用MATLAB结合四种方法搜寻罗马尼亚度假问题
选修了cs的AI课,开始有点不适应,只能用matlab硬着头皮上了,不过matlab代码全网仅此一份,倒有点小自豪。
一、练习题目
分别用宽度优先、深度优先、贪婪算法和 A*算法求解“罗马利亚度假问题”。具体地图我这里不给出了,有兴趣的可以去搜索。即找到从初始地点 Arad到 目的地点 Bucharest 的一条路径。
要求:分别用文件存储地图和启发函数表,用生成节点数比较以上四种算法在同一问题求解时的效率,列表给出结果。
附:罗马尼亚度假问题图(图1.1)
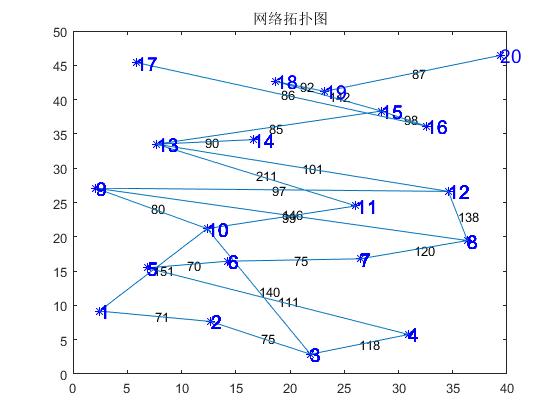
图1.1 罗马尼亚度假问题
1.2 题目分析
本题要求分别用宽度优先、深度优先、贪婪算法和 A*算法求解“罗马利亚度假问题”。罗马尼亚度假问题本质上属于“图类”问题,该地图上共有20个地点,要求从Arad出发,到达Bucharest,从图中搜索到达路径,并比较四种方法的优缺点。因此主要的数据结构可以采用图存储的方法,搜索方法题目已经给出。
二、数据结构
2.1 图结构
图:由有穷、非空点集和边集合组成,简写成G(V,E),其中,G表示一个图,V表示图中的顶点,E表示图中的边。在本题,顶点为20个罗马尼亚城市,边则为相邻城市之间的距离。边之间有方向,图为有向图,无方向的图为无向图。本题所用的图为无向图。
尽管二维数组比较占用内存,但是由于MATLAB对矩阵运算非常方便,运算速度也很快,我采用二维数组的方法存储邻接矩阵。对20个地点编号1-20,其中Arad为3号地点,对边采用数值的方法,例如3号到4号距离为75,则令矩阵中点(3,4)的值为75。并令自身距离为0,不相邻的点之间也设为0。
2.2 队列结构
队列(Queue):是只允许在一端进行插入操作,在另一端进行删除操作的线性表。队列也是一种特殊的线性表,是一种先进先出的线性表。允许插入的一端称为表尾,允许删除的一端称为表头。我们将在广度优先搜索中使用到这个结构存储已搜索过的节点。其结构如图2.2所示。
![]()
图2.2 队列结构图
2.3 栈结构
