MySQL数据库常见面试题
SQL基础
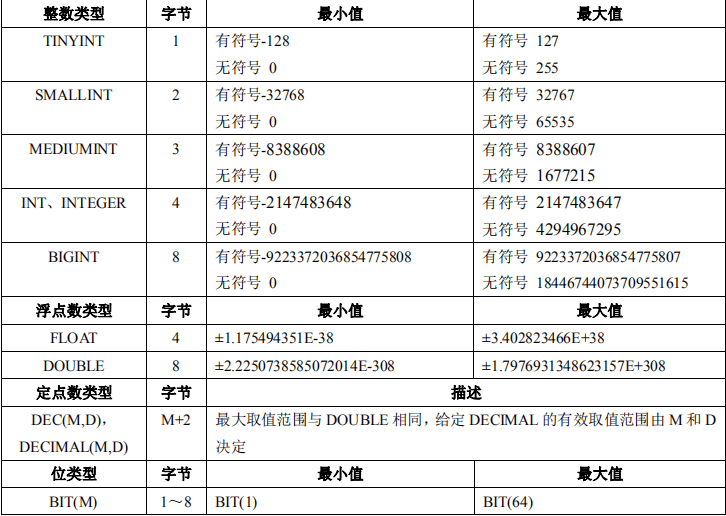
1.MySQL的数据类型
2.MySQL的SQL语句分类
DDL(Data Definition Language)语句:数据定义语言,这些语句定义了不同的数据段、表、列、索引等数据库对象的定义。常用的语句关键字主要包括create、drop、alter等。
DML(Data Manipulation Language)语句:数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括insert、delete、update和select等。
DCL(Data Control Language)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括grant、revoke等。
数据库范式
第一范式(1NF)是指在关系模型中,数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
第二范式(2NF)是在1NF的基础上,要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性
第三范式(3NF)在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
巴斯-科德范式(BCNF)在3NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)
白话区:
第一范式:每个表应该有唯一标识每一行的主键。
第二范式:在复合主键的情况下,非主键部分不应该依赖于部分主键。
第三范式:非主键之间不应该有依赖关系。
BC范式:排除了任何属性(不光是非主属性,2NF和3NF所限制的都是非主属性)对候选键的传递依赖与部分依赖。
MyISAM与Innodb区别
(1)MyISAM不支持事务,Innodb支持事务
(2)Myisam不支持外键,innodb支持外键
(3)myisam支持表级锁,innodb支持行级锁
(4)innodb 进行select count(*) from tablename时,需要对表进行一次遍历;myisam进行select count(*) from tablename时
(5)myisam删除表时,先将表drop,然后新建一个表;innodb则是将表中数据一条一条的删除
(6)对于包含auto-increment字段的索引,innodb只包含auto-increment字段;而myisam则可以和其他字段一起建立联合索引
(7)myisam搜索引擎查找要比innodb搜索引擎快
(8)innodb中索引没有fulltext类型,而myisam中有fulltext类型
视图
视图(View)是一种虚拟存在的表,对于使用视图的用户来说基本上是透明的。视图并
不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时
动态生成的
简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,
对用户来说已经是过滤好的复合条件的结果集。
安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能
限制到某个行某个列,但是通过视图就可以简单的实现。
数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加
列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问
者的影响
事务的特性及隔离级别:
1.事务特性--ACID
Atomicity(原子性):要么全做,要么不做,不能只做一半(银行转账)
Consistency(约束性):事务的前后,约束都能满足
Isolation(依赖性):事务之间是独立的,互不影响的
Durability(持久性):事务执行之后,事物的结果可以持久保存
2.事务隔离级别:
read uncommitted:可以读到未提交的事务结果
read committed:只能读已提交事务的结果
repeatable reads:可以读到开启事务时的值
serializable:两个事务同时发生,必定是有先后的
索引
1.什么是索引
索引(Index)是帮助MySQL高效获取数据的数据结构。
2.索引的种类
从逻辑角度
1、主键索引:主键是一种唯一性索引,但它必须指定为“PRIMARY KEY”
2、唯一索引:不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查。
3、组合索引
从物理存储角度
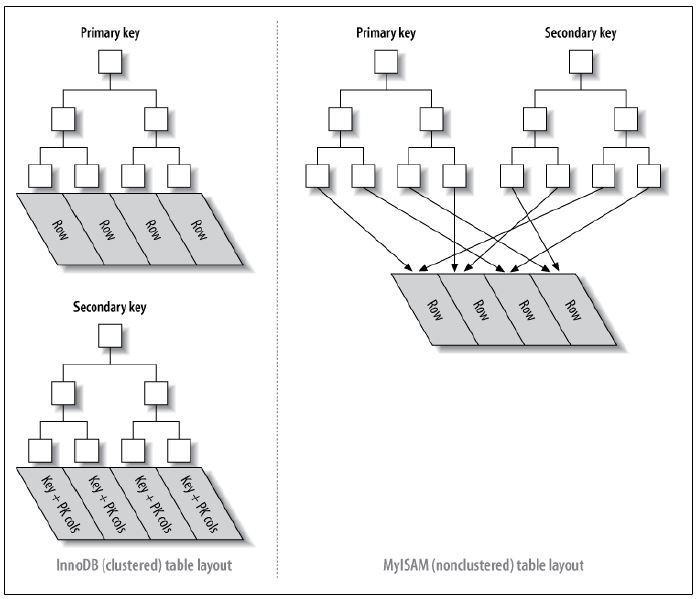
1、聚簇索引(clustered index):聚簇索引的叶子节点就是数据节点
