
【目标检测】Faster R-CNN算法实现
一、前言
继2014年的R-CNN、2015年的Fast R-CNN后,2016年目标检测领域再次迎来Ross Girshick大佬的神作Faster R-CNN,一举解决了目标检测的实时性问题。相较于Fast R-CNN而言,Faster R-CNN主要改进措施包括:
- 区域建议网络(RPN):Faster R-CNN摒弃了选择性搜索,提出区域提议网络(Region Proposal Network)用于生成候选目标区域。RPN网络通过滑窗的方式提取候选区域特征,并将提取的特征映射到一个低维向量,然后将其输入到边界框回归层和边界框分类层,获取候选目标区域的位置偏移和分类输出。
- 共享卷积特征:Faster R-CNN中RPN和检测网络共享输入图像的卷积特征,实现了端到端的联合训练,使得模型能够更好地调整卷积特征以适应特定的检测任务。
- 先验框(Anchors):Faster R-CNN中首次提出先验框的概念,通过使用多尺度先验框,RPN能够生成不同大小和长宽比的候选区域,提高了模型对于不同尺度的目标的检测能力。
上述改进措施使得Faster R-CNN在速度和准确性上都优于Fast R-CNN,它不仅具有更高的检测精度,而且在处理多尺度和小目标问题时也更加有效。
同Fast RCNN实现一样(见 https://www.cnblogs.com/Haitangr/p/17709548.html),本文将基于Pytorch框架,实现Faster RCNN算法,完成对17flowes数据集的花朵目标检测任务。
二、Faster RCNN算法结构
Faster RCNN论文原文中算法整体结构如下:

如图,Faster R-CNN算法流程主要包括四个部分,分别是卷积层(Conv Layers)、区域建议网络(RPN)、感兴趣区域池化(RoI Pool)和检测网络(Classifier)。各部分功能如下:
- 卷积层:卷积层是输入图像的特征提取器,作用是提取输入图像的全图特征,用于RPN推荐区域生成和RoI区域池化。卷积层可以采用多种网络结构来实现,比如Vgg/ResNet,本文代码实现部分采用的是Vgg16部分结构;
- RPN:RPN作用是生成候选框。RPN在特征图上滑动,对特征图上每个位置生成一定数量的先验框anchors,再结特征图分类和回归结果对先验框位置进行校正,从中选取符合要求的候选区域proposals用于区域池化和目标检测;
- 区域池化:区域池化的作用是根据proposals区域位置在特征图上进行特征截取,并将截取的特征缩放到固定大小以便于检测网络进行分类和回归;
- 检测网络:检测网络是最终对proposals进行分类和回归的全连接网络,用于对proposals进行更为精确的分类和位置回归。
三、Faster RCNN算法实现
下图为以VGG16为backbone的Faster RCNN模型结构。对于任意大小输入图像,在输入网络前会先统一缩放至MxN,然后经过VGG16进行提取高维特征图。特征图进入RPN网络后有两个分支流向,一是分类分支计算目标置信度,二是回归分支计算位置偏移量,综合二者结果获得目标区域proposals。ROI Pooling层利用获取的proposals从特征图上提取区域特征,送入后续分类和回归网络进行最终预测。

1. Conv Layers
Conv Layers一般采用Vgg/ResNet结构作为backbone,目的是进行深度特征提取,将特征用于后续任务。本工程中使用的骨干网络包含extractor和linear两部分。其中extractor为Vgg16结构,包含4次2*2池化,其主要作用是对输入图像进行全图特征提取。linear为全连接层结构,主要作用是对roi池化特征进行初步处理,便于最终检测网络分类和回归。backbone具体实现如下:



def backbone(pretrained=False): """ 定义主干特征提取网络和最终推荐区域特征处理线性网络 :param pretrained: 是否加载预训练参数 :return: 特征提取器和后续线性全连接层 """ net = torchvision.models.vgg16(pretrained=pretrained) extractor = net.features[:-1] linear = nn.Sequential( nn.Linear(in_features=512 * 7 * 7, out_features=4096, bias=True), nn.ReLU() ) if not pretrained: extractor.apply(lambda x: nn.init.kaiming_normal_(x.weight) if isinstance(x, nn.Conv2d) else None) linear.apply(lambda x: nn.init.kaiming_normal_(x.weight) if isinstance(x, nn.Linear) else None) return extractor, linear
2. RPN
RPN网络是Faster RCNN的主要改进点,利用RPN网络直接生成检测框,极大的提高了检测速度。RPN网络示意图如下

网络主要分为两个分支,即分类和回归,分别计算目标概率和偏移值。实际代码实现时主要分如下三步:
- 对特征图像上每个位置生成固定数量一定尺寸的先验框anchors,anchors会覆盖图像所有位置,并将进入后续网络进行分类和回归;
- 通过RPN中的分类和回归分支判断每个anchor是否包含目标并计算每个anchor的坐标偏移值;
- 在ProposalCreater中利用坐标偏移offsets对anchors进行位置校正,再通过尺寸、目标得分、非极大值抑制对anchors进行过滤,获取最终的rois区域。
2.1 先验框生成
先验框anchors就是目标检测中常用的一定尺寸的矩形框,每行有四个元素[x1, y1, x2, y2],用来表示左上和右下角点坐标。在anchors生成过程中需要三组参数来控制anchors的大小和形状,分别为base_size,wh_ratios和anchor_spatial_scales。其中base_size表示预设的基础空间尺寸,默认为获取feature_map过程中的空间缩放比例,表示特征图上一个像素映射回原图时的大小。wh_ratios表示锚框宽高比值,用来控制先验框的形状。anchor_spatial_scales表示锚框与基础尺寸的比值,用来控制先验框的大小。以base_size=16,wh_ratios=(0.5, 1.0, 2.0),anchor_spatial_scales=(8, 16, 32)为例,算法会以原点为中心,按空间尺寸比分别生成边长为16*8=128、16*16=256、16*32=512的正方形,然后在保持面积基本不变的情况下调整各边长,得到宽高比分别为0.5、1.0、2.0的矩形先验框。这样三种空间尺寸和三种宽高比,能够得到9个基础先验框。
基础先验框的具体代码实现如下:
def generate_anchor_base(base_size=16, wh_ratios=(0.5, 1.0, 2.0), anchor_spatial_scales=(8, 16, 32)) -> np.ndarray: """ 生成基础先验框->(x1, y1, x2, y2) :param base_size: 预设基础空间尺寸, 即特征图与原图的缩放比例, 表示映射回原图时的空间大小 :param wh_ratios: 锚框宽高比w/h取值 :param anchor_spatial_scales: 待生成正方形框锚与预设的最基本锚框空间尺度上的缩放比例 :return: 生成的锚框 """ # 默认锚框左上角为(0, 0)时计算预设锚框的中心点坐标 cx = cy = (base_size - 1) / 2.0 # 根据锚框宽高比取值个数M1和锚框空间尺度缩放取值数量M2, 生成M2组面积基本相同但宽高比例不同的基础锚框, 共N个(N=M1*M2) # 假设wh_ratios=(0.5, 1.0, 2.0)三种取值, anchor_scales=(8, 16, 32)三种取值, 那么生成的基础锚框有9种可能取值 num_anchor_base = len(wh_ratios) * len(anchor_spatial_scales) # 生成[N, 4]维的基础锚框 anchor_base = np.zeros((num_anchor_base, 4), dtype=np.float32) # 根据锚框面积计算锚框宽和高 # 锚框面积s=w*h, 而wh_ration=w/h, 则s=h*h*wh_ratio, 在已知面积和宽高比时: h=sqrt(s/wh_ratio) # 同样可得s=w*w/wh_ratio, 在已知面积和宽高比时: w=sqrt(s*wh_ratio) # 计算不同宽高比、不同面积大小的锚框 for i in range(len(wh_ratios)): # 遍历空间尺度缩放比例 for j in range(len(anchor_spatial_scales)): # 预设框面积为s1=base_size^2, 经空间尺度缩放后为s2=(base_size*anchor_spatial_scale)^2 # 将s2带入上述锚框宽和高计算过程可求w和h值 h = base_size * anchor_spatial_scales[j] / np.sqrt(wh_ratios[i]) w = base_size * anchor_spatial_scales[j] * np.sqrt(wh_ratios[i]) idx = i * len(anchor_spatial_scales) + j anchor_base[idx, 0] = cx - (w - 1) / 2.0 anchor_base[idx, 1] = cy - (h - 1) / 2.0 anchor_base[idx, 2] = cx + (w - 1) / 2.0 anchor_base[idx, 3] = cy + (h - 1) / 2.0 return anchor_base
运行此代码,可以生成9个基础先验框,这些框中的值都是映射回原图后相对于(0,0)的坐标值
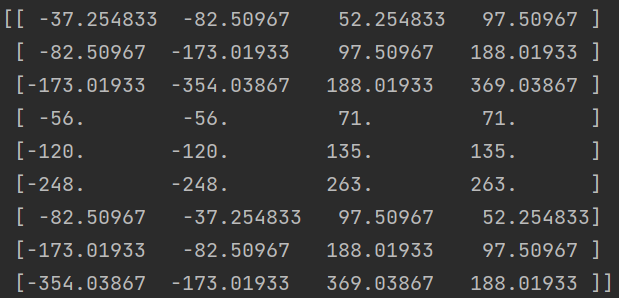
先验框是基于特征图上每个位置来生成的,特征图有多上个点,就需要生成多少个先验框。在上述9个基准先验框的基础上,可以通过坐标偏移来获取全图的先验框,具体实现方法如下:
def generate_shifted_anchors(anchor_base: np.ndarray, fstep: int, fw: int, fh: int) -> np.ndarray: """ 根据基础先验框, 在特征图上逐像素生成输入图像对应的先验框 :param anchor_base: 预生成的基础先验框->[num_anchor_base, 4], 列坐标对应[x1, y1, x2, y2] :param fstep: 每个特征点映射回原图后在原图上的步进, 也就是空间缩放比例 :param fw: 特征图像宽度 :param fh: 特征图像高度 :return: 生成的全图先验框->[num_anchor_base * fw * fh, 4], 列坐标对应[x1, y1, x2, y2] """ # 特征图上每个点都会生成anchor, 第一个特征点对应原图上的先验框就是anchor_base, 由于特征图与原图间空间缩放, 相邻两特征点对应的anchor在原图上的步进为图像空间缩放尺度大小fstep # 因此由anchor_base和anchor间步进, 可以计算出输入图像的所有anchor # 计算出原图每一行上anchor与anchor_base的位置偏移值取值 shift_x = np.arange(0, fw * fstep, fstep) # 计算出原图每一列上anchor与anchor_base的位置偏移值取值 shift_y = np.arange(0, fh * fstep, fstep) # 用两方向偏移值生成网格, x和y方向偏移值维度均为[fh, fw], shift_x/shift_y相同位置的两个值表示当前anchor相对于anchor_base的坐标偏移值 shift_x, shift_y = np.meshgrid(shift_x, shift_y) # 将shift_x/shift_y展开成一维并按列拼接在一起, 分别对应anchor的x1/y1/x2/y2的坐标偏移值, 构成偏移值矩阵 shift = np.stack([shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel()], axis=1) # anchor_base维度为[num_anchor_base, 4], 偏移值矩阵shift维度为[fw * fh, 4] # 将anchor_base每一行与shift中每一行元素相加即得到位置偏移后的所有anchor坐标, 但二者维度不同需进行扩展 num_anchor_base = anchor_base.shape[0] num_points = shift.shape[0] # 将两者均扩展为[num_points, num_anchors, 4] anchor_base_extend = np.repeat(a=anchor_base[np.newaxis, :, :], repeats=num_points, axis=0) shift_extend = np.repeat(a=shift[:, np.newaxis, :], repeats=num_anchor_base, axis=1) # 获取最终anchors坐标, 并展开成二维向量, 维度为[num_anchors * num_points, 4] = [num_anchors * fw * fh, 4] anchors = anchor_base_extend + shift_extend anchors = np.reshape(a=anchors, newshape=(-1, 4)) return anchors
2.2 前景判断与偏移值计算
特征图进入RPN网络后会先经过一个3*3卷积,进一步集中特征信息,之后分别流向分类分支和回归分支。
在分类分支中,输入特征(预设512通道)经过1*1卷积后,变成18通道特征,维度为[num,18,fh,fw]。其中num为输入图像数量,fh和fw为特征图高和宽。之所以设计为18通道,是因为每个特征点生成了9个形状大小不一的anchors,每个anchors有前景和背景两种可能,所以每个特征点对应的anchors有18种结果。这样18通道和18种结果相互对应,经过后面softmax处理后,能够根据置信度挑选出目标区域。之后通过reshape操作,经过[num,num_anchor_base * 2,fh,fw]→[num,fh,fw,num_anchor_base * 2]→[num,fh * fw * num_anchor_base,2]的维度变换,能够使分类结果更便于后续使用。

同理,在回归分支中,输入特征经过1*1卷积后,变成36通道特征,维度为[num,36,fh,fw]。其中36对应每个位置9个先验框,每个先验框有4个坐标值。为了后续使用方便,本文工程实现过程中也对结果进行了[num,num_anchor_base * 4,fh,fw]→[num,fh,fw,num_anchor_base * 4]→[num,fh * fw * num_anchor_base,4]的维度变换。

前景判断和偏移值计算部分代码如下:
