2020春 软工实践寒假作业(2/2)—疫情统计
 武汉加油!中国加油!
武汉加油!中国加油!
| 这个作业属于哪个课程 | 2020春软工实践|W班 |
|---|---|
| 这个作业要求在哪里 | 作业的要求 |
| 这个作业的目标 | 开发一个简易的疫情统计系统,并学会git,github项目管理 |
| 作业正文 | 博客链接 |
| 其他参考文献 | 《构建之法》,学长以及其他网友的博客,菜鸟教程 |
一.Github仓库地址
二.构建之法阅读与PSP
1.第一章
通过第一章的阅读,了解到软件的开发的不同阶段,书中以航天业的发展映射到软件开发,使得对于软件开发有一个更加深入的理解。也明白了其实软件工程包罗了许多的知识领域,这倒是颠覆我传统的思想,一直认为软件工程是把代码与代码管理做好而且,其实不然,软件工程还有它自身需要的目标,比如用户满意度,可靠性等。
2.第二章
在第二章中,主要介绍了单元测试,回归测试,效能分析以及个人软件开发流程(PSP),这个章节在我看来是软件工程的一个特别重要的部分,因为这其中首先有对开发流程的规划以及假设(PSP),还有开发之后对于软件的效能分析,使得我可以直观的发现自己的程序在哪个部分耗时多,边可以及时分析是不是可以进一步进行优化或者使用一些算法进行操作。而且单元测试中的测试样例可以自己手动构造,这其实也是从侧面对自己写的程序需要有一个直观的感受,才能从隐隐约约对自己程序的信任通过多次的debug转化为真正的信任。
3.第三章
其实对于自己的工作能力来说,个人觉得还是很弱,主要原因在于没有真正意义上写过项目。所以项目能力也无从说起,希望能通过这次的软件工程提升自己的能力。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 45 |
| Estimate | 估计这个任务需要多少时间 | 800 | 855 |
| Development | 开发 | 450 | 535 |
| Analysis | 需求分析 (包括学习新技术) | 90 | 95 |
| Design Spec | 生成设计文档 | 30 | 35 |
| Design Review | 设计复审 | 30 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 60 | 55 |
| Coding | 具体编码 | 360 | 450 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 55 |
| Reporting | 报告 | 40 | 65 |
| Test Report | 测试报告 | 40 | 55 |
| Size Measurement | 计算工作量 | 10 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 50 | 65 |
| 合计 | - | 1320 | 1550 |
三.解题思路
1.分析
一开始拿到题目,从题意把问题分为三大块,
一是命令的处理,
二是文件的读入与存储,
最后是数据的处理和输出。
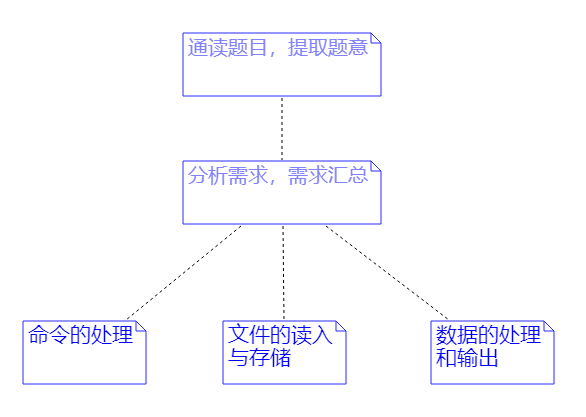
2.问题解决构思
命令的处理:考虑到命令可能会有输入的先后顺序,便采取定位的方法而后将命令参数提取出来。
文件读入与存储:在读入的时候考虑将文件名称与提供的日期作对比,即找出所需文件的绝对路径,
而后使用正则表达式对疫情的8种不同情况进行匹配,并再次使用正则表达式将情况中的省份以及人数
进行提取,而后使用HashMap对省份进行命中与存储。
数据的处理和输出:通过之前命令的分解,再次使用HashMap对type和province进行标记,最后输出即可。
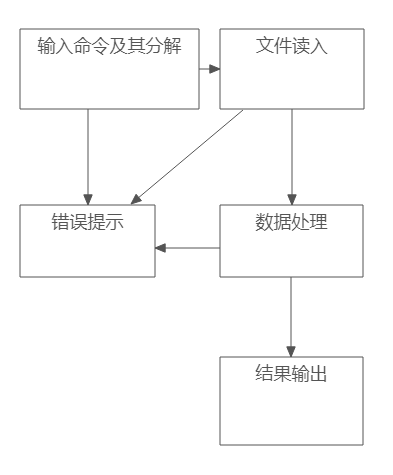
四.实现过程
从最初的命令的处理与判断,
到文件判断与读入,
而后分析命令需求,
最后对不同命令做出不同的输出要求。
结构图
顺序图

五.关键代码说明
开始:通过上述的代码流程图建立疫情类进行操作
public static void main(String[] args) throws IOException {
CoronavirusDetail CD=new CoronavirusDetail();
CD.Init();
AnalysisCommand(args);
CD.ReadAll(Log,Out,Date,Type,Province);