2、非聚簇索引(non-clustered index):非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
从数据结构角度
1、B+树索引
2、hash索引
3、FULLTEXT索引(InnoDB引擎5.7以后支持):
3.索引的设计原则

4.索引存在但是不使用索引
(1)如果MySQL估计使用索引比全表扫描更慢,则不使用索引。例如如果列key_part1均匀分布在1~100之间,下列查询使用索引就不是很好
SELECT * FROM table_name where key_part1 > 1 and key_part1 < 90;
(2)如果使用 MEMORY/HEAP 表并且 where 条件中不使用“=”进行索引列,那么不会用到索引。heap 表只有在“=”的条件下才会使用索引。
(3)用 or 分割开的条件,如果 or 前的条件中的列有索引,而后面的列中没有索引,那么涉及到的索引都不会被用到,例如
(4)对于符合索引如果不是第一列,在查询中也不会被MySQL用到
(5)如果like是以%开始,那么索引不会被MySQL使用
(6)如果列类型是字符串,那么一定记得在 where 条件中把字符常量值用引号引起来,否则的话即便这个列上有索引,MySQL 也不会用到的,因为,MySQL 默认把输入的常量值进行转换以后才进行检索。
5.B+Tree索引
B+树:B+树是为磁盘或其他直接存取辅助设备设计的一种平衡查找树。在B+树中,所有记录结点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。
数据库中B+树索引分为聚集索引和辅助索引,两者内部都是B+树,即高度平衡的,叶子节点存放着所有的数据。聚集索引与辅助索引不同的是,叶子节点存放的是否是一整行的信息。
聚集索引
聚集索引:聚集索引就是按照每张表的主键构造的一棵B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。
辅助索引
慢查询
1.为什么查询速度会慢
查询性能低下最基本的原因是访问的数据太多。某些查询可能不可避免的需要筛选大量数据,但这并不常见。大部分性能低下的查询都可以减少访问的数据量的方式进行优化。对于低效的查询,我们发现通过下面两个步骤来分析总是很有效:
(1)确认应用程序是否在检索大量超过需要的数据。这通常意味着访问了太多的行,但有时候也可能是访间了太多的列。
(2)确认MYSQL服务器层是否在分析大量超过需要的数据行。
2.慢查询基础
(1)是否向数据库请求了不需要的数据
查询不需要的记录
一个常见的错误是常常会误以为MYSQL会只返回需要的数据,实际上MYSQL却
是先返回全部结果集再进行计算。我们经常会看到一些了解其他数据库系统的人会
设计出这类应用程序。这些开发者习惯使用这样的技术,先使用SELECT语句查询大
量的结果,然后获取前面的N行后关闭结果集(例如在新闻网站中取出100条记录,
但是只是在页面上显示前面10条)。他们认为MYSQL会执行查询,并只返回他们
需要的10条数据,然后停止查询。实际情况是MYSQL会查询出全部的结果集,客
户端的应用程序会接收全部的结果集数据,然后抛弃其中大部分数据。最简单有效
的解决方法就是在这样的查询后面加上LIMIT。
多表关联时返回全部列
如果你想查询所有在电影Academy Dinosaur中出现的演员,千万不要按下面的写法
编写查询:
ysql> select FRO sakila. Actor MER torn sakila. fin actor usimg(actor. id -2 INBROR, 5azla to. Mt -) WERE sakila. Film. Title - 'acadery Dinosaur'; 这将返回这三个表的全部数据列。正确的方式应该是像下面这样只取需要的列: my5ql> SELECT sakila. Actor. " fro sakila. Actor. . ;
总是取出全部列
每次看到SELECT *的时候都需要用怀疑的眼光审视,是不是真的需要返回全部的
列?很可能不是必需的。取出全部列,会让优化器无法完成索引覆盖扫描这类优化,
还会为服务器带来额外的I/O、内存和CPU的消耗。因此,一些DBA是严格禁止
SELECT *的写法的,这样做有时候还能避免某些列被修改带来的问题。
当然,查询返回超过需要的数据也不总是坏事。在我们研究过的许多案例中,人们
会告诉我们说这种有点浪费数据库资源的方式可以简化开发,因为能提高相同代码
片段的复用性,如果清楚这样做的性能影响,那么这种做法也是值得考虑的。如果
应用程序使用了某种缓存机制,或者有其他考虑,获取超过需要的数据也可能有其
好处,但不要忘记这样做的代价是什么。获取并缓存所有的列的查询,相比多个独
立的只获取部分列的查询可能就更有好处。
重复查询相同的数据
如果你不太小心,很容易出现这样的错误——不断地重复执行相同的查询,然后每
