本文主要解释不断 的过程如何快速实现的具体流程。
给定正整数 和 个区间 。
有 组询问,每次询问给定一个整数 。在每个区间内选择一个整数 (),使得所选整数的总和等于 ,并使得选出的 序列的方差最小。输出方差最小值,对 取模。保证存在至少一种合法的选取方案。
第一行两个正整数 。
接下来的 行,每行两个自然数 。
最后 行,每行一个整数 ,表示一次询问。保证存在至少一种合法的选取方案。
行,每行一个整数,表示最小方差对 取模的值。
| 811073551 |
| 811073543 |
| 748683272 |
【样例解释 #1】
询问一方差最小的选择方案为 ,最小方差为 ,有 ,故输出 。
询问二方差最小的选择方案为 ,最小方差为 ,有 ,故输出 。
询问三方差最小的选择方案为 ,最小方差为 ,有 ,故输出 。
【数据范围】
本题开启捆绑测试。
对于所有数据,满足 ,,对于每个 保证存在一种合法的方案。
最重要的一个式子,有点类似于高中时学回归方程的时候学过的 ,其中 ,也就是 。
所以本题中的方差可以变成 ,对于每一个询问的 是固定的,所以要最小化的就是平方和 ,为了达到这个目的很显然的一个贪心就是让所有 取最小值 ,设此时他们的和为 ,那么我们还剩下 的数值要分配给这些 ,那么只用把 依次分配给最小的 即可。
注意这里可能有理解上的偏差,并不能在排序过后按照 的顺序依次将他们变成 ,直到不能操作为止,因为每次 之后最小值都有可能变化;而是取出每次给最小值 加上 之后的序列中的最小值 循环地动态进行该操作,否则你就只能在 上 AC 两个点。
按照该过程手玩一下样例就会发现这实际上类似于一个倒水的过程,拿样例一举个例子的话(红线为初始值),可以具象为如下模型:
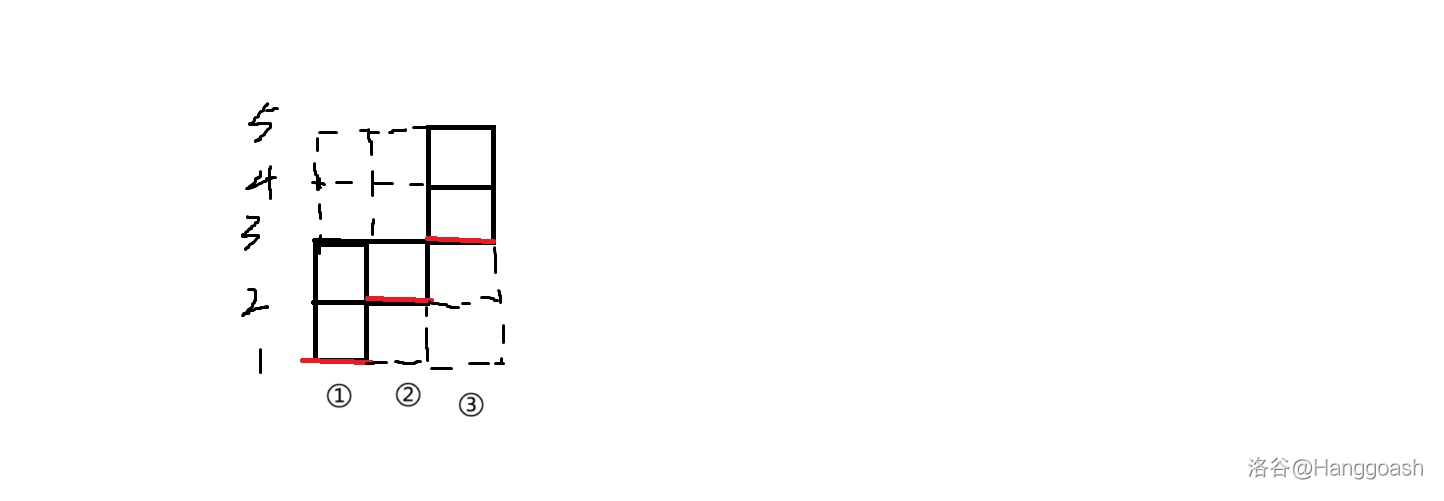
现在如果倒水进去,把最高液面的高度变为 ,也就相当于对 们进行若干次操作后使得 ,就会变成这样 :
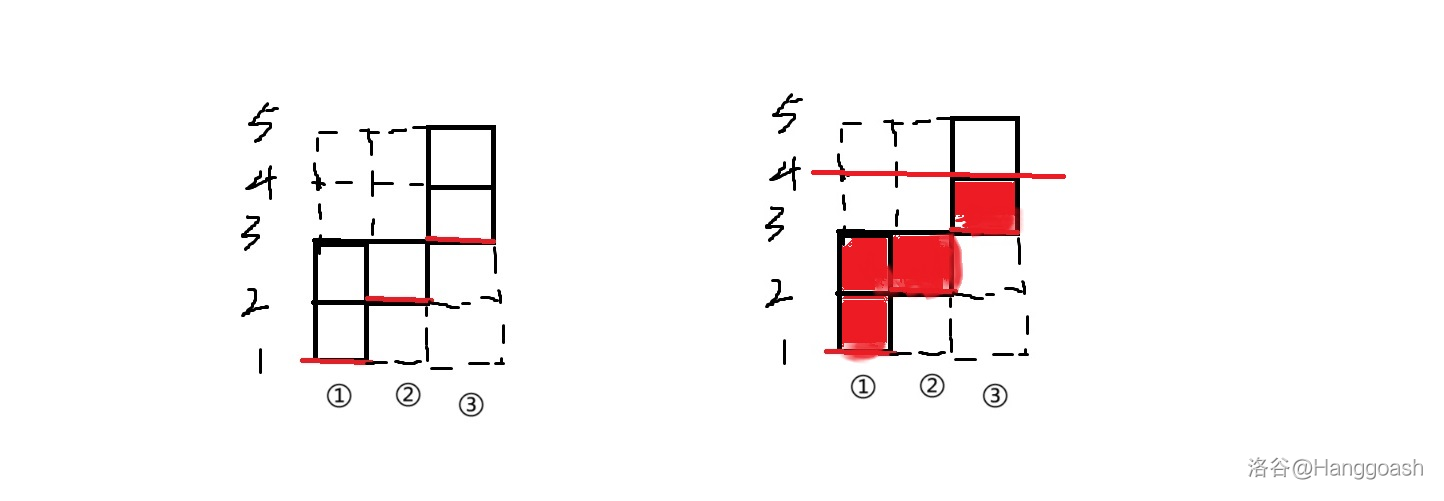
其中我们花费的代价为 ,也就是 个红格子。
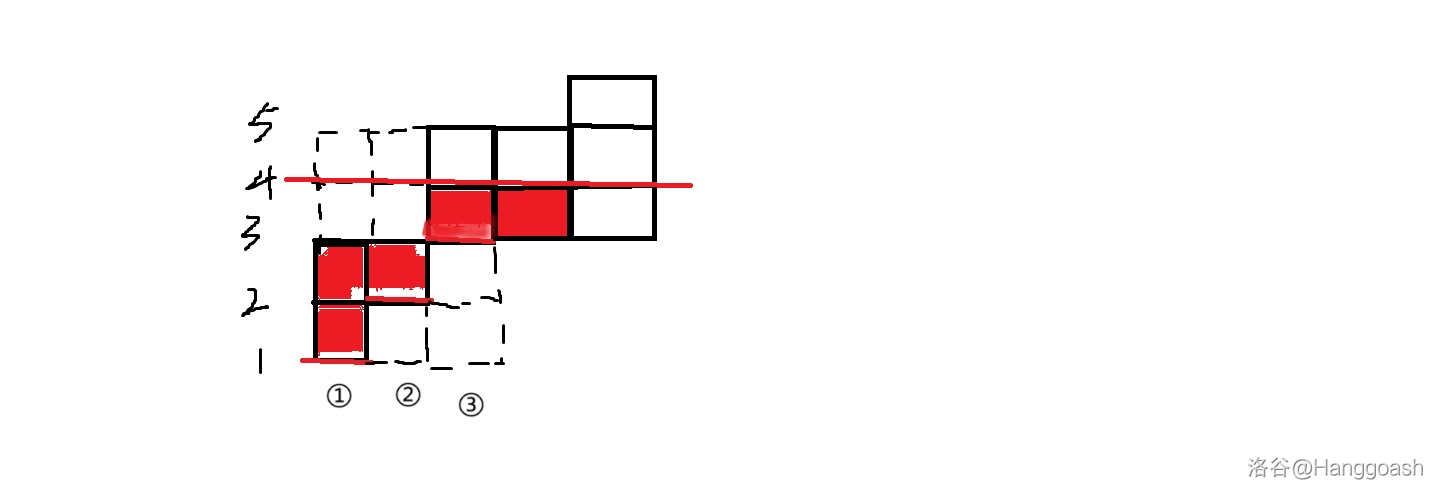
那在这个问题中,我们一共需要花费的代价是 ,很显然的是这个最后的最高高度是具有单调性的,也就是说总是存在一个 ,使得在花费完 的代价后,最高液面 (最大的 )能够达到 ,但无法达到 。(注意最高一层的液面不一定都能恰好取到最大值,因为“液面”高度是用整数而不是小数来衡量的,比如下图这种 的情况) ,所以可以采取二分。
至于在二分内部的判断方式,我们可以定义一个 数组,表示将所有 提高到 的代价,可以想到维护 数组的方式就是根据 依次在 内进行区间内每个数 的操作 ,最后算出每个位置对应的值,再前缀和即可,可以在读入的时候就维护差分数组,再做两次前缀和的方式实现,不会的话请移步 P2367 。
显然是不能够暴力枚举的,思考一下发现,如果我们现在算出了最大高度为 :
对于 的所有(显而易见,不可取等)区间 :其对应的 必取 ,对答案的贡献为 。
