基础字符串总结
讨厌字符串...
关于字符串的一些定义:
1. 哈希(Hash)
没什么可说的,将字符串表示为
可能有哈希冲突,通常可用双哈希(不过我懒)。
一些题也可以用哈希冲过去,是一个不错的工具。
2. kmp算法
3. 后缀数组(SA)
一个稍难但极好用的算法。
3.1 定义
- 设
3.2 后缀排序
后缀排序算法可以求出后缀数组,用的是倍增法。
假设我们已经求出来所有
考虑一种优化,我们发现对于二元组的第二维,如果
(还有 DC3
int n,m,p;
char c[N];
int sa[N],rk[N],ork[N<<1],id[N],cnt[N];
bool cmp(int a,int b,int w){return ork[a] == ork[b] && ork[a + w] == ork[b + w];}
//若与相等的不加,否则加
int main(){
scanf("%s",c+1);
n = strlen(c+1),m = 128;
for(int i = 1;i <= n;i++)cnt[rk[i] = c[i]]++;
for(int i = 1;i <= m;i++)cnt[i] += cnt[i-1];
for(int i = n;i >= 1;i--)sa[cnt[rk[i]]--] = i;
for(int w = 1;;w <<= 1,m = p,p = 0){
for(int i = n - w + 1;i <= n;i++)id[++p] = i;
for(int i = 1;i <= n;i++)
if(sa[i] > w)id[++p] = sa[i] - w;
memset(cnt,0,sizeof cnt);
for(int i = 1;i <= n;i++)cnt[rk[i]]++;
for(int i = 1;i <= m;i++)cnt[i] += cnt[i-1];
for(int i = n;i >= 1;i--)sa[cnt[rk[id[i]]]--] = id[i];
p = 0;
memcpy(ork,rk,sizeof rk);
for(int i = 1;i <= n;i++)rk[sa[i]] = cmp(sa[i-1],sa[i],w) ? p : ++p;
if(p == n)break;
}
for(int i = 1;i <= n;i++)printf("%d ",sa[i]);
printf("\n");
return 0;
}
3.3 height 数组
求
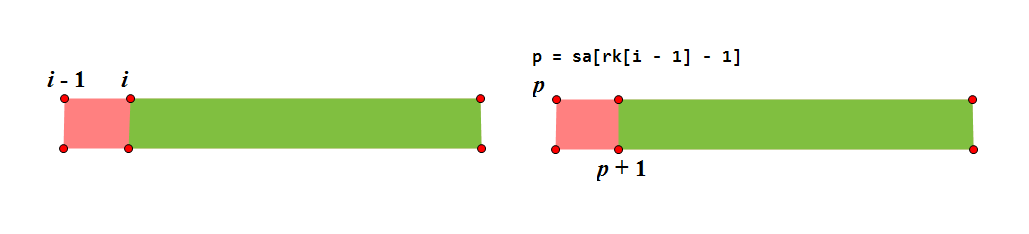
(图源为 Alex_wei)
- 证明,首先我们设
所以我们可以
for(int i = 1;i <= n;i++){
if(p)p--;
while(c[i + p] == c[sa[rk[i] - 1] + p])p++;
ht[rk[i]] = p;
}
3.4 应用
3.4.1 求两个后缀的 LCP
设
即
3.4.2 本质不同子串个数
首先总数有
我们考虑重复子串,对于从
得到本质不同子串个数为:
3.4.3 结合单调栈
我们观察
3.5 例题
复制一遍拼下,然后就是板子。
首先我们把
然后我们考虑每个
复杂度
III P3181 [HAOI2016] 找相同字符
答案就是一些
我们首先拼接一下,然后我们考虑后缀的贡献,只需要跑三遍 SA + 单调栈 即可(即 总的贡献 - 两字符串自己对自己的贡献)。
首先可以想到本质不同子串,但本题会加字符,如果我们加在字符串尾部的话,整个字符串的后缀都会改变,这是不好的,所以我们考虑反转倒序加入,这样字符串仅仅只是多了一个后缀,其他后缀都不变,考虑如何求不同子串,即求,当前后缀与所有后缀的最长前缀,我们只需维护一个
复杂度
V P5341 [TJOI2019] 甲苯先生和大中锋的字符串
题目即求字符串中出现次数 恰好 为
我们考虑如何找恰好出现
复杂度
首先有差分,然后转化为求
然后拼接到一起,考虑在
复杂度
VII P4094 [HEOI2016/TJOI2016] 字符串
首先我们知道,一个后缀 当然也可以用可持久化平衡树。
但是这是错的,原因是因为有右界,导致我们需要对每个答案取
: )
最后别忘记与
为啥暴力 SA 跑的比正解快 几十倍?
VIII P2178 [NOI2015] 品酒大会
好题,首先我们考虑 r 相似 的性质,可以发现 r 相似,即在
然后考虑算答案,第一问是好求的,在并查集合并时加上
复杂度
这个
IX CF822E Liar
好题,先拼接,题目中有一句话是 "按照原顺序合并",这启发我们可以枚举每个
观察数据范围看到
对于每一个
复杂度
神仙题,不过 ,首先
然后就牛了,我们钦定一个
不懂的可以画图,下图绿色部分即可用起点区间,棕色部分即可以结尾区间。
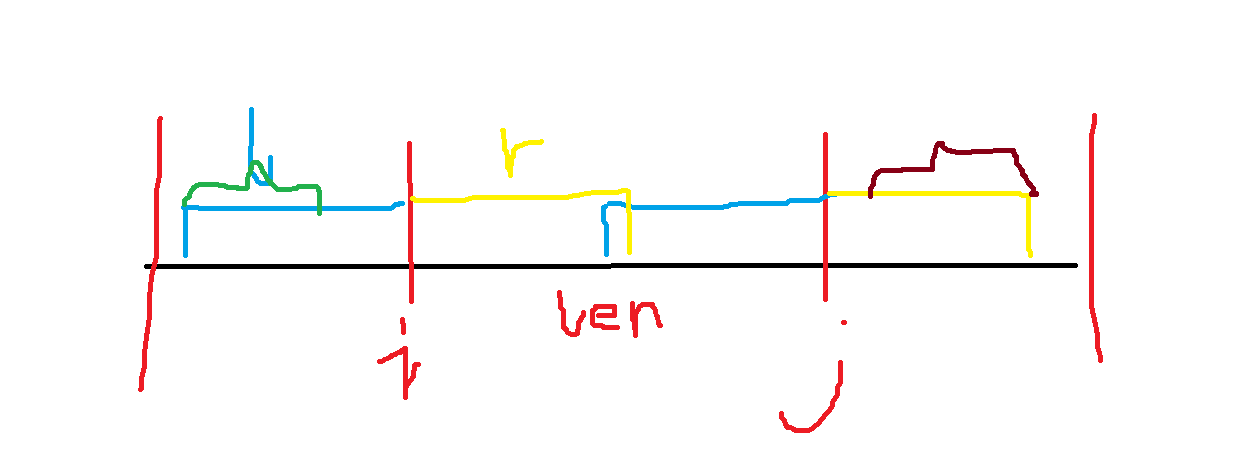
枚举
XI P4081 [USACO17DEC] Standing Out from the Herd P
神秘题。
首先拼接,注意这样多个串拼接要用 不同拼接符号,所有字串总答案即
然后我们按排名枚举,对于每个
复杂度


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 一文读懂知识蒸馏
· 终于写完轮子一部分:tcp代理 了,记录一下