CD.PrintDetail(Log,Out,Date,Type,Province);
}
命令输入与命令分解:对5种输入参数进行匹配与分解
//获取log目录,out目录,date数值
Log=MatchTot(Command,$log,Len,Log);
Out=MatchTot(Command,$out,Len,Out);
Date=MatchTot(Command,$date,Len,Date);
//获取type的参数,province的参数
Type=MatchMuch(Command,$type,Len,Type);
Province=MatchMuch(Command,$province,Len,Province);
文件读入:通过文件名时间与指定时间进行配对获取截止当前时间的所有文件
//得到当前日期之前的文件名
File tempFile=new File(Files.get(i).trim());
String fileName=tempFile.getName().substring(0,10);
if(date.compareTo(fileName)>=0){
Beforefiles.add(Files.get(i));
}
文件内容读取:通过正则表达式的匹配将八种情况进行配对与切割,而后进行存储
//设定正则表达式规则
String MatString_1="(\\S+) 新增 感染患者 (\\d+)人";
String SplitString_1=" 新增 感染患者 |人";
String MatString_2="(\\S+) 新增 疑似患者 (\\d+)人";
String SplitString_2=" 新增 疑似患者 |人";
String MatString_3="(\\S+) 感染患者 流入 (\\S+) (\\d+)人";
String SplitString_3=" 感染患者 流入 | |人";
String MatString_4="(\\S+) 疑似患者 流入 (\\S+) (\\d+)人";
String SplitString_4=" 疑似患者 流入 | |人";
String MatString_5="(\\S+) 死亡 (\\d+)人";
String SplitString_5=" 死亡 |人";
String MatString_6="(\\S+) 治愈 (\\d+)人";
String SplitString_6=" 治愈 |人";
String MatString_7="(\\S+) 疑似患者 确诊感染 (\\d+)人";
String SplitString_7=" 疑似患者 确诊感染 |人";
String MatString_8="(\\S+) 排除 疑似患者 (\\d+)人";
String SplitString_8=" 排除 疑似患者 |人";
文件输出:按照指定省份的拼音顺序输出,以及所指定的省份type顺序输出,也是用HashMap取得标号进行输出
for(int i=0;i<ProvinceStr.length;i++) {
for(int j=0;j<Province.length;j++)
if(ProvinceStr[i].equals(Province[j])){
System.out.print(ProvinceStr[i]+" ");
Integer Pronum=(Integer) ProvinceMap.get(ProvinceStr[i]);
int Typecnt=0;
for(int k=0;k<4;k++) {
if(Type[k].equals($nothing)) Typecnt++;
}
for(int k=0;k<4;k++)
if((Typecnt==4)||(!Type[k].equals($nothing))){
Integer Tynum=(Integer) TypeMap.get(Type[k]);
System.out.print(TypeStrCn[Tynum]+Detail[Pronum][Tynum]+" ");
}
System.out.println();
}
}
六.单元测试截图和描述
单元测试结果:
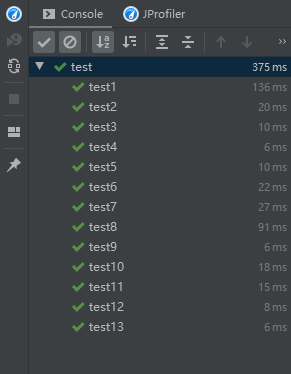
分析
1.
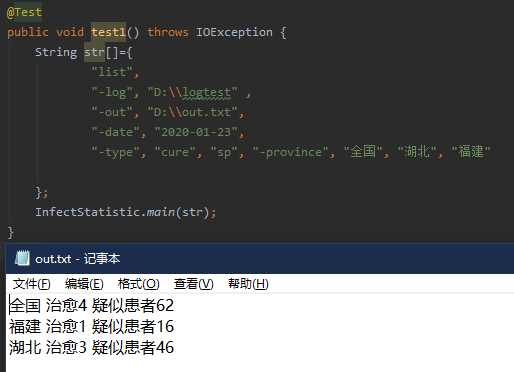
type采取cure、sp,province使用全国、湖北和福建,
输出type时候安装type输入顺序输出,省份用拼音排序输出。
2.