对于 的所有(显而易见,可以取等)区间:其对应的 必取 ,贡献为 。
对于其他的所有区间:
其 的可能取值为 或 ,有 个 , 个 ,可以 地统计。
前两种情况可以定义 为高度为 时, ; 亦是如此。
由于一个 可以对所有比它大的高度产生贡献,符合区间加的特性,所以同样可以用差分的方式预处理求出。
涉及到逆元的最好开个 ,尤其是在模数比较大的情况下,任何可能会爆的地方最好都取个模。
然后由于 的下标都对应的是高度而不是编号 ,所以枚举的时候应该是从 到
代码仅供参考,有些小地方的实现可能不同,不过不影响。
| #include<bits/stdc++.h> |
| #define int long long |
| #define rr register |
| using namespace std; |
| const int MOD=998244353; |
| template<typename T>inline void re(T &x) |
| { |
| x=0; |
| int f=1;char c=getchar(); |
| while(!isdigit(c)){if(c=='-')f=-1;c=getchar();} |
| while(isdigit(c)){x=(x<<1)+(x<<3)+(c^48);c=getchar();} |
| x*=f; |
| } |
| template<typename T>inline void wr(T x) |
| { |
| if(x>9)wr(x/10); |
| putchar(x%10^48); |
| } |
| inline int power(int a,int b) |
| { |
| int ans=1; |
| while(b) |
| { |
| if(b&1)ans=ans*a%MOD; |
| a=a*a%MOD; |
| b/=2; |
| } |
| return ans%MOD; |
| } |
| const int N=1e6+10; |
| pair<int,int> q[N]; |
| int sum[N],lsum[N],rsum[N],lcnt[N],rcnt[N]; |
| int L=1e6+10,R=-1; |
| int n,tn,Q,S; |
| inline void add(int l,int r) |
| { |
| sum[l]++,sum[r]--; |
| } |
| inline void pre() |
| { |
| re(n),re(Q); |
| |
| for(rr int i=1;i<=n;++i) |
| re(q[i].first),re(q[i].second),add(q[i].first,q[i].second),L=min(L,q[i].first),R=max(R,q[i].second),S+=q[i].first; |
| for(rr int i=L;i<=R;++i)sum[i]=sum[i-1]+sum[i]; |
| for(rr int i=L;i<=R;++i)sum[i]=sum[i-1]+sum[i]; |