# rpn网络的3*3卷积, 目的是对输入feature map进行卷积, 进一步集中特征信息 self.conv = nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=(3, 3), stride=(1, 1), padding=1) # rpn网络分类分支, 逐像素对特征图上anchor进行分类(每个anchor对应前景/背景两类, 每个类别为一个通道, 总通道数为num_anchor_base * 2) self.classifier = nn.Conv2d(in_channels=mid_channels, out_channels=num_anchor_base * 2, kernel_size=(1, 1), stride=(1, 1), padding=0) # rpn网络回归分支, 逐像素对特征图上anchor进行坐标回归(每个框对应四个坐标值, 每个坐标为一个通道, 总通道数为num_anchor_base * 4) self.regressor = nn.Conv2d(in_channels=mid_channels, out_channels=num_anchor_base * 4, kernel_size=(1, 1), stride=(1, 1), padding=0) self.relu = nn.ReLU() self.softmax = nn.Softmax(dim=-1)
num, chans, fh, fw = x.size() # 先将输入图像特征经过3*3网络, 进一步特征处理用于后续分类和回归 x = self.conv(x) x = self.relu(x) # 将特征图送入分类网络, 计算特征图上每个像素的分类结果, 对应原输入图像所有先验框的分类结果, 维度为[num, num_anchor_base * 2, fh, fw] out_classifier = self.classifier(x) # 维度转换[num, num_anchor_base * 2, fh, fw]->[num, fh, fw, num_anchor_base * 2]->[num, fh * fw * num_anchor_base, 2] out_classifier = out_classifier.permute(0, 2, 3, 1).contiguous().view(num, -1, 2) # 将特征图送入回归网络, 计算特征图上每个像素的回归结果, 对应原输入图像所有先验框的回归结果, 维度为[num, num_anchor_base * 4, fh, fw] out_offsets = self.regressor(x) # 维度转换[num, num_anchor_base * 4, fh, fw]->[num, fh, fw, num_anchor_base * 4]->[num, fh * fw * num_anchor_base, 4] out_offsets = out_offsets.permute(0, 2, 3, 1).contiguous().view(num, -1, 4) # 将分类器输出转换为得分 out_scores = self.softmax(out_classifier) # out_scores[:, :, 1]表示存在目标的概率 out_scores = out_scores[:, :, 1].contiguous().view(num, -1)
2.3 目标区域过滤
按照上述流程能够在一幅图像上提取到大量先验框。假设图像缩放值[640, 800]后输入VGG16网络,经过特征提取后,其尺寸变为[40,50],那么能够得到40*50*9=18000个先验框,但是这些先验框存在三个问题,一是部分框坐标超出原图像范围,二是很多框内不存在待检测目标,三是这些框存在大量重叠,因此需要对其进一步过滤筛选。具体过滤流程依次为以下几个步骤:
- 利用2.2中计算出的偏移值offsets对2.1中计算出的先验框anchors位置进行修正,计算位置校正后的anchors;
- 剔除超出图像边界范围的anchors;
- 限定最小尺寸min_size,剔除尺寸过小的anchors;
- 根据2.2中前景得分对anchors进行降序排列,保留得分最高前N个anchors;
- 对最后保留的N个anchors进行nms非极大值抑制,保留的rois作为过滤后的目标区域
本文中目标区域过滤采用ProposalCreator来实现,代码如下:
class ProposalCreator: # 对每一幅图像, 利用偏移值对所有先验框进行位置矫正得到目标建议框, 再通过尺寸限制/得分限制/nms方法对目标建议框进行过滤, 获得推荐区域, 即每幅图像的roi区域 def __init__(self, nms_thresh=0.7, num_samples_train=(12000, 2000), num_samples_test=(6000, 300), min_size=16, train_flag=False): """ 初始化推荐区域生成器, 为每幅图像生成满足尺寸要求、得分要求、nms要求的规定数量推荐框 :param nms_thresh: 非极大值抑制阈值 :param num_samples_train: 训练过程非极大值抑制前后待保留的样本数 :param num_samples_test: 测试过程非极大值抑制步骤前后待保留的样本数 :param min_size: 边界框最小宽高限制 :param train_flag: 模型训练还是测试 """ self.train_flag = train_flag self.nms_thresh = nms_thresh self.num_samples_train = num_samples_train self.num_samples_test = num_samples_test self.min_size = min_size @staticmethod def calc_bboxes_from_offsets(offsets: Tensor, anchors: Tensor, eps=1e-5) -> Tensor: """ 由图像特征计算的偏移值offsets对rpn产生的先验框位置进行修正 :param offsets: 偏移值矩阵->[n, 4], 列对应[x1, y1, x2, y2]的偏移值 :param anchors: 先验框矩阵->[n, 4], 列坐标对应[x1, y1, x2, y2] :param eps: 极小值, 防止乘以0或者负数 :return: 目标坐标矩阵->[n, 4], 对应[x1, y1, x2, y2] """ eps = torch.tensor(eps).type_as(offsets) targets = torch.zeros_like(offsets, dtype=torch.float32) # 计算目标真值框中心点坐标及长宽 anchors_h = anchors[:, 3] - anchors[:, 1] + 1 anchors_w = anchors[:, 2] - anchors[:, 0] + 1 anchors_cx = 0.5 * (anchors[:, 2] + anchors[:, 0]) anchors_cy = 0.5 * (anchors[:, 1] + anchors[:, 3]) anchors_w = torch.maximum(anchors_w, eps) anchors_h = torch.maximum(anchors_h, eps) # 将偏移值叠加到真值上计算anchors的中心点和宽高 targets_w = anchors_w * torch.exp(offsets[:, 2]) targets_h = anchors_h * torch.exp(offsets[:, 3]) targets_cx = anchors_cx + offsets[:, 0] * anchors_w targets_cy = anchors_cy + offsets[:, 1] * anchors_h targets[:, 0] = targets_cx - 0.5 * (targets_w - 1) targets[:, 1] = targets_cy - 0.5 * (targets_h - 1) targets[:, 2] = targets_cx + 0.5 * (targets_w - 1) targets[:, 3] = targets_cy + 0.5 * (targets_h - 1) return targets def __call__(self, offsets: Tensor, anchors: Tensor, scores: Tensor, im_size: tuple, scale: float = 1.0) -> Tensor: """ 利用回归器偏移值/全图先验框/分类器得分生成满足条件的推荐区域 :param offsets: 偏移值->[fw * fh * num_anchor_base, 4], 列坐标对应[x1, y1, x2, y2] :param anchors: 全图先验框->[fw * fh * num_anchor_base, 4], 列坐标对应[x1, y1, x2, y2] :param scores: 目标得分->[fw * fh * num_anchor_base] :param im_size: 原始输入图像大小 (im_height, im_width) :param scale: scale和min_size一起控制先验框最小尺寸 :return: 经过偏移值矫正及过滤后保留的目标建议框, 维度[num_samples_after_nms, 4]列坐标对应[x1, y1, x2, y2] """ # 设置nms过程前后需保留的样本数量, 注意训练和测试过程保留的样本数量不一致 if self.train_flag: num_samples_before_nms, num_samples_after_nms = self.num_samples_train else: num_samples_before_nms, num_samples_after_nms = self.num_samples_test im_height, im_width = im_size # 利用回归器计算的偏移值对全图先验框位置进行矫正, 获取矫正后的目标先验框坐标 targets = self.calc_bboxes_from_offsets(offsets=offsets, anchors=anchors) # 对目标目标先验框坐标进行限制, 防止坐标落在图像外 # 保证0 <= [x1, x2] <= cols - 1 targets[:, [0, 2]] = torch.clip(targets[:, [0, 2]], min=0, max=im_width - 1) # 0 <= [y1, y2] <= rows - 1 targets[:, [1, 3]] = torch.clip(targets[:, [1, 3]], min=0, max=im_height - 1) # 利用min_size和scale控制先验框尺寸下限, 移除尺寸太小的目标先验框 min_size = self.min_size * scale # 计算目标先验框宽高 targets_w = targets[:, 2] - targets[:, 0] + 1 targets_h = targets[:, 3] - targets[:, 1] + 1 # 根据宽高判断框是否有效, 挑选出有效边界框和得分 is_valid = (targets_w >= min_size) & (targets_h >= min_size) targets = targets[is_valid] scores = scores[is_valid] # 利用区域目标得分对目标先验框数量进行限制 # 对目标得分进行降序排列, 获取降序索引 descend_order = torch.argsort(input=scores, descending=True) # 在nms之前, 选取固定数量得分稍高的目标先验框 if num_samples_before_nms > 0: descend_order = descend_order[:num_samples_before_nms] targets = targets[descend_order] scores = scores[descend_order] # 利用非极大值抑制限制边界框数量 keep = nms(boxes=targets, scores=scores, iou_threshold=self.nms_thresh) # 如果数量不足则随机抽取, 用于填补不足 if len(keep) < num_samples_after_nms: random_indexes = np.random.choice(a=range(len(keep)), size=(num_samples_after_nms - len(keep)), replace=True) keep = torch.concat([keep, keep[random_indexes]]) # 在nms后, 截取固定数量边界框, 即最终生成的roi区域 keep = keep[:num_samples_after_nms] targets = targets[keep] return targets
上述代码利用num_samples_train和num_samples_test来控制训练与预测过程中的rois数量。训练过程中每幅图像生成2000个roi区域,预测过程中每幅图像生成300个roi区域。
2.4 RPN实现
本文中RPN网络整体结构由RegionProposalNet来定义实现,具体代码如下:
class RegionProposalNet(nn.Module): # rpn推荐区域生成网络, 获取由图像特征前向计算得到的回归器偏移值/分类器结果, 以及经过偏移值矫正后的roi区域/roi对应数据索引/全图先验框 def __init__(self, in_channels=512, mid_channels=512, feature_stride=16, wh_ratios=(0.5, 1.0, 2.0), anchor_spatial_scales=(8, 16, 32), train_flag=False): super(RegionProposalNet, self).__init__() # 特征点步长, 即特征提取网络的空间尺度缩放比例, 工程中vgg16网络使用了4层2*2的MaxPool, 故取值为16 self.feature_stride = feature_stride # 推荐框生成器: 对全图先验框进行位置矫正和过滤, 提取位置矫正后的固定数量的目标推荐框 self.create_proposals = ProposalCreator(train_flag=train_flag) # 根据宽高比和空间尺度比例, 生成固定数量的基础先验框 self.anchor_base = self.generate_anchor_base(wh_ratios=wh_ratios, anchor_spatial_scales=anchor_spatial_scales) num_anchor_base = len(wh_ratios) * len(anchor_spatial_scales) # rpn网络的3*3卷积, 目的是对输入feature map进行卷积, 进一步集中特征信息 self.conv = nn.Conv2d(in_channels=in_channels, out_channels=mid_channels, kernel_size=(3, 3), stride=(1, 1), padding=1) # rpn网络分类分支, 逐像素对特征图上anchor进行分类(每个anchor对应前景/背景两类, 每个类别为一个通道, 总通道数为num_anchor_base * 2) self.classifier = nn.Conv2d(in_channels=mid_channels, out_channels=num_anchor_base * 2, kernel_size=(1, 1), stride=(1, 1), padding=0) # rpn网络回归分支, 逐像素对特征图上anchor进行坐标回归(每个框对应四个坐标值, 每个坐标为一个通道, 总通道数为num_anchor_base * 4) self.regressor = nn.Conv2d(in_channels=mid_channels, out_channels=num_anchor_base * 4, kernel_size=(1, 1), stride=(1, 1), padding=0) self.relu = nn.ReLU() self.softmax = nn.Softmax(dim=-1) # 权重初始化 nn.init.kaiming_normal_(self.conv.weight) nn.init.constant_(self.conv.bias, 0.0) nn.init.kaiming_normal_(self.classifier.weight) nn.init.constant_(self.classifier.bias, 0.0) nn.init.kaiming_normal_(self.regressor.weight) nn.init.constant_(self.regressor.bias, 0.0) @staticmethod def generate_anchor_base(base_size=16, wh_ratios=(0.5, 1.0, 2.0), anchor_spatial_scales=(8, 16, 32)) -> np.ndarray: """ 生成基础先验框->(x1, y1, x2, y2) :param base_size: 预设的最基本的正方形锚框边长 :param wh_ratios: 锚框宽高比w/h取值 :param anchor_spatial_scales: 待生成正方形框锚与预设的最基本锚框空间尺度上的缩放比例 :return: 生成的锚框 """ # 默认锚框左上角为(0, 0)时计算预设锚框的中心点坐标 cx = cy = (base_size - 1) / 2.0 # 根据锚框宽高比取值个数M1和锚框空间尺度缩放取值数量M2, 生成M2组面积基本相同但宽高比例不同的基础锚框, 共N个(N=M1*M2) # 假设wh_ratios=(0.5, 1.0, 2.0)三种取值, anchor_scales=(8, 16, 32)三种取值, 那么生成的基础锚框有9种可能取值 num_anchor_base = len(wh_ratios) * len(anchor_spatial_scales) # 生成[N, 