创建一张临时表c,该表的结构和my_tab02一样。
create table my_temp like my_tab02;
2)把my_tab02 中的数据通过distinct去重之后插入到my_temp。
insert into my_temp select distinct * from my_tab02;
3)清除掉my_tab02 中的数据。
delete from my_tab02;
4)把my_temp中的数据复制到my_tab02;
insert into my_tab02 select * from my_temp ;
5)删除掉my_temp表。
drop table my_temp;
union和union all
union将两个表的查询结果合并,会去重复数据。
union al1将两个表的查询结果合并,原样显示,不去重复。
表外连接
左外连接:左侧表的内容完全显示。
select stu. name, stu.id,exam.grade from stu
left join exam on stu.id = exam.id;
stu是主表,stu表的数据会被全部显示。
右外连接:右侧表的内容完全显示。
左外连实现
select name, job from dept left join emp where dept.deptno = emp.deptno;
dept表的所有字段都显示,在emp中没有的话显示为空。
右外连实现
select name, job from emp right join dept where dept.deptno = emp.deptno;
显示效果和上面left join的SQL文一样。
左外连的主表就是左侧的表,右外连的表就是右侧的表,主表的数据全部显示,从表没有数据的话,显示为空。
约束
primary key(主键)
语法:字段名 字段类型 primary key
注意:
1)标记为primary key的列不能重复,而且不能为null。
2)一张表最多只能有一个主键,但可以是复合主键。
3)主键的指定方式有两种
・直接在字段名后指定:字段名primary key
・在表定最后写primary key(列名)
4)使用dec表名,可以看到primary key的情况。
例:
这个例子会报错,因为不能定义两个主键。
create table tb_01
(id int primary key , 'name ' varchar(32) primary key , email varchar(32))
复合主键:
create table tb_01
(id int , 'name' varchar(32) ,email varchar(32)) primary key (id,'name') #这里是复合主键
如果在列上定义了not null , 那么插入数据的时候,必须为该列提供数据。
字段名字段类型not null
unique(唯一)
当定义了唯一约束后,该列是不能重复的。
语法:字段名 字段类型 unique
如果没有指定not null,则unique字段可以是null,并且允许多个null。
一张表可以有多个unique字段。
create table tb_01
(id int primary key , 'name' varchar(32) not null , email varchar(32) unique )
#如果一个列是not null 又是unique的话,使用效果类似primary key。
foreign key(外键)
用于定义主表和从表之间的关系:外键约束要定义在从表上,主表必须具有主键约束或是unique约束。
当定义外键约束后,要求外键列数据必须在主表的主键列存在,否则从表的数据插入不进去。
语法: foreign key (本表字段名) references
主表名(主键名或unique字段名)
例:
主表:
create table my_class
(id int primary key , 'name' varchar(32) not null DEFAULT '')
从表:
create table my_stu
(id int primary key , ' name
varchar(32) not null DEFAULT '',class_id int,
foreign key(class_id) references my_class(id))
如果在主表my_class中没有id的300的数据,那么以下SQL文执行会报错。