栈(Stack):也是一种线性存储结构,栈中的数据元素遵守“先进后出”(First In Last Out)的原则,简称FILO结构。只能在栈顶进行插入和删除操作。我们将在深度优先搜索中使用到这个结构存储已搜索过的节点。其结构如图2.3所示。
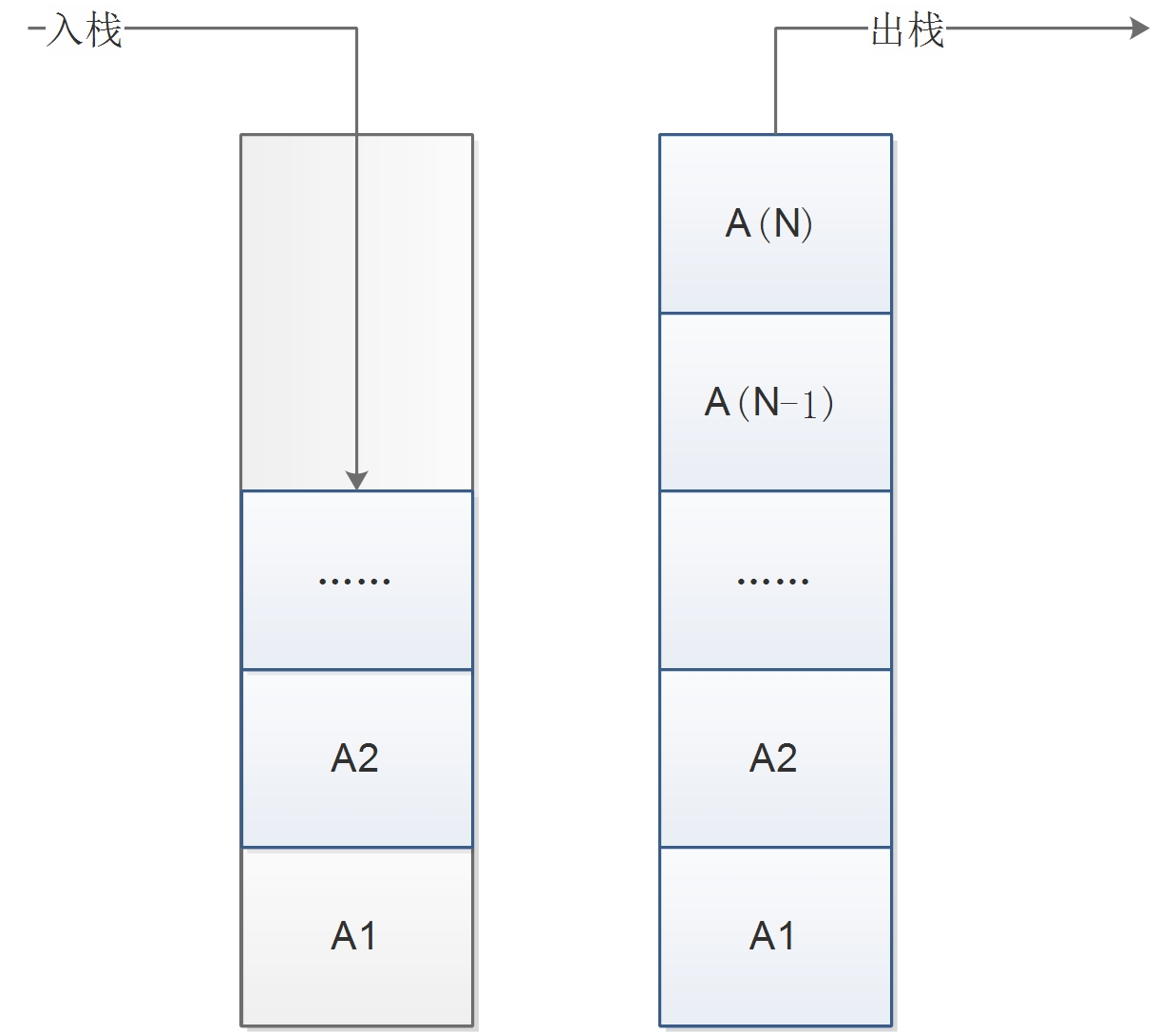
图2.3 栈结构图
三、算法思想
3.1 宽度优先
宽度优先搜索算法(又称广度优先搜索)其别名又叫BFS( Breadth First Search)。属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。算法采用队列的数据结构,所有因为展开节点而得到的子节点都会被加进一个先进先出的队列中。其邻居节点尚未被检验过的节点会被放置在一个被称为 open 的队列,而被检验过的节点则被放置在被称为 closed 的容器中(open-closed表)算法自始至终一直通过已找到和未找到顶点之间的边界向外扩展,首先搜索和s距离为k的所有顶点,然后再去搜索和S距离为k+l的其他顶点。算法流程图如图3.1所示。
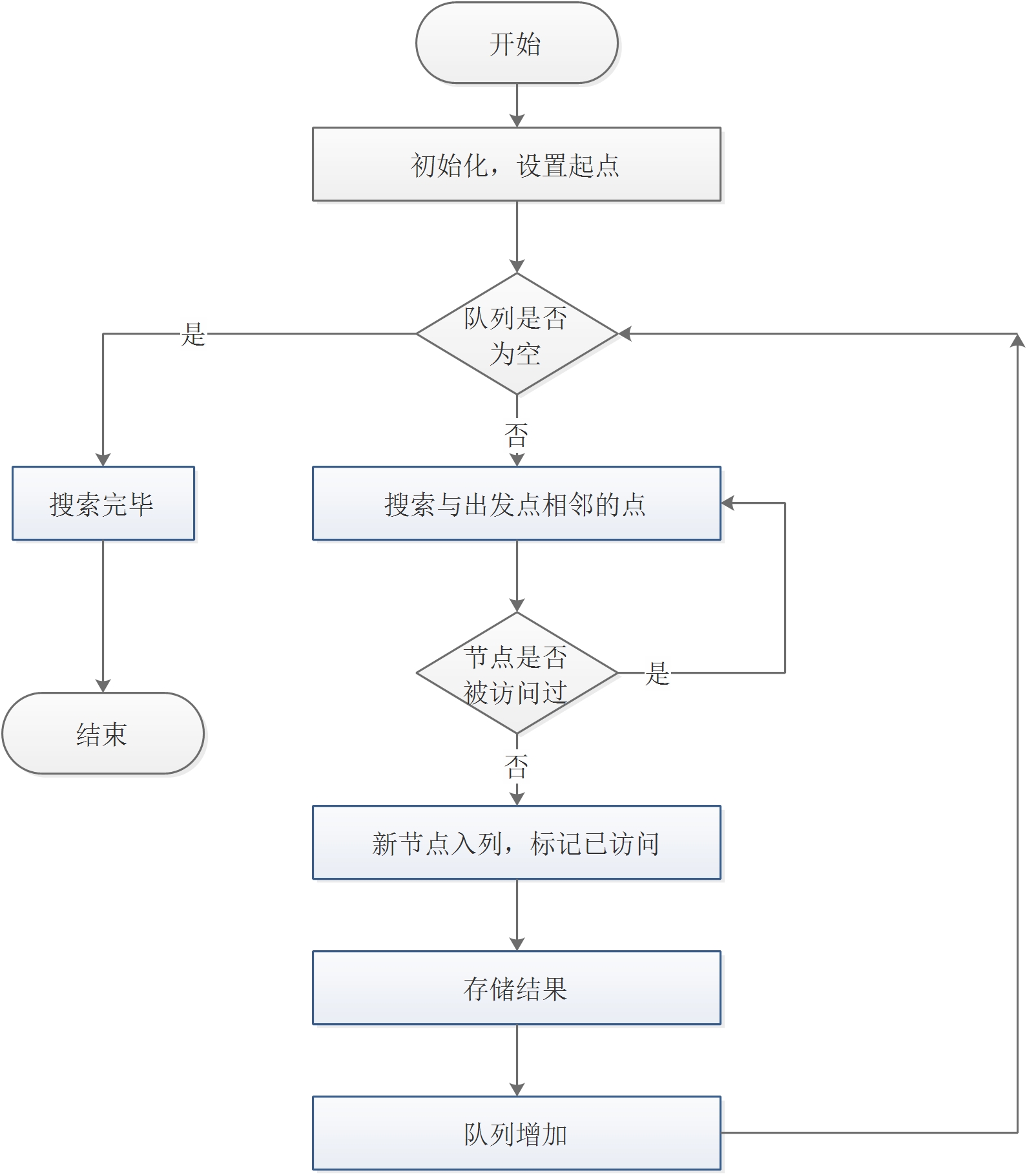
图3.1 DFS算法流程图
3.2 深度优先
深度优先搜索方法,又称DFS(Depth First Search),和树的先序遍历比较类似。假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。算法流程图如图3.2所示。
图3.2 BFS算法流程图
3.3 贪婪方法
贪婪算法(又称贪心算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。为了解决问题,需要寻找一个构成解的候选对象集合,起初,算法选出的候选对象的集合为空。接下来的每一步中,根据选择函数,算法从剩余候选对象中选出最有希望构成解的对象。如果集合中加上该对象后不可行,那么该对象就被丢弃并不再考虑;否则就加到集合里。每一次都扩充集合,并检查该集合是否构成解。
本题中具体实现方法为,先进行深度搜索,但是不急进入堆栈操作,而是存储当前所有搜索到的点的距离,选择距离最短的点,并放弃搜索其他同一深度的点,进入堆栈操作。算法流程图如图3.3所示。

图3.3 贪婪算法流程图
