

Django-C002-深入模型,到底有多深
此文章完成度【100%】留着以后忘记的回顾。多写多练多思考,我会努力写出有意思的demo,如果知识点有错误、误导,欢迎大家在评论处写下你的感想或者纠错。
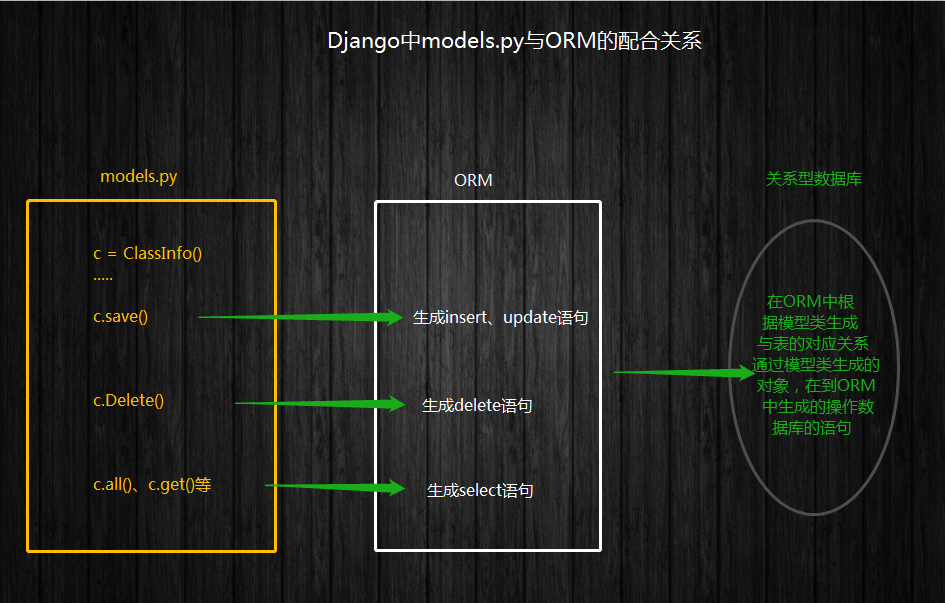
ORM介绍:对象关系映射(英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换 。从效果上说,它其实是创建了一个可在编程语言里使用的--“虚拟对象数据库”。
面向对象是从软件工程基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从数学理论发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生。
那么说说他的好处:
-
实现了数据模型与数据库的解耦,通过简单的配置就可以轻松更换数据库,而不需要修改代码
-
只需要面向对象编程,不需要面向数据库编写代码
-
在MVC中model中定义的类,通过ORM与关系型数据库中的表对应,对象的属性提现对象之间的关系,这种关系也被映射到数据表中
那么SQLite 并不是我喜欢的数据库,虽然自带,还是不感冒,所以下面就看看我们如何使用自己想用到的数据库之MySQL
重新创建一个项目,来用于接下来的练习
【Django version】: 2.1
【pymysql version】:0.9.3
【python version】: 3.7
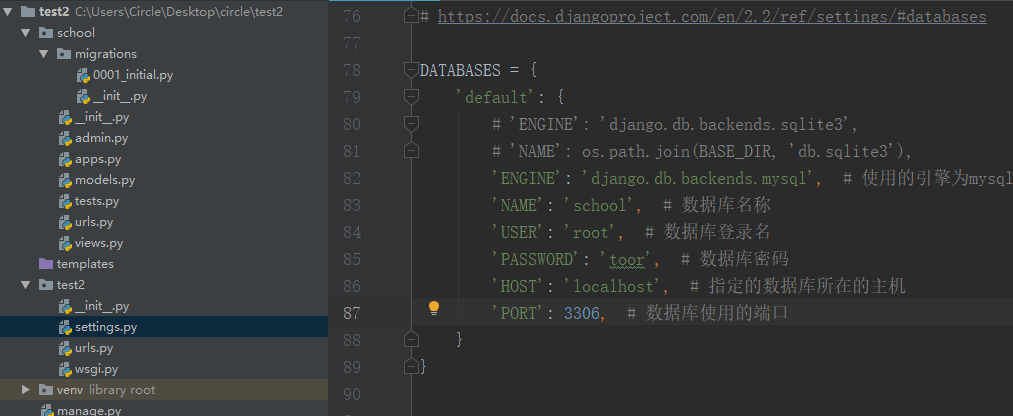
1.首先找到test2/settings.py 里的有关数据库设置的变量 变量名=DATABASES
# 你可以选择将原有指定的数据库注释掉,也可以直接删除
DATABASES = {
'default': {
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
'ENGINE': 'django.db.backends.mysql', # 使用的引擎为mysql
'NAME': 'school', # 数据库名称
'USER': 'root', # 数据库登录名
'PASSWORD': 'toor', # 数据库密码
'HOST': 'localhost', # 指定的数据库所在的主机
'PORT': 3306, # 数据库使用的端口
}
}
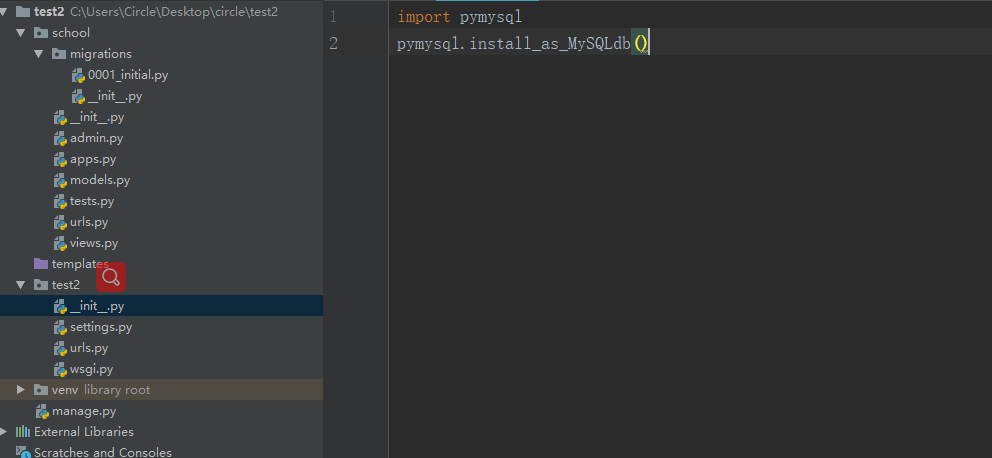
※踩了一晚上坑,终于pymysql可以成功导入,Django2.2.X的版本貌似不兼容pymysql,将版本降到2.1之后
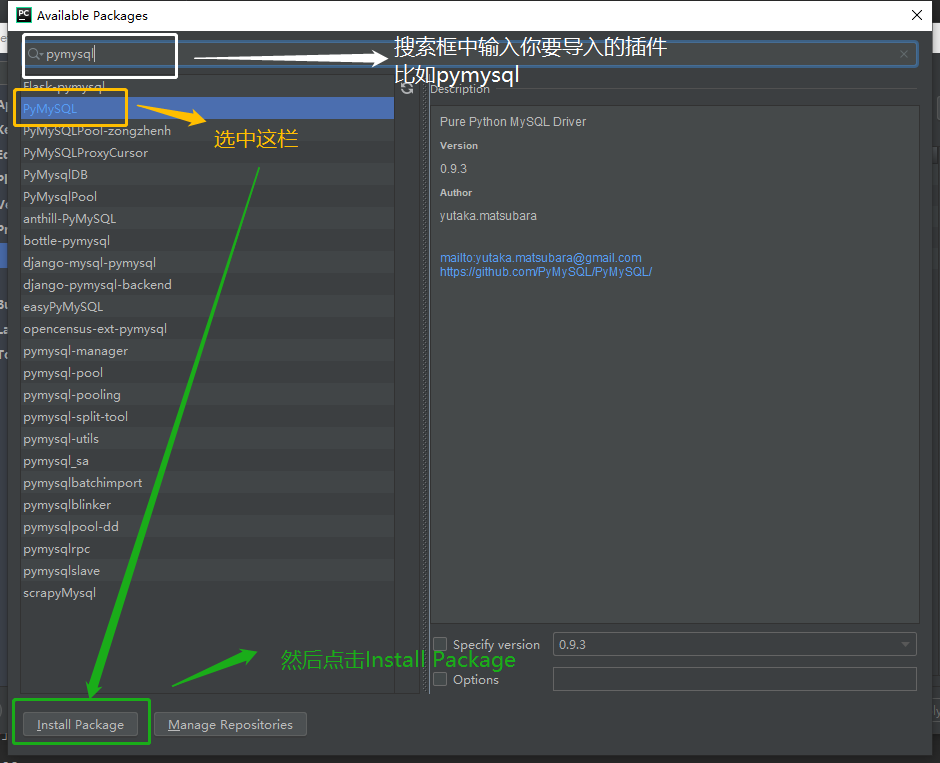
如果你的pycharm没有安装pymysql,你在导入的时候将会有红色下标,这时只需要在Pycharm中的Settings里面找到Project:你的项目名 里面添加即可

