
嵌入 HTML 里的 PDF 文件解密
前言
今天弄到了一份奇怪的 PDF 文件,它是以 html 文件的形式存在的,似乎还加密了。

明明是 2020 年的文件,居然还有跨域问题,这作者也太……了吧
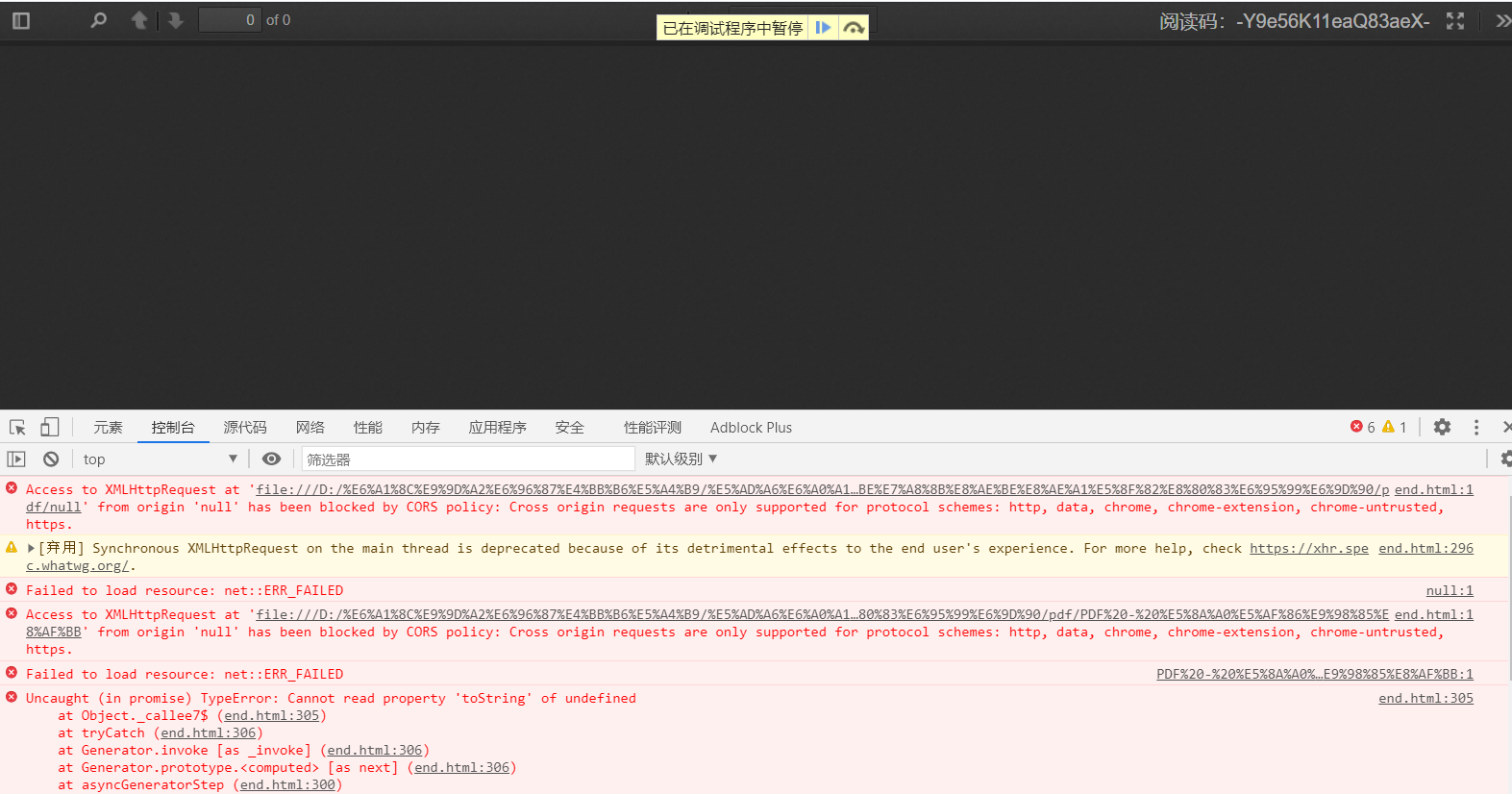
就因为这个跨域问题,导致我看不了里边的内容,这怎么能忍?干他
尝试分析
首先尝试使用记事本打开,因为文件内容实在是太大了,记事本卡死,这招行不通。
