爬取汽车之家新闻首页数据
1.分析网页
如下图所知,该网页是一次性将所有数据全部返回
2.使用get请求也可以正常获取数据
1 import requests
2 res=requests.get('https://www.autohome.com.cn/news/1/#liststart').text
3 print(res)
输出:
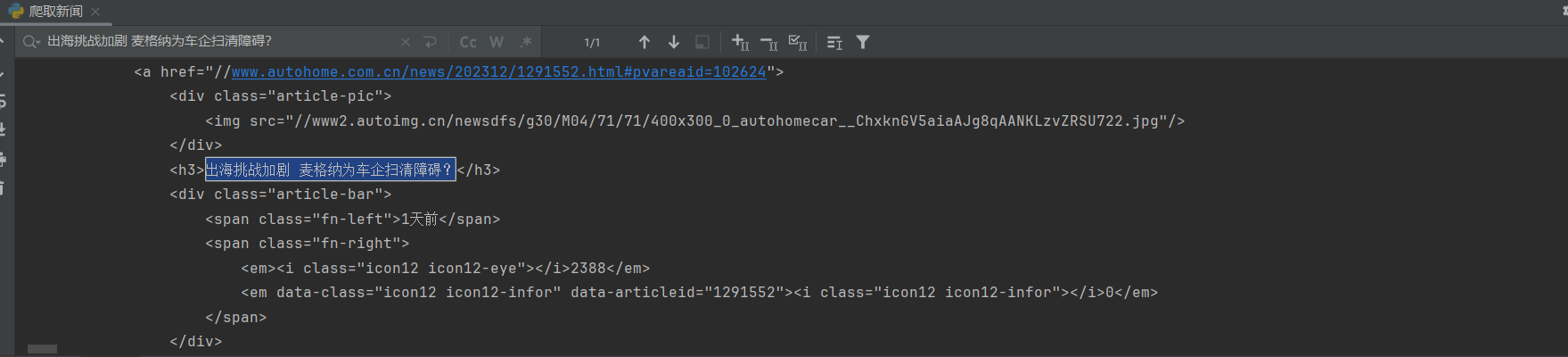
3.解析页面

4.解析数据

import bs4
import requests
from bs4 import BeautifulSoup
import pymysql
conn = pymysql.connect(
user='root',
password="123456",
host='127.0.0.1',
database='news'
)
cursor = conn.cursor()
for i in range(100):
res = requests.get('https://www.autohome.com.cn/news/%s/#liststart'%i)
soul = BeautifulSoup(res.text, 'lxml')
#查询所有ul标签,class=article的元素
ul_list = soul.find_all(name='ul', class_='article')
for ul in ul_list:
#查询出ul标签下所有li元素
li_list = ul.find_all(name='li')
for li in li_list:
# 查询li标签下的h3标签
title = li.find(name='h3')
# 因为有广告的存在,做一层判断过滤广告
if title:
title = title.text
desc = li.find(name='p').text
address = 'https:' + li.find(name='a').attrs.get('href')
img = li.find(name='img').attrs.get('src')
print(title)
# 存入数据库
cursor.execute('insert into news (title,img,address,`desc`) values (%s,%s,%s,%s)', args=[title, img, address, desc])
conn.commit()
爬取一百页后数据如下



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架