
Coursera台大机器学习课程笔记5 -- Theory of Generalization
本章思路:
根据之前的总结,如果M很大,那么无论假设泛化能力差的概率多小,都无法忽略,所以问题转化为证明M不大,然后上章将其转化为证明成长函数:mh(N)为多项式级别。直接证明似乎很困难,本章继续利用转化的思想,首先想想和mh(N)相关的因素可能有哪些?不难想到目前来看只有两个:
- 假设的抽样数据集大小N;
- break point k(这个变量确定了假设的类型);
那么,由此可以得到一个函数B,给定N和k可以确定该系列假设能够得到的最大的mh(N),那么新的目标便是证明B(N,k) <= Poly(N)。这便是本章的主要目标。

上图展示了不同N和k如何影响最终的growth function,表达了本章的重点是证明growth function是Poly的。
接着,问题可以进一步简化,上面我们知道growth function由N及H决定,而H又可以转为k,一个k决定了一类H,这样的抽象推导出了一个很重要的函数,这个函数的y是growth function,X则分别为N和k。

典型的例子是positive intervals和1D perceptrons的k都为3,它们的growth function即时一致的,换句话说,这个函数将H的本质通过k表达了出来。
原目标就继续转化为证明B(N,k)为poly。
证明的过程很巧妙,以B(4,3)为例子:
步骤1:找出B(4,3)和B(3,x)的关系,则可以得到一个递推式
B(4,3)已知为11,dichotomy如下:
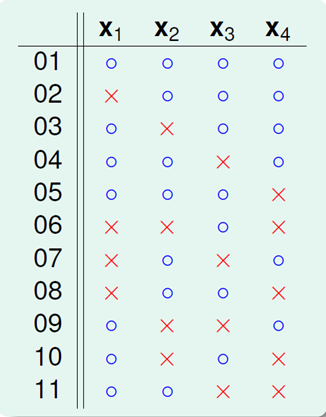
也就是说再加一种dichotomy,任意三点都能被shattered。11是极限。
对这11种dichotomy分组,目前分成两组,分别是orange和purple,orange的特点是,x1,x2和x3是一致的,x4不同并成对,例如1和5,2和8等,purple则是单一的,x1,x2,x3都不同。
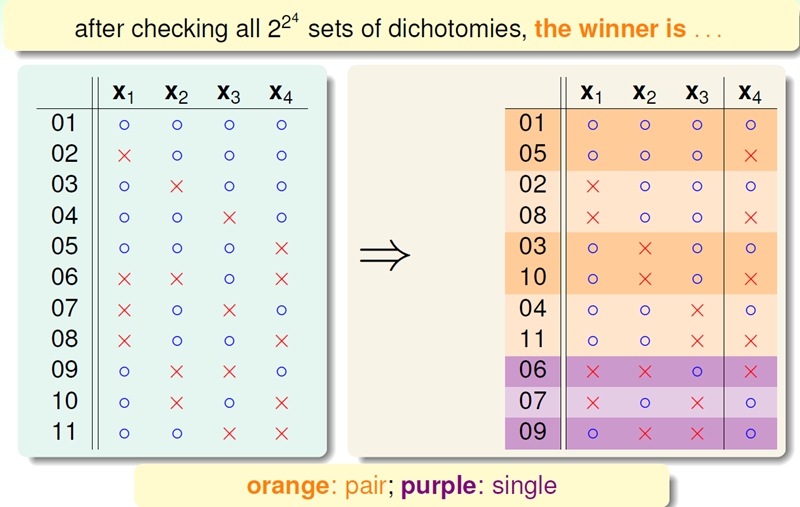
这是第一步化简,将Orange去掉x4后去重得到4个不同的vector并成为alpha,相应的purple为beta,那么B(4,3) = 2*alpha + beta,这个是直接转化。紧接着,由定义,B(4,3)是不能允许任意三点shatter的,所以由alpha和beta构成的所有B(4,3)的所有三点组合也不能shatter(alpha经过去重),即alpha + beta <= B(3,3)

最关键的来了,首先给出结论,alpha的vector不能在任意两点被shatter,为啥?反证法,假设可以,那么由于alpha对x4是成对出现的,所以把apha加上x4就能构成三个点的shatter,这个地方非常巧妙这也道出了之前这样分组的精髓,所以alpha <= B(3,2)。

由此得出B(4,3)和B(3,x)的关系。

步骤二:推导出一般式
有了前面一步的基础,后面的就很直接了。

展开可以,接着得出:

那么得出的结论就是:

上面明显是poly的,由此得出来我们梦寐已久的结果。
光有这个还不行,我们要带到下面的关键不等式中才能最终得出,选取最小Ein 假设是可以的忽略错误的,只要有breaking point存在于假设。

这里的证明我大致看了一下,对整体理解不是很大帮助,准备以后上完大部分课程后再看看。
总结:
本章的结论很明显,即时假设看起来是无穷的,只要存在breaking point,那么growth function便是多项式级别,假设的数量是限定的,我们只要保证Ein足够小,那么N大以及breaking point存在可以保证该假设具有较好的泛化性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号