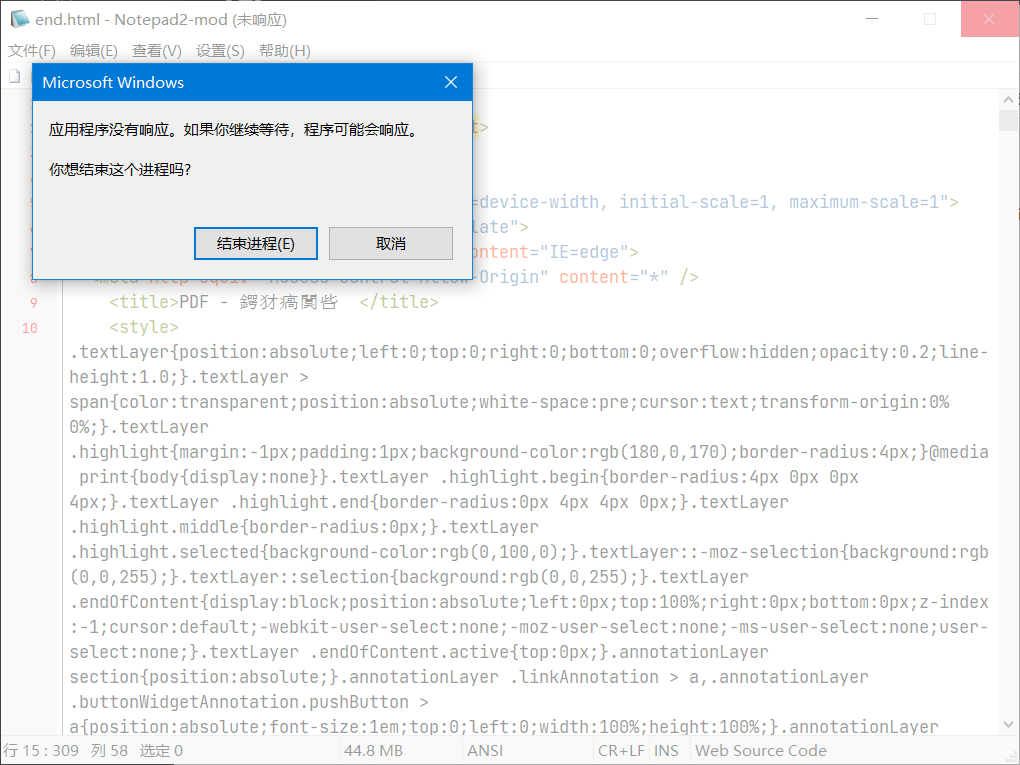
然后,想到了我们强大的 Word

一样,卡死,文件大就是可以为所欲为嗷。

然后百度搜索一堆东西,似乎有好多人分析过这种文件,试过了各种编辑器,全都是卡死。
然后,突然就有灵感了,既然卡死是因为文件过大,文件过大是因为里头嵌入了超大的 PDF 文件本体,那我想办法把 PDF 本体从 HTML 里剥离出来不就好了?
逐个击破
虽然可以通过编程来实现字节读取,可我并不知道 PDF 本体的偏移量。