insert into my_stu (1, 'tom' , 300)
说明:
1.外键指向的表的字段,要求是primary key或者是unique。
2.表的类型是innodb ,这样才会支持外键。
3.外键的字段类型要和主键的字段类型一致。(长度可以不同)
4.外键字段的值,必须在主键字段中出现过,或者为null(前提是外键字段允许为null)
5.一旦建立了主外键的关系,数据不能随意删除了。
check
用于强制行数据必须满足的条件,假定在sal列上定义了check约束,并要求sal列值在1000~2000之间,如果不再1000~2000之间就会提示出错。
提示:Oracle和SQL server均支持check,但是mysq15.7目前不支持check,只做语法效验,但不会生效。
基本语法:
列名类型check (check条件)
create table tb01
(id int primary key,'name' varchar(32),
sex varchar(6) check(sex in( 'man', 'woman'))
sal double check (sal >1000 and sal <2000) )
自增长
在某张表中,存在一个id列(整数),我们希望再添加记录的时候,该列从1开始
字段名 整型 primary key auto_ increment
create table (id int primary key auto_increment , name varchar(50),age int)
添加自增长的方式
insert into tb01(id, name, age) value (null, 'tom', 20) ;
insert into tb01(name, age) value ('tom', 30) ;
insert into tb01 value (null, 'tom', 40) ;
说明:
1.一般来说自增长是和primary key配合使用。
2.自增长也可以单独使用,但是需要配合一个unique。
3.自增长修饰的字段为整数型(虽然小时也可以,很少使用)
4.自增长默然从1开始,你也可以通过如下命令修改“alter table 表名auto_increament = 新的开始值)
5.如果你添加数据的时候,给自增长字段(列)指定的有值,则以指定的值为准,如果指定了自增长,一般来说就按照自增长的规则来填写数据。
索引
语法:
create index 索引名字on对象表(对象字段)
create index empno_index on emp_tb ( id)
没有索引为什么会变慢?因为全表扫描,会遍历所有数据。
使用索引为什么会变快?形成一个索引的数据结构。
比如二叉树,找到一个数据之后根据树形结构查找目标数据。
比如,想找到id = 3的数据,第一个被查询的数据是5的话,就不会在查询比5大的数据,会依次往5以下的数据找。
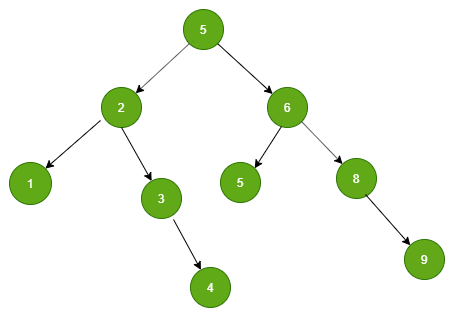
1.磁盘占用。
2.影响dml(update,delete,insert )的效率。因为在执行的时候需要做成索引。
索引的类型:
1.主键索引,主键自动为主索引(primary key)
2.唯一索引(unique)
3.普通索引(index)
4.全文索引(fulltext) [适用于MYISAM]
一般开发不使用Mysql自带的全文索引,而是使用全文索引Solr和Elasticsearch(ES)
create table1 (id int primary key , --主键,同时也是索引,称为主键索引)
name varchar(50))
create table2 (id int unique)) -- id是唯一的,同时也是索引,称为unique索引。
查询表是否有索引
show indexes from tb_test;
添加索引
添加唯一索引
create unique index id_index on tb_test(id);
添加普通索引
create index id_index on tb_test(id);
alter table tb_test add index id_index(id);
如果某列的值是不会重复的,则优先考虑使用unique索引,否则使用普通索引。
引用:https://www.cnblogs.com/liehen2046/p/11052666.html
◆索引失效
1.有or必全有索引
如果条件中有or,即使其中有部分条件带索引也不会使用(这也是为什么尽量少用or的原因)