4]维的基础锚框 anchor_base = np.zeros((num_anchor_base, 4), dtype=np.float32) # 根据锚框面积计算锚框宽和高 # 锚框面积s=w*h, 而wh_ration=w/h, 则s=h*h*wh_ratio, 在已知面积和宽高比时: h=sqrt(s/wh_ratio) # 同样可得s=w*w/wh_ratio, 在已知面积和宽高比时: w=sqrt(s*wh_ratio) # 计算不同宽高比、不同面积大小的锚框 for i in range(len(wh_ratios)): # 遍历空间尺度缩放比例 for j in range(len(anchor_spatial_scales)): # 预设框面积为s1=base_size^2, 经空间尺度缩放后为s2=(base_size*anchor_spatial_scale)^2 # 将s2带入上述锚框宽和高计算过程可求w和h值 h = base_size * anchor_spatial_scales[j] / np.sqrt(wh_ratios[i]) w = base_size * anchor_spatial_scales[j] * np.sqrt(wh_ratios[i]) idx = i * len(anchor_spatial_scales) + j anchor_base[idx, 0] = cx - (w - 1) / 2.0 anchor_base[idx, 1] = cy - (h - 1) / 2.0 anchor_base[idx, 2] = cx + (w - 1) / 2.0 anchor_base[idx, 3] = cy + (h - 1) / 2.0 return anchor_base @staticmethod def generate_shifted_anchors(anchor_base: np.ndarray, fstep: int, fw: int, fh: int) -> np.ndarray: """ 根据基础先验框, 在特征图上逐像素生成输入图像对应的先验框 :param anchor_base: 预生成的基础先验框->[num_anchor_base, 4], 列坐标对应[x1, y1, x2, y2] :param fstep: 每个特征点映射回原图后在原图上的步进, 也就是空间缩放比例 :param fw: 特征图像宽度 :param fh: 特征图像高度 :return: 生成的全图先验框->[num_anchor_base * fw * fh, 4], 列坐标对应[x1, y1, x2, y2] """ # 特征图上每个点都会生成anchor, 第一个特征点对应原图上的先验框就是anchor_base, 由于特征图与原图间空间缩放, 相邻两特征点对应的anchor在原图上的步进为图像空间缩放尺度大小fstep # 因此由anchor_base和anchor间步进, 可以计算出输入图像的所有anchor # 计算出原图每一行上anchor与anchor_base的位置偏移值取值 shift_x = np.arange(0, fw * fstep, fstep) # 计算出原图每一列上anchor与anchor_base的位置偏移值取值 shift_y = np.arange(0, fh * fstep, fstep) # 用两方向偏移值生成网格, x和y方向偏移值维度均为[fh, fw], shift_x/shift_y相同位置的两个值表示当前anchor相对于anchor_base的坐标偏移值 shift_x, shift_y = np.meshgrid(shift_x, shift_y) # 将shift_x/shift_y展开成一维并按列拼接在一起, 分别对应anchor的x1/y1/x2/y2的坐标偏移值, 构成偏移值矩阵 shift = np.stack([shift_x.ravel(), shift_y.ravel(), shift_x.ravel(), shift_y.ravel()], axis=1) # anchor_base维度为[num_anchor_base, 4], 偏移值矩阵shift维度为[fw * fh, 4] # 将anchor_base每一行与shift中每一行元素相加即得到位置偏移后的所有anchor坐标, 但二者维度不同需进行扩展 num_anchor_base = anchor_base.shape[0] num_points = shift.shape[0] # 将两者均扩展为[num_points, num_anchors, 4] anchor_base_extend = np.repeat(a=anchor_base[np.newaxis, :, :], repeats=num_points, axis=0) shift_extend = np.repeat(a=shift[:, np.newaxis, :], repeats=num_anchor_base, axis=1) # 获取最终anchors坐标, 并展开成二维向量, 维度为[num_anchors * num_points, 4] = [num_anchors * fw * fh, 4] anchors = anchor_base_extend + shift_extend anchors = np.reshape(a=anchors, newshape=(-1, 4)) return anchors def forward(self, x: Tensor, im_size: tuple, scale: float = 1.0) -> Tuple[Tensor, Tensor, Tensor, Tensor, Tensor]: """ 前向处理, 获取rpn网络的回归器输出/分类器输出/矫正的roi区域/roi数据索引/全图先验框 :param x: 由原图提取的输入特征图feature_map->[num, 512, fh, fw] :param im_size: 原始输入图像尺寸->[im_width, im_height] :param scale: 与min_size一起用于控制最小先验框尺寸 :return: list->[回归器输出, 分类器输出, 建议框, 建议框对应的数据索引, 全图先验框] """ num, chans, fh, fw = x.size() # 先将输入图像特征经过3*3网络, 进一步特征处理用于后续分类和回归 x = self.conv(x) x = self.relu(x) # 将特征图送入分类网络, 计算特征图上每个像素的分类结果, 对应原输入图像所有先验框的分类结果, 维度为[num, num_anchor_base * 2, fh, fw] out_classifier = self.classifier(x) # 维度转换[num, num_anchor_base * 2, fh, fw]->[num, fh, fw, num_anchor_base * 2]->[num, fh * fw * num_anchor_base, 2] out_classifier = out_classifier.permute(0, 2, 3, 1).contiguous().view(num, -1, 2) # 将特征图送入回归网络, 计算特征图上每个像素的回归结果, 对应原输入图像所有先验框的回归结果, 维度为[num, num_anchor_base * 4, fh, fw] out_offsets = self.regressor(x) # 维度转换[num, num_anchor_base * 4, fh, fw]->[num, fh, fw, num_anchor_base * 4]->[num, fh * fw * num_anchor_base, 4] out_offsets = out_offsets.permute(0, 2, 3, 1).contiguous().view(num, -1, 4) # 将分类器输出转换为得分 out_scores = self.softmax(out_classifier) # out_scores[:, :, 1]表示存在目标的概率 out_scores = out_scores[:, :, 1].contiguous().view(num, -1) # 生成全图先验框, 每个特征点都会生成num_anchor_base个先验框, 故全图生成的先验框维度为[fh * fw * num_anchor_base, 4] anchors = self.generate_shifted_anchors(anchor_base=self.anchor_base, fstep=self.feature_stride, fw=fw, fh=fh) # 将anchors转换到和out_offsets的数据类型(float32)和设备类型(cuda/cpu)一致 anchors = torch.tensor(data=anchors).type_as(out_offsets) # 获取batch数据的roi区域和对应的索引 rois, rois_idx = [], [] # 遍历batch中每个数据 for i in range(num): # 按照数据索引获取当前数据对应的偏移值和得分, 生成固定数量的推荐区域, 维度为[fixed_num, 4] proposals = self.create_proposals(offsets=out_offsets[i], anchors=anchors, scores=out_scores[i], im_size=im_size, scale=scale) # 创建和推荐区域proposals数量相同的batch索引, 维度为[fixed_num] batch_idx = torch.tensor([i] * len(proposals)) # 将推荐区域和索引进行维度扩展后放入列表中, 扩展后二者维度分别为[1 ,fixed_num, 4]和[[1 ,fixed_num]] rois.append(proposals.unsqueeze(0)) rois_idx.append(batch_idx.unsqueeze(0)) # 将rois列表中所有张量沿0维拼接在一起. 原rois列表长度为num, 其中每个张量均为[1, fixed_num, 4], 拼接后rois张量维度为[num, fixed_num, 4] rois = torch.cat(rois, dim=0).type_as(x) # 将rois索引拼接在一起, 拼接后维度为[num, fixed_num] rois_idx = torch.cat(rois_idx, dim=0).to(x.device) return out_offsets, out_classifier, rois, rois_idx, anchors
3. ROI Pooling与Classifier
RPN网络获得的rois目标区域,其大小并不是固定的,对应到特征图上也就是不同尺寸。但后续区域分类和位置回归需要输入固定大小特征数据进入全连接网络,所以需要对每个roi区域提取的特征进行尺寸缩放,使其变换为同一大小。此外,经过ROI Pooling后,获得的区域池化特征pool_features又有两个流向,一是进行边界框位置预测,二是进行目标类别判断。
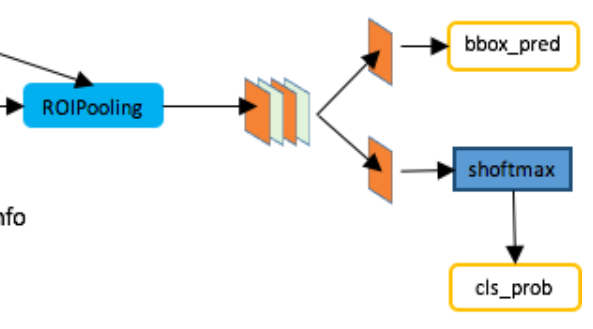
注意,Classifier与RPN都包含分类和回归两个分支,虽然这两部分结构共享卷积特征feature map,有助于减少计算量并提高检测速度,但二者仍具有明显的区别:
- 结构不同:RPN中分类和回归分支是利用卷积,用对用通道表示分类和回归结果,Classifier使用全连接结果来表示分类和回归结果;
- 任务不同:RPN中分类分支负责对生成的anchor进行二分类,判断其是前景还是背景,任务相对简单,目的是筛选出可能包含目标物体的proposals。回归分支则负责对这些anchor的位置进行微调,使其更接近于真实的目标边界框,关注的是对候选区域位置的初步修正。Classifier中的分类分支需要对RPN网络筛选出的候选区域进行多类别分类,确定每个区域具体属于哪个物体类别,任务更复杂。同时,Classifier中的回归分支则负责对候选区域的位置进行进一步的精细调整,以获得更准确的目标定位,关注的是对目标物体位置的精确预测。
本文中采用ROIHead来实现ROI Pooling与Classifier,代码如下:
class ROIHead(nn.Module): def __init__(self, num_classes: int, pool_size: int, linear: nn.Module, spatial_scale: float = 1.0): """ 将ROI区域送入模型获得分类器输出和回归器输出 :param num_classes: 样本类别数 :param pool_size: roi池化目标尺寸 :param linear: 线性模型 :param spatial_scale: roi池化所使用的空间比例, 默认1.0, 若待处理的roi坐标为原图坐标, 则此处需要设置spatial_scale=目标特征图大小/原图大小 """ super(ROIHead, self).__init__() self.linear = linear # 对roi_pool结果进行回归预测 self.regressor = nn.Linear(4096, num_classes * 4) self.classifier = nn.Linear(4096, num_classes) nn.init.kaiming_normal_(self.regressor.weight) nn.init.kaiming_normal_(self.classifier.weight) # 后续采用的roi坐标为特征图上坐标, 因此spatial_scale直接设置为1.0即可 # 注意roi_pool要求roi坐标满足格式[x1, y1, x2, y2] self.roi_pool = RoIPool(output_size=(pool_size, pool_size), spatial_scale=spatial_scale) def forward(self, x: Tensor, rois: Tensor, rois_idx: Tensor, im_size: Tensor) -> Tuple[Tensor, Tensor]: """ 根据推荐框对特征图进行roi池化, 并将结果送入分类器和回归器, 得到相应结果 :param x: 输入batch数据对应的全图图像特征, 维度为[num, 512, fh, fw] :param rois: 输入batch数据对应的rois区域, 维度为[num, num_samples, 4], 顺序为[y1, x1, y2, x2] :param rois_idx: 输入batch数据对应的rois区域索引, 维度为[num, num_samples] :param im_size: 原始输入图像尺寸, 维度为[im_height, im_width] :return: 分类模型和回归模型结果 """ num, chans, fh, fw = x.size() im_height, im_width = im_size # 将一个batch内数据的推荐区域展开堆叠在一起, 维度变为[num * num_samples, 4] rois = torch.flatten(input=rois, start_dim=0, end_dim=1) # 将一个batch内数据的索引展开堆叠在一起, 维度变为[num * num_samples] rois_idx = torch.flatten(input=rois_idx, start_dim=0, end_dim=1) # 计算原图roi区域映射到特征图后对应的边界框位置, 维度为[num * num_samples, 4] rois_on_features = torch.zeros_like(rois) # 计算[x1, x2]映射后的坐标 rois_on_features[:, [0, 2]] = rois[:, [0, 2]] * (fw / im_width) # 计算[y1, y2]映射后的坐标 rois_on_features[:, [1, 3]] = rois[:, [1, 3]] * (fh / im_height) # 将特征图上roi区域和对应的数据索引在列方向进行拼接, 得到[num * num_samples, 5]维张量, 用于后续roi_pool, 列对应[idx, x1, y1, x2, y2] fidx_and_rois = torch.cat([rois_idx.unsqueeze(1), rois_on_features], dim=1) # 根据数据idx和推荐框roi对输入图像特征图进行截取 # 注意由于rois_on_features中roi坐标已经缩放到了特征图大小, 所以RoIPool池化时的spatial_scale需要设置为1.0 # 注意此处roi_pool需要num * num_samples, 5]维, 根据第0列的idx取x中截取相应的特征进行池化 pool_features = self.roi_pool(x, fidx_and_rois) # 上面获取的池化特征维度为[num * num_samples, chans, pool_size, pool_size], 将其展开为[num * num_samples, chans * pool_size * pool_size]以便送入分类和回归网络 pool_features = pool_features.view(pool_features.size(0), -1) # 利用线性层进行特征进一步浓缩 linear_features = self.linear(pool_features) # 将样本特征送入回归器, 得到各样本输出, 维度为[num * num_samples, 4 * num_classes] rois_out_regressor = self.regressor(linear_features) # 将样本特征送入回归器, 得到各样本输出, 维度为[num * num_samples, num_classes] rois_out_classifier = self.classifier(linear_features) # 维度变换, 获得当前batch中每个数据的所有回归结果, 维度为[num, num_samples, 4 * num_classes] rois_out_regressor = rois_out_regressor.view(num, -1, rois_out_regressor.size(1)) # 维度变换, 获得当前batch中每个数据的所有分类结果, 维度为[num, num_samples, num_classes] rois_out_classifier = rois_out_classifier.view(num, -1, rois_out_classifier.size(1)) return rois_out_regressor, rois_out_classifier