这时就该祭出强大的 WinHex 了,打开文件后它长这样
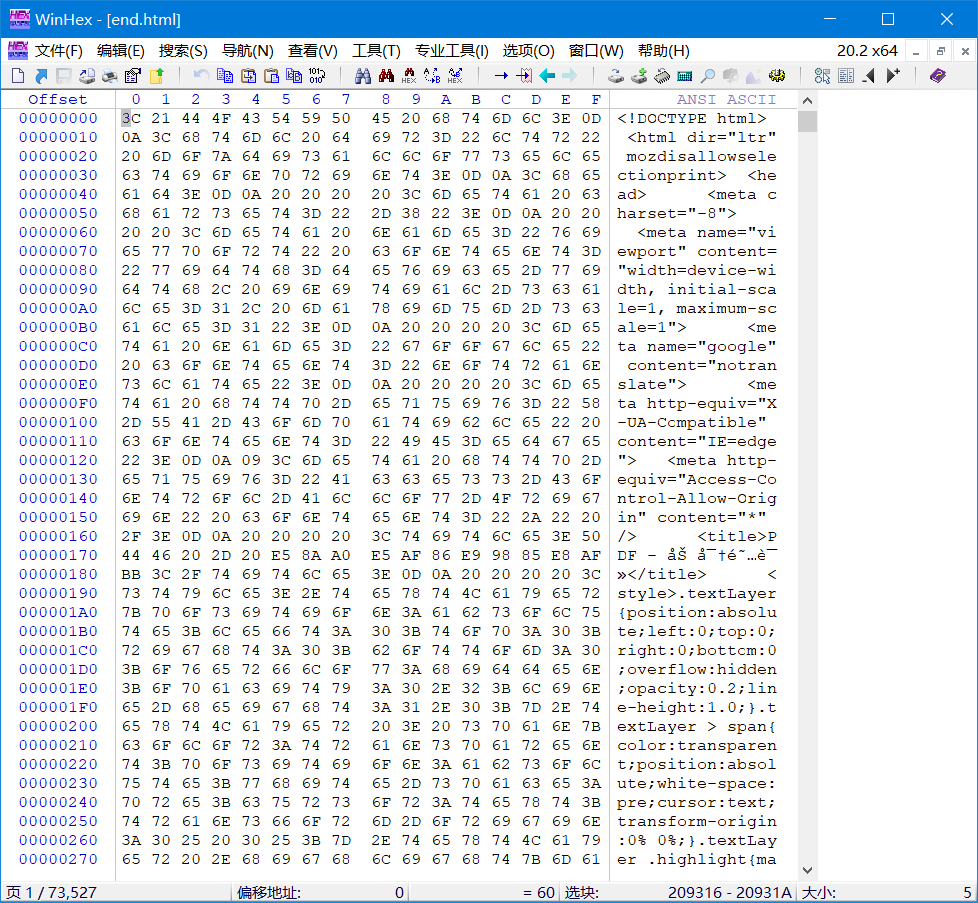
虽然界面丑了点,当还是能用的,也可以用其他 十六进制编辑器。这下就完全是不卡了,可以安心分析文件了。
抽离内嵌 PDF 与 HTML
随手一拖就发现了大量的毫无规律的大写字母区域,可以推断出这应该就是被编码后的 PDF 本体了
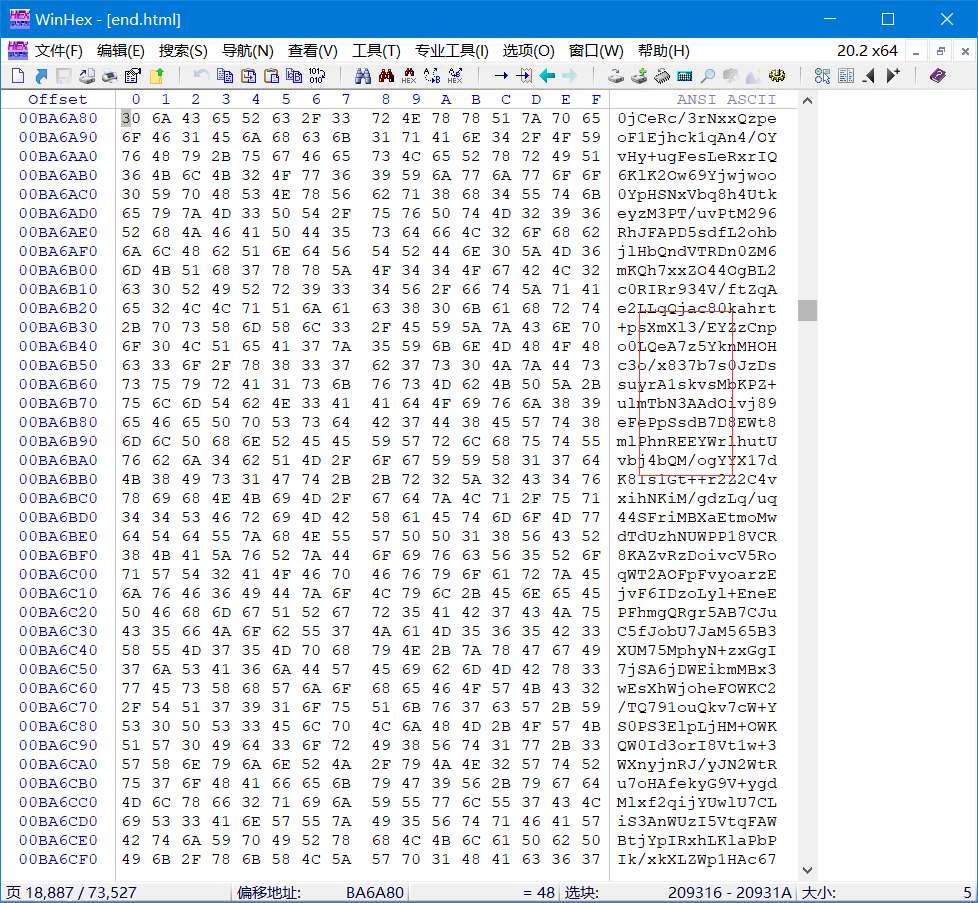
