机器学习笔记17(Lifelong Learning)
Lifelong Learning 终身学习
1、什么是Lifelong Learning
2、怎么做Lifelong Learning
(Elastic Weight Consolidation )EWC
其他方法
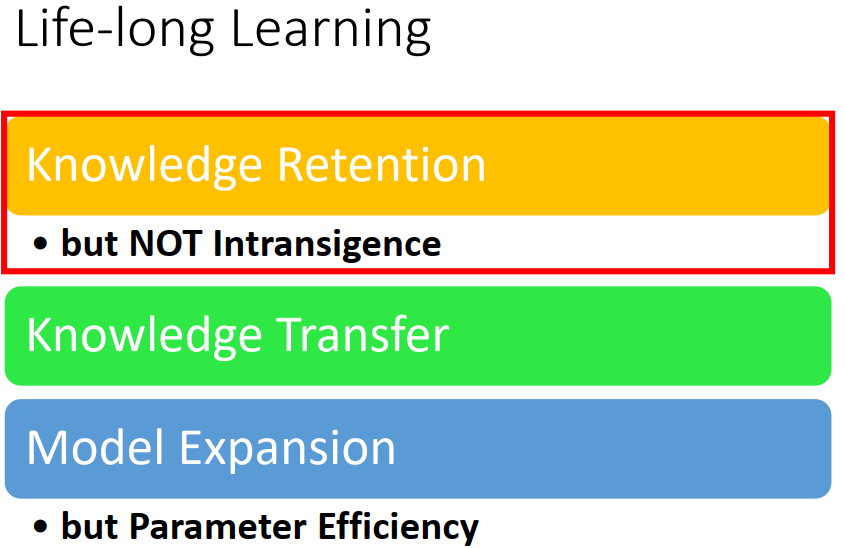
3、怎么评估Lifelong Learning
4、Model Expansion
5、Curriculum Learning 课程学习(任务排序, 如何排序?)
1、什么是Lifelong Learning
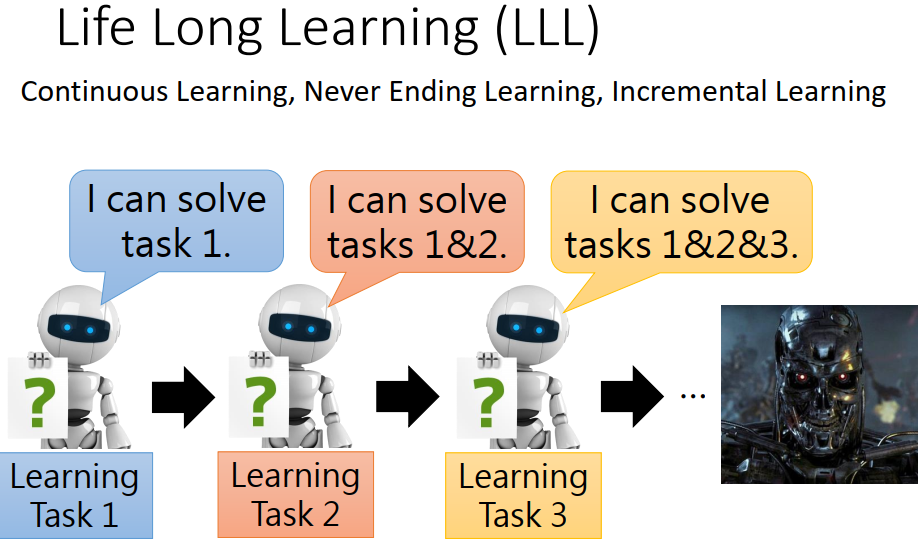
在我们前面的任务中,每个任务都需要有不同的的神经网络,只能解决某一个问题。但是我们想要用一个方案解决所有的问题。像这样,学习完第一个任务之后,再学习第二个任务,就可以同时解决两个问题了。以此类推就可以解决好多问题。也就是说在学习后面的内容的时候,也要保证前面学习过的东西不能忘掉。
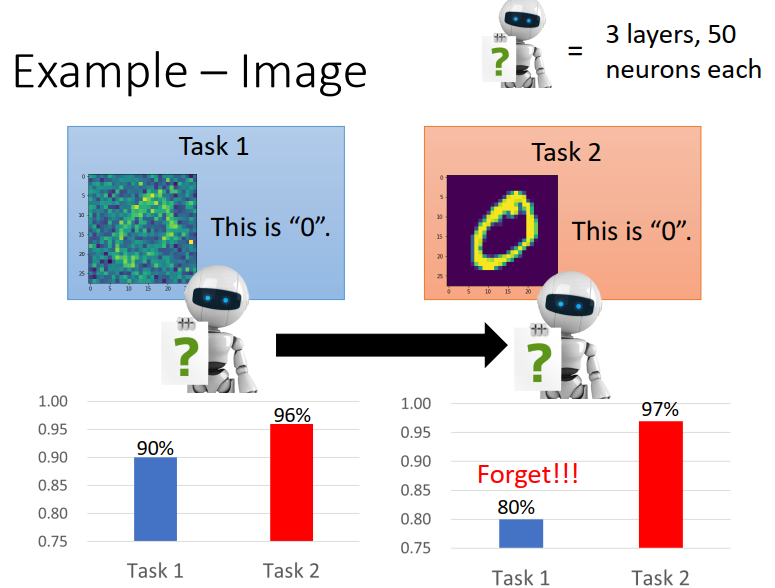
但事实上,现在并不能做到这样。如下分别训练一个NN,来进行数字识别,两个可以得到很高的正确率;但是如果首先用一个NN来训练task1,完成之后再用这个NN的参数作为初始参数来训练task2,虽然对于task2能得到不错的正确率,但是再去判别task1就会变差。也就是忘掉了前面学过的内容。