4. Faster RCNN代码
由上可知,本文中Faster RCNN包含backbone、RPN、ROI Head三大主体结构,其具体代码实现如下:
class FasterRCNN(nn.Module): def __init__(self, num_classes, train_flag=False, feature_stride=16, anchor_spatial_scales=(8, 16, 32), wh_ratios=(0.5, 1.0, 2.0), pretrained=False): """ 初始化Faster R-CNN :param num_classes: 最终分类类别数, 包含背景0和目标类别数 :param train_flag: 是否为训练过程 :param feature_stride: 特征步进, 实际就是特征提取器的空间缩放比例, 工程使用移除最后一个池化层的vgg16, 特征空间缩放比例为16 :param anchor_spatial_scales: 待生成先验框与基本先验框的边长比值 :param wh_ratios: 待生成先验框的宽高比 :param pretrained: 特征提取器是否加载预训练参数 """ super(FasterRCNN, self).__init__() self.feature_stride = feature_stride self.extractor, linear = backbone(pretrained=pretrained) self.rpn = RegionProposalNet(in_channels=512, mid_channels=512, feature_stride=feature_stride, wh_ratios=wh_ratios, anchor_spatial_scales=anchor_spatial_scales, train_flag=train_flag) self.head = ROIHead(num_classes=num_classes, pool_size=POOL_SIZE, spatial_scale=1, linear=linear) def forward(self, x, scale: float = 1.0, mode: str = "forward"): """ Faster R-CNN前向过程 :param x: 输入 :param scale: rpn结构中用于控制最小先验框尺寸 :param mode: 处理流程控制字符串 :return: """ if mode == "forward": im_size = x.size()[-2:] # 提取输入图像特征 im_features = self.extractor(x) # 获取建议框 _, _, rois, rois_idx, _ = self.rpn(im_features, im_size, scale) # 根据图像特征和建议框计算偏移值回归结果和区域分类结果 rois_out_regressor, rois_out_classifier = self.head(im_features, rois, rois_idx, im_size) return rois_out_regressor, rois_out_classifier, rois, rois_idx elif mode == "extractor": # 提取图像特征 im_features = self.extractor(x) return im_features elif mode == "rpn": im_features, im_size = x # 获取建议框 out_offsets, out_classes, rois, rois_idx, anchors = self.rpn(im_features, im_size, scale) return out_offsets, out_classes, rois, rois_idx, anchors elif mode == "head": im_features, rois, rois_idx, im_size = x # 获取分类和回归结果 rois_out_regressor, rois_out_classifier = self.head(im_features, rois, rois_idx, im_size) return rois_out_regressor, rois_out_classifier else: raise TypeError("Invalid parameter of mode, which must be in ['forward', 'extractor', 'rpn', 'head']")
至此,Faster RCNN网络结构实现基本完成,之后将开始模型训练和预测。
四、模型训练
本文Faster RCNN模型训练按照以下顺序进行:
- 计算输入batch图像数据特征im_features;
- 将im_features输入RPN网络,获取感兴趣区域rois并计算RPN网络分类和回归损失;
- 对im_features中感兴趣区域进行ROI Pooling,将结果送入Classifier计算rois对应的分类和回归损失;
- 计算整体损失并反向传播,优化网络参数。
1. 获取图像特征
输入图像经backbone的extractor(VGG16)进行多次卷积池化,可以得到输入批数据特征im_features,具体实现如下:
if step < train_batch_num: # 设置为训练模式 network.train() # 获取输入图像全图特征, 维度为[num, 512, im_height/16, im_width/16] im_features = network.forward(x=ims, mode="extractor")
2. RPN训练
2.1 RPN输出
将图像输入RPN网络后,可以获取rois以及RPN分类和回归输出,具体实现如下:
# 利用rpn网络获取回归器输出/分类器输出/batch数据对应建议框/建议框对应数据索引/全图先验框 rpn_offsets, rpn_classifier, rois, rois_idx, anchors = network.forward(x=[im_features, (im_height, im_width)], mode="rpn") np_anchors = anchors.cpu().numpy()
此处除了rois、rpn_offsets、rpn_classifier外,还保留了rois_idx和anchors结果。其中anchors是先验框,后续获取RPN网络分类和回归真值时需要使用,rois_idx存储的是每个roi区域对应的batch数据中的图片索引。
2.2 RPN真值
我们已经获得RPN分类和回归分支输出,训练网络需要损失函数,也就还需要得到对应真值。对于RPN分类分支,其真值对应的是每个anchor的标签,但实际我们只有每个图象上真实边界框gt_boxes对应的标签,我们肯定不能用gt_boxes标签来定义anchor标签,否则若一幅图上某个gt_box标签为1,那么所有anchor标签也为1,整幅图上所有位置都标记为1了,这显然是不合理的。应该如何来定义每个anchor对应的标签呢?具体方案如下:
- 剔除不在图像边界范围内的anchors;
- 计算anchors与gt_boxes的交并比iou;
- 寻找每个gt_box下iou最大时的anchor索引max_iou_idx_anchor,每个anchor对应iou最大时的gt_box索引max_iou_idx_gt以及当前anchor对应的iou最大值max_iou_values_anchor;
- 如果max_iou_values_anchor小于预设的负样本iou阈值negative_iou_thresh,表示当前anchor与所有gt_box重叠面积小,应置为背景(标签0);
- 对于max_iou_idx_anchor,表示与当前gt_box重叠最大的anchor索引,即最接近真实目标位置的anchor,应置为前景(标签1);
- 同样,如果max_iou_values_anchor大于预设的正样本iou阈值positive_iou_thresh,表示当前anchor与所有gt_box重叠面积大,应置为前景(标签1);
- 对于其他情况,统一将标签设置为-1,表示既不是正样本也不是负样本,不用于RPN网络训练;
- 获得的正负样本数量可能较大也可能数量不足,故还需要对其正负样本数量进行一定限制。
通过上面的方案获取了分类网络中anchors对应的标签labels,还需要获取回归网络anchors对应的偏移值真值offsets。上面我们已经求得每个anchor对应iou最大时的gt_box索引为max_iou_idx_gt,那么对应的这个gt_box就理应作为当前anchor的位置真值,据此能够获得偏移值作为RPN回归网络真值。
这个过程用AnchorCreator来定义实现,具体代码如下:
class AnchorCreator: # 生成先验框对应的标签及与真值框间的真实偏移值 def __init__(self, num_samples=256, positive_iou_thresh=0.7, negative_iou_thresh=0.3, positive_rate=0.5): """ 初始化anchor生成器 :param num_samples: 每帧图片上用于后续分类和回归任务的有效推荐区域总数 :param positive_iou_thresh: 正样本的IoU判定阈值 :param negative_iou_thresh: 负样本的判定阈值 :param positive_rate: 正样本所占样本总数的比例 """ self.num_samples = num_samples self.positive_iou_thresh = positive_iou_thresh self.negative_iou_thresh = negative_iou_thresh self.positive_rate = positive_rate @staticmethod def is_inside_anchors(anchors: Union[np.ndarray, Tensor], width: int, height: int) -> Union[np.ndarray, Tensor]: """ 获取图像内部的推荐框 :param anchors: 生成的所有推荐框->[x1, y1, x2, y2] :param width: 输入图像宽度 :param height: 输入图像高度 :return: 未超出图像边界的推荐框 """ is_inside = (anchors[:, 0] >= 0) & (anchors[:, 1] >= 0) & (anchors[:, 2] <= width - 1) & (anchors[:, 3] <= height - 1) return is_inside @staticmethod def calc_IoU(anchors: np.ndarray, gt_boxes: np.ndarray, method=1) -> np.ndarray: """ 计算推荐区域与真值的IoU :param anchors: 推荐区域边界框, [m, 4]维数组, 四列分别对应左上和右下两个点坐标[x1, y1, x2, y2] :param gt_boxes: 当前图像中所有真值边界框, [n, 4]维数组, 四列分别对应左上和右下两点坐标[x1, y1, x2, y2] :param method: iou计算方法 :return: iou, [m, n]维数组, 记录每个推荐区域与每个真值框的IoU结果 """ # 先判断维度是否符合要求 assert anchors.ndim == gt_boxes.ndim == 2, "anchors and ground truth bbox must be 2D array." assert anchors.shape[1] == gt_boxes.shape[1] == 4, "anchors and ground truth bbox must contain 4 values for 2 points." num_anchors, num_gts = anchors.shape[0], gt_boxes.shape[0] # 方法1: 利用for循环遍历求解交并比 if method == 0: iou = np.zeros((num_anchors, num_gts)) # anchor有m个, gt_box有n个, 遍历求出每个gt_box对应的iou结果即可 for idx in range(num_gts): gt_box = gt_boxes[idx] box_area = (anchors[:, 2] - anchors[:, 0]) * (anchors[:, 3] - anchors[:, 1]) gt_area = (gt_box[2] - gt_box[0]) * (gt_box[3] - gt_box[1]) inter_w = np.minimum(anchors[:, 2], gt_box[2]) - np.maximum(anchors[:, 0], gt_box[0]) inter_h = np.minimum(anchors[:, 3], gt_box[3]) - np.maximum(anchors[:, 1], gt_box[1]) inter = np.maximum(inter_w, 0) * np.maximum(inter_h, 0) union = box_area + gt_area - inter iou[:, idx] = inter / union # 方法2: 利用repeat对矩阵进行升维, 从而利用对应位置计算交并比 elif method == 1: # anchors维度为[m, 4], gt_boxes维度为[n, 4], 对二者通过repeat的方式都升维到[m, n, 4] anchors = np.repeat(anchors[:, np.newaxis, :], num_gts, axis=1) gt_boxes = np.repeat(gt_boxes[np.newaxis, :, :], num_anchors, axis=0) # 利用对应位置求解框面积 anchors_area = (anchors[:, :, 2] - anchors[:, :, 0]) * (anchors[:, :, 3] - anchors[:, :, 1]) gt_boxes_area = (gt_boxes[:, :, 2] - gt_boxes[:, :, 0]) * (gt_boxes[:, :, 3] - gt_boxes[:, :, 1]) # 求交集区域的宽和高 inter_w = np.minimum(anchors[:, :, 2], gt_boxes[:, :, 2]) - np.maximum(anchors[:, :, 0], gt_boxes[:, :, 0]) inter_h = np.minimum(anchors[:, :, 3], gt_boxes[:, :, 3]) - np.maximum(anchors[:, :, 1], gt_boxes[:, :, 1]) # 