将测试一中湖北省份删去后输入文件中将不再有湖北的相关信息
3.
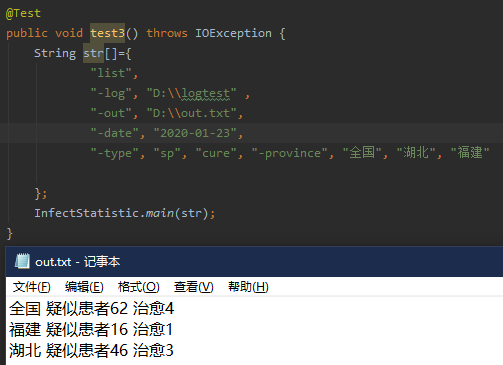
将测试一中的cure和sp调换位置后,输出也调换位置
4.
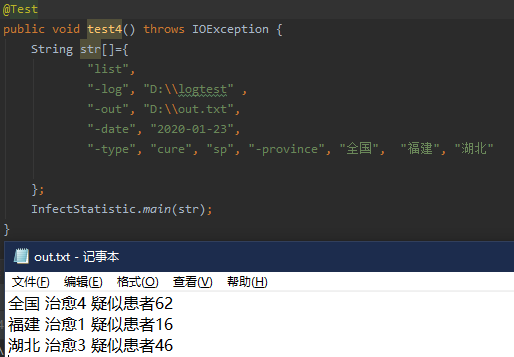
将测试一中的湖北和福建调换位置后,输出仍然按照拼音排序
5.
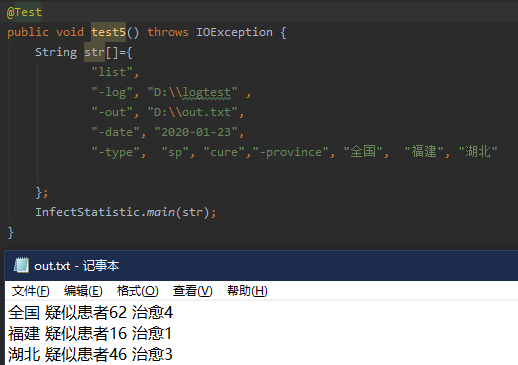
将测试一中的湖北和福建,cure和sp一同调换位置后,输出
省份仍然按照拼音排序,cure和sp按照调换后的位置输出。
6.
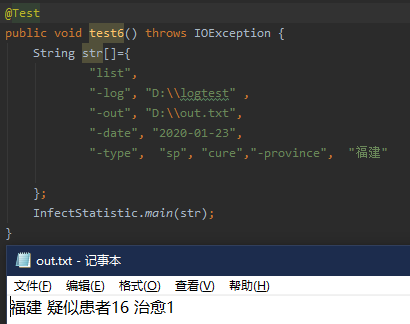
将测试五中省份删除至只剩福建,则单独输出福建
7.
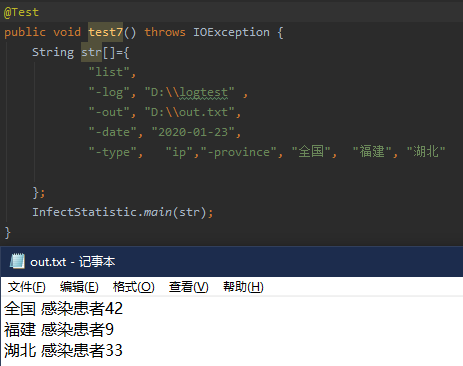
将测试五中的type参数删除并只使用ip参数,则只输出感染患者的人数
8.
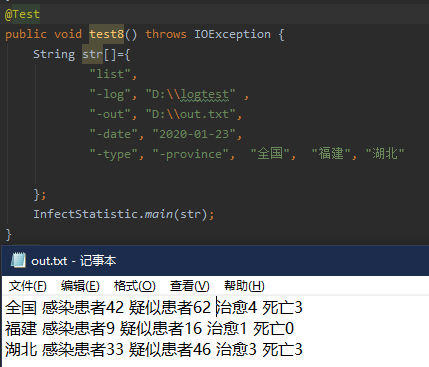
将测试五中的type参数删除但保留-type,则全部输出指定省份的四种状态的人数
9.