# 接下来运行,成功返回下面的页面,不成功你可以在评论中提出你的问题,咱们一起想解决办法
python manage.py runserver
通过之前的学习我们可以看出Django的M,是为了简化程序与数据库之间的操作,可以让我们用更少的代码实现更多的功能,这也是Python的编程风格,我们只需要通过类和对象,比如之前例子中的ClassInfo、StudentInfo这两个类和他们的对象,就能完成很多数据库的增、删、改、查。
我们还是需要两个类来进行演示:ClassInfo 【班级类】StudentInfo【学生类】
这里需要注意的是我们创建类的时候必须要继承models.Model类
首先我们找到models.py把这两个类创建出来
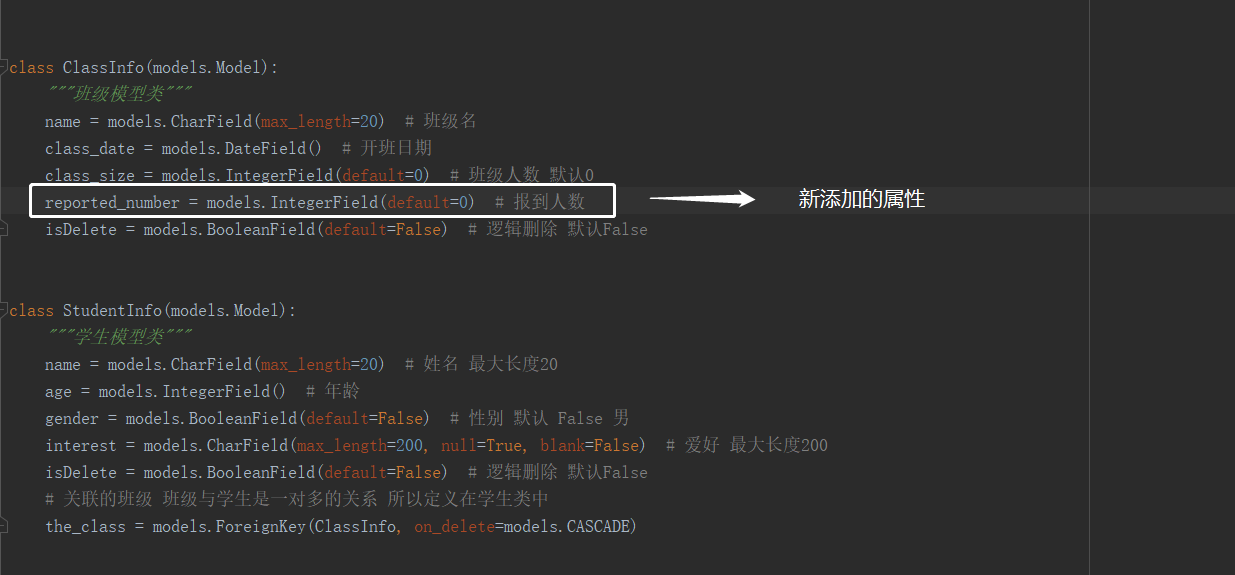
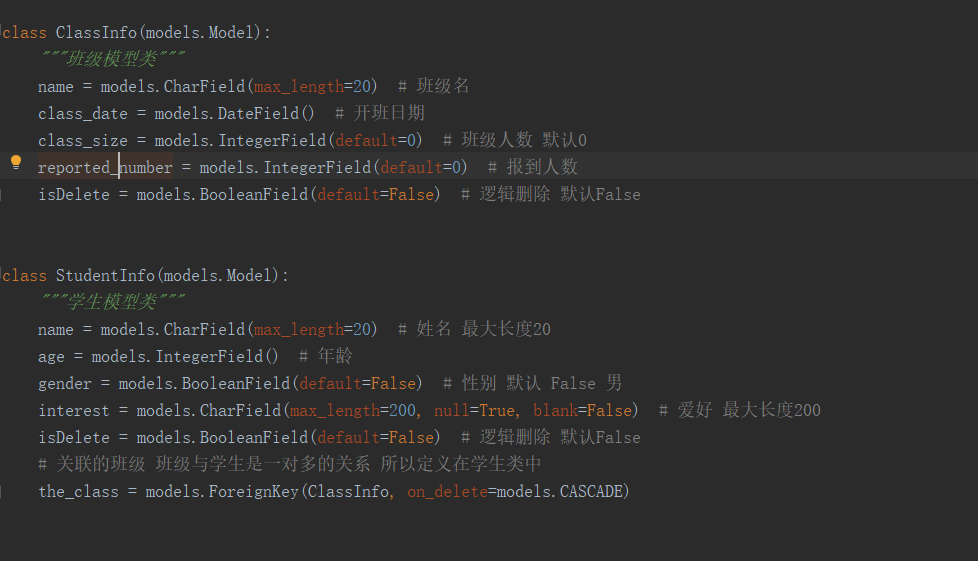
1 from django.db import models 2 3 4 class ClassInfo(models.Model): 5 """班级模型类""" 6 name = models.CharField(max_length=20) # 班级名 7 class_date = models.DateField() # 开班日期 8 class_size = models.IntegerField(default=0) # 班级人数 默认0 9 isDelete = models.BooleanField(default=False) # 逻辑删除 默认False 10 11 12 class StudentInfo(models.Model): 13 """学生模型类""" 14 name = models.CharField(max_length=20) # 姓名 最大长度20 15 age = models.IntegerField() # 年龄 16 gender = models.BooleanField(default=False) # 性别 默认 False 男 17 interest = models.CharField(max_length=200) # 爱好 最大长度200 18 isDelete = models.BooleanField(default=False) # 逻辑删除 默认False 19 # 关联的班级 班级与学生是一对多的关系 所以定义在学生类中 20 the_class = models.ForeignKey(ClassInfo, on_delete=models.CASCADE)
models.py里面的类已经创建完,之后需要生成迁移文件
python manage.py makemigrations