求交并比 inter = np.maximum(inter_w, 0) * np.maximum(inter_h, 0) union = anchors_area + gt_boxes_area - inter iou = inter / union # 方法3: 利用np函数的广播机制求结果而避免使用循环 else: # 计算anchors和gt_boxes左上角点的最大值, 包括两x1坐标最大值和y1坐标最大值 # 注意anchors[:, None, :2]会增加一个新维度, 维度为[m, 1, 2], gt_boxes[:, :2]维度为[n, 2], maximum计算最大值时会将二者都扩展到[m, n, 2] max_left_top = np.maximum(anchors[:, None, :2], gt_boxes[:, :2]) # 计算anchors和gt_boxes右下角点的最小值, 包括两x2坐标最大值和y2坐标最大值, 同上也用到了广播机制 min_right_bottom = np.minimum(anchors[:, None, 2:], gt_boxes[:, 2:]) # 求交集面积和并集面积 # min_right_bottom - max_left_top维度为[m, n, 2], 后两列代表交集区域的宽和高 # 用product进行两列元素乘积求交集面积, 用(max_left_top < min_right_bottom).all(axis=2)判断宽和高是否大于0, 结果维度为[m, n] inter = np.product(min_right_bottom - max_left_top, axis=2) * (max_left_top < min_right_bottom).all(axis=2) # 用product进行两列元素乘积求每个anchor的面积, 结果维度维[m] anchors_area = np.product(anchors[:, 2:] - anchors[:, :2], axis=1) # 用product进行两列元素乘积求每个gt_box的面积, 结果维度维[n] gt_boxes_area = np.product(gt_boxes[:, 2:] - gt_boxes[:, :2], axis=1) # anchors_area[:, None]维度维[m, 1], gt_boxes_area维度维[n], 二者先广播到[m, n]维度, 再和同纬度inter做减法计算, 结果维度维[m, n] union = anchors_area[:, None] + gt_boxes_area - inter iou = inter / union return iou @staticmethod def calc_max_iou_info(iou: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]: """ 利用iou结果计算出最大iou及其对应位置 :param iou: [m, n]维矩阵, 其中m为anchors数量, n为gt_boxes数量 :return: 每一列最大iou出现的行编号, 每一行最大iou出现的列编号, 每一行的最大iou结果 """ # 按列求每一列的iou最大值出现的行数, 即记录与每个gt_box的iou最大的anchor的行编号, 维度和gt_box个数相同, 为n(每个gt_box对应一个anchor与之iou最大) max_iou_idx_anchor = np.argmax(iou, axis=0) # 按行求每一行的iou最大值出现的列数, 即记录与每个anchor的iou最大的gt_box的列编号, 维度和anchor个数相同, 为m(每个anchor对应一个gt_box与之iou最大) max_iou_idx_gt = np.argmax(iou, axis=1) # 求每个anchor与所有gt_box的最大iou值 max_iou_values_anchor = np.max(iou, axis=1) return max_iou_idx_anchor, max_iou_idx_gt, max_iou_values_anchor def create_anchor_labels(self, anchors: np.ndarray, gt_boxes: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: """ 计算IoU结果并根据结果为每个推荐区域生成标签 :param anchors: 生成的有效推荐区域, 列坐标对应[x1, y1, x2, y2] :param gt_boxes: 真值框, 列坐标对应[x1, y1, x2, y2] :return: 每个推荐区域的最大iou对应的真值框编号, 推荐区域对应的标签 """ # 计算iou结果 iou = self.calc_IoU(anchors=anchors, gt_boxes=gt_boxes) # 计算行/列方向最大iou对应位置和值 max_iou_idx_anchor, max_iou_idx_gt, max_iou_values_anchor = self.calc_max_iou_info(iou=iou) # 先将所有label置为-1, -1表示不进行处理, 既不是正样本也不是负样本, 再根据iou判定正样本为1, 背景为0 labels = -1 * np.ones(anchors.shape[0], dtype="int") # max_iou_values_anchor为每一行最大的iou结果, 其值低于负样本阈值, 表明该行对应的anchor与所有gt_boxes的iou结果均小于阈值, 设置为负样本 labels[max_iou_values_anchor < self.negative_iou_thresh] = 0 # max_iou_idx_anchor为每一列iou最大值出现的行编号, 表明对应行anchor与某个gt_box的iou最大, iou最大肯定是设置为正样本 labels[max_iou_idx_anchor] = 1 # max_iou_values_anchor为每一行最大的iou结果, 其值大于正样本阈值, 表明该行对应的anchor与至少一个gt_box的iou结果大于阈值, 设置为正样本 labels[max_iou_values_anchor >= self.positive_iou_thresh] = 1 # 对正负样本数量进行限制 # 计算目标正样本数量 num_positive = int(self.num_samples * self.positive_rate) # 记录正样本行编号 idx_positive = np.where(labels == 1)[0] if len(idx_positive) > num_positive: size_to_rest = len(idx_positive) - num_positive # 从正样本编号中随机选取一定数量将标签置为-1 idx_to_reset = np.random.choice(a=idx_positive, size=size_to_rest, replace=False) labels[idx_to_reset] = -1 # 计算现有负样本数量 num_negative = self.num_samples - np.sum(labels == 1) # 记录负样本行编号 idx_negative = np.where(labels == 0)[0] if len(idx_negative) > num_negative: size_to_rest = len(idx_negative) - num_negative # 从负样本编号中随机选取一定数量将标签置为-1 idx_to_reset = np.random.choice(a=idx_negative, size=size_to_rest, replace=False) labels[idx_to_reset] = -1 return max_iou_idx_gt, labels @staticmethod def calc_offsets_from_bboxes(anchors: np.ndarray, target_boxes: np.ndarray, eps: float = 1e-5) -> np.ndarray: """ 计算推荐区域与真值间的位置偏移 :param anchors: 候选边界框, 列坐标对应[x1, y1, x2, y2] :param target_boxes: 真值, 列坐标对应[x1, y1, x2, y2] :param eps: 极小值, 防止除以0或者负数 :return: 边界框偏移值->[dx, dy, dw, dh] """ offsets = np.zeros_like(anchors, dtype="float32") # 计算anchor中心点坐标及长宽 anchors_h = anchors[:, 3] - anchors[:, 1] + 1 anchors_w = anchors[:, 2] - anchors[:, 0] + 1 anchors_cy = 0.5 * (anchors[:, 3] + anchors[:, 1]) anchors_cx = 0.5 * (anchors[:, 2] + anchors[:, 0]) # 计算目标真值框中心点坐标及长宽 targets_h = target_boxes[:, 3] - target_boxes[:, 1] + 1 targets_w = target_boxes[:, 2] - target_boxes[:, 0] + 1 targets_cy = 0.5 * (target_boxes[:, 3] + target_boxes[:, 1]) targets_cx = 0.5 * (target_boxes[:, 2] + target_boxes[:, 0]) # 限制anchor长宽防止小于0 anchors_w = np.maximum(anchors_w, eps) anchors_h = np.maximum(anchors_h, eps) # 计算偏移值 offsets[:, 0] = (targets_cx - anchors_cx) / anchors_w offsets[:, 1] = (targets_cy - anchors_cy) / anchors_h offsets[:, 2] = np.log(targets_w / anchors_w) offsets[:, 3] = np.log(targets_h / anchors_h) return offsets def __call__(self, im_width: int, im_height: int, anchors: np.ndarray, gt_boxes: np.ndarray) -> Tuple[np.ndarray, np.ndarray]: """ 利用真值框和先验框的iou结果为每个先验框打标签, 同时计算先验框和真值框对应的偏移值 :param im_width: 输入图像宽度 :param im_height: 输入图像高度 :param anchors: 全图先验框, 列坐标对应[x1, y1, x2, y2] :param gt_boxes: 真值框, 列坐标对应[x1, y1, x2, y2] :return: 先验框对应标签和应该产生的偏移值 """ num_anchors = len(anchors) # 获取有效的推荐区域, 其维度为[m], m <= num_anchors is_inside = self.is_inside_anchors(anchors=anchors, width=im_width, height=im_height) inside_anchors = anchors[is_inside] # 在有效先验框基础上, 获取每个先验框的最大iou对应的真值框编号和区域标签 max_iou_idx_gt, inside_labels = self.create_anchor_labels(anchors=inside_anchors, gt_boxes=gt_boxes) # 每个anchor都存在n个真值框, 选择最大iou对应的那个真值框作为每个anchor的目标框计算位置偏移 # gt_boxes维度为[n, 4], max_iou_idx_gt维度为[m], 从真值中挑选m次即得到与每个anchor的iou最大的真值框, 即所需目标框, 维度为[m, 4] target_boxes = gt_boxes[max_iou_idx_gt] inside_offsets = self.calc_offsets_from_bboxes(anchors=inside_anchors, target_boxes=target_boxes) # 上面的偏移值和labels都是在inside_anchors中求得, 现在将结果映射回全图 # 将所有标签先置为-1, 再将内部先验框标签映射回全图 labels = -1 * np.ones(num_anchors) labels[is_inside] = inside_labels # 将所有偏移值先置为0, 再将内部先验框偏移值映射回全图 offsets = np.zeros_like(anchors) offsets[is_inside] = inside_offsets return labels, offsets
在训练过程中通过遍历的方式,计算每张图片RPN中对应的真值,代码如下:
anchor_creator = AnchorCreator() # 遍历每一个数据的真值框/数据标签/rpn网络输出 for i in range(num): # 获取每张图像的真值框/标签/rpn生成的偏移值/rpn生成的分类输出 cur_gt_boxes = gt_boxes[i] cur_labels = labels[i] cur_rpn_offsets = rpn_offsets[i] cur_rpn_classifier = rpn_classifier[i] cur_rois = rois[i] np_cur_gt_boxes = cur_gt_boxes.clone().detach().cpu().numpy() np_cur_rois = cur_rois.clone().detach().cpu().numpy() np_cur_labels = cur_labels.clone().detach().cpu().numpy() # 根据当前图像真值框和先验框, 获取每个先验框标签以及图像经过rpn网络后应产生的偏移值作为真值 cur_gt_rpn_labels, cur_gt_rpn_offsets = anchor_creator(im_width=im_width, im_height=im_height, anchors=np_anchors, gt_boxes=np_cur_gt_boxes)
2.3 RPN损失
获得RPN输出和真值后,可以计算相应的损失值。RPN分为分类和回归两个任务,每个任务都需要进行计算。代码实现如下:
def multitask_loss(out_offsets: Tensor, out_classifier: Tensor, gt_offsets: Tensor, gt_labels: Tensor, alpha: float = 1.0) -> Tuple[Tensor, Tensor, Tensor]: """ 计算多任务损失 :param out_offsets: 回归模型边界框结果 :param out_classifier: 分类模型边界框结果 :param gt_offsets: 真实边界框 :param gt_labels: 边界框标签 :param alpha: 权重系数 :return: 分类损失/正样本回归损失/总损失 """ # 分类损失计算式忽略标签为-1的样本 cls_loss_func = nn.CrossEntropyLoss(ignore_index=-1) reg_loss_func = nn.SmoothL1Loss() # 计算分类损失 loss_cls = cls_loss_func(out_classifier, gt_labels) # 选择正样本计算回归损失 out_offsets_valid = out_offsets[gt_labels > 0] gt_offsets_valid = gt_offsets[gt_labels > 0] loss_reg = reg_loss_func(out_offsets_valid, gt_offsets_valid) # 总损失 loss = loss_cls + alpha * loss_reg return loss_cls, loss_reg, loss
在计算损失时,标签为-1既不是正样本也不是负样本,需要忽略,所以计算回归损失时设置ignore_index=-1,表明忽略标签-1,计算回归损失时,也采用设置gt_labels>0。
3. Classifier训练
3.1 roi区域筛选