次都返回完全相同的数据。例如,在用户评论的地方需要查询用户头像的URL,那
么用户多次评论的时候,可能就会反复查询这个数据。比较好的方案是,当初次查
的的时候将这个数据缓存起来,需要的时候从缓存中取出,这样性能显然会更好
(2)MySQL是否在扫描额外的记录
响应时间
扫描行数
返回的行数
3.查看慢查询日志
慢查询日志记录了包含所有执行时间超过参数 long_query_time(单位:秒)所设置值的 SQL
语句的日志。获得表锁定的时间不算作执行时间。
(1) 文件位置和格式
当用--log-slow-queries[=file_name]选项启动 mysqld(MySQL 服务器)时,慢查询日志开始被
记录。和前面几种日志一样,如果没有给定 file_name 的值,日志将写入参数 DATADIR(数
据目录)指定的路径下,默认文件名是 host_name-slow.log。
(2) 日志的读取
和错误日志、查询日志一样,慢查询日志记录的格式也是纯文本,可以被直接读取。下例中
演示了慢查询日志的设置和读取过程。
(2.1)首先查询一下 long_query_time 的值。
mysql> show variables like 'long%'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | long_query_time | 10 | +-----------------+-------+ 1 row in set (0.00 sec)
(2.2)为了方便测试,将修改慢查询时间为 2 秒。
mysql> set long_query_time=2; Query OK, 0 rows affected (0.02 sec)
(2.3)依次执行下面两个查询语句。
第一个查询因为查询时间低于 2 秒而不会出现在慢查询日志中:
mysql> select count(1) from emp; +----------+ | count(1) | +----------+ | 131075 | +----------+ 1 row in set (0.00 sec)
第二个查询因为查询时间大于 2 秒而应该出现在慢查询日志中:
mysql> select count(1) from emp t1,dept t2 where t1.id=t2.id; 322 +----------+ | count(1) | +----------+ | 33555200 | +----------+ 1 row in set (11.31 sec)
(2.4)查看慢查询日志。
[root@localhost mysql]# more localhost-slow.log /usr/sbin/mysqld, Version: 5.0.41-community-log (MySQL Community Edition (GPL)). started with: Tcp port: 3306 Unix socket: /var/lib/mysql/mysql.sock Time Id Command Argument # Time: 070810 23:43:55 # User@Host: root[root] @ localhost [] # Query_time: 297 Lock_time: 0 Rows_sent: 0 Rows_examined: 26214 use test; # Query_time: 11 Lock_time: 0 Rows_sent: 1 Rows_examined: 512 select count(1) from emp t1,dept t2 where t1.id=t2.id;
从上面日志中,可以发现查询时间超过 2 秒的 SQL,而小于 2 秒的则没有出现在此日志中。
如果慢查询日志中记录内容很多,可以使用 mysqldumpslow 工具(MySQL 客户端安装自带)
来对慢查询日志进行分类汇总。下例中对日志文件 bj37-slow.log 进行了分类汇总,只显示汇
总后摘要结果:
[zzx@bj37 data]$ mysqldumpslow bj37-slow.log [root@localhost mysql]# mysqldumpslow localhost-slow.log Reading mysql slow query log from localhost-slow.log Count: 1 Time=297.00s (297s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost select count(N) from emp t1,emp t2 where t1.id<>t2.id Count: 2 Time=11.00s (22s) Lock=0.00s (0s) Rows=1.0 (2), root[root]@localhost