python manage.py migrate

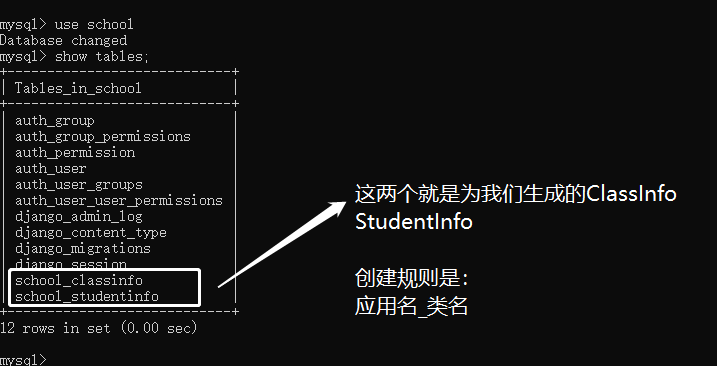
# 首先进入到这个表里 use school
# 接下来我们检查一下刚刚生成的数据表
show tables;
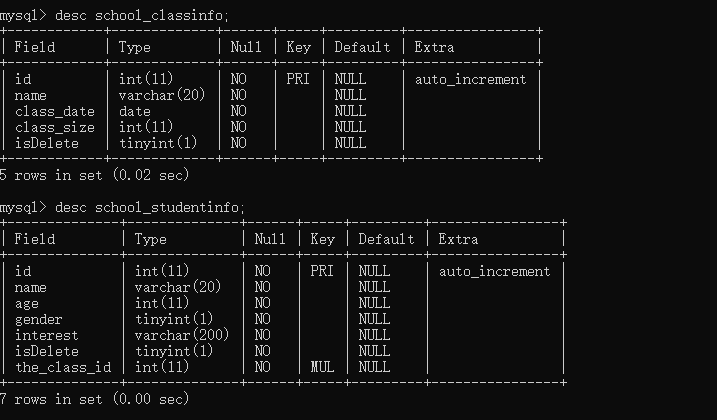
既然已经完成让我们看一下表结构:
desc school_classinfo;
desc school_studentinfo;
那么现在我们添加一些数据到数据库中
# 班级
insert into school_classinfo(name,class_date,class_size,isDelete) values ('python class','2019-6-21',17,0), ('java class','2019-6-21',1,0), ('c#','2019-6-21',1,0), ('php','2019-6-21',1,0);
# 学生 insert into school_studentinfo(name,age,gender,interest,isDelete,the_class_id) values ('蒙奇·D·路飞',19,0,'所有美食首先是肉、喜欢探险、感兴趣于新奇怪异的事物',0,1), ('罗罗诺亚·索隆',21,0,'睡觉、修炼、喝酒',0,1), ('娜美',20,1,'钱,橘子',0,1), ('乌索普',19,0,'发明各种东西、制造武器',0,1), ('山治',21,0,'下厨,抽烟,浪漫幻想',0,1), ('托尼托尼·乔巴',17,1,'医术',0,1), ('妮可·罗宾',30,1,'考古',0,1), ('弗兰奇',36,0,'汉堡包',0,1), ('布鲁克',90,0,'演奏,喝红茶,牛奶,说骷髅冷笑话',0,1), ('甚平',46,0,'不详',0,1), ('红发香克斯',46,0,'红发海贼团船长,原罗杰海贼团的实习员,拥有强大的霸王色霸气',0,1), ('乔拉可尔·米霍克',46,0,'世界第一大剑豪,红发好友,索隆的师傅',0,1), ('巴索罗米·熊',46,0,'原革命军干部,肉球果实能力者,已被贝加庞克改造成完全改造为“人间兵器”和平主义者PX-0,失去作为人的记忆',0,1), ('波雅·汉库克',32,1,'路飞',0,1), ('特拉法尔加·罗',26,0,'红心海贼团船长,手术果实能力者,极恶的世代之一',0,2), ('蒙奇·D·龙',42,0,'革命军总司令,被政府认定为世界最凶恶的罪犯',0,3), ('唐吉诃德·多弗朗明哥',36,0,'王位',0,4);