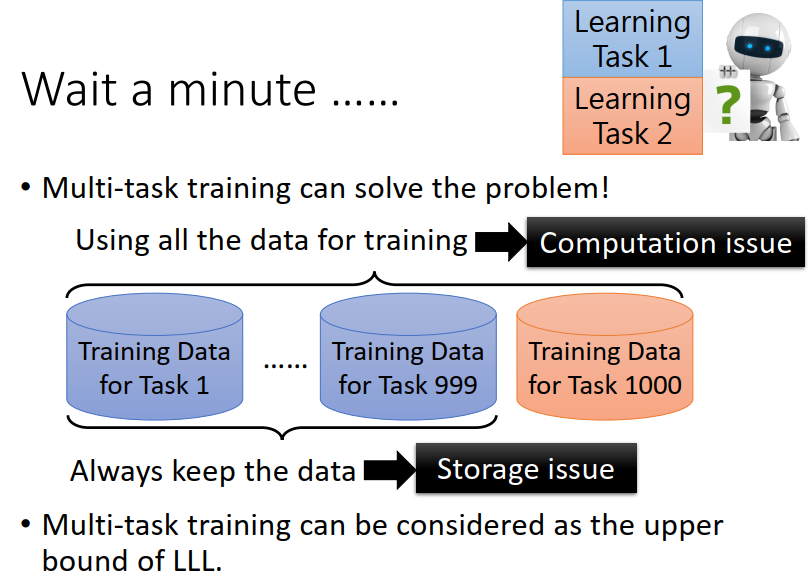
但是如果直接用两个任务的data去训练一个NN,则会得到不错的结果,也就是说机器是有能力学习到这么多的东西的。并不是能力限制,比如数据量太多等。

同样的,对于其他方面也是一样的结果,在学习完后面的内容之后,就会忘记前面所学过的内容。
但是我们不能采用前面说的把所有的资料都放在一起学习的方法,比如已经学习了999组data的NN,如果又需要学习第1000种东西,则又重新需要将所有的data放在一起重新训练,这是个很耗时费力地过程。机器终将背负他的一生。
2、怎么做Lifelong Learning
一、(Elastic Weight Consolidation )EWC
NN中的一些参数,对于对于前面已经学过的任务而言这些参数很重要,但是也有些参数对于前面的内容并不太重要;在学习后面的任务时,我们只改变这些不重要的参数就可以了。
L为前面已经学过的任务的 loss function,L` 如下图所示,𝜃𝑏 是NN中前面已经确定的参数,𝜃i 为同个位置后面需要的参数,在前面加上bi 之后,bi表示 𝜃 这个参数有多重要;举例说明,如果 bi = 0,那说明 不管 𝜃i 为多少,都对前面的任务没什么影响,对于这个参数而言,新的 L 和原来的 L一样, loss function并没有发生改变,但是如果 bi 很大,则略有改动 𝜃i 就会使得NN对于前面的任务改变很大。