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引。
where id=1 or user_id=100;无效。如果 id和user_id都有索引的话,就有效。
2.复合索引未用左列字段
对于复合索引,如果不使用前列,后续列也将无法使用,类电话簿。
创建联合索引index(a,b,c)的时候,
Where a=1 and b=2 and c=3 全部有效
Where a=1 and c=2 and b=3 全部有效
Where a=1 and c=2 只有a有效
Where a like '1%' and b=3 只有a有效 #
Where c=2 无效
3.like以%开头
Where a like '%1' 无效; Where a like '1%' 有效;
4.需要类型转换;
存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
where name = '123' 有效;where name = 123 无效;
5.where中索引列有运算;
Where a+1 =2 无效
6.where中索引列使用了函数;
Where MAX(a)=2 无效
7.如果mysql觉得全表扫描更快时(数据少);
◆没有必要使用索引
1.数据唯一性差(一个字段的取值只有几种时)的字段不要使用索引
比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描。2. 频繁更新的字段不要使用索引
比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。3.字段不在where语句出现时不要添加索引,如果where后含IS NULL /IS NOT NULL/ like ‘%输入符%’等条件,不建议使用索引
只有在where语句出现,mysql才会去使用索引4.where 子句里对索引列使用不等于(<>),使用索引效果一般
事务
事务用于保证数据的一致性,它由一组相关的dml语句组成,改组的dml语句要么全部成功,要么全部失败。
如:转账就要使用事务处理,用以保证数据的一致性。
事务和锁
当执行事务操作的时(dml语句),MYSQL会在表上加锁,以防止其他用户改表的数据。
MYSQL控制台事务的几个重要操作
1.start transaction --开始一个事务
2. savepoint保存点名--设置 保存点
3.rollback to保存点名--回退事务
4. rollback --退回全部事务
5.commit -- 提交事务,所有操作生效,不能回退
注意:
1.退回事务
用于取消部分事务,当结束事务时,会自动的删除该事务所定义的所有保存点。
2.提交事务
当执行了commit后,会确认事务的变化,结束事务,删除保存点,释放锁,数据生效。
当使用commit结束事务后,其他会话可以查看事务变化后的新数据。
3.如果不开始事务,在默认情况下,dml操作是自动提交的,不能回滚。
4. mysql的事务机制需要innodb的存储引擎才可以使用,myisam不好使。
5.开始一个事务start transaction,set autocommit =off。
事务的隔离级别
多个连接开启后各自事务操作数据库中的数据的时候,数据库负责隔离操作,以保证各个连接能够获取到正确的数据。
事务的ACID特性
1.原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么不发生。例:金钱交易处理,所有表更新都成功才符合原子性。
2.一致性(Consistencyp)
事务必须使数据库从一个一致性状态变换到另一个一致性状态。
3.隔离性(Isolation)
多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事物之间要相互隔离。
4.持久性(Durability)
是指一个事务一旦被提交,他对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其产生影响。
视图
1.视图是根据基表创建的,视图是虚拟的表。
2.视图也有列,数据来自基表。
3.通过视图可以修改基表的数据。
4.基表的数据改变也会影响视图的查询结果。
最佳实践:
1.不想把基表暴露出去。
有些数据库表有着重要的信息,有些字段是保密的,不能让用户直接看到。这样可以创建一个视图,让客户只看到需要的字段。
2.表集合繁琐,做成视图之后使用便捷。