3.4 A*方法
A*搜寻算法俗称A星算法。A*算法是比较流行的启发式搜索算法之一,被广泛应用于路径优化领域。它的独特之处是检查最短路径中每个可能的节点时引入了全局信息,对当前节点距终点的距离做出估计,并作为评价该节点处于最短路线上的可能性的量度。
本题中的实现方法为,同贪婪类似,A*就相当于有一个智慧的老人为搜寻的对象打分,搜索过程中将距离和打分值相加,作为新的距离即可。其算法流程图如3.4所示。
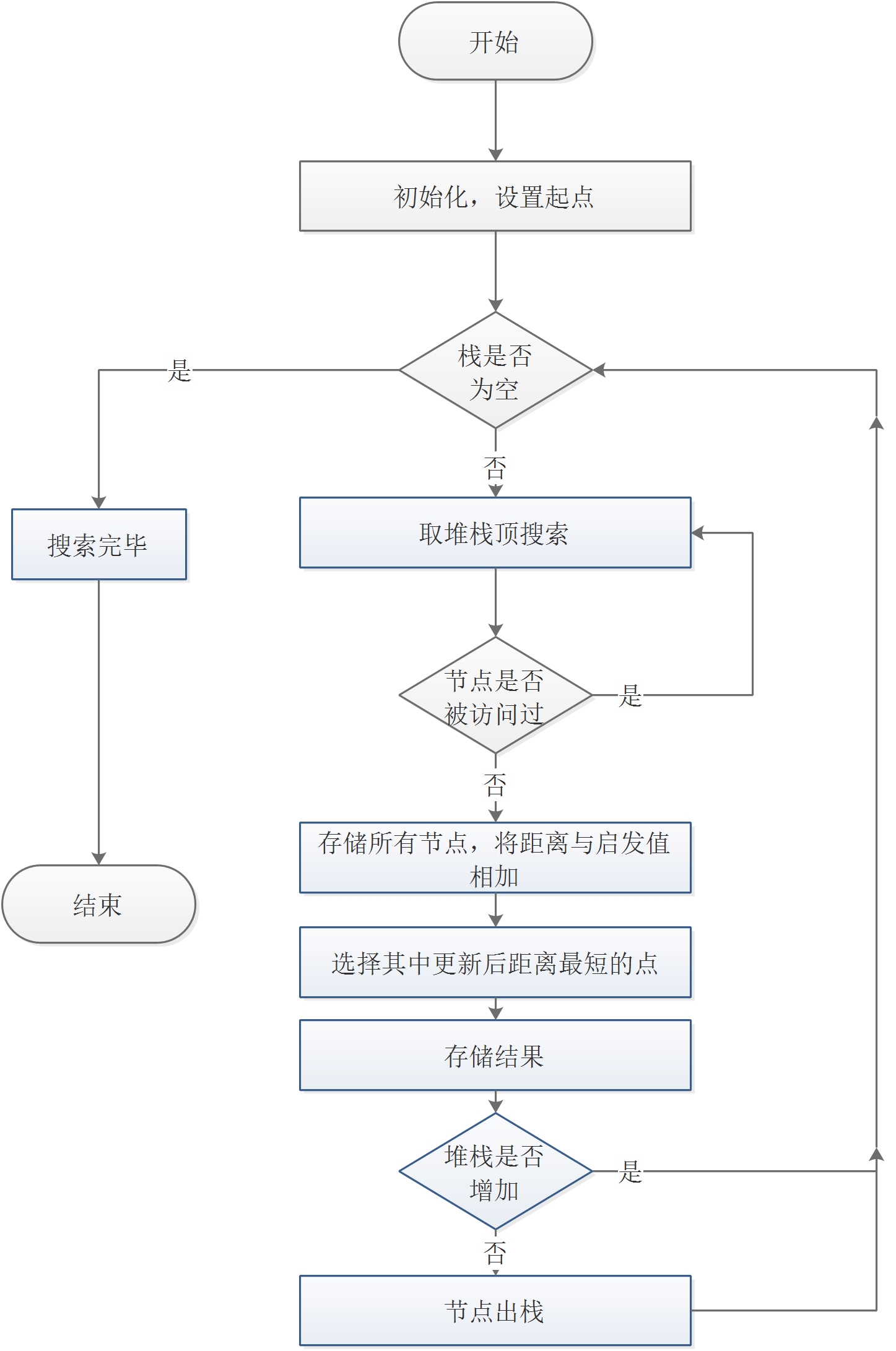
图3.3 A*算法流程图
四、关键代码
4.1 BFS方法
while tail~=head %判断
i=queue(tail); %取点
for j=1:20 %搜索所有适合的节点
if A(i,j)>=1 && isempty(find(flag==j,1))
queue(head)=j;
head=head+1; %数数
flag=[flag j]; %扩容
result=[result;i,j,A(i,j)]; %记录
end
end
tail=tail+1; %队列增加
end
4.2 DFS方法
while top~=0 %判断
pre_len=length(stack); %记录栈长度
i=stack(top); %取栈顶
for j=1:20
if A(i,j)>=1 && isempty(find(flag==j,1))
top=top+1;
stack(top)=j;
flag=[flag j];
re=[re;i,j,A(i,j)]; %记录
break;
end
end
if length(stack)==pre_len %如果栈未增加,则出栈
stack(top)=[];
top=top-1;
end
end
4.3 贪婪方法
while top~=0
pre_len=length(stack);
i=stack(top);
record=[];
for j=1:20
if A(i,j)>=1 && isempty(find(flag==j,1)) %记录所有相邻节点
record=[record;i,j,A(i,j)]
end
end
if isempty(record)