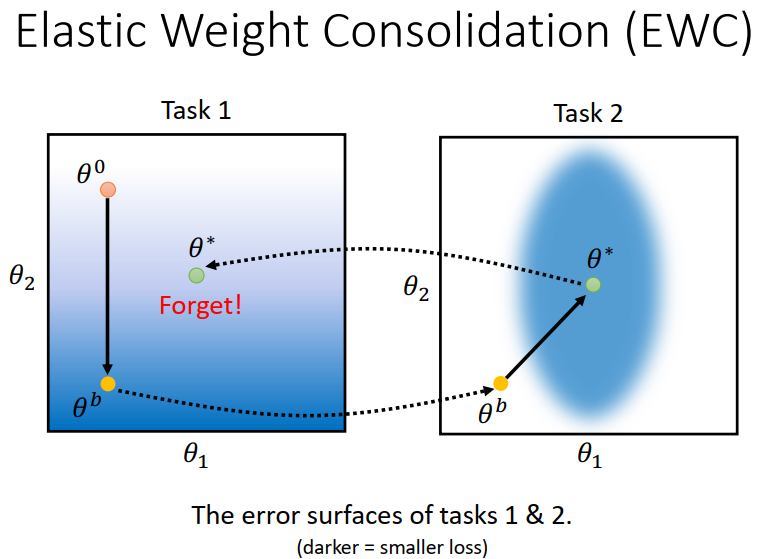
图形理解:
假设一个NN有两个参数,在train task1的 时候,蓝色部分说明 loss function 小,白色的部分说明,loss function 比较大;在我们对task1训练的时候,随机选取一个点𝜃0,train完之后,达到了新的点𝜃b,然后继续用这个参数作为初始参数来train task2,两个参数到达了新的位置𝜃* ,这个时候我们发现这个NN在task1 上的表现会变差。
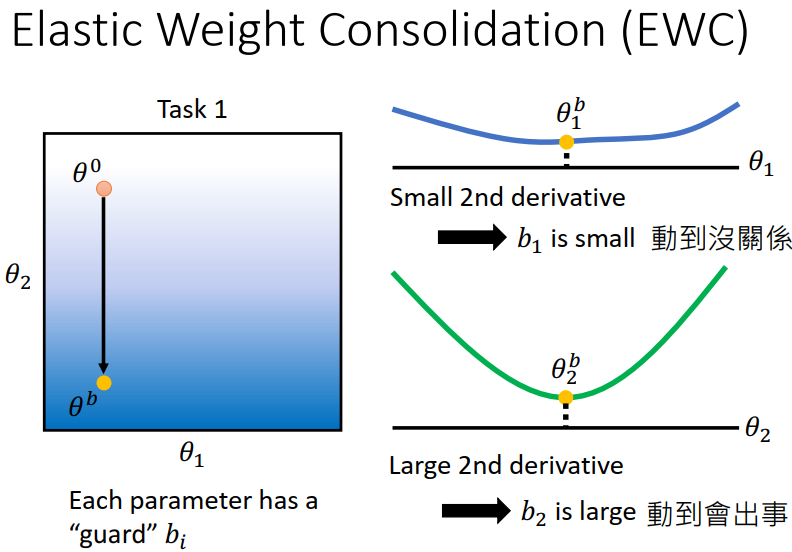
因此我们求取关于两个参数的二次微分,发现对于参数𝜃1而言,改变并不会对 L 有较大影响,因此这个b1就可以选的比较小,而对于参数𝜃2,改变会对 L 有较大影响,因此这个b2就要选的比较大,在训练时也就不能轻易改变𝜃2的值。
二、 其他方法
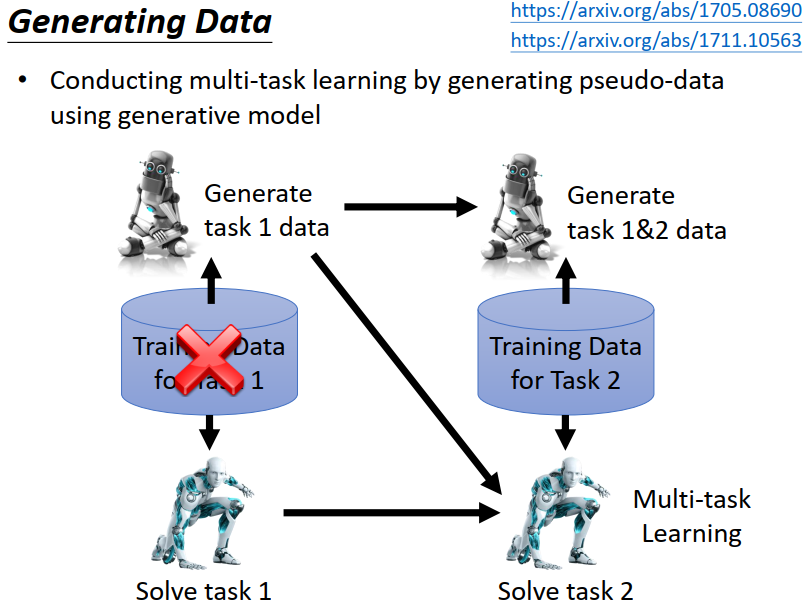
1)生成数据
使用一个生成器 来替代存储大量的数据集。 需要数据集来训练任务时,直接使用生成器来生成数据即可。先让机器学task1,然后学task2,同时要训练generator,学会生成task1的数据,此时就可以把task1的data丢掉,用生成的数据和task2的放在一起训练。