顺着这条线索就能找到 PDF 偏移头和 PDF 偏移尾了
文件头
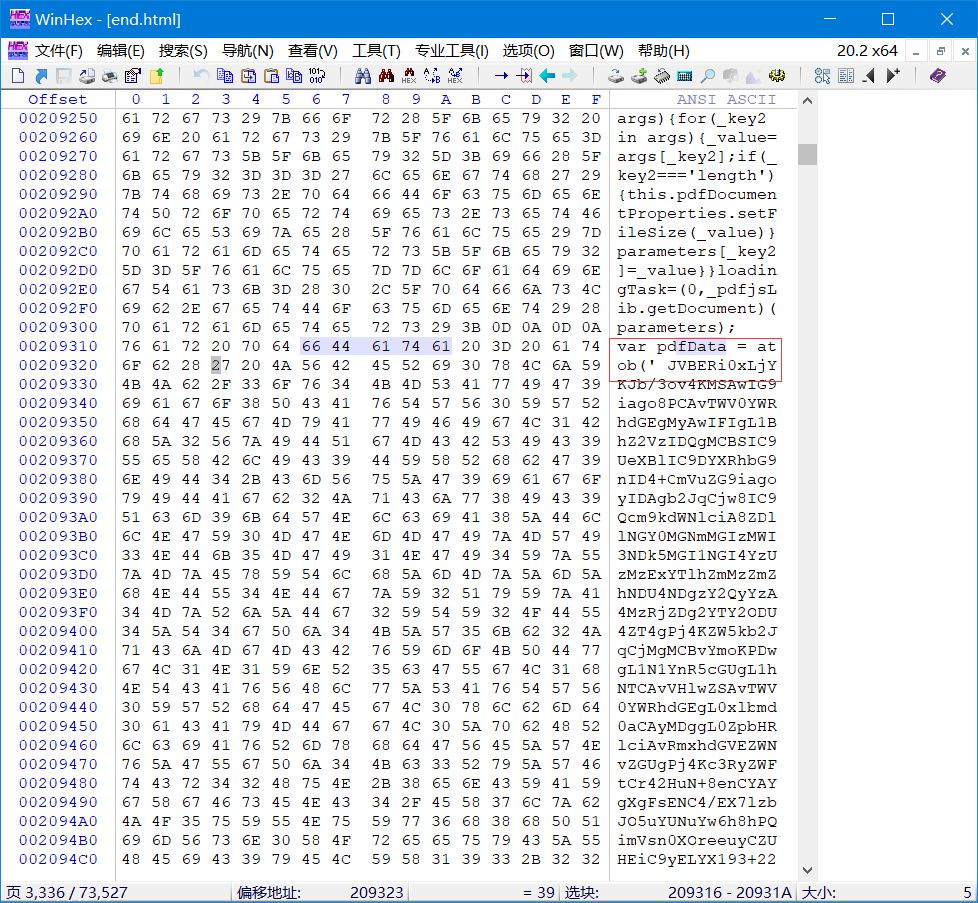
文件尾
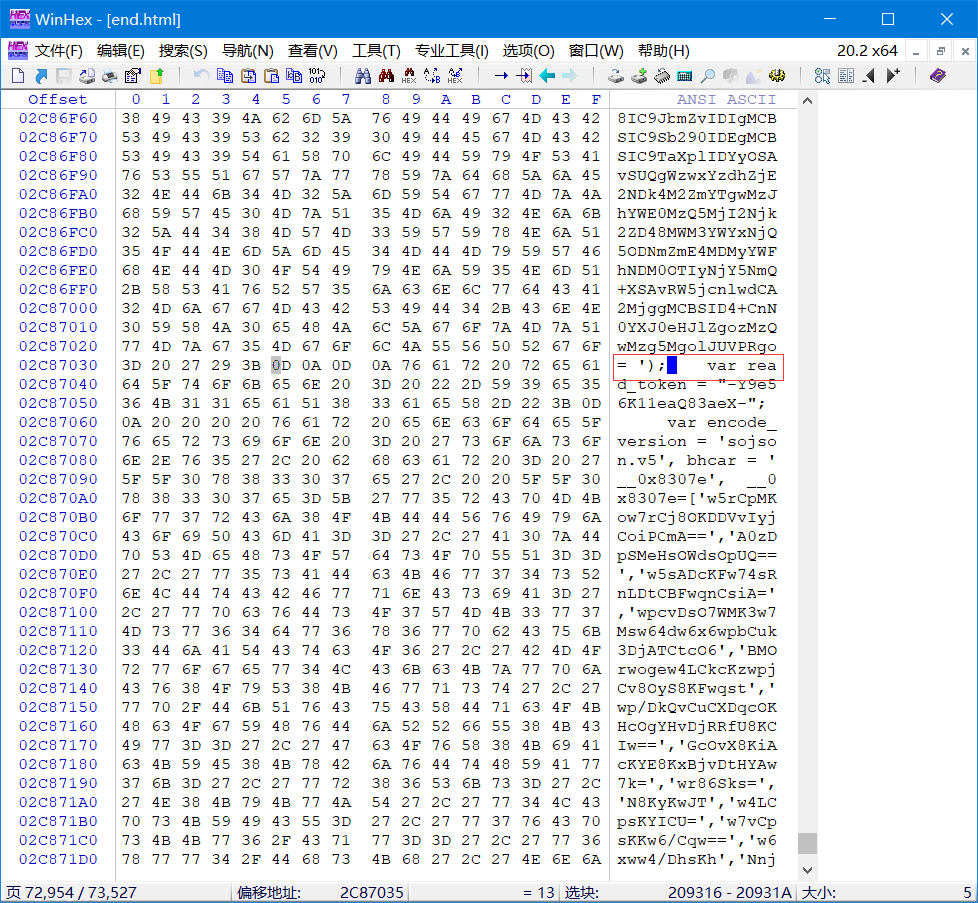
因为这个巨大的字符串全是 大小写字母+ 数字 还有 / 和 + 我们大胆推断它应该是 Base64 编码,这点后边要用到
知道了偏移量,接下来要做的就是编程分离 PDF 和 HTML 了,这里我使用 Python 3(PY 永远滴神!)