如,一大堆表结合,还有多个表union等场景。
3.灵活
表升级的时候,因为有view做一层屏蔽,会大大减少修改程序作业。
create view my_view as select id, job, salary from emp;
select id, job, salary from my_view;
update my_view set salary =1000 where id=1;
drop view my_view;
MySQL用户管理
mysql的用户都存在user表中。
user中有三个字段,
host:允许登录的位置,localhost表示该表只允许本机登录访问,也可以指定IP地址,比如192.168.1.100。
user:用户名
authentication_string:密码是通过password()函数加密之后的密码。#即便在数据库中看到改密码,也无法登录。
创建用户名:
1.使用CREATE USER语句创建新用户
CREATE USER ' xiaowang ' @' LOCALHOST' IDENTIFIED BY '12345678';
#使用CREATE USER语句创建账户后在USER表中新增一条记录,但是新创建的用户没有任何权限,还需要通过GRANT语句进行赋权。
2.使用GRANT语句创建新用户
grant select, insert on *.* to 'xiaowang ' @' localhost' identified by '12345678';
#给xiaowang这个用户操控左右数据库的select和insert权限,并且只能在本地机器操作。
GRANT ALL PRIVILEGES ON test_ DB^.* To 'xiaowang'@' localhost';
#给xi aowang这个用户操控test_DB数据库的所有权限。
3.直接操作MYSQL用户表
使用CREATE和GRANT的本质都是像USER表中插入一个用户。所以也可以直接在USER表中插入一条数据。
insert into user(host , user , authentication_string) values('localhost', 'xiaowang' , password( '12345678'));
修改自己的密码:
SET PASSWORD = password( 'qwerty')
修改他人的密码(需要权限)
SET PASSWORD FOR 'root'@'localhost' = password( 'qwerty');
修改权限
GRANT update, insert ON testDB.My.TB to 'xiaowang' @' localhost';
JDBC
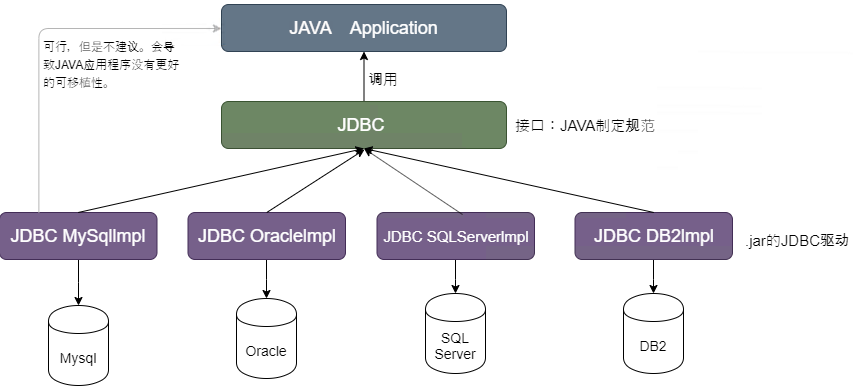
JDBC是JAVA提供的一套用于数据库操作的API接口,JAVA程序员只需要面向整个接口编程即可,JDBC已经为程序员屏蔽了细节问题。
JAVA程序员使用JDBC,可以连接任何提供了JDBC驱动程序的数据库系统,从而完成对数据库的各种操作。
JDBC API是一系列的接口,它统一和规范了应用程序与数据库的连接,执行SQL语句,并得到返回结果等各类操作,相关类和接口在JAVA. SQL和JAVAX . sql包中。数据库驱动jar包实现了Java的接口,并放回数据。因此实现的源码不在Java.SQL中。
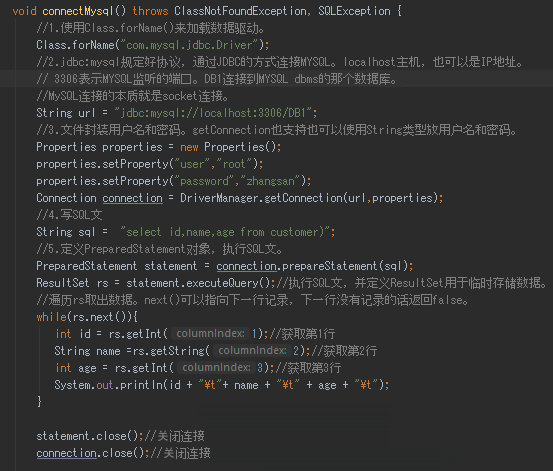
ResultSET(结果集)
1.表示数据结果集的数据表,通常通过执行查询数据库的语句生成。
2. ResultSET保持一个光标指向其当前的数据行,最初光标位于第一行之前。
3. next方法将光标移动到下一行,并且由于在resultSet对象中没有更多行时返回false。因此可以在while循环中使用循环来遍历结果集。
Statement
1. Statement对象用于执行静态SQL语句并返回其生成的结果的对象。
2.在连接建立之后,需要对数据库进行访问,执行命名或是SQL语句,可以通过Statement , PreparedStatement (预处理) , CallableStatement (存储过程)
3. Statement对象执行SQL文存在SQL注入的风险。
4. SQL注入是利用某些系统没有对输入的数据进行充分的检验,导致用户输入的数据原样进入系统,注入到SQL语句或命令,恶意攻击数据库。
