
并发系统实践1
最近项目里面遇到了一个较为复杂的并发系统设计,虽然最终还是实现了并投入运行,但是耗时还是挺久的,想想可以总结下,希望可以帮助以后的设计和实践,需要注意的是,我专注于介绍遇到的问题以及相应的解决思路,可能不够系统性,欢迎指正。
谈到并发,很多童鞋听到的都是优点,我想泼下冷水,虽然多线程可以极大的提高效率,吞吐量等,但是并发不是银弹,引入的同时会提高系统的复杂性,给设计和调试带了难度(还不包括引入的系统开销例如线程切换等),所以需要辩证的来看待并发,这点很多基础并发书籍都会在最开始介绍。
背景介绍
我们所做的是一个监控系统,用于监控我们开发的线上服务。我们的线上服务大致包括两部分,

首先定义下我们的监控目标:延迟。也就是说,A的流入数据到B的产出数据时间在95%的percentile超过5分钟即表示有较大延迟需要报警。
初步设计
根据目标,我们设计的初步架构是在内存中保存所有的数据结构,并根据我们的阈值打各种perfCounter,再通过Counter内置的统计计算和报警系统进行报警。这样设计的目的是:简单并可以快速原型化,目前的需求不需要历史记录,所以落盘也就没有必要了。
首先第一个遇到的问题是,如何监控我们高度依赖的服务A?
我们希望降低监控系统对被监控系统的耦合,所以很自然的还是想到了引入一个中间件来解决,就是kafka queue。这样,我们打算给A和B定义如下几组kafka消息,我们需要监控目标就变成了最初的消息和最后的消息的时间差,结构大致如下:
消息结构:
- 时间戳;
- 步骤名称;
- 各个步骤的额外数据;
- id;
- 是否成功;
- 错误消息;
总体思路可以描绘如下:
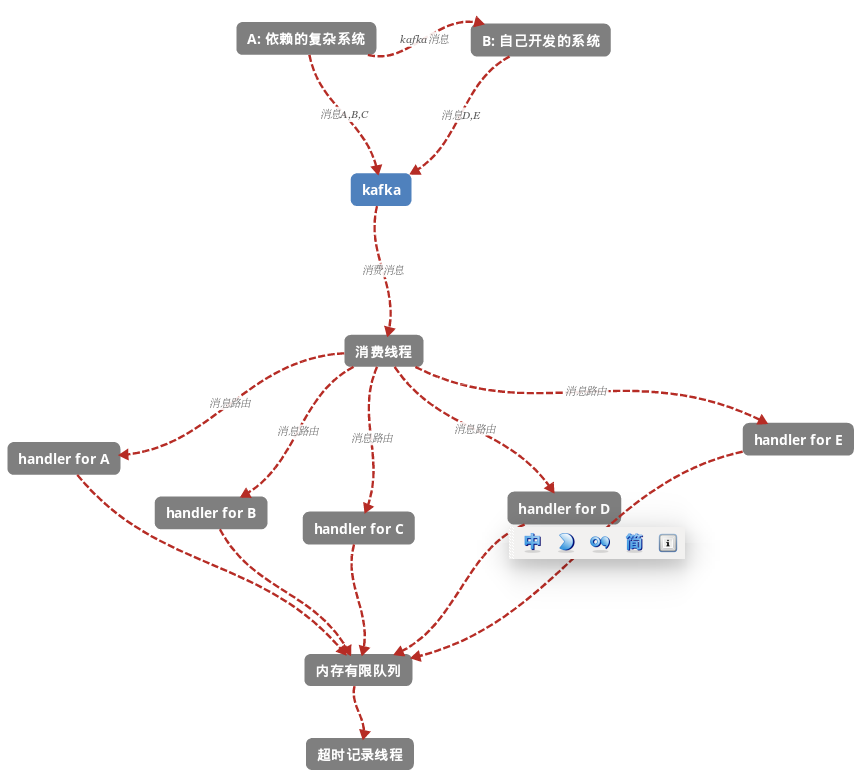
总共有两个线程,一个是主线程,负责从kafka中取消息消费,并根据消息类型路由到各个handler处理;另一个线程是超时记录线程,用于不断的从内存队列中取消息并计时,如果超时且没有没有收到消息E(结束)即认为超时并打上报警的counter。
所以,一次处理超时的定义为 time(E) - time(A) > threshold
这里需要考虑的问题是怎么设计数据结构来存储消息以及如何加锁来控制并发呢?
