

词法分析器Lexer
词法分析
In computer science, lexical analysis, lexing or tokenization is the process of converting a sequence of characters (such as in a computer program or web page) into a sequence of tokens (strings with an assigned and thus identified meaning).
在计算机科学中,词法分析,lexing或标记化是将一系列字符(例如在计算机程序或网页中)转换成一系列标记(具有指定且因此标识的含义的字符串)的过程。
编码目标
给定一个源代码文件,能够将其转化为词法记号流。
比如规定int的词法记号为30,输出就是<30, int>;数字的词法记号为11,则输入123,输出为<11, 123>。
约定
把程序中的词法单元分为四类:标识符(分为关键字和一般标识符)、数字、特殊字符、空白(空格、Tab、回车换行等)
程序流程图
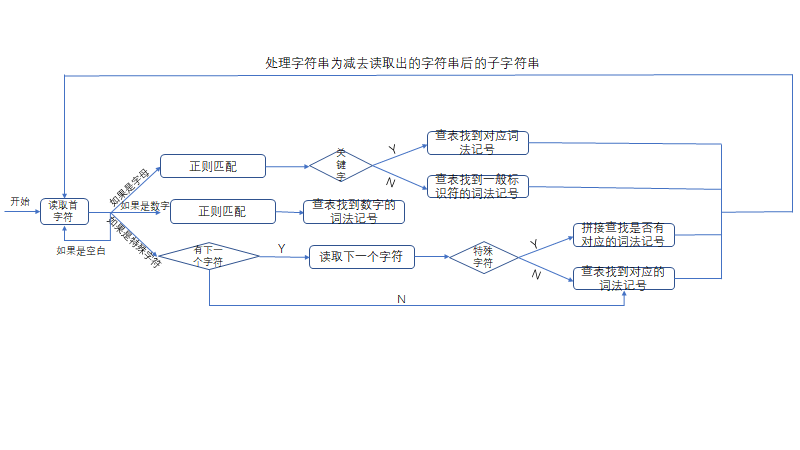
对于运算符等符号,这里只考虑两个字符的组合情况,不考虑三个字符组成的运算符。之所以要在读到特殊字符之后在往后读一个字符是因为有可能在表中存在类似>=和>的运算符,要保证最长字符匹配。
关键代码
首字符类型判断
public static String getCharType(String str) {
String regex_Letter = "[a-zA-Z]";
String regex_Number = "[0-9]";
String regex_Blank = "\\s";
Pattern pattern;
pattern = Pattern.compile(regex_Letter);
Matcher matcher = pattern.matcher(str);
if (matcher.find())
return "LETTER";
pattern = Pattern.compile(regex_Number);
matcher = pattern.matcher(str);
if (matcher.find())
return "NUMBER";
pattern = Pattern.compile(regex_Blank);
matcher = pattern.matcher(str);
if (matcher.find())
return "BLANK";
return "SPECIAL";
}
如果首字符为字母
case "LETTER":
pattern = Pattern.compile(regex_ID);
matcher = pattern.matcher(srcCode);
if (matcher.lookingAt()) {
String result = matcher.group();
if (LexicalToken.isKeyWord(result)) {
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
} else {
int token = lextok.getToken("ID");
System.out.printf("<%d,%s> ", token, result);
}
}
srcCode = srcCode.substring(matcher.end());
break;
如果首字符是数字
case "NUMBER":
pattern = Pattern.compile(regex_NUM);
matcher = pattern.matcher(srcCode);
if (matcher.lookingAt()) {
String result = matcher.group();
int token = lextok.getToken("NUM");
System.out.printf("<%d,%s> ", token, result);
}
srcCode = srcCode.substring(matcher.end());
break;
如果首字符是空格
case "BLANK":
srcCode = srcCode.substring(1);
break;
如果首字符是特殊符号
case "SPECIAL":
if (srcCode.length() > 1) {
String secondChar = srcCode.substring(1, 2);
String result;
LinkedHashMap tokenMap = lextok.getLexicalTokenMap();
Set set = tokenMap.keySet();
result = firstChar + secondChar;
if (getCharType(secondChar).equals("SPECIAL") && set.contains(result)) {
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
srcCode = srcCode.substring(2);
}else {
result = firstChar;
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
srcCode = srcCode.substring(1);
}
} else { // 字符串中只有一个字符时
int token = lextok.getToken(srcCode);
System.out.printf("<%d,%s> ", token, srcCode);
srcCode = srcCode.substring(1);
}
break;
源码地址:https://github.com/Liyzy/Lexer
开发环境:IJ idea 2018.2