经过RPN网络后,每张训练图片能生成2000个roi区域用于精确分类和定位,这些区域并不是全部用于ROI Pooling和最终的Classifier网络。我们会对这些区域进一步筛选,并计算筛选后的结果与真值之间的偏移,作为最终Classifier网络的真值用于Classifier网络训练。具体实施方法如下:
- 计算推荐区域rois与真值gt_boxes的交并比iou;
- 计算每个roi对应iou最大时的gt_box索引max_iou_idx_gt以及每个roi对应的iou最大值max_iou_values_anchor;
- 根据max_iou_idx_gt获取rois对应的真值框位置roi_gt_boxes和对应的标签roi_gt_labels;
- 通过随机抽取的方式控制保留的rois数量,得到用于后续任务的样本sample_rois;
- 计算保留的sample_rois与对应真值框sample_gt_boxes的位置偏移sample_offsets,以及对应的多分类标签sample_labels,作为最终Classifier网络的真值。
上述过程定义ProposalTargetCreator来实现,经过处理后,2000个roi区域最终会保留128个用于Classifier训练。具体代码如下:
class ProposalTargetCreator: def __init__(self, num_samples=128, positive_iou_thresh=0.5, negative_iou_thresh=(0.5, 0.0), positive_rate=0.5): """ 在roi区域中选择一定数量的正负样本区域, 计算坐标偏移和分类标签, 用于后续分类和回归网络 :param num_samples: 待保留的正负样本总数 :param positive_iou_thresh: 正样本阈值 :param negative_iou_thresh: 负样本阈值最大值和最小值 :param positive_rate: 正样本比例 """ self.num_samples = num_samples self.positive_iou_thresh = positive_iou_thresh self.negative_iou_thresh = negative_iou_thresh self.positive_rate = positive_rate self.num_positive_per_image = int(num_samples * positive_rate) # 定义坐标偏移值归一化系数, 用于正负样本区域的offsets归一化 self.offsets_normalize_params = np.array([[0, 0, 0, 0], [0.1, 0.1, 0.2, 0.2]], dtype="float32") def __call__(self, rois: np.ndarray, gt_boxes: np.ndarray, labels: np.ndarray): """ 根据推荐区域的iou结果选择一定数量的推荐区域作为正负样本, 并计算推荐区域与真值间的偏移值 :param rois: 推荐区域, 维度为[m, 4] :param gt_boxes: 真值框, 维度为[n, 4] :param labels: 图像类别标签, 维度为[l, 1], 注意此处取值为[1, num_target_classes], 默认背景为0 :return: 保留的正负样本区域/区域偏移值/区域标签 """ rois = np.concatenate((rois, gt_boxes), axis=0) # 计算iou结果 iou = AnchorCreator.calc_IoU(anchors=rois, gt_boxes=gt_boxes) # 根据iou最大获取每个推荐框对应的真实框的idx和相应iou结果 _, max_iou_idx_gt, max_iou_values = AnchorCreator.calc_max_iou_info(iou=iou) # 获取每个roi区域对应的真值框 roi_gt_boxes = gt_boxes[max_iou_idx_gt] # 获取每个roi区域对应的真值框标签, 取值从1开始, 如果取值从0开始, 由于存在背景, 真值框标签需要额外加1 roi_gt_labels = labels[max_iou_idx_gt] # 选取roi区域中的正样本序号, np.where()返回满足条件的元组, 元组第一个元素为行索引, 第二个元素为列索引 positive_idx = np.where(max_iou_values >= self.positive_iou_thresh)[0] num_positive = min(self.num_positive_per_image, len(positive_idx)) if len(positive_idx) > 1: positive_idx = np.random.choice(a=positive_idx, size=num_positive, replace=False) # 选取roi区域中的负样本序号 negative_idx = np.where((max_iou_values < self.negative_iou_thresh[0]) & (max_iou_values >= self.negative_iou_thresh[1]))[0] num_negative = min(self.num_samples - num_positive, len(negative_idx)) if len(negative_idx) > 1: negative_idx = np.random.choice(a=negative_idx, size=num_negative, replace=False) # 将正负样本索引整合在一起, 获得所有样本索引 sample_idx = np.append(positive_idx, negative_idx) # 提取正负样本对应的真值标签, 此时无论正/负roi_gt_labels中都为对应iou最大的真值框标签, 下一步就需要对负样本标签赋值为0 sample_labels = roi_gt_labels[sample_idx] # 对正负样本中的负样本标签赋值为0 sample_labels[num_positive:] = 0 # 提取样本对应的roi区域 sample_rois = rois[sample_idx] # 计算选取的样本roi与真值的坐标偏移值 # 根据样本索引, 获取样本对应的真值框 sample_gt_boxes = roi_gt_boxes[sample_idx] # 计算推荐区域样本与真值的坐标偏移 sample_offsets = AnchorCreator.calc_offsets_from_bboxes(anchors=sample_rois, target_boxes=sample_gt_boxes) # 对坐标偏移进行归一化 sample_offsets = (sample_offsets - self.offsets_normalize_params[0]) / self.offsets_normalize_params[1] return sample_rois, sample_offsets, sample_labels
训练过程中,遍历每张图片获取最终推荐区域后,需要将每个batch的数据结果整合在一起,其代码如下:
# 在当前图像生成的roi建议框中中, 抽取一定数量的正负样本, 并计算出相应位置偏移, 用于后续回归和区域分类 sample_rois, sample_offsets, sample_labels = proposal_creator(rois=np_cur_rois, gt_boxes=np_cur_gt_boxes, labels=np_cur_labels) # 将每个图像生成的样本信息存储起来用于后续回归和分类 # 抽取当前数据生成的推荐区域样本放入list中, list长度为num, 每个元素维度为[num_samples, 4] samples_rois.append(torch.tensor(sample_rois).type_as(rpn_offsets)) # 将抽取的样本索引放入list中, list长度为num, 每个元素维度为[num_samples] samples_indexes.append(torch.ones(len(sample_rois), device=rpn_offsets.device) * rois_idx[i][0]) # 将抽取的样本偏移值放入list中, list长度为num, 每个元素维度为[num_samples, 4] samples_offsets.append(torch.tensor(sample_offsets).type_as(rpn_offsets)) # 将抽取的样本分类标签放入list中, list长度为num, 每个元素维度为[num_samples] samples_labels.append(torch.tensor(sample_labels, device=rpn_offsets.device).long())
3.2 Classifier损失
将图像特征im_features、保留的推荐区域sample_rois经过ROIHead处理,可以得到每张图片Classifier网络的分类和回归输出。结合4.3.1中获取的真值,即可计算该网络的损失。代码如下:
# 整合当前batch数据抽取的推荐区域信息 samples_rois = torch.stack(samples_rois, dim=0) samples_indexes = torch.stack(samples_indexes, dim=0) # 将图像特征和推荐区域送入模型, 进行roi池化并获得分类模型/回归模型输出 roi_out_offsets, roi_out_classifier = network.forward(x=[im_features, samples_rois, samples_indexes, (im_height, im_width)], mode="head") # 遍历每帧图像的roi信息 for i in range(num): cur_num_samples = roi_out_offsets.size(1) cur_roi_out_offsets = roi_out_offsets[i] cur_roi_out_classifier = roi_out_classifier[i] cur_roi_gt_offsets = samples_offsets[i] cur_roi_gt_labels = samples_labels[i] # 将当前数据的roi区域由[cur_num_samples, num_classes * 4] -> [cur_num_samples, num_classes, 4] cur_roi_out_offsets = cur_roi_out_offsets.view(cur_num_samples, -1, 4) # 根据roi对应的样本标签, 选择与其类别对应真实框的offsets cur_roi_offsets = cur_roi_out_offsets[torch.arange(0, cur_num_samples), cur_roi_gt_labels] # 计算分类网络和回归网络的损失值 cur_roi_cls_loss, cur_roi_reg_loss, _ = multitask_loss(out_offsets=cur_roi_offsets, out_classifier=cur_roi_out_classifier, gt_offsets=cur_roi_gt_offsets, gt_labels=cur_roi_gt_labels) roi_cls_loss += cur_roi_cls_loss roi_reg_loss += cur_roi_reg_loss
自此,Classifier网络训练结束。
4. 训练代码
综合上述流程,得到最终的训练部分代码Train.py:
import os import torch import numpy as np import torch.nn as nn from torch import Tensor from typing import Tuple import matplotlib.pyplot as plt from Utils import GenDataSet from torch.optim.lr_scheduler import StepLR from Model import AnchorCreator, ProposalTargetCreator, FasterRCNN from Config import * def multitask_loss(out_offsets: Tensor, out_classifier: Tensor, gt_offsets: Tensor, gt_labels: Tensor, alpha: float = 1.0) -> Tuple[Tensor, Tensor, Tensor]: """ 计算多任务损失 :param out_offsets: 回归模型边界框结果 :param out_classifier: 分类模型边界框结果 :param gt_offsets: 真实边界框 :param gt_labels: 边界框标签 :param alpha: 权重系数 :return: 分类损失/正样本回归损失/总损失 """ # 分类损失计算式忽略标签为-1的样本 cls_loss_func = nn.CrossEntropyLoss(ignore_index=-1) reg_loss_func = nn.SmoothL1Loss() # 计算分类损失 loss_cls = cls_loss_func(out_classifier, gt_labels) # 选择正样本计算回归损失 out_offsets_valid = out_offsets[gt_labels > 0] gt_offsets_valid = gt_offsets[gt_labels > 0] loss_reg = reg_loss_func(out_offsets_valid, gt_offsets_valid) # 总损失 loss = loss_cls + alpha * loss_reg return loss_cls, loss_reg, loss def train(data_set, network, num_epochs, optimizer, scheduler, device, train_rate: float = 0.8): """ 模型训练 :param data_set: 训练数据集 :param network: 网络结构 :param num_epochs: 训练轮次 :param optimizer: 优化器 :param scheduler: 学习率调度器 :param device: CPU/GPU :param train_rate: 训练集比例 :return: None """ os.makedirs('./model', exist_ok=True) network = network.to(device) best_loss = np.inf print("=" * 8 + "开始训练模型" + "=" * 8) # 计算训练batch数量 batch_num = len(data_set) train_batch_num = round(batch_num * train_rate) # 记录训练过程中每一轮损失和准确率 train_loss_all, val_loss_all, train_acc_all, val_acc_all = [], [], [], [] anchor_creator = AnchorCreator() proposal_creator = ProposalTargetCreator() for epoch in range(num_epochs): # 记录train/val总损失 num_train_loss = num_val_loss = train_loss = val_loss = 0.0 for step, batch_data in enumerate(data_set): # 读取数据, 注意gt_boxes列坐标对应[x1, y1, x2, y2] ims, labels, gt_boxes = batch_data ims = ims.to(device) labels = labels.to(device) gt_boxes = gt_boxes.to(device) num, chans, im_height, im_width = ims.size() if step < train_batch_num: # 设置为训练模式 network.train() # 获取输入图像全图特征, 维度为[num, 512, im_height/16, im_width/16] im_features = network.forward(x=ims, mode="extractor") # 利用rpn网络获取回归器输出/分类器输出/batch数据对应建议框/建议框对应数据索引/全图先验框 