将测试八中的-type也删除,仍然输出指定省份的四种状态的人数
10.
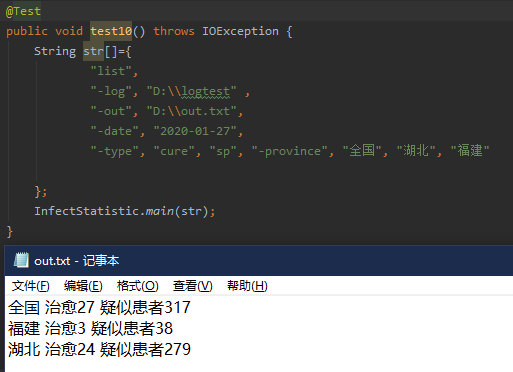
将测试一中的时间改为2020-01-27,则将统计截止到2020-01-27时候的情况
11.
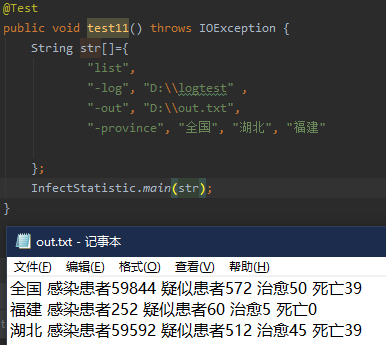
将时间-date不输入,让系统时间作为默认时间,并且-type也不输入
则得到截止当日2020-02-18的统计结果(不是真实数据)
12.

将测试十一中的-out命令与-province命令调换位置,结果不影响
13.
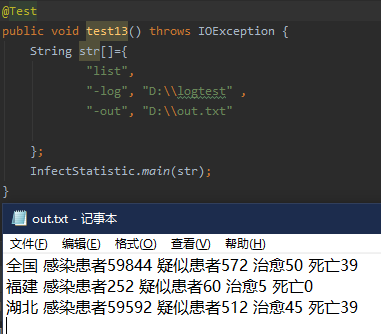
仅仅只输入-out -log 命令则会将有数据的省份输出
七.单元测试覆盖率优化和性能测试
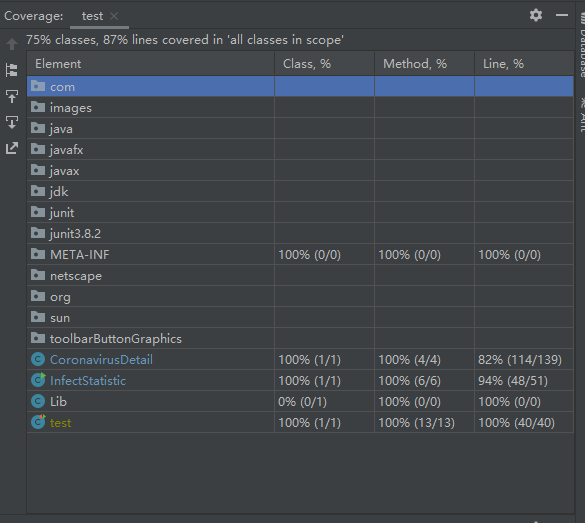
1.覆盖率
优化之前
优化之后
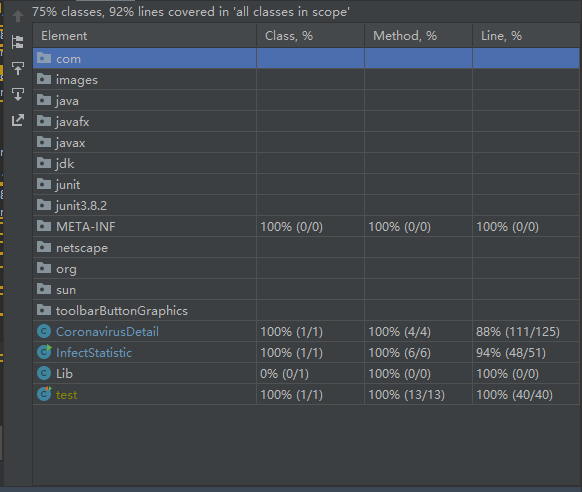
覆盖率的优化中主要优化了将易于重复的代码整合成函数,减少冗余的代码行。
2.性能测试
优化之前

优化之后
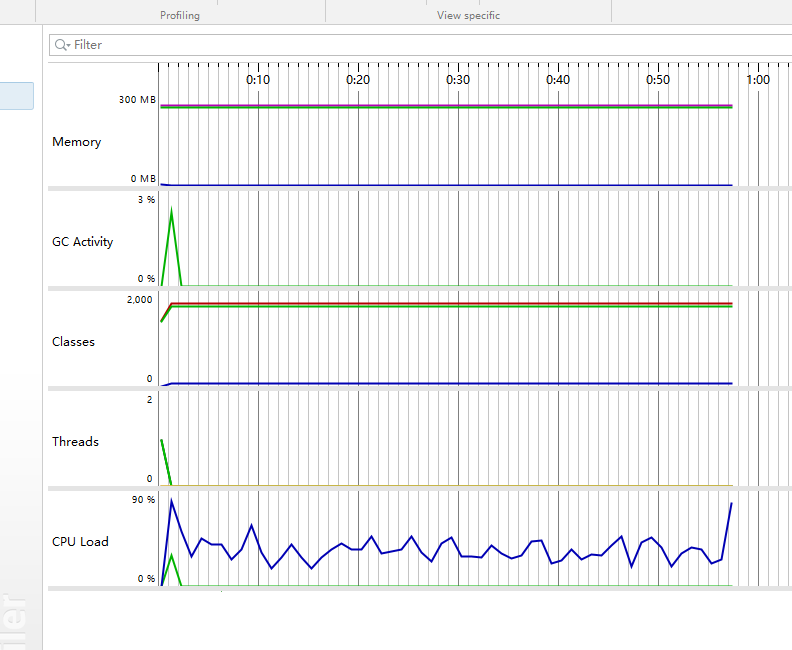
性能优化上主要通过hash将省份进一步优化成Nlog(N)访问,同样减少冗余代码的使用。
八.代码规范链接
九.心路历程与收获
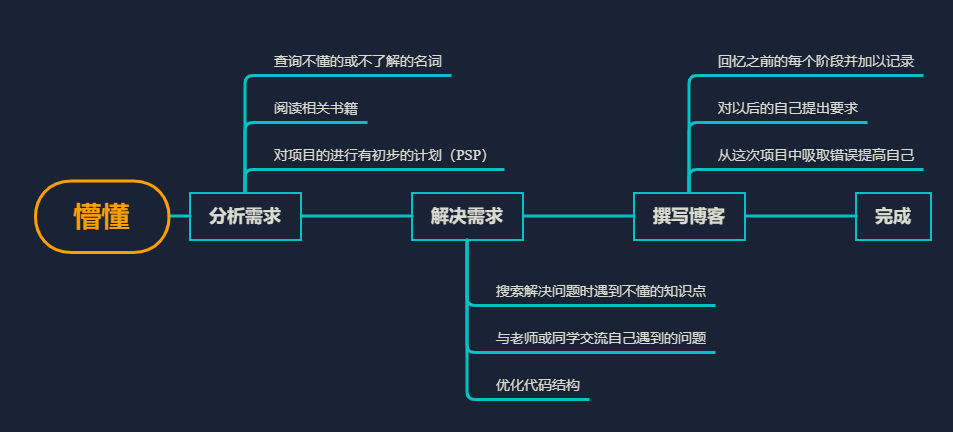
首先觉得这次的作业量虽然不是很大,但是确实受益匪浅,
感觉自己比较完整得体验了一把做项目的感觉,一开始朦朦胧胧,
先是阅读了构建之法而后使用PSP对自己本次的作业进行了一个规划,
显而易见,自己总会高估自己的能力,实际操作的时间远比规划来的慢,
但是这其实也是对自己的不断认识,不断摸索的过程,包括最后的单元测试
和覆盖率优化以及性能优化也是第一次接触,感觉也是做的不太好,希望以后多多努力。
十.第一次作业中技术路线图相关的仓库
| 仓库名 | 链接 | 简介 |
|---|---|---|
| 算法学习 | https://github.com/XG-zheng/ACM | 介绍了算法领域常见的知识点 |
| AI学习 | https://github.com/apachecn/AiLearning | 机器学习、深度学习、自然语言处理的入门教材 |
| 大数据入门指南 | https://github.com/heibaiying/BigData-Notes | 提供了详尽的大数据入门教材 |
| 人工智能系统TensorFlow | https://github.com/jikexueyuanwiki/tensorflow-zh | Google发布人工智能系统TensorFlow开源代码 |
| 数据科学和人工智能技术笔记 | https://github.com/apachecn/ds-ai-tech-notes | 介绍了数据科学和人工智能技术的相关知识 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号