PS: 目前靠机器生成复杂数据,能不能做的起来尚待研究
2017 Continual Learning with Deep Generative Replay https://arxiv.org/abs/1705.08690
2017 FearNet: Brain-Inspired Model for Incremental Learning https://arxiv.org/abs/1711.10563
2)
当不同的任务需要使用不同的网络结构时,该如何更改网络结构呢?
Learning without Forgetting https://arxiv.org/abs/1606.09282
iCaRL: Incremental Classifier and Representation Learning https://arxiv.org/pdf/1611.07725.pdf

Knowledge transfer
不使用不同的model 来训练不同的任务的原因:
1. 一个模型学习一个任务。会出现不同的任务之间是相互独立的,我们希望 模型/任务之间是有关联的,知识的学习应该是存在递进关系的,不同任务之间的学习应该能互相促进。
2. 存储空间与任务数量是线性的,我们希望更小的模型学习更多的东西。

但同时,LLL不同于Transfer Learning (前一节),迁移学习只关注当前的任务,LLL要求不能忘记之前的任务。
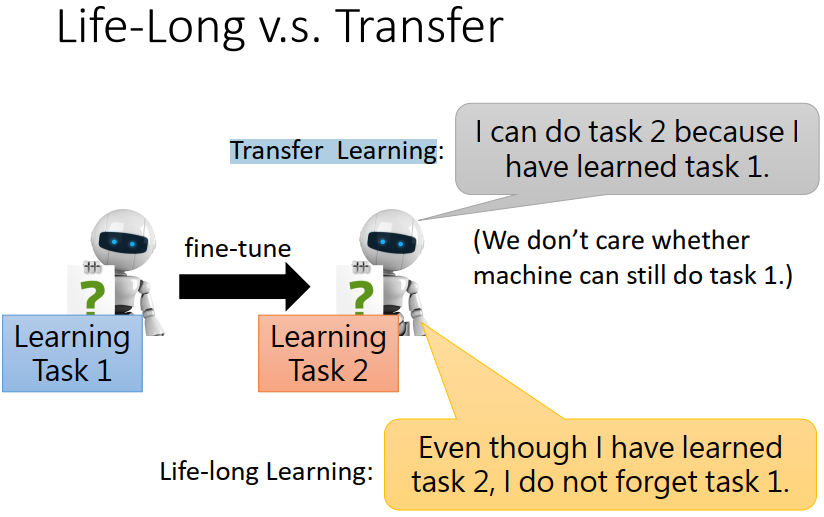
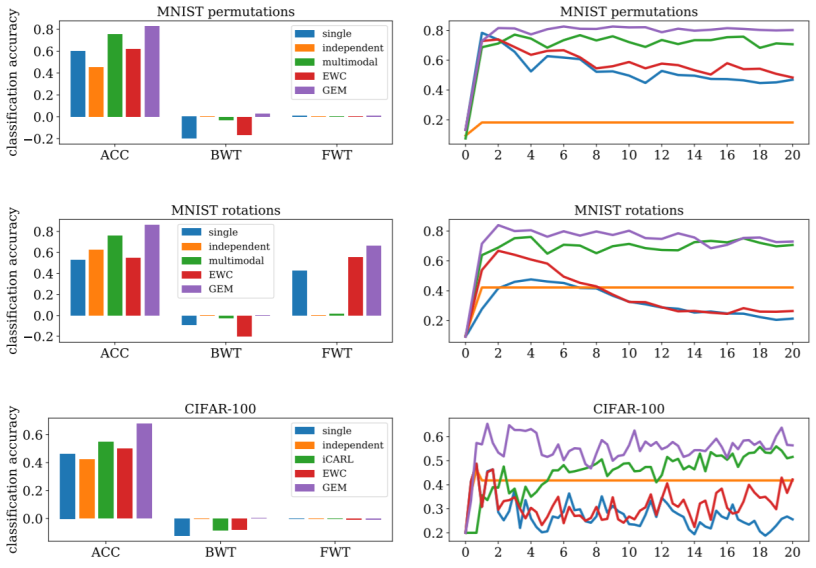
3、怎么评估Lifelong Learning
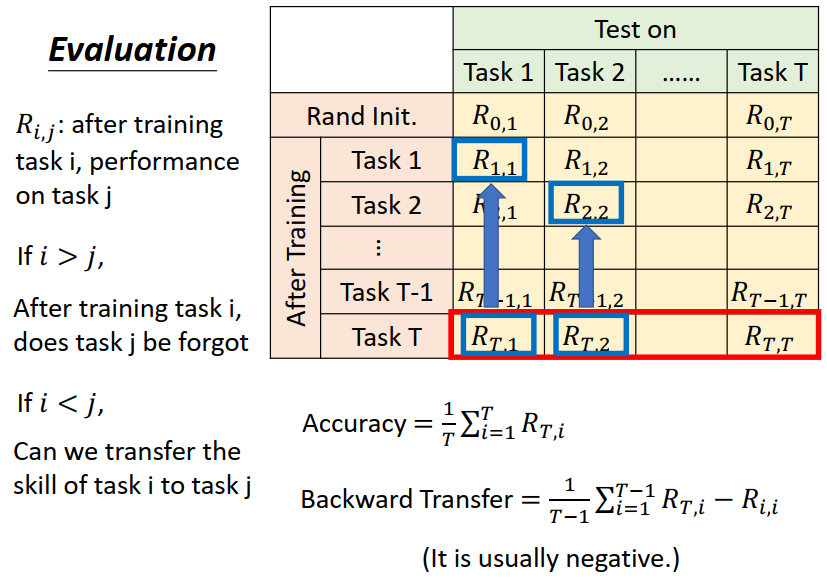
如下表所示,横着表示model在每个task上的表现如何,数着表示在学完新的task之后,在每个task上表现如何;比如,R0,1 R0,2,.....,R0,T,表示还没学习时,model在每个task上的正确率。R1,1 R1,2,.....,R1,T,表示在学习完task1之后,在各个task上的表现如何。
评估的方法有三种:
1、Accurary (红色方框)
2、Backward Transfer (蓝色方框)(BWT)
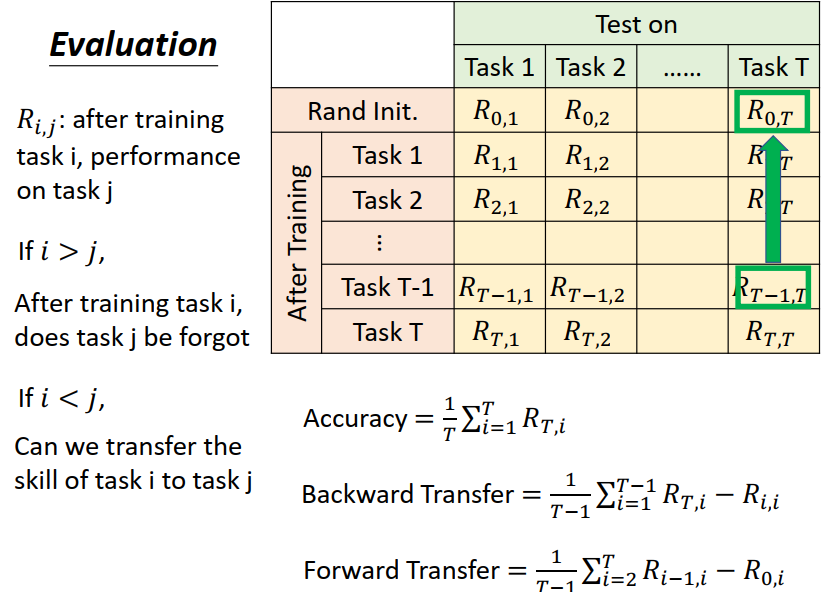
3、Forward Transfer (绿色的方框)(FWT)
Gradient Episodic Memory (GEM)
Gradient Episodic Memory for Continual Learning https://arxiv.org/abs/1706.08840