先抽出 PDF 本体,代码如下
with open('end.html','rb')as f:
# pdf 头 0x209323
# pdf 尾 0x2C87035
with open('inner','wb+')as ff:
f.seek(0x209323) # 跳转文件指针到 PDF 头的偏移量
# 尾偏移 - 头 偏移 得到文件尺寸
ff.write(f.read(0x2A7DD12)) # 读取 文件尺寸 大小的字节数,并写入新文件
然后就是读取 HTML 文件
with open('end.html','rb')as f:
# pdf 头 0x209323
# pdf 尾 0x2C87035
with open('a.html','wb+')as ff:
ff.write(f.read(0x209323))
f.seek(0x2C87035) # 跳过 pdf 主体
ff.write(f.read())
代码思路是这样,可能存在偏差,仅供参考。
大胆猜测
还记得我们前边说的 Base64 吗?现在就是用到的时候了!
由于文件实在是太大了,而且也还是二进制文件(解码后),因此十分不适合使用在线解码方式。
在百度一周无果后,突然想到了 Linux (Linux 永远滴神!)
别问为什么不自己写程序,问就是懒!
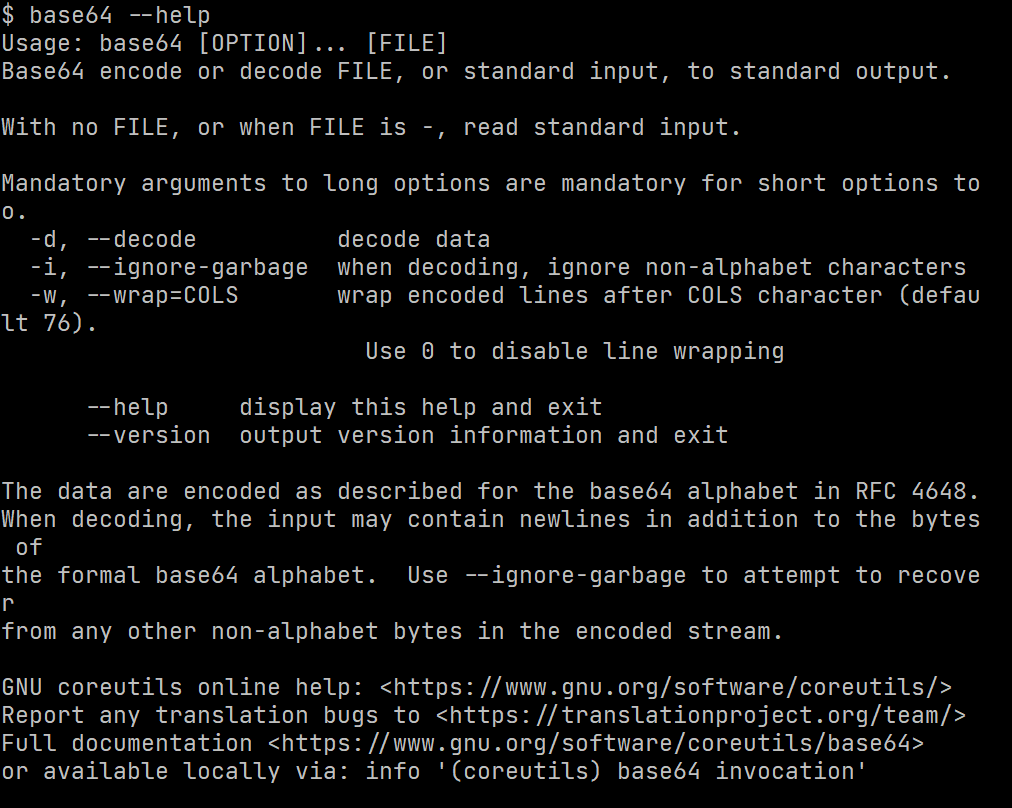
Linux 下有个命令(实际也是程序啦) base64,因为我在用 git,就随手开了个 git -bash(实在不想因为这事去开个虚拟机)
尝试性的输入了
base64 --help
果然是有的啊,(git 永远滴神!),不光如此,它的参数还是接收一个文件!这不就是正合我意嘛!