5.要防范SQL注入,只要用PreparedStatement (预处理)取代Statement就可以了。
select * from admin where name='tom' and pwd = '123' ;
输入用户名:1’or, 输入密码: or '1' ='1
select * from admin where name='1’ or' and pwd ='or‘ 1' = '1 ' ;
解说:' and pwd ='变成了注释。where条件变成了where name='1' or '1' ='1',所以肯定能检索出内容。
批处理
1.当需要成批插入或者更新记录时候,可以采用JAVA的批处理更新机制,这一机制允许许多条语句一次性提交给数据库,之后数据库进行批量处理。
通常情况下比单挑处理效率更高。
2. JDBC的批量处理语句包括下面方法:
addBatch():添加嚅要批量处理的SQL语句或参数。
ExecuteBatch:执行批量处理语句。
clearBatch:清空批处理包的语句。
3. JDBC连接Mysql的时候,如果需要使用批处理功能,请在url参数中加参数{? rewriteBatchedStatements =true}
4.批处理往往和PreparedStatement一起搭配使用,可以即减少编译次数,又减少运行次数,效率大大提高。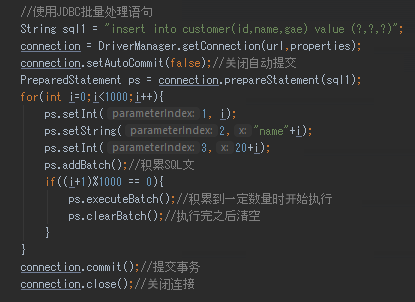
【函数】
1.数学相关函数
求绝对值 ABS(num)
select ABS(-10) from DUAL执行结果是10。
求最小值
least(number, number2, number3,. . . numberN)
select least(0, 1, -10, 4) from DUAL执行结果是-10.
求余
MOD(number, denominator)
select MOD(10, 3) from DUAL执行结果是1。
求随机数
Rand([seed])
使用Rand(每次返回不同的随机数,其范围是0<= v <=1.0.
Rand( [seed])同样是返回随机数,seed的值不变的话,随机数值就不变。
进制转换
BIN(decimal_number) 十进制转二进制
select BIN(10) from DUAL执行结果是
HEX(decimalNumber)转十六进制
CONV(number2 ,from_base, to_base) 进制转换
select CONV(16,16,10) from DUAL执行结果是22。
取位
向上取整,得到比num2大的最小整数
CEILING(number2)
select CEILING(-1.1) from DUAL执行结果是-1。
向下取整,得到比num2小的最大整数
Floor(number2)
select Floor(-1.1) from DUAL执行结果是-2。
保留小数位(四舍 五入)
FORMAT(number, decimal_ places)
select FORMAT(78.12345 , 2) from DUAL执行结果是78.12。
nvl(expr1,expr2) 如果expr1是null就返回expr2。
2.时间日期相关函数
当前日期
CURRENT_DATE()
select CURRENT_DATE() from DUAL; 执行结果是2022-04-15。
当前时间
NOW()
select NOW() from DUAL; 执行结果是2022-04-05 00:00:00。
当前时间
CURRENT_TIME( )
select CURRENT_TIME() from DUAL; 执行结果是17:30:15。
当前时间戳
CURRENT_TIMETAMP()
select CURRENT_TIMETAMP() from DUAL; 执行结果是。
insert into mg_tb (id, content, datetime) value(1, 'news ', CURRENT_TIMETAMP() )
返回期日的部分
DATE(datetime)返回datetime的日期部分
#YEAR(NOW()), MONTH(NOW(), DAY(NOW()可以取到需要的单位。
select id, content , DATE(datetime) from mg_TB
在date1中加 上日期或时间
DATE_ADD(date1, INTERVAL d__value_type)
INTERVAL后面可以是year, minute, second , day.
