长链剖分小记
相当于是树上的一个trick。
1. 算法简介
类似于重链剖分,我们根据子树深度最深的节点建立重儿子,我们可以得到以下性质。
- 所有链长之和为
- 任意一个节点的
- 任意叶子节点向上最多经过
- 证明:经过一个轻边,则跳到的长链长度一定大于当前长链的长度,则最坏情况为
- 证明:经过一个轻边,则跳到的长链长度一定大于当前长链的长度,则最坏情况为
2. 基础应用
2.1 树上 K 级祖先
长链剖分可以在线
我们首先倍增预处理出每个节点
对于每一个询问
int n,m,rt;
ui s;
struct edge{
int ver,nx;
}e[N<<1];
int hd[N],tot;
void link(int x,int y){e[++tot] = {y,hd[x]},hd[x] = tot;}
int f[N][22],g[N];
struct tree{
int dep[N],son[N],d[N],top[N];
vector<int>up[N],down[N];
void dfs1(int x){
for(int i = 1;i <= 20;i++)f[x][i] = f[f[x][i-1]][i-1];//倍增预处理
for(int i = hd[x];i;i = e[i].nx){
int y = e[i].ver;
dep[y] = d[y] = dep[x] + 1,f[y][0] = x;
dfs1(y);
d[x] = max(d[x],d[y]);
if(!son[x] || d[y] > d[son[x]])son[x] = y;
}
}//长剖
void dfs2(int x,int t){
top[x] = t;
if(x == t){
for(int i = 0,now = x;i <= d[x] - dep[x];i++)up[x].push_back(now),now = f[now][0];
for(int i = 0,now = x;i <= d[x] - dep[x];i++)down[x].push_back(now),now = son[now];
}//预处理链顶节点的子孙父亲
if(!son[x])return;
dfs2(son[x],t);
for(int i = hd[x];i;i = e[i].nx){
int y = e[i].ver;
if(y != son[x])dfs2(y,y);
}
}
void build(){dep[rt] = 1,dfs1(rt),dfs2(rt,rt);}
int ask(int x,int k){
if(!k)return x;
x = f[x][g[k]],k -= (1ll << g[k]);
k -= (dep[x] - dep[top[x]]),x = top[x];
return k > 0 ? up[x][k] : down[x][-k];
}
}t;
inline ui get(ui x) {
return x ^= x << 13, x ^= x >> 17, x ^= x << 5, s = x;
}
int main(){
n = read(),m = read(),s = read();g[0] = -1;
for(int i = 1;i <= n;i++)g[i] = g[i>>1] + 1;//highbit
for(int i = 1;i <= n;i++){
int x = read();
if(!x)rt = i;
else link(x,i);
}
t.build();
int las = 0;
ll ans = 0;
for(int i = 1;i <= m;i++){
int x = (get(s) ^ las) % n + 1;
int k = (get(s) ^ las) % t.dep[x];
las = t.ask(x,k);
ans ^= (ll)i * las;
}
printf("%lld\n",ans);
return ,0;
}
2.2 例题
I CF208E Blood Cousins
即求
首先第一步可以用上述方法
还有一种 dsu on tree
II P5384 [Cnoi2019] 雪松果树
上一题的加强版,只是将
首先我们第二步是
具体的:我们开一个栈,遍历它们的 dfs 序,对于每一个节点,我们只需要在栈内向前找
总复杂度
代码 甚至比上一题短 : (
3. 长链剖分优化dp
3.1 引入
重点!!
长链剖分可以优化树上 与深度相关 的 DP。一般有
可以将该 DP 优化到
以该题来引入,我们设
直接写是
3.2 细节与实现
有用 vector 与 指针 的两种方法,这里介绍指针方法,实现更简单(当然因为是指针可能会有玄学错误 : ( ),常数更小。
我们利用指针动态申请内存,对于一条长链,其共用一个大小为其长度的数组,这样只需要在继承重儿子时根据 DP 简单转移即可。
3.3 例题
长链剖分例题,指针实现代码。
(不会 01分数规划 的可以看我的笔记 - 01分数规划小记)
首先有分数规划,我们二分一个
我们考虑 DP,设
直接写是
复杂度
III P3899 [湖南集训] 更为厉害
首先对于每一个询问
我们写出式子,其实是二位偏序的类型,可以简单做到
,这里不做讨论。
我们考虑 DP,设
我们 离线询问,长链剖分优化,我们需要一个标记数组方便我们查询,类似上一题 差分。
复杂度
代码
IV P5904 [POI2014] HOT-Hotels 加强版
极好的题,让我的脑袋旋转。
首先我们考虑 DP,令
我们考虑如何优化,首先我们固定根为 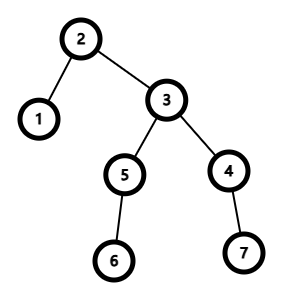
显然有
我们仅考虑只合并该子树
对这些式子长链剖分优化即可。
我们观察
复杂度
V P4292 [WC2010] 重建计划
没上一题难
其实就是 II 的加强版,分数规划,二分一个
有边权转点权的操作。
加一个标记数组,类似 树上差分,或者也可以暴写区间修改线段树 : (,然后我们建立个线段树,存 DP 中区间最大值,我们可以按照
复杂度
本题还有神神淀粉质做法,有兴趣可以了解: (
4. 基于长链剖分的贪心
一个经典结论:选一个节点能覆盖它到根的所有节点。选


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】