输入
base64 -d inner >> a.pdf
成功转码,看来就是 base64 编码了,让我们打开文件看看效果
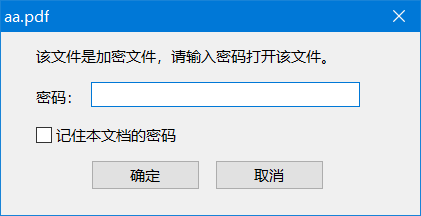
不出所料,是有密码的
爆破密码
既然它是内嵌进 HTML 的,那我们可以尝试在 HTML 里找一找蛛丝马迹
在 PDF 文件本体后边的 HTML 里有一些有意思的东西
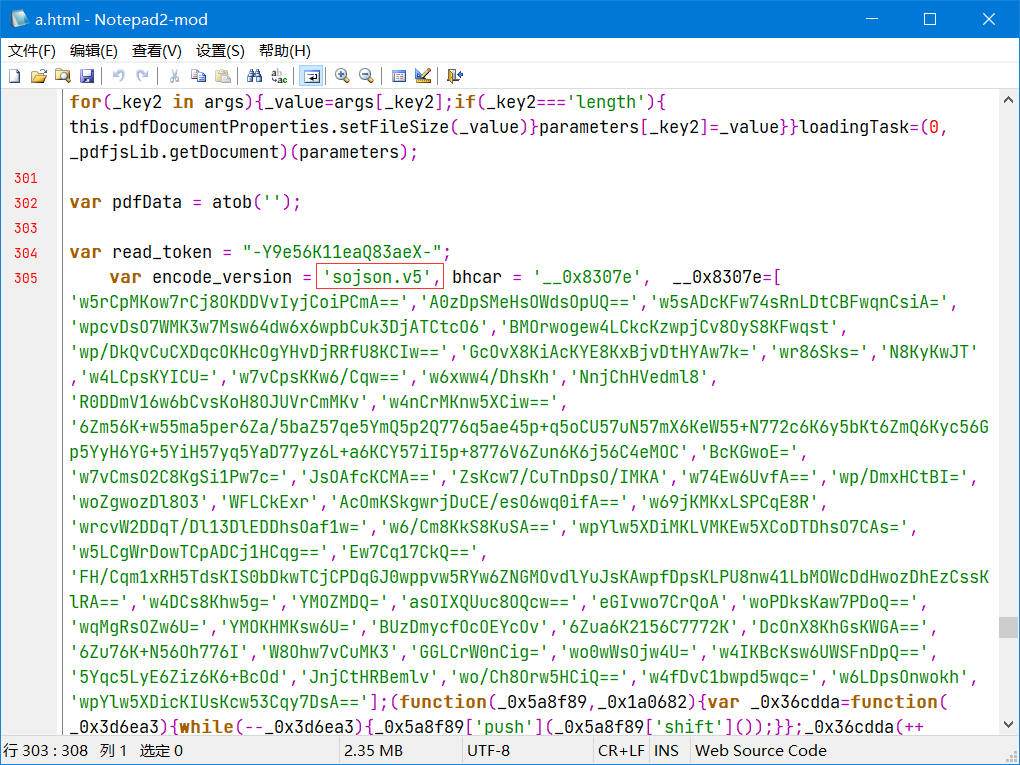
这明显是加密了的 JavaScript ,随手搜了下在线解密网站