例:请查询在10分钟内发布的新闻
select content, datetime from mgtb where DATE_ADD( datetime , INTERVAL 10 MINUTE) >NOW( )
DATE_SUB(date1, INTERVAL datevalue_type)
在date1中减去INTERVAL后的时间。
两个日期差(结果是天)
DATEDIFF(date1,date2)
得到的是天数date1-date2的天数,因此结果可以是负数。
例:1)求出2023-11-11和2011-11-11相差多少天
Select DATEDIFF( ' 2023-11-11', '2011-11-11') from DUAL
2)求出己经活了多少天?
Select DATEDIFF (NOW(), '1985-11-11') from DUAL
3 )假设能活到80岁,剩下还有多少天
DATEDIFF (NOW(), DATE_ADD( '1985-11-11', INTERVAL 80 YEAR))
取两个时间差(结果是时分秒)
TIMEDIFF((time1 , time2)
DATE_SUB, DATEDIFF, DATE_ADD, DATE_SUB四个函数的类型可以使date , datetime , timestamp。
返回的是1970- 1- 1到现在的秒数
UNIX_TIMESTAMP( )
按照格式把秒数转换成日期型
FROM_UNIXTIME(秒数,格式)
select FROM_UNIXTIME (161848348, '%Y- %m-%d %H:%i%s') from DUAL执行结果: 2021-04-15 18:44: 44
在实际的开发中会使用int保存一个Unix时间戳,之后使用from_unixtime( )进行转换。
3.加密和系统函数
查询用户:USER()
数据库名称:DATABASE()
为字符串算出一个MD532的字符串,(用户密码)加密:MD5(str)
insert into mg_tb (id, name ,password) value (1, 'xiaowang' ,MD5( 'testpw'))
select * from mg_tb where name = parameter_name , password=MD5 (parameter_PW)
PASSWORD(str)从原文密码str计算并返回密码字符串。
4.表查询--加强
分页查询
select ..from.. limit start ,row
limit有start和row两个参数,start从0开始计算,表示从start+ 1行开始取,取出rows行。
select id, name, agefrom mg_tb order by id dsce limit 0,20
原则:(页数-1) *显示的数据条数
页数可以外部传进来。显示的数据条数可以是定死的,也可以通过设置改变。
这样就组成了SQL文,到DB中取到需要的数据。
select id, name,age from mg_tb order by id dsce limit(pageNum-1)*showNum,showNum
每页显示20条数据的话:
第1页 0,20
第2页 20, 20
第3页 40,20
5.判断函数
IF语句
Select name , IF(salary IS NULL , 0.0 , salary) from mg_tb;
如果薪资是空就显示0.0,不是空的话就显示薪资额度。
#注意:NULL的语法是“IS NULL”,不是“=NULL"。
Select name,IFNULL(salary,0.0) from mg_ tb;
如果salary不为空,就显示salary,否则显示0.0。
>,<,=等符合
在MySQL中日期类型可以直接比较,但是需要注意格式。
例:查找2020年后入职的员工
select * from mg_tb where hiredate >'2020-01-01';
模糊查询like
select * from mg_tb where name like 'Z%' ;查询首字母为Z的员工。
select * from mg_tb where name like '__Z%' ;查询第三个字母为Z的员工。
6.字符串相关函数
返回字符串字符集
CHARSET(str:select CHARSET(name) from info_tb; 返回utf8等等
连接字符串
CONCAT(string1, string2):select CONCAT(name, '工作是',job) from info_tb;
返回字符串出现的位置
INSTR(string, substring)返回substring在string中 出现的位置,没有返回0
select INSTR('abcefg','fg') from info_tb; 返回8
大小写转换
UCASE(string2)转换成大写:select UCASE('abc') from info_tb;
LCASE(string2)转换成小写:select UCASE('ABC') from info_tb;
取字符串
LEFT(string2, length)从string2 中的左边起取length个字符:select LEFT( 'ABC',1) from info_tb;取到' A'
SUBSTRING( str , position, length])从str的position开始 (从1开始计算),取length个字符
select SUBSTRING('name',1,2) form info_tb ;取出'na' 两个字符。
取字符长度:
LENGTH(string) string的长度 [按照字节]
select LEFT( 'ABC') from info_tb;
替换:
REPLACE(str, search_str, replace_str) 在str中 用replace_str替 换search_str
select REPLACE( '测试以下呀','以下','一下');
比较:
STRCMP(string1 ,string2)逐个字符比较两个子串大小.