| |
| int l,r,tmp; |
| for(rr int i=1;i<=n;++i) |
| { |
| l=q[i].first,r=q[i].second; |
| rcnt[r+1]++,rcnt[R+1]--; |
| lcnt[L]++,lcnt[l+1]--; |
| tmp=l*l%MOD,lsum[L]=(lsum[L]+tmp)%MOD,lsum[l+1]=(lsum[l+1]-tmp+MOD)%MOD; |
| tmp=r*r%MOD,rsum[r+1]=(rsum[r+1]+tmp)%MOD,rsum[R+1]=(rsum[R+1]-tmp+MOD)%MOD; |
| } |
| for(rr int i=L;i<=R;++i) |
| { |
| lcnt[i]+=lcnt[i-1],rcnt[i]+=rcnt[i-1]; |
| lsum[i]+=lsum[i-1],lsum[i]%=MOD; |
| rsum[i]+=rsum[i-1],rsum[i]%=MOD; |
| } |
| |
| tn=power(n,MOD-2); |
| } |
| |
| inline int find(int x,int l,int r) |
| { |
| if(l>=r)return l; |
| int mid=(l+r)/2; |
| if(sum[mid-1]>=x)return find(x,l,mid); |
| else return find(x,mid+1,r); |
| } |
| inline int solve(int x) |
| { |
| int ans1,ans2; |
| int h=find(x-S,L,R); |
| int res=n-rcnt[h]-lcnt[h],cnt=sum[h-1]-x+S; |
| ans1=(rsum[h]+lsum[h])%MOD,ans1+=(h-1)*(h-1)%MOD*cnt%MOD+h*h%MOD*(res-cnt)%MOD,ans1=ans1%MOD*tn%MOD; |
| ans2=(MOD-power(x%MOD,2)*power(tn,2)%MOD)%MOD; |
| return (ans1+ans2)%MOD; |
| } |
| signed main() |
| { |
| pre(); |
| int x; |
| while(Q--) |
| { |
| re(x); |
| wr(solve(x)),putchar('\n'); |
| } |
| return 0; |
| } |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 单线程的Redis速度为什么快?
· 展开说说关于C#中ORM框架的用法!
· Pantheons:用 TypeScript 打造主流大模型对话的一站式集成库
· SQL Server 2025 AI相关能力初探
· 为什么 退出登录 或 修改密码 无法使 token 失效