模型类数据已经都就位了,接下来我们去定义视图找到应用下的views.py
from django.shortcuts import render, redirect from school.models import ClassInfo from datetime import date # 查询所有班级并显示 def index(request): class_list = ClassInfo.objects.all() return render(request, 'school/index.html', {'class_list': class_list}) # 创建新的班级类 def create(request): c = ClassInfo() c.name = "海贼团 class" c.class_date = date(2019, 6, 21) c.class_size = 0 c.isDelete = 0 c.save() return redirect('/index.html') # 逻辑删除指定编号的图书 def delete(request, cid): c = ClassInfo().objects.get(id=cid) c.isDelete = 1 c.save() return redirect('/index.html')
为了让程序能找到我们的视图,配置URLconf就显得尤为重要了,那么显示在test2下的urls.py
# test2下的urls.py from django.contrib import admin from django.urls import path from django.conf.urls import url, include urlpatterns = [ path('admin/', admin.site.urls), url(r'^', include("school.urls")) ]
等价于
# test2下的urls.py from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include("school.urls")) ]
项目下的配置完,去应用下也就【school/urls【1】】配置具体对应的视图函数
【1】:这里的urls.py是我们自己创建的,用于配置我们自己的视图,可以更好的进行路径管理
from django.conf.urls import url from school import views urlpatterns = [ url(r'index$', views.index), url(r'create$', views.create), url(r'delete(\d+)$', views.delete), ]
M和V已经完成,现在就差一个T了,那么就去创建模板,在创建模板之前先去settings.py检查一下TEMPLATES里面是否已经配置好


下面就是模板index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>school</title> <style> a{text-decoration:none} </style> </head> <body> <h1 style="text-align: center">Circle & School</h1> <HR style="FILTER: alpha(opacity=100,finishopacity=0,style=2)" width="80%" color=#987cb9 SIZE=10> <ul style="list-style-type:none"> {% for class in class_list %} <li style="text-align: center"> {% if class.isDelete != 1 %} <a href="#">{{ class.name }}</a>------------<a href="/delete{{class.id}}">删除</a></li> {% endif %} </li> {% endfor %} </ul> <a href="/create" style="padding-left: 120px;font-size: 30px">创建</a> </body> </html>
这里开始测试一下,是否成功,那么我们将服务器运行起来
python manage.py runserver

测试创建

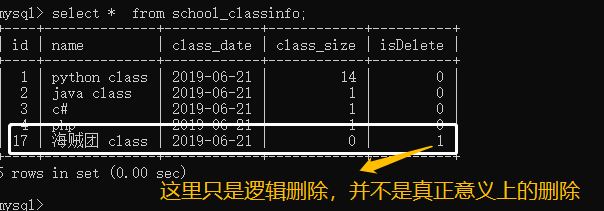
测试删除

这里只是逻辑上的删除,并没有在数据库真正的删除,有一个好处是避免我们误操作,也可以保存数据,供以后研究
定义属性
Django根据属性的类型确定以下信息:
-
当前选择的数据库使用字段的类型
-
渲染管理表单时使用的默认HTML控件
-
在管理站点最低限度的验证
django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列。
属性命名限制:
-
不能是python的保留关键字。
-
不允许使用连续的下划线,这是由django的查询方式决定的,在字段查询的说明会讲解为什么不能使用连续下划线
-
定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下
-
属性 = models.字段类型(选项)
-
字段类型:使用时需要导入django.db.models包
- AutoField:自动增长的IntegerField,默认不需要写,不写会自动创建属性名为id的自动增长属性
- BooleanField:布尔字段,值 True、False
- NullBooleanField:值为 Null、True、False
- CharField:字符串
- 参数max_length表示最大字符个数
- TextField:大文本字段 一般超过4000个字符使用
- IntegerField:整数
- DecimalField:十进制浮点数
- 参数max_digits表示总位数。
- 参数decimal_places表示小数的位数
- FloatField:浮点数
- DateField[auto_now=False, auto_now_add=False]):日期。
- 参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。
- 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。
- 参数auto_now_add和auto_now是相互排斥的,组合将会发生错误。
- TimeField:时间,参数同DateField。
- DateTimeField:日期时间,参数同DateField。
- FileField:上传文件字段。
- ImageField:继承于FileField,对上传的内容进行校验,确保是有效的图片。
选项
通过选项实现对字段的约束,选项如下:
- null:如果为True,表示允许为空,默认值是False。
- blank:如果为True,则该字段允许为空白,默认值是False。
- 对比:null是数据库范畴的概念,blank是表单验证范畴的。
- db_column:字段的名称,如果未指定,则使用属性的名称。
- db_index:若值为True, 则在表中会为此字段创建索引,默认值是False。
- default:默认值。
- primary_key:若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用。
- unique:如果为True, 这个字段在表中必须有唯一值,默认值是False。
字段查询
实现sql中where的功能,通过过滤器filter()、exclude()、get()
语法如下:
说明:属性名称和条件运算符间使用两个下划线,所以属性名不能包括多个下划线。
过滤器(属性名__条件运算符=值) # 这里的_是两个
条件运算符
1.exact : 判断相等
# 要求: 查询id为1的班级 c = ClassInfo.objects.filter(id__exact=1) # 等价于 c = ClassInfo.objects.filter(id=1)

这里ClassInfo.objects.filter(id__exact=1)返回的是一个Queryset,简单理解Queryset就像Python中的list
<QuerySet [<ClassInfo: ClassInfo object (1)>]>说明里面只有一个ClassInfo对象
我们可以用c[0]查看name属性
得到的就是id=1那个属性的名字为python class
想详细了解Queryset的话,后续会推出
2. contains: 判断是否包含
# 查询班级名是否包含'python'的班级 c = ClassInfo.objects.filter(name__contains=‘python’)