Efficient Lifelong Learning with A-GEM https://arxiv.org/abs/1812.00420
在当前任务上进行的每一次权重修改,都需要计算当前权重对先前任务的梯度方向,保证最终的权重修改方向与先前任务(即先前任务数据集,所以需要利用之前的数据集)在此时的权重修改方向的內积为正。目的是为了保证不对之前的任务产生负影响,甚至产生好的影响。
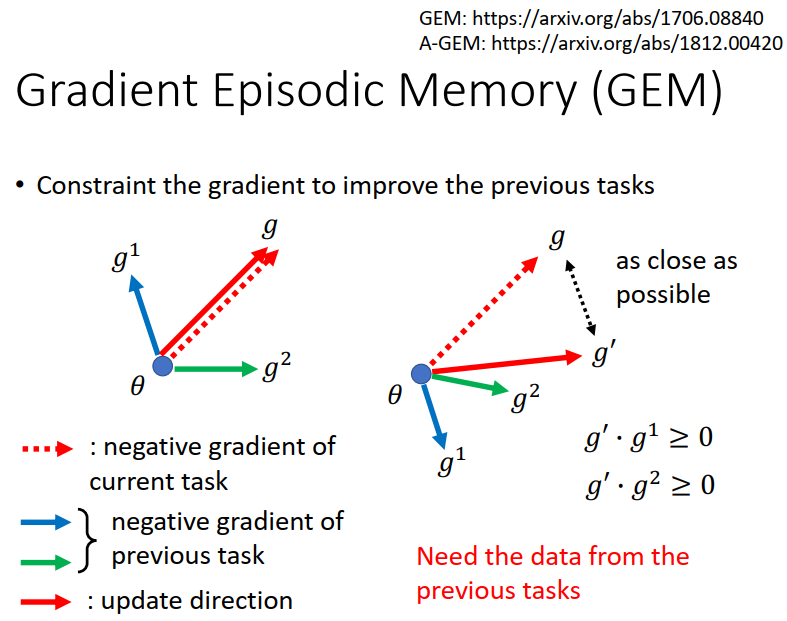
GEM的BWT是正的,说明学习新的任务提升了旧任务的表现。
4、Model Expansion

当我们的model完不成我们需要的任务时,我们希望我们的model会进行扩张,比如多生成几个神经元,同时也我们希望模型的增长速度是低于任务的增长速度。
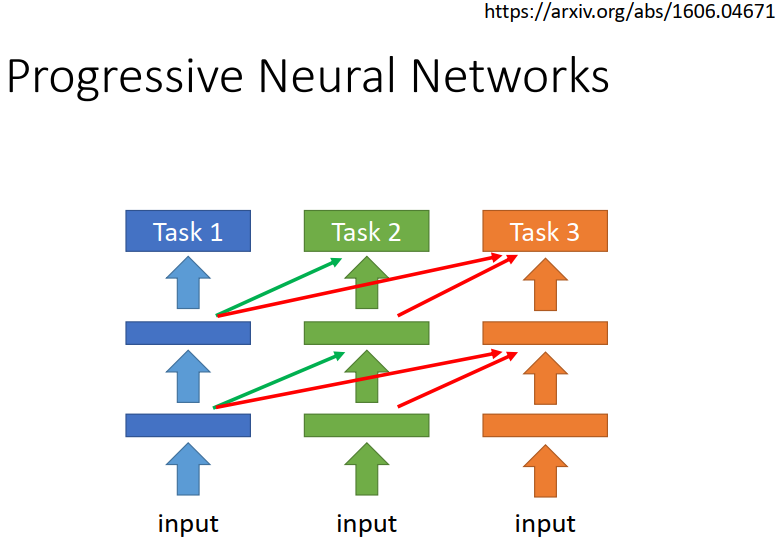
1)Progressive Neural Networks
训练新任务时,利用之前的模型参数。多一个任务,多一个模型。
2016 Progressive Neural Networks https://arxiv.org/abs/1606.04671
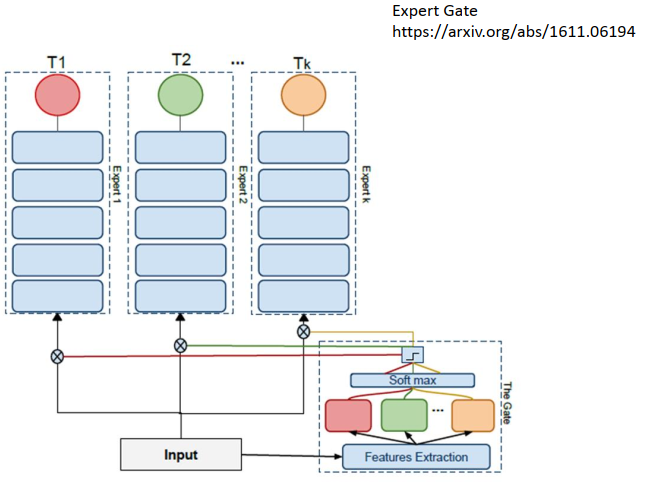
2)多一个任务多一个模型;利用之前的模型来建立新的模型。