rpn_offsets, rpn_classifier, rois, rois_idx, anchors = network.forward(x=[im_features, (im_height, im_width)], mode="rpn") np_anchors = anchors.cpu().numpy() # 记录rpn区域推荐网络的分类/回归损失, 以及最终的roi区域分类和回归损失 rpn_cls_loss, rpn_reg_loss, roi_cls_loss, roi_reg_loss = 0, 0, 0, 0 samples_rois, samples_indexes, samples_offsets, samples_labels = [], [], [], [] # 遍历每一个数据的真值框/数据标签/rpn网络输出 for i in range(num): # 获取每张图像的真值框/标签/rpn生成的偏移值/rpn生成的分类输出 cur_gt_boxes = gt_boxes[i] cur_labels = labels[i] cur_rpn_offsets = rpn_offsets[i] cur_rpn_classifier = rpn_classifier[i] cur_rois = rois[i] np_cur_gt_boxes = cur_gt_boxes.clone().detach().cpu().numpy() np_cur_rois = cur_rois.clone().detach().cpu().numpy() np_cur_labels = cur_labels.clone().detach().cpu().numpy() # 根据当前图像真值框和先验框, 获取每个先验框标签以及图像经过rpn网络后应产生的偏移值作为真值 cur_gt_rpn_labels, cur_gt_rpn_offsets = anchor_creator(im_width=im_width, im_height=im_height, anchors=np_anchors, gt_boxes=np_cur_gt_boxes) # 转换为张量后计算rpn网络的回归损失和分类损失 cur_gt_rpn_offsets = torch.tensor(cur_gt_rpn_offsets).type_as(rpn_offsets) cur_gt_rpn_labels = torch.tensor(cur_gt_rpn_labels).long().to(rpn_offsets.device) cur_rpn_cls_loss, cur_rpn_reg_loss, _ = multitask_loss(out_offsets=cur_rpn_offsets, out_classifier=cur_rpn_classifier, gt_offsets=cur_gt_rpn_offsets, gt_labels=cur_gt_rpn_labels) rpn_cls_loss += cur_rpn_cls_loss rpn_reg_loss += cur_rpn_reg_loss # 在当前图像生成的roi建议框中中, 抽取一定数量的正负样本, 并计算出相应位置偏移, 用于后续回归和区域分类 sample_rois, sample_offsets, sample_labels = proposal_creator(rois=np_cur_rois, gt_boxes=np_cur_gt_boxes, labels=np_cur_labels) # 将每个图像生成的样本信息存储起来用于后续回归和分类 # 抽取当前数据生成的推荐区域样本放入list中, list长度为num, 每个元素维度为[num_samples, 4] samples_rois.append(torch.tensor(sample_rois).type_as(rpn_offsets)) # 将抽取的样本索引放入list中, list长度为num, 每个元素维度为[num_samples] samples_indexes.append(torch.ones(len(sample_rois), device=rpn_offsets.device) * rois_idx[i][0]) # 将抽取的样本偏移值放入list中, list长度为num, 每个元素维度为[num_samples, 4] samples_offsets.append(torch.tensor(sample_offsets).type_as(rpn_offsets)) # 将抽取的样本分类标签放入list中, list长度为num, 每个元素维度为[num_samples] samples_labels.append(torch.tensor(sample_labels, device=rpn_offsets.device).long()) # 整合当前batch数据抽取的推荐区域信息 samples_rois = torch.stack(samples_rois, dim=0) samples_indexes = torch.stack(samples_indexes, dim=0) # 将图像特征和推荐区域送入模型, 进行roi池化并获得分类模型/回归模型输出 roi_out_offsets, roi_out_classifier = network.forward(x=[im_features, samples_rois, samples_indexes, (im_height, im_width)], mode="head") # 遍历每帧图像的roi信息 for i in range(num): cur_num_samples = roi_out_offsets.size(1) cur_roi_out_offsets = roi_out_offsets[i] cur_roi_out_classifier = roi_out_classifier[i] cur_roi_gt_offsets = samples_offsets[i] cur_roi_gt_labels = samples_labels[i] # 将当前数据的roi区域由[cur_num_samples, num_classes * 4] -> [cur_num_samples, num_classes, 4] cur_roi_out_offsets = cur_roi_out_offsets.view(cur_num_samples, -1, 4) # 根据roi对应的样本标签, 选择与其类别对应真实框的offsets cur_roi_offsets = cur_roi_out_offsets[torch.arange(0, cur_num_samples), cur_roi_gt_labels] # 计算分类网络和回归网络的损失值 cur_roi_cls_loss, cur_roi_reg_loss, _ = multitask_loss(out_offsets=cur_roi_offsets, out_classifier=cur_roi_out_classifier, gt_offsets=cur_roi_gt_offsets, gt_labels=cur_roi_gt_labels) roi_cls_loss += cur_roi_cls_loss roi_reg_loss += cur_roi_reg_loss # 计算整体loss, 反向传播 batch_loss = (rpn_cls_loss + rpn_reg_loss + roi_cls_loss + roi_reg_loss) / num optimizer.zero_grad() batch_loss.backward() optimizer.step() # 记录每轮训练数据量和总loss train_loss += batch_loss.item() * num num_train_loss += num else: # 设置为验证模式 network.eval() with torch.no_grad(): # 获取输入图像全图特征, 维度为[num, 512, im_height/16, im_width/16] im_features = network.forward(x=ims, mode="extractor") # 利用rpn网络获取回归器输出/分类器输出/batch数据对应建议框/建议框对应数据索引/全图先验框 rpn_offsets, rpn_classifier, rois, rois_idx, anchors = network.forward(x=[im_features, (im_height, im_width)], mode="rpn") np_anchors = anchors.cpu().numpy() # 记录rpn区域网络的分类/回归损失, 以及roi区域分类和回归损失 rpn_cls_loss, rpn_reg_loss, roi_cls_loss, roi_reg_loss = 0, 0, 0, 0 samples_rois, samples_indexes, samples_offsets, samples_labels = [], [], [], [] # 遍历每一个数据的真值框/数据标签/rpn网络输出 for i in range(num): # 获取每张图像的真值框/标签/rpn生成的偏移值/rpn生成的分类输出 cur_gt_boxes = gt_boxes[i] cur_labels = labels[i] cur_rpn_offsets = rpn_offsets[i] cur_rpn_classifier = rpn_classifier[i] cur_rois = rois[i] np_cur_gt_boxes = cur_gt_boxes.clone().detach().cpu().numpy() np_cur_rois = cur_rois.clone().detach().cpu().numpy() np_cur_labels = cur_labels.clone().detach().cpu().numpy() # 根据当前图像真值框和先验框, 获取每个先验框标签以及图像经过rpn网络后应产生的偏移值作为真值 cur_gt_rpn_labels, cur_gt_rpn_offsets = anchor_creator(im_width=im_width, im_height=im_height, anchors=np_anchors, gt_boxes=np_cur_gt_boxes) # 转换为张量后计算rpn网络的回归损失和分类损失 cur_gt_rpn_offsets = torch.tensor(cur_gt_rpn_offsets).type_as(rpn_offsets) cur_gt_rpn_labels = torch.tensor(cur_gt_rpn_labels).long().to(rpn_offsets.device) cur_rpn_cls_loss, cur_rpn_reg_loss, _ = multitask_loss(out_offsets=cur_rpn_offsets, out_classifier=cur_rpn_classifier, gt_offsets=cur_gt_rpn_offsets, gt_labels=cur_gt_rpn_labels) rpn_cls_loss += cur_rpn_cls_loss rpn_reg_loss += cur_rpn_reg_loss # 在当前图像生成的roi建议框中中, 抽取一定数量的正负样本, 并计算出相应位置偏移, 用于后续回归和区域分类 sample_rois, sample_offsets, sample_labels = proposal_creator(rois=np_cur_rois, gt_boxes=np_cur_gt_boxes, labels=np_cur_labels) # 将每个图像生成的样本信息存储起来用于后续回归和分类 # 抽取当前数据生成的推荐区域样本放入list中, list长度为num, 每个元素维度为[num_samples, 4] samples_rois.append(torch.tensor(sample_rois).type_as(rpn_offsets)) # 将抽取的样本索引放入list中, list长度为num, 每个元素维度为[num_samples] samples_indexes.append(torch.ones(len(sample_rois), device=rpn_offsets.device) * rois_idx[i][0]) # 将抽取的样本偏移值放入list中, list长度为num, 每个元素维度为[num_samples, 4] samples_offsets.append(torch.tensor(sample_offsets).type_as(rpn_offsets)) # 将抽取的样本分类标签放入list中, list长度为num, 每个元素维度为[num_samples] samples_labels.append(torch.tensor(sample_labels, device=rpn_offsets.device).long()) # 整合当前batch数据抽取的推荐区域信息 samples_rois = torch.stack(samples_rois, dim=0) samples_indexes = torch.stack(samples_indexes, dim=0) # 将图像特征和推荐区域送入模型, 进行roi池化并获得分类模型/回归模型输出 roi_out_offsets, roi_out_classifier = network.forward(x=[im_features, samples_rois, samples_indexes, (im_height, im_width)], mode="head") for i in range(num): cur_num_samples = roi_out_offsets.size(1) cur_roi_out_offsets = roi_out_offsets[i] cur_roi_out_classifier = roi_out_classifier[i] cur_roi_gt_offsets = samples_offsets[i] cur_roi_gt_labels = samples_labels[i] cur_roi_out_offsets = cur_roi_out_offsets.view(cur_num_samples, -1, 4) # 根据roi对应的样本标签, 选择与其类别对应真实框的offsets cur_roi_offsets = cur_roi_out_offsets[torch.arange(0, cur_num_samples), cur_roi_gt_labels] # 计算分类网络和回归网络的损失值 cur_roi_cls_loss, cur_roi_reg_loss, _ = multitask_loss(out_offsets=cur_roi_offsets, out_classifier=cur_roi_out_classifier, gt_offsets=cur_roi_gt_offsets, gt_labels=cur_roi_gt_labels) roi_cls_loss += cur_roi_cls_loss roi_reg_loss += cur_roi_reg_loss # 计算整体loss, 反向传播 batch_loss = (rpn_cls_loss + rpn_reg_loss + roi_cls_loss + roi_reg_loss) / num # 记录每轮训练数据量和总loss val_loss += batch_loss.item() * num num_val_loss += num scheduler.step() # 记录loss和acc变化曲线 train_loss_all.append(train_loss / num_train_loss) val_loss_all.append(val_loss / num_val_loss) print("Epoch:[{:0>3}|{}] train_loss:{:.3f} val_loss:{:.3f}".format(epoch + 1, num_epochs, train_loss_all[-1], val_loss_all[-1])) # 保存模型 if val_loss_all[-1] < best_loss: best_loss = val_loss_all[-1] save_path = os.path.join("./model", "model_" + str(epoch + 1) + ".pth") torch.save(network, save_path) # 绘制训练曲线 fig_path = os.path.join("./model/", "train_curve.png") plt.plot(range(num_epochs), train_loss_all, "r-", label="train") plt.plot(range(num_epochs), val_loss_all, "b-", label="val") plt.title("Loss") plt.legend() plt.tight_layout() plt.savefig(fig_path) plt.close() return None if __name__ == "__main__": device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model = FasterRCNN(num_classes=CLASSES, train_flag=True, feature_stride=FEATURE_STRIDE, anchor_spatial_scales=ANCHOR_SPATIAL_SCALES, wh_ratios=ANCHOR_WH_RATIOS, pretrained=False) optimizer = torch.optim.Adam(params=model.parameters(), lr=LR) scheduler = StepLR(optimizer, step_size=STEP, gamma=GAMMA) model_root = "./model" os.makedirs(model_root, exist_ok=True) # 在生成的ss数据上进行预训练 train_root = "./data/source" train_set = GenDataSet(root=train_root, im_width=IM_SIZE, im_height=IM_SIZE, batch_size=BATCH_SIZE, shuffle=True) train(data_set=train_set, network=model, num_epochs=EPOCHS, optimizer=optimizer, scheduler=scheduler, device=device, train_rate=0.8)