break
end
[s,k]= min(record(:,3,:)) %取距离最小节点
i=record(k,1,:);
j=record(k,2,:);
if isempty(find(flag==j,1))
top=top+1;
stack(top)=j;
flag=[flag j];
re=[re;i,j,A(i,j)];
end
if length(stack)==pre_len
stack(top)=[];
top=top-1;
end
end
4.4 A*方法
绝大部分与贪婪算法相同,只是更新了距离值。
for j=1:20
if A(i,j)>=1 && isempty(find(flag==j,1))
F(i,j)=A(i,j)+H(j);
record=[record;i,j,F(i,j)]; %启发值
end
end
if isempty(record)
break
end
4.5 反向寻址
所有的算法均采用相同的反向寻址方法。
while (1)
x=find(re(:,2,:)==m) %找到到达目的地所有的经过地
m=re(x,1,:) %迭代法反向寻找来的路径
if 1-isempty(x)
lujin=[city{re(x,1,:)},lujin];
juli=juli+re(x,3,:)
else
break
end
end
4.6 读取EXCEL
city={'Oradea','Zerind','Arad','Timisonra','Lugoj','Mehadia','Dobreta','Craiova','Rimmicu Vikea','Sibiu',...
'Fagaras','Pitesti','Bucharest','Giurglu','Uiziceni','Hirsova','Eforie','Vaslui','Lasi','Neamt'}; %存储城市名
filename = 'mymap.xlsx';
sheet = 1;
xlRange = 'C3:V22';
map = xlsread(filename,sheet,xlRange); %读取excel
map(isnan(map)) = 0; %将不相邻的点之间也设为0