select STRCMP( '测试',' 测试1') from info_tb;
去空格:
LTRIM( string2)和RTRIM(string) 和trim去除前端空格或后端空格。
selcet LTRIM(' 测试' );
selcetRTRIM( '测试 ');
selcet TRIM( ' 测试 ');
★★★★★★★★★★★数据类型★★★★★★★★★★★
1.char和vachar
char会浪费空间,如果知道数据的长度可以使用char。例如,密码,邮编,手机号,身份证号。
事先不知道数据的长度的话,使用变长的vachar。例如,留言,文章等。#char的优点是查询速度快。
1)char(4) 这个4表示4个字符数(最大255字符),不是字符数,不管中文还是字母都是放四个。按字符计算。
char占用的是定长(固定大小),就是说,即使你插入‘aa’,在char(4)定义中,也会占用4个字符。
2)vachar(4) 这个4表示字符数(最大长度65532字节,utf8编码最大21844字符),不管字母还是中文都以定义好的表的编码来存放数据。
vachar是变成,实际占用空间大小并不是4个字符,而是按照实际占用空间来分配。
(vachar本身还需要占用1-3个字节来记录存放内容长度)
实例:
create table tb1('name' char(4));
insert into tb1 values('abcde'); ⇒这条语句会报错,因为装不进去4个字符以上的数据。
insert into tb1 values('你好呀中国'); ⇒这条语句会报错,因为装不进去4个字符以上的数据。
creat table tb2('name' vachar(32766)) charset gbk;
如果vachar不能满足长度需求的话可以考虑使用mediumtext,longtext,text.
create table tb3(content text , content2 mediumtext,content3 longtext);
2.decimal,float,double
1)float/double[UNSIGNED],float是单精度,double双精度。
2)decimal[M,D] [UNSIGNED]
可以支持更加精度的小数位。M是小数位数(精度)的总数(小数点前后合计位数),D是小数点(标度)后面的位数。
如果D是0则没有小数点或分数部分。M最大65,D最大是30。
如果D被省略则默认为0。如果M被省略则默认为10。
建议:希望小数精度高的场景,推荐使用decimal。
实例:
create table tb4 (num1 float , num2 double, num3 decimal[30,20])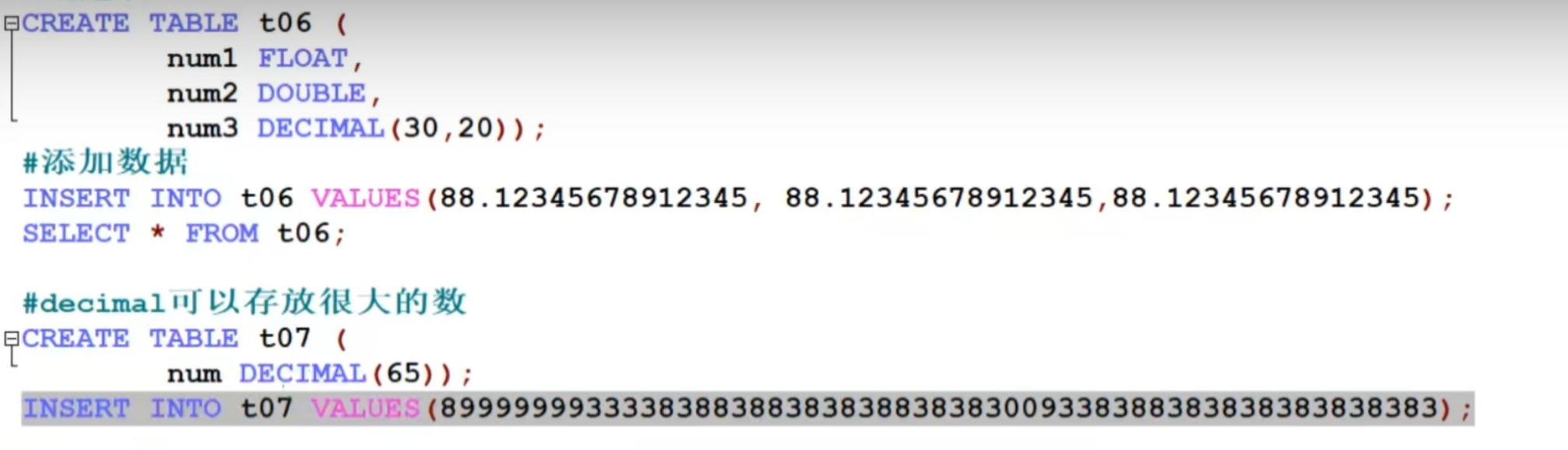
单精度有6位小数,双精度有15位小数。
单精度数(float型)在32位计算机中存储占用4字节,也就是32位,有效位数为7位,小数点后6位。
双精度数(double型)在32位计算机中存储占用8字节,也就是64位,有效位数为16位,小数点后15位。
3.日期类型
主要的日期类型有date,datetime,timestamp三种。
实例:
create table info_tb1 (birthday data, injoindate datetime,
t3 timestamp NOT NULL
DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
insert into info_tb1 (bithday , injoindate ) values ('2021-11-11','2011-11-11 10:10:10');
#timestamp在insert和update时,自动更新。
★★★★★★★★★★★SQL注意事项(优化,易错等)★★★★★★★★★★★