由于A,B,C,D,E的消息获取记录都需要,因为系统的这次处理可能中断在任何一个消息的处理上,所以这些收到的消息都需要给到超时记录线程用于报警。所以,很自然的想到了ConcurrentMap,key是消息id,value则是另一个map,包括了各个消息步骤的数据,key是步骤名,value是消息。
通过wiki我们知道,
A Map providing additional atomic putIfAbsent, remove, and replace methods.Memory consistency effects: As with other concurrent collections, actions in a thread prior to placing an object into a ConcurrentMap as a key or value happen-before actions subsequent to the access or removal of that object from the ConcurrentMap in another thread.
这个并发map,保证了删除和放入的原子性,以及可见性,这样这个数据结构就相当于自带锁了,它会同时被消费线程和超时记录线程访问。
(这里有个小技巧需要注意,操作value的时候往往需要判断是否存在某个key,因为这个key随时可能被其他线程删除,所以一般来说是把value的引用记下来而不是判断一次后,每次都去读,因为有被异步删除的风险。)
乍一看,逻辑似乎很清晰,各个消息的handler在处理消息的时候,判断有没有失败,失败就直接报警(当作处理不成功),成功的话直接放入超时线程计时。对于E的handler,多加上判断是否结束,如果结束,把当前的时间差记录下来并直接返回(删掉map中的key)。
版本迭代
2.0版本:
细心的同学应该发现,这里还有并发问题:
- 对于一个消息,在整个流程中,其实应该只被打一次的(成功或者失败),但是我们之前方案并没有考虑,可能一个消息在E处刚打了成功,与此同时,超时记录线程正好记录到超时(没来得及检查map的key是否被删除),这个时候消息就被打了两次时间,造成数据不真实;
这个并发问题不容易发现是因为,共享变量不是那么好察觉,不像那个map,这个打counter其实也是共享变量,所以审视一个并发系统需要从整体和局部同时考虑,局部上我们发现需要对map加锁,整体上,监控系统的输入是各种kafka消息,输出是counter计时,这样考虑我们可能就比较容易发现这个隐藏的共享变量了。
那么怎么解决呢?对每个消息的counter加锁即可。由于不想在原来的map加数据了,所以新加了一个concurrentMap来记录每一个消息id->AtomicBoolean,这样,在每次打成功或者失败的counter的时候,用CAS判断即可,本身AtomicBoolean是保证可见性的,这点就不需要担心了。
可是,不久又有新需求来了,大家需要知道每一个消息A,B,C,D,E的处理时间差,这样方便定位是哪一步比较慢。
3.0版本:
针对这个问题,我看到是同一个id的每一步都需要打一次的锁,所以,又建了一个每一个id+step的ConcurrentMap来记录每一个id+step -> AtomicBoolean来保证每一个step都只被打一次。
改完之后,上线发现C,D和E的时间比E的时间还长,思前想后,突然发现没有考虑到A,B,C,D, E的顺序是不保证了,所以,不能假设C比D早来,或者E比D晚来,这样就造成了,某些id的处理E先来了,打了一个结束时间的counter,C和D还没来,等它们来了,由于已经结束了就不会计时了,这样造成总体C,D的时间少了。解决方法是,在E来了,结束时,检查C,D是否来,没来按当前时间打即可。
总结
直到这个版本上线,才使得总体的时间指标看起来比较正常,这3个版本走走停停改了将近1个月感慨良多,深刻的理解了多线程带来的系统复杂性和调试复杂性,觉得有下来以下几点值得总结:
- 在设计的时候,尽量多花时间考虑清楚可能造成并发问题的点;
- 可以从整体和局部,输入和输出等多方面来考虑并发点,再设计相应的并发工具解决;
- 在引入多线程的时候,要考虑到即将造成的复杂性提升,需要有权衡的思考;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号