不多说了,懂得都懂(永远滴神!),稍微格式化下代码,继续(永远滴神!),找到一些有意思的字符串。

拿去碰碰运气;第一个失败了,第二个,直接密码正确
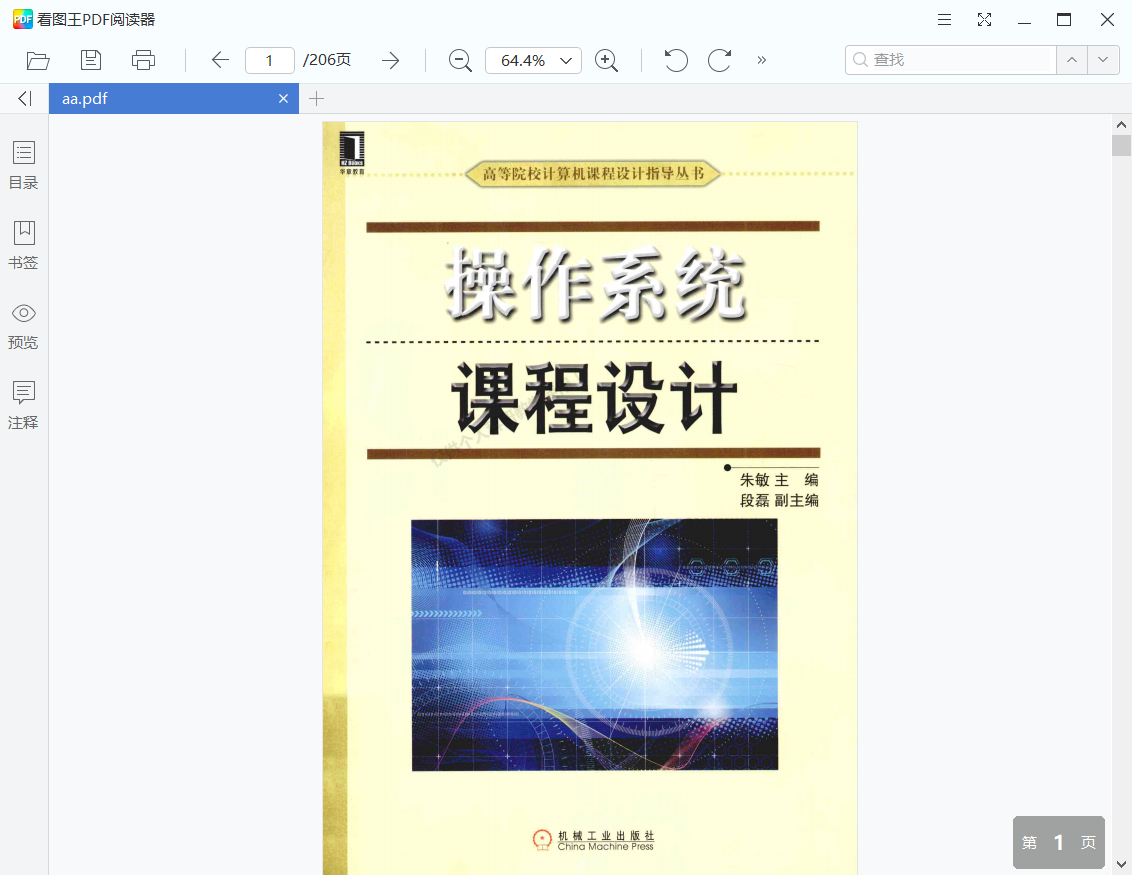
到此为止,解密部分就结束了,但这种密码我怎么可能会去记?
去除密码
随手百度了一个 PDF 密码去除工具
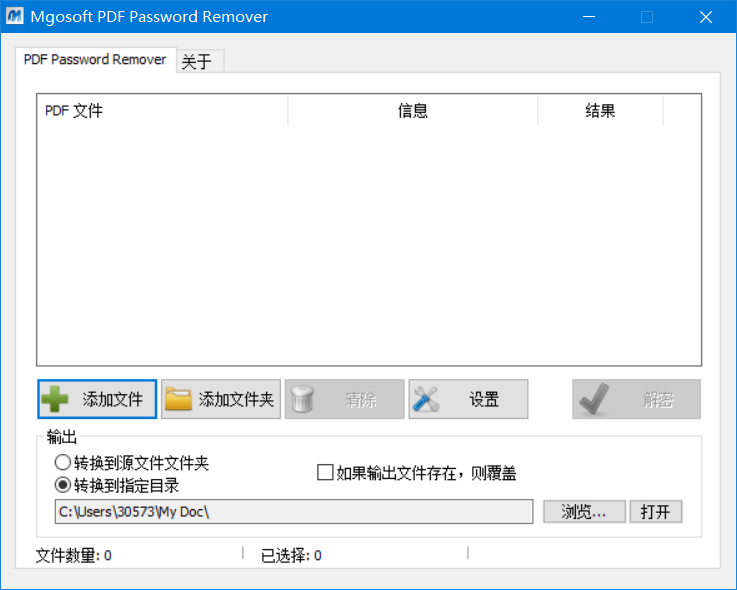
一套操作后
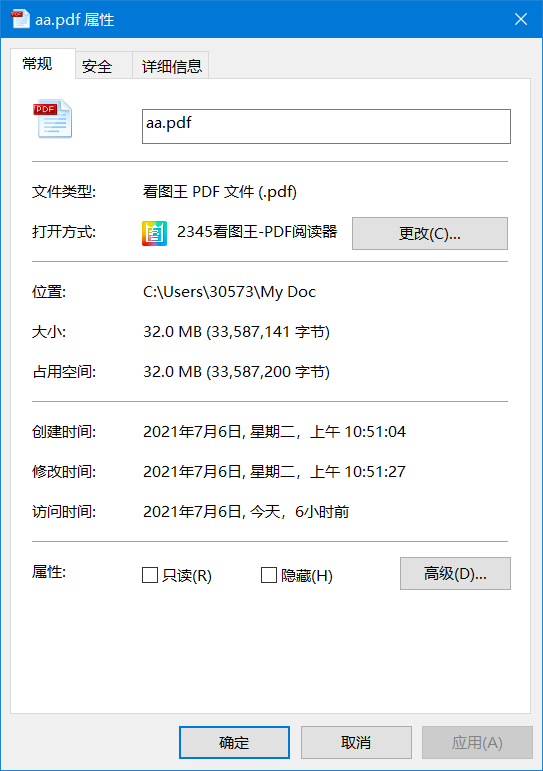
没问题了,成功去除密码
小插曲