五、模型预测
1. 预测代码
预测流程比训练简单的多,其具体过程如下:
- 将图片输入模型获得Classifier网络的分类输出rois_out_classifier、偏移值输出rois_out_regressor以及筛选后的推荐区域rois;
- 根据偏移值rois_out_regressor和rois计算预测的目标边界框target_boxes;
- 利用rois_out_classifier分类结果对预测边界框进行限制;
- 利用非极大值抑制nms对最终bbox进行筛选。
预测过程Predict.py代码如下:
import os import torch import numpy as np from torch import Tensor import torch.nn.functional as F from torchvision.ops import nms from Model import FasterRCNN, ProposalCreator import matplotlib.pyplot as plt from matplotlib import patches from Utils import GenDataSet from skimage import io from Config import * def draw_box(img: np.ndarray, boxes: np.ndarray = None, save_name: str = None): """ 在图像上绘制边界框 :param img: 输入图像 :param boxes: bbox坐标, 列分别为[x, y, w, h, score, label] :param save_name: 保存bbox图像名称, None-不保存 :return: None """ plt.imshow(img) axis = plt.gca() if boxes is not None: for box in boxes: x, y, w, h = box[:4].astype("int") score = box[4] rect = patches.Rectangle((x, y), w, h, linewidth=1, edgecolor='r', facecolor='none') axis.add_patch(rect) axis.text(x, y - 10, "Score: {:.2f}".format(score), fontsize=12, color='blue') if save_name is not None: os.makedirs("./predict", exist_ok=True) plt.savefig("./predict/" + save_name + ".jpg") plt.show() return None def predict(network: FasterRCNN, im: np.ndarray, device: torch.device, im_width: int, im_height: int, num_classes: int, offsets_norm_params: Tensor, nms_thresh: float = 0.3, confidence_thresh: float = 0.5, save_name: str = None): """ 模型预测 :param network: Faster R-CNN模型结构 :param im: 原始输入图像矩阵 :param device: CPU/GPU :param im_width: 输入模型的图像宽度 :param im_height: 输入模型的图像高度 :param num_classes: 目标类别数 :param offsets_norm_params: 偏移值归一化参数 :param nms_thresh: 非极大值抑制阈值 :param confidence_thresh: 目标置信度阈值 :param save_name: 保存文件名 :return: None """ # 测试模式 network.eval() src_height, src_width = im.shape[:2] # 数据归一化和缩放 im_norm = (im / 255.0).astype("float32") im_rsz = GenDataSet.resize(im=im_norm, im_width=im_width, im_height=im_height, gt_boxes=None) # 将矩阵转换为张量 im_tensor = torch.tensor(np.transpose(im_rsz, (2, 0, 1))).unsqueeze(0).to(device) with torch.no_grad(): # 获取Faster R-CNN网络的输出, 包括回归器输出/分类器输出/推荐区域 # 维度分别为[num_ims, num_rois, num_classes * 4]/[num_ims, num_rois, num_classes]/[num_ims, num_rois, 4] rois_out_regressor, rois_out_classifier, rois, _ = network.forward(x=im_tensor, mode="forward") # 获取当前图像数量/推荐区域数量 num_ims, num_rois, _ = rois_out_regressor.size() # 记录预测的边界框信息 out_bboxes = [] # 遍历处理每张图片, 此处实际只有一张图 cur_rois_offsets = rois_out_regressor[0] cur_rois = rois[0] cur_rois_classifier = rois_out_classifier[0] # 将偏移值进行维度变换[num_rois, num_classes * 4] -> [num_rois, num_classes, 4] cur_rois_offsets = cur_rois_offsets.view(-1, num_classes, 4) # 对roi区域进行维度变换[num_rois, 4] -> [num_rois, 1, 4] -> [num_rois, num_classes, 4] cur_rois = cur_rois.view(-1, 1, 4).expand_as(cur_rois_offsets) # 将偏移值和roi区域展开成相同大小的二维张量, 方便对roi进行位置矫正 # 将偏移值展开, 维度[num_rois, num_classes, 4] -> [num_rois * num_classes, 4] cur_rois_offsets = cur_rois_offsets.view(-1, 4) # 将和roi区域展开, 维度[num_rois, num_classes, 4] -> [num_rois * num_classes, 4] cur_rois = cur_rois.contiguous().view(-1, 4) # 对回归结果进行修正 # 注意Faster R-CNN网络输出的样本偏移值是经过均值方差修正的, 此处需要将其还原 offsets_norm_params = offsets_norm_params.type_as(cur_rois_offsets) # ProposalTargetCreator中计算方式: sample_offsets = (sample_offsets - self.offsets_normalize_params[0]) / self.offsets_normalize_params[1] cur_rois_offsets = cur_rois_offsets * offsets_norm_params[1] + offsets_norm_params[0] # 利用偏移值对推荐区域位置进行矫正, 获得预测框位置, 维度[num_rois * num_classes, 4] cur_target_boxes = ProposalCreator.calc_bboxes_from_offsets(offsets=cur_rois_offsets, anchors=cur_rois) # 展开成[num_rois, num_classes, 4]方便与类别一一对应 cur_target_boxes = cur_target_boxes.view(-1, num_classes, 4) # 获取分类得分 cur_roi_scores = F.softmax(cur_rois_classifier, dim=-1) # 根据目标得分, 获取最可能的分类结果 max_prob_labels = torch.argmax(input=cur_roi_scores[:, 1:], dim=-1) + 1 max_prob_scores = cur_roi_scores[torch.arange(0, cur_roi_scores.size(0)), max_prob_labels] max_prob_boxes = cur_target_boxes[torch.arange(0, cur_target_boxes.size(0)), max_prob_labels] # 选取得分大于阈值的 is_valid_scores = max_prob_scores > confidence_thresh if sum(is_valid_scores) > 0: valid_boxes = max_prob_boxes[is_valid_scores] valid_scores = max_prob_scores[is_valid_scores] keep = nms(boxes=valid_boxes, scores=valid_scores, iou_threshold=nms_thresh) # 获取保留的目标框, 维度为[num_keep, 4] keep_boxes = valid_boxes[keep] # 获取保留目标框的得分, 并将维度扩展为[num_keep, 1] keep_scores = valid_scores[keep][:, None] # 将预测框/标签/得分堆叠在一起 cls_predict = torch.cat([keep_boxes, keep_scores], dim=1).cpu().numpy() # 预测结果添加进cur_out_bboxes里 out_bboxes.extend(cls_predict) if len(out_bboxes) > 0: out_bboxes = np.array(out_bboxes) # 计算原始输入图像和模型输入图像之间的空间缩放比例 map_scale = np.array([src_width, src_height, src_width, src_height]) / np.array([im_width, im_height, im_width, im_height]) # 将预测框从模型输入图像映射到原始输入图像 out_bboxes[:, :4] = out_bboxes[:, :4] * map_scale # 对预测框坐标进行限制 out_bboxes[:, [0, 2]] = np.clip(a=out_bboxes[:, [0, 2]], a_min=0, a_max=src_width - 1) out_bboxes[:, [1, 3]] = np.clip(a=out_bboxes[:, [1, 3]], a_min=0, a_max=src_height - 1) # 将预测框[x1, y1, x2, y2, score, label]转换为[x1, y1, w, h, score, label] out_bboxes[:, [2, 3]] = out_bboxes[:, [2, 3]] - out_bboxes[:, [0, 1]] + 1 if len(out_bboxes) == 0: out_bboxes = None draw_box(img=im, boxes=out_bboxes, save_name=save_name) if __name__ == "__main__": device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model_path = "./model/model_180.pth" model = torch.load(model_path, map_location=device) # 偏移值归一化参数, 需保证和训练阶段一致 offsets_normalize_params = torch.Tensor([[0, 0, 0, 0], [0.1, 0.1, 0.2, 0.2]]) test_root = "./data/source/17flowers" for roots, dirs, files in os.walk(test_root): for file in files: if not file.endswith(".jpg"): continue im_name = file.split(".")[0] im_path = os.path.join(roots, file) im = io.imread(im_path) predict(network=model, im=im, device=device, im_width=IM_SIZE, im_height=IM_SIZE, num_classes=CLASSES, offsets_norm_params=offsets_normalize_params, nms_thresh=NMS_THRESH, confidence_thresh=CONFIDENCE_THRESH, save_name=im_name)
2. 预测结果
如下为Faster RCNN在花朵数据集上预测结果展示,左图中当同一图中存在多个相同类别目标且距离较近时,边界框并没有很好地检测出每个个体。

六、算法缺点
Faster R-CNN虽然在目标检测领域取得了显著成果,但仍存在一些缺点:
- 卷积提取网络的问题:Faster R-CNN在特征提取阶段,无论使用VGGNet还是ResNet,其特征图都是单层的,且分辨率通常较小。这可能导致对于多尺度、小目标的检测效果不佳。为了优化这一点,研究者们提出了使用多层融合的特征图或增大特征图的分辨率等方法;
- NMS(非极大值抑制)的问题:NMS在RPN产生Proposal时用于避免重叠的框,并以分类得分为筛选标准。但NMS对于遮挡物体的处理并不友好,有可能将本属于两个物体的Proposal过滤为一个,导致漏检。因此,对NMS的改进可以进一步提升检测性能;
- RoI Pooling的问题:Faster R-CNN的原始RoI Pooling在两次取整过程中可能会带来精度的损失,虽然后续的Mask R-CNN针对此问题进行了改进,但原始的Faster R-CNN在这一方面仍有待优化。
七、数据和代码
本文中数据和详细工程代码实现请移步:https://github.com/jchsun1/Faster-RCNN
本文至此结束,如有疑惑欢迎留言交流。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术