3.startwith、endswith: 查询以指定开头或结尾
# 查询班级以class结尾的班级 c = ClassInfo.objects.filter(name__endswith='class')

4.isnull:查询是否为null
# 查询班级名不为null的班级 c = ClassInfo.objects.filter(name__isnull=False)

5.in: 是否包含在范围内
# 查询id为1、3、17的班级 c = ClassInfo.objects.filter(id__in=[1,3,17])
# 这里会返回三个ClassInfo对象

# 上面查询的都是在数据库里有的数据,如果要是查询一个不存在的数据会怎样? c = ClassInfo.objects.filter(id__in=[1,3,5]) # 可以通过上面的数据看出,这里1,3都是包含在内的,但是5是不包含在内的

结果可以的看出,这里返回了除了id=5的所有相等的ClassInfo对象
6.比较查询---> gt、gte、lt、lte:大于、大于等于、小于、小于等于。
# id大于3的班级 c = ClassInfo.objects.filter(id__gt=3)

7.不等可以使用exclude()过滤器
# 查询不等id为3的班级 c = ClassInfo.objects.exclude(id=3)

可以看出上面没有返回id=3的ClassInfo对象
8.日期查询---->year、month、day、week_day、hour、minute、second
# 查询2019年开班的班级 c = ClassInfo.objects.filter(class_date__year=2019)

# 查询2019年6月20日以后开班的班级 from datetime import date c = ClassInfo.objects.filter(class_date__gt=date(2019,6,20))

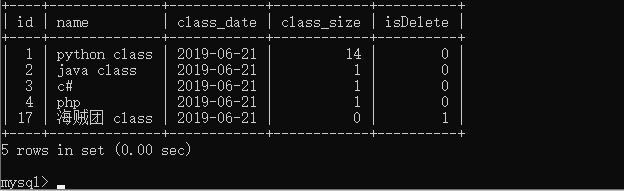
两个属性相比较怎么办?那么就来介绍一个F对象,但是没什么办法好举例,所以下面加一个属性
让我们来复习一下,之后需要用到生成迁移文件,和迁移
python manage.py makemigrations
python manage.py migrate

然后修改一id为一的班级那条数据库,将reported_number 改为14
UPDATE `school_classinfo` SET `name` = 'python class', `class_date` = '2019-06-21', `class_size` = 14, `reported_number` = 14, `isDelete` = 0 WHERE `school_classinfo`.`id` = 1;
数据准备完毕,我们来接着学习F对象
# 查询班级人数和报道人数相等的数据,也就是两个属性间的比较 from django.db.models import F # 想要使用F对象,必须要导包 c = ClassInfo.objects.filter(class_size=F('reported_number'))

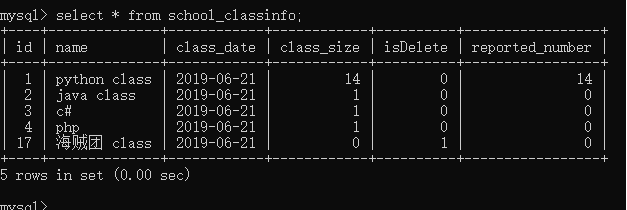
这里报道人数和班级人数相等的只有两个,分别是id=1、id=17的
Q对象
多个过滤器逐个调用表示逻辑与 [&] 关系,同SQL中的where里的and关键字
Q对象被义在django.db.models中。
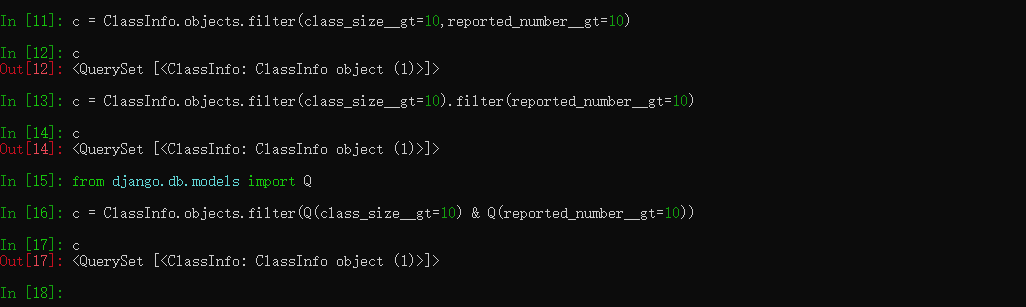
# 查询班级人数大于10,并且报道人数大于10的 c = ClassInfo.objects.filter(class_size__gt=10,reported_number__gt=10) 或者 c = ClassInfo.objects.filter(class_size__gt=10).filter(reported_number__gt=10) 或者 from django.db.models import Q c = ClassInfo.objects.filter(Q(class_size__gt=10) & Q(reported_number__gt=10))
如果需要实现逻辑或 [ | ] 的查询,需要使用Q()对象结合 | 运算符,同SQL语句中的where里的or关键字
# 查询班级人数大于10的,或者id 小于3 的班级 c = ClassInfo.objects.filter(Q(class_size__gt=10) | Q(id__lt=3))

这里返回了两个ClassInfo对象,是因为或只要满足一个条件就成立:
- id=1 的是都成立,既满足班级人数大于10.,也满足id小于3
- id=2 的id小于3这个成立,所以也会返回在Queryset中
Q也可以使用非~操作符
# 查询id不等于3的班级 c = ClassInfo.objects.filter(~Q(id=3))

这里除了id=3的班级都会返回到Queryset中
聚合函数:使用aggregate()过滤器调用聚合函数[Avg,Count,Max,Min,Sum]使用时候需要导入django.db.models
# 查询所有学生 from django.db.models import Sum c_dict = ClassInfo.objects.aggregate(Sum('class_size'))