在调试过程中还发现这个网页有个有意思的东西——反调试
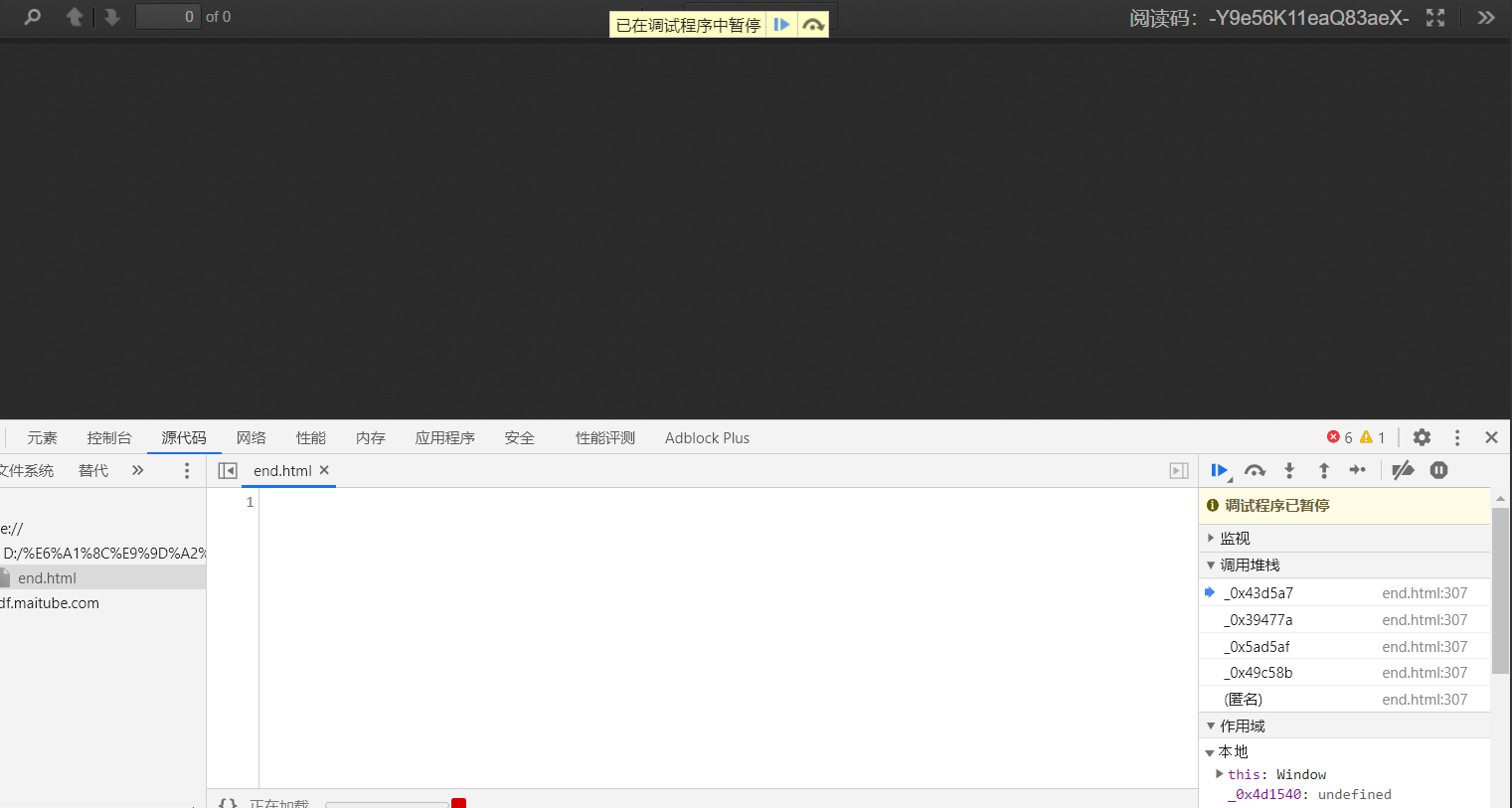
打开控制台时,会进入无限 Debug,如果尝试取消断点,网页还是会卡死
经过分析,这应该是第二个 加密的 js 干的,去掉之后就没事了,具体代码就不贴出来了
本文作者:博麗靈夢
本文链接:https://www.cnblogs.com/Hakurei-Reimu-Zh/p/14977757.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步