select count(N) from emp t1,dept t2 where t1.id=t2.id Count: 1 Time=9.00s (9s) Lock=0.00s (0s) Rows=0.0 (0), root[root]@localhost select count(N) from emp t1,emp t2 where t1.id=t2.id Count: 2 Time=3.00s (6s) Lock=0.00s (0s) Rows=1.0 (2), root[root]@localhost select count(N) from emp t1,dept t2 where t1.id=t2.id and t1.id=N
对于 SQL 文本完全一致,只是变量不同的语句,mysqldumpslow 将会自动视为同一个语句进
行统计,变量值用 N 来代替。这个统计结果将大大增加用户阅读慢查询日志的效率,并迅
速定位系统的 SQL 瓶颈。
注意:慢查询日志对于我们发现应用中有性能问题的 SQL 很有帮助,建议正常情况下,打开此
日志并经常查看分析。
(3) 其他选项
在 MySQL 5.1 中,通过--log-slow-admin-statements 服务器选项,可以请求将慢管理语句,例
如 OPTIMIZE TABLE、ANALYZE TABLE 和 ALTER TABLE 写入慢查询日志
MySQL优化
1.优化SQL语句
(1)通过show status命令了解各种SQL的执行效率
例如show status like 'Com_%'
Com_select:执行select操作的次数,一次查询只累加1.
Com_insert:执行insert操作的次数,对于批量插入的INSERT操作,只累加一次。
Com_updated:执行UPDATE操作的次数。
Com_deleted:执行delle操作的次数。
Innodb_rows_read:select查询返回的行数.
Innodb_rows_inserted:执行INSERT操作插入的行数。
Innodb_rows_updated:执行UPDATE操作更新的行数
Innodb_rows_deleted:执行DELETE操作删除的行数。
Connections::图连接MYSQL服务器的次数。
Uptime:服务器工作时间。
Slow_queries:慢查询的次数。
(2)定位性效率较低的SQL语句
通过慢查询日志定位那些执行效率较低的sql语句,用--log-slow-queries[=file_name]选
项启动时,mysqld写一个包含所有执行时间超过long_query_time秒的SQL语句的日志
文件。
慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候慢查
询日志并不能定位问题,可以使用show processlist命令查看当前mysql在进行的线程,
包括线程的状态、是否锁表等,可以实时地查看SOL的执行情况,同时对一些锁表操
作进行优化。
(3)通过Explain分析低效SQL的执行计划
Explain解析的每一列含义:
select_type:表示select的类型,常见的取值有simple(简单表,即不使用表连接
或者子查询)、PRIMARV(主查询,即外层的查询)、UNION(UNION中的第二个或
中的第二个或者后面的查询语句)、SUBQUERY (子查询中的第一个SHLECT)等。
table:输出结果集的表。
type:表示表的连接类型,性能由好到差的连接类型为
system(表中仅有一行,即常量表)、
const(单表中最多有一个匹配行,例如primary key或者unique index).
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)、
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)、
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)、
index_merge(索引合并优化)、
unique_subquery (in的后面是一个查询主键字段的子查询)、
index_subquery(与unique_Subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)、
range(单表中的范围查询)、
index(对于前面的每一行,都通过查询索引来得到数据)、
all(对于前面的每一行都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
extra:执行情况的说明和描述。
(4)确定问题并采取相应的优化措施
2.MySQL如何使用索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号