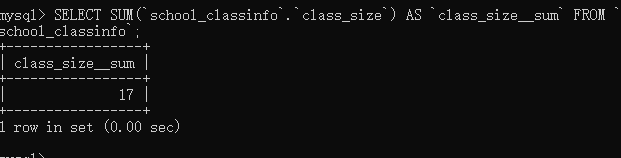
使用count时一般不使用aggregate()过滤器。
# 查询班级总数 class_count = ClassInfo.objects.count()

count()返回的是一个数字
Queryset:Queryset表示从数据库中获取的对象集合,在管理器上调用某些过滤器方法会返回Queryset,Queryset可以含有0个、1、或者多个过滤器,过滤器基于所给的参数有限制查询结果,从SQL的角度,Queryset和select语句等价,过滤器类似where、limit
返回多个值的过滤器:
- all(): 返回所有数据
- filter(): 返回满足条件的数据
- exclude():返回满足条件之外的数据
- order_by(): 对结果进行排序
返回单个值得过滤器:
- get():返回单个满足条件的对象
- 如果没找到会报DoesNotExist异常
- 如果多条被返回,会返回MultipleObjectsReturned异常
- count():返回当前查询结果的总条数
- aggregate(): 聚合,返回一个字典
判断某一个Queryset中是否有数据:
exists(): 判断查询集中是否有数据,如果有返回True 否则返回False
三大特性
- 惰性执行:创建Queryset不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用
- 缓存:使用同一个Queryset,第一次使用时会发生数据库的查询,然后把结果缓存下来,再次使用这个Queryset时,返回的是缓存数据
- 限制查询:可以对Queryset进行取下标或切片操作,等同于sql中的limit和offset子句。注意:不支持负数索引。
- 如果获取一个对象,直接使用[0],但是如果没有数据,[0]引发IndexError异常
模型类关系
关系型数据库的关系包括三种:
-
ForeignKey:一对多,将属性定义在多的中
-
ManyToManyField:多对多,将属性定义在任意类中
-
OneToOneField:一对一将属性定义在任意类中
-
可以维护递归的关联关系,使用self指定,应用在自关联
一对多关系:之前我们一直使用的ClassInfo类和StudentInfo类就是一对多的关系

多对多的关系:创建一个课程表类与学生,每个学生有多门课程,一门课程也会有很多学生,在创建多对多关系的时候,除了学生表和课程表之外会多创建一个中间表,分别都是他们的id
# 在models.py中创建课程表类 class Timetable(models.Model): """课程表模型类""" name = models.CharField(max_length=30) # 课程表名称 school_time = models.TimeField() # 课程时间 stu_table = models.ManyToManyField(StudentInfo) # 课程表和学生属于多对多的关系
生成迁移文件,并且迁移,
python manage.py makemigrations
python manage.py migrate
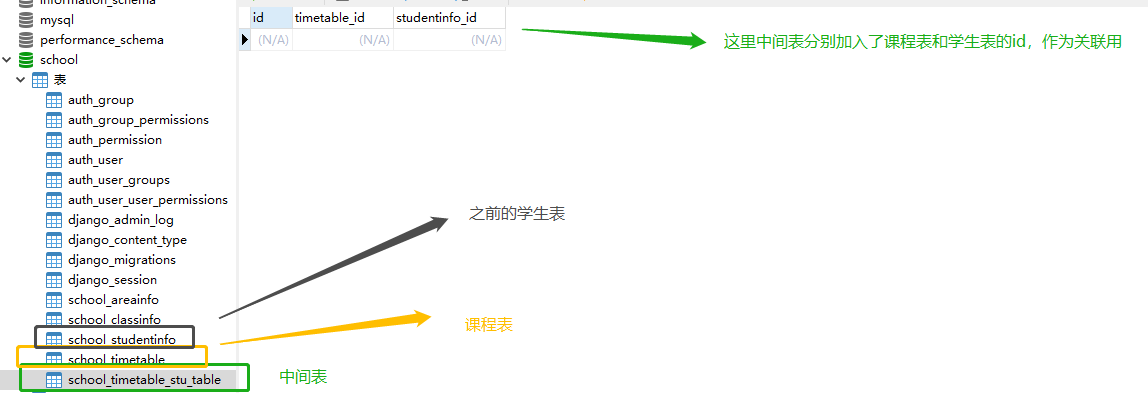
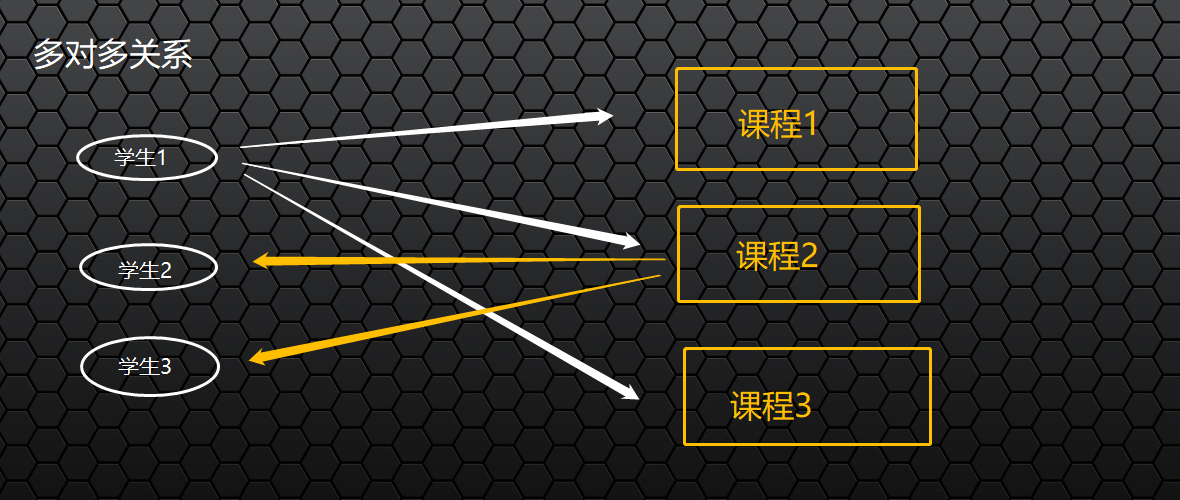
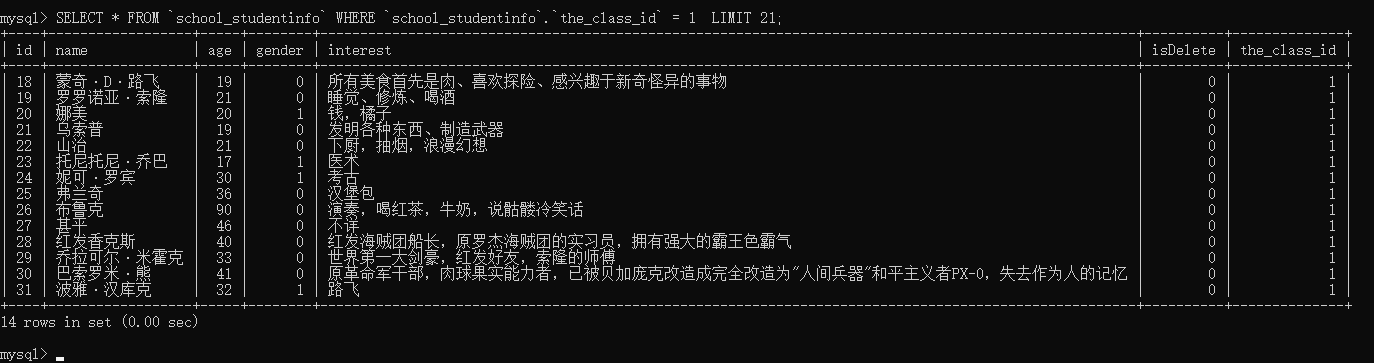
关联查询:Django也能实现类似SQL中的join查询
通过对象执行关联查询:在定义模型类的时候可以指定关联关系,最常用的就是一对多的关系
# 查询id为1的班级下的所有学生 # 1.首先来获取id为1的班级 c = ClassInfo.objects.get(id=1) s = c.studentinfo_set.all() # 这里需要由ClassInfo类.学生类名小写_set
# SQL语句
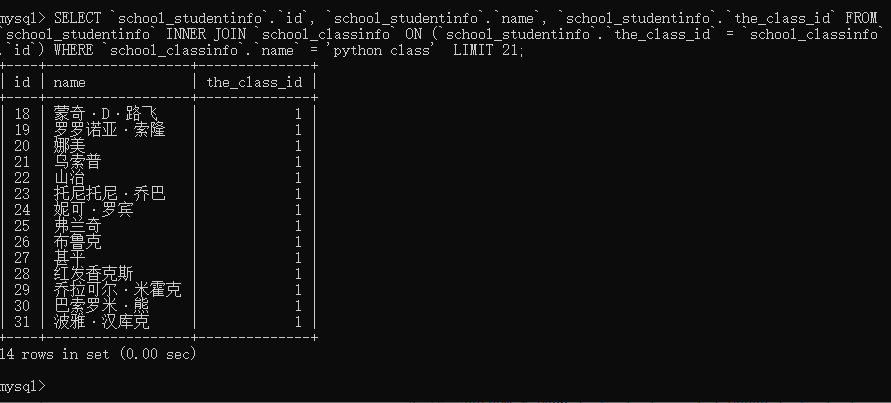
SELECT * FROM `school_studentinfo` WHERE `school_studentinfo`.`the_class_id` = 1 LIMIT 21;