五、运行结果
BFS方法的运行结果显示路径为:{'Arad' 'Sibiu' 'Fagaras' 'Bucharest'}
DFS方法的运行结果显示路径为:{ 'Arad' 'Zerind' 'Oradea' 'Sibiu' 'Rimmicu Vikea' 'Craiova' 'Pitesti' 'Bucharest'}
贪婪方法的运行结果显示路径为:{ 'Arad' 'Zerind' 'Oradea' 'Sibiu' 'Rimmicu Vikea' 'Pitesti' 'Bucharest'}
A*方法的运行结果显示路径为:{ 'Arad' 'Sibiu' 'Rimmicu Vikea' 'Pitesti' 'Bucharest'}
比较见表5.1
表5.1 四种算法的运行结果
|
算法 |
生成节点数 |
求解时间 |
距离 |
|
BFS方法 |
11 |
3.725s |
450 |
|
DFS方法 |
12 |
3.057s |
762 |
|
贪婪方法 |
7 |
3.606s |
575 |
|
A*方法 |
7 |
3.049s |
418 |
注:求解时间包括计时函数自用时间
六、比较结论
得益于MATLAB高速的矩阵运算能力,四种方法均在3-4秒之间完成,速度相差不大,但是在生成节点数上,DFS方法搜索了12个节点最多,贪婪方法和A*方法均为7最少。比较四种搜索方法得到的搜索路径,有启发值的A*方法搜索到的路径距离最短,为418,其次是宽度优先搜索,距离为450,距离最长的路径是由DFS方法产生,为762,贪婪方法为575。通过比较我们可以得出如下结论:
- 四种搜索方法在处理小型网络的搜索问题时,速度相差不大。
- 贪婪方法和A*方法生成节点数较少,理论上能够更快搜索出到达路径,在处理大型图的问题时,会表现得比较明显。
- 贪婪方法每一步都是选择当前状态下的最优解进行搜索,很容易陷入局部最优,从而使得搜索时间延长。
- 尽管BFS方法和DFS方法都一定可以找到路径,但是BFS方法搜索到的路径距离要明显优于DFS方法。
---恢复内容结束---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号