Expert Gate: Lifelong Learning with a Network of Experts https://arxiv.org/abs/1611.06194
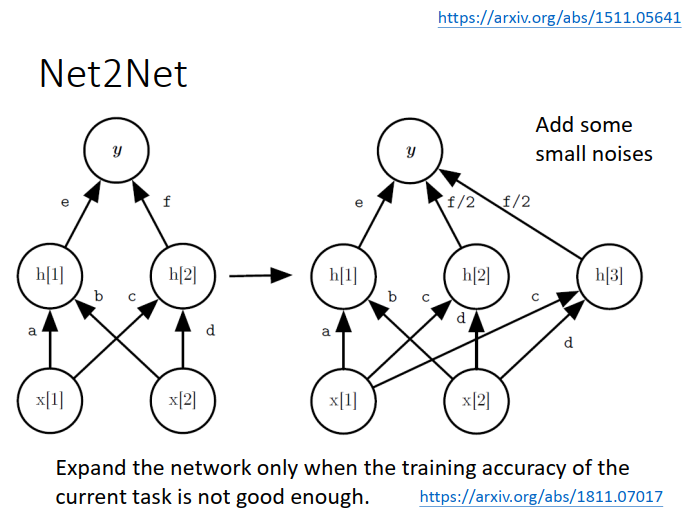
3)将原来的节点一分为二,之后加 noise 保证两个节点有点却别,能学习心得任务,但不忘记旧的任务。
2016 Net2Net: Accelerating Learning via Knowledge Transfer https://arxiv.org/abs/1511.05641
2019 Towards Training Recurrent Neural Networks for Lifelong Learning https://arxiv.org/pdf/1811.07017.pdf
5、Curriculum Learning 课程学习(任务排序, 如何排序?)
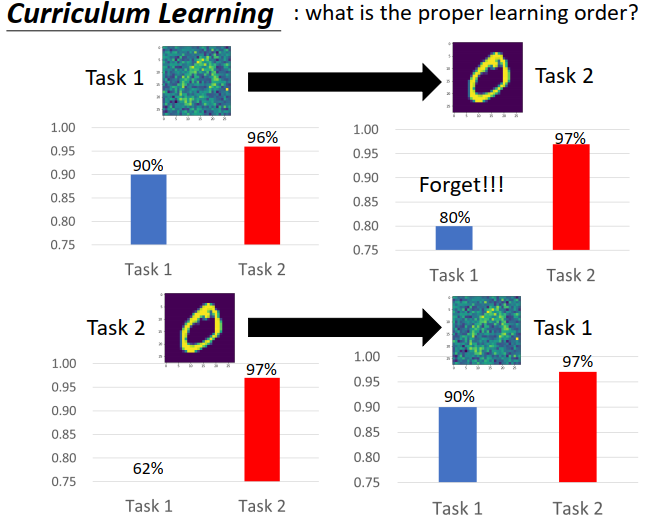
如果LLL完全实现了,那如何排出一个最有效的学习顺序呢?Curriculum Learning
2018 Disentangling Task Transfer Learning CVPR18 beat paper : http://taskonomy.stanford.edu/#abstract
下图是说明,顺序不同,训练的结果不同。