通过SQL语句来来对比一下在Python manage.py shell 中的数据:
# 查询id=18的学生所在的班级 s = StudentInfo.objects.get(id=18) s.the_class
# SQL语句 SELECT * FROM `school_classinfo` WHERE `school_classinfo`.`id` = 1;


通过多模型类访问关联一模型类的语法
# 多对应的模型类对象.关联类属性_id s = StudentInfo.objects.get(id=18) s.the_class_id 对比 s.the_class

让我们测试一下所学的关联查询
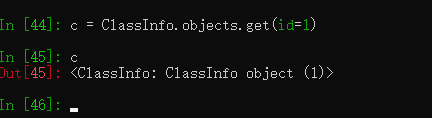
# 查询id为1的班级 c = ClassInfo.objects.get(id=1) # SELECT * FROM `school_classinfo` WHERE `school_classinfo`.`id` = 1;
# 获取C班级的所有学生 c.studentinfo_set.all() # SELECT * FROM `school_studentinfo` WHERE `school_studentinfo`.`the_class_id` = 1 LIMIT 21;

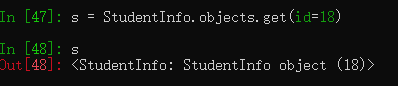
# 获取id = 18 的学生 s = StudentInfo.objects.get(id=18) # SELECT * FROM `school_studentinfo` WHERE `school_studentinfo`.`id` = 18;
# s这个学生所在的班级 s.the_class # SELECT * FROM `school_classinfo` WHERE `school_classinfo`.`id` = 1;

通过模型类执行关联查询
由多模型类条件查询一模型类数据语法:
关联模型类名小写__属性名__条件运算符 = 值
# 那么让我们做一个例子 # 查询班级,要求班级中的学生爱好里包含‘肉’的,返回所在的班级 class_list = ClassInfo.objects.filter(studentinfo__interest__contains = '肉')


# 多模型类查询,但是由一模型类条件查询 # 查询班级名为python class班下的所有学生 stu_list = StudentInfo.objects.filter(the_class__name = 'python class')

自关联:地区信息、分类信息、等等数据,表结构基本固定的,每个表的数据量不是特别庞大的,为了充分利用数据表的搭理那个数据存储功能,可以设计成一张表,内部的关系字段指向本表的主键,这就是自关联的表结构
# 第一步咱们开始准备模型类 models.py 下创建AreaInfo模型类
class AreaInfo(models.Model): """地区模型类""" name = models.CharField(max_length=50) # 地区名称 area_parent = models.ForeignKey('self', on_delete=models.CASCADE, null=True, blank=True) # 关系键
【扩展】:在设置外键时,需要通过on_delete选项指明主表删除数据时,对于外键引用表数据如何处理,在 django.db.models中包含了可选常量:
关联属性on_delete选项的取值
-
models.CASCADE此为默认值,级联删除,会删除关联数据models.ForeignKey('self', on_delete=models.CASCADE) -
models.PROTECT只要存在关联数据就不能删除models.ForeignKey('self', on_delete=models.PROTECT) -
models.SET_NULL删除数据后关联字段设置为NULL,仅在该字段允许为null时可用(null=True)
models.ForeignKey('self', on_delete=models.PROTECT,null=True)
生成迁移文件,并且迁移
python manage.py makemigrations # 生成迁移文件 python manage.py migrate # 迁移
接下来就是将省、市、区县的数据导入
我在windows的环境下,所以编码问题很是头疼这里是通过Navicat导入的数据:
数据在这里: 链接:https://pan.baidu.com/s/1SIPtBmQRoEnL_DYDYIB9qQ 提取码:r3px