1.in和exists
1)in语句有数量显示,在Oracle中超过1000条数据的话,就会报错。
2)exists比in效率高的说法不够准确。
原因:
・查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in。
・反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。
in是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
だから、一直以来认为exists比in效率高的说法是不准确的,要看场景。
不要使用not in
如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。
因此,无论哪个表大,用not exists都比not in要快。
2.Oracle或mySQL中如果字段的值为null,并且在where中该字段有不等于判断。那么null数据不会被检索出来。
select * from testN where id<>2;
解决方法:
方案1 :SELECT * FROM testN WHERE NVL(ID,9999)<>2;
方案2:select * from testN where id<>2 OR ID IS NULL;
3.and的执行优先级最高!
当使用or 和 and 拼接语句时,需要注意执行的先后顺序。
where 后面如果有and,or的条件,则or自动会把左右的查询条件分开,即先执行and,再执行or。
原因就是:and的执行优先级最高!
逻辑运算的顺序
SQL1: select count(*) from tableA where DEL_FLAG = '0' or DEL_FLAG is null and 1 <> 1
相当于
SQL1: select count(*) from tableA where DEL_FLAG = '0' or (DEL_FLAG is null and 1 <> 1)
当判断第一个条件DEL_FLAG = '0' 满足时,就不再继续判断后面的条件了
而
SQL2: select count(*) from tableA where (DEL_FLAG = '0' or DEL_FLAG is null) and 1 <> 1
判断(DEL_FLAG = '0' or DEL_FLAG is null)这个条件的结果,并且要同时满足后面的 and 1<>1
显然 1<>1 是false
回避数据重复插入(当记录不存在时插入 insert if not exists)
基于一些场景,插入记录前,需要检查这条记录是否已存在,只有当记录不存在时才执行插入操作。
例1:插入多条
假设有一个主键为 client_id 的 clients 表,可以使用下面的语句:
INSERT INTO clients (client_id, client_name, client_type)
SELECT supplier_id, supplier_name, 'advertising'
FROM suppliers WHERE not exists (select * from clients where clients.client_id = suppliers.supplier_id);
例2:插入单条
INSERT INTO clients (client_id, client_name, client_type)
SELECT 10345, 'IBM', 'advertising'
FROM dual WHERE not exists (select * from clients where clients.client_id = 10345);Where a like '1%'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号