【目标检测】R-CNN算法实现
一、前言
RCNN(Regions with CNN features)算法由Ross Girshick在2014年的论文“Rich feature hierarchies for accurate object detection and semantic segmentation”提出,是深度学习目标检测的开山之作。RCNN将CNN应用到目标检测问题上,它使用选择性搜索从图像中提取候选区域,利用卷积层提取候选区域的特征,最后对这些候选区域进行分类和回归 。RCNN的出现大大提高了目标检测的效果,同时也改变了目标检测领域的主要研究思路。它的出现使得人们开始意识到深度学习在计算机视觉领域中的广泛应用前景。虽然RCNN难以满足实时检测需求,但能帮助我们较好的理解并入门目标检测算法。
二、RCNN算法实现
RCNN算法实现主要包括以下步骤:候选区域生成→特征提取→图像分类→候选框位置修正→预测。和论文中实现方式不同的是,本文不采用SVM训练分类器,而是直接使用CNN分类模型完成图像分类和特征提取任务。
本文算法基于python3.7 + pytorch框架 + 17flowers数据集实现。
1. 候选区域生成
RCNN采用选择性搜索(selective search,后面简称为ss)的办法产生候选区域,参考论文:J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders. Selective search for object recognition. IJCV, 2013.
1.1 ss方法实现思路
1.1.1 采用某种手段(如Felzenszwalb方法)将图像分割成许多小区域 R = {r1, ... , rn}
1.1.2 初始化一个集合 S = Ø,用于存放临近区域的相似度结果
1.1.3 遍历R中的相邻区域对 (rm, rn),计算他们之间的相似度 s( rm, rn),将相似度结果放入集合 S 中:
1.1.4 如果S不为空集:
a. 根据 s(ri, rj)=max(S) 寻找 S 中相似度最高的区域对 (ri, rj)
b. 将区域 ri 和 rj 合并,得到新的区域 rt = ri U rj
c. 移除S中区域 ri 和 rj 相关的所有相似度结果 S = S \ s(rp, r*),p = {i, j}
d. 计算新区域 rt 与周围区域的相似度集合 St,并将 St 放入集合 S 中,将新区域 rt 放入集合 R 中,即 S = S U St, R = R U rt
1.1.5 提取 R 中所有区域的边界框,即为可能存在物体的区域
1.2 ss方法的特点
1.2.1 速度快:利用分割算法而非暴力穷举的方式生成候选区域,同时采用自底向上合并重叠区域的方法,减少区域冗余
1.2.2 多样化:并非从单一特征定位物体,而是从颜色、纹理、大小等多个方向对分割区域进行合并定位
1.3 ss方法的python实现
ss方法的python代码:


# SelectiveSearchCode.py # -*- coding: utf-8 -*- import os from skimage import util, io, feature, color, transform, segmentation import numpy as np # "Selective Search for Object Recognition" by J.R.R. Uijlings et al. def _generate_segments(im_orig, scale, sigma, min_size): """ 根据Felzenswalb-Huttenlocher方法将图像分割为小区域图像 :param im_orig: 输入3通道图像 :param scale: 分割参数, 数值越小, 分割越精细 :param sigma: 分割图像前对图像进行高斯平滑的参数 :param min_size: 分割的最小单元, 一般设置10-100间 :return: 带分割类别的4通道图 """ # 获取分割后每个小区域所属的类别 im_mask = segmentation.felzenszwalb(util.img_as_float(im_orig), scale=scale, sigma=sigma, min_size=min_size) # 把类别合并到最后一个通道上, 维度为[w, h, 4] im_orig = np.append(im