M准备完成,开始准备V,定义视图views.py下的area
# 这里需要导入AreaInfo这个类 from school.models import AreaInfo # 创建地区信息的视图 def area(request): # 获取数据,由于数据太多咱们选择一个省的数据 230100=哈尔滨 area = AreaInfo.objects.get(id=230100) return render(request, 'school/area.html', {'area': area})
设置URLconf配置
1 from django.conf.urls import url 2 from school import views 3 urlpatterns = [ 4 url(r'index$', views.index), 5 url(r'create$', views.create), 6 url(r'delete(\d+)$', views.delete), 7 url(r'area$', views.area), # 新增的url 8 ]
Django框架MVT,MV已经准备完,现在来创建模板(T)area.html文件
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <h1 style="text-align: center">Circle & 地区</h1> <HR style="FILTER: alpha(opacity=100,finishopacity=0,style=2)" width="80%" color=#987cb9 SIZE=10> <div style="padding-left: 200px">当前市: {{ area.name }}</div> <HR style="FILTER: alpha(opacity=100,finishopacity=0,style=2)" width="80%" color=#987cb9 SIZE=10> <div style="padding-left: 200px">{{ area.name }}的省是: {{ area.area_parent.name }}</div> <HR style="FILTER: alpha(opacity=100,finishopacity=0,style=2)" width="80%" color=#987cb9 SIZE=10> <div style="padding-left: 200px"> 下级区 县 市: <ul> {% for a in area.areainfo_set.all %} <li> {{ a.name }} </li> {% endfor %} </ul> </div> </body> </html>
返回的结果是

模型类实例方法:
- str(): 将对象转换成字符串
- save(): 将对象保存到数据表中
- delete(): 将对象从数据表中删除
模型类的属性
objects
模型当中最重要的属性是 Manager。它是Django模型和数据库查询操作之间的接口,并且它被用作从数据库 当中查询,如果没有指定自定义的 Manager 默认名称是 objects。Manager只能通过模型类来访问,不能通 过模型实例来访问。
管理器(Manager):是向Django模型提供数据库查询操作的接口。Django应用程序中的每个模型至少有一个管理器。
管理器命名(Manager):默认Django会为每一个模型类添加一个命名为objects的管理器 ,如果你想用objects作为字段名,或者你想用除了objects以外的名字为这个管理器命名,你可以根据模型类来重命名,将重命名的管理器给定一个类,在这个模型类上定义一个models.Manager()类型的类属性。例如:
from django.db import models class ClassInfo(models.Model): class_manager = models.Manager()
使用上面的例子,ClassInfo.objects将会产生一个AttributeError的异常,但是ClassInfo.class_manager.all() 将会提供ClassInfo对象的列表
自定义管理器:你可以用一个自定义管理器在模型中扩展这个基本的管理器,和在模型中实例化自定义管理器。
自定义管理器有两个好处,也许正是你想要修改管理器的两个原因
1.修改管理器返回的初始Queryset。
2.添加额外的管理器方法
之前我们使用的all()函数都是直接返回Queryset,这里我来学习一下修改管理器返回的初始Queryset
# 首先我们来定义一个管理器 class ClassInfoManager(models.Manager): """班级管理器""" # 重写all()方法 def all(self): # 调用的父类的all()方法,默认获取所有的班级信息 class_model = super().all() # 修改查询的结果,将isDelete 为 True 的不返回 # 返回结果 return class_model.filter(isDelete=False) class ClassInfo(models.Model): """班级模型类""" name = models.CharField(max_length=20) # 班级名 class_date = models.DateField() # 开班日期 class_size = models.IntegerField(default=0) # 班级人数 默认0 reported_number = models.IntegerField(default=0) # 报到人数 isDelete = models.BooleanField(default=False) # 逻辑删除 默认False objects = ClassInfoManager() # 将自定义的管理器赋值给objects管理器对象

第二个好处就是添加额外的管理器方法,还记得之前在网站点击创建就会添加一个班级,这里我们可以将它把创建方法封装到models的管理器中
管理器:models.py
# 首先我们来定义一个管理器 class ClassInfoManager(models.Manager): """班级管理器""" # 重写all()方法 def all(self): # 调用的父类的all()方法,默认获取所有的班级信息 class_model = super().all() # 修改查询的结果,将isDelete 为 True 的不返回 # 返回结果 return class_model.filter(isDelete=False) # 创建一个新的方法:添加班级 def create_class(self, name, class_date, class_size=0, reported=0): # 创建对象 c = self.model() # 等价于 c = ClassInfo() # print(type(c)) # 测试self.model()的返回值类型 c.name = name c.class_date = class_date c.class_size = class_size c.reported_number = reported c.isDelete = False c.save() return c
视图:views.py
# 创建新的班级类 def create(request): """ c = ClassInfo() c.name = "海贼团 class" c.class_date = date(2019, 6, 21) c.class_size = 0 c.isDelete = 0 c.save() return redirect('/index') """ ClassInfo.objects.create_class("web class", '2019-06-23') return redirect('/index')
元选项(Meta options) : 设置元信息,需要在模型类中定义一个Meta的内部类
这货到底有啥用,简单的说明一下。当我们定义完模型类的时候,生成的数据库表名都是 应用名_模型类名(例如:school_classinfo),但是我还不想让他在数据库生成这种名字,我们就可以用Meta当中的一个选项,就是db_table,设置数据库的表名,具体如何操作呢?我们就动手写一下
# 这里我们就用课程表模型类演示 class Timetable(models.Model): """课程表模型类""" name = models.CharField(max_length=30) # 课程表名称 school_time = models.TimeField() # 课程时间 stu_table = models.ManyToManyField(StudentInfo) # 课程表和学生属于多对多的关系 class Meta: db_table = 'timetable' # 设置表名为timetable

其实仔细想想,这也是与应用名之间的解耦,还有很多的元选项之后有时间,可以做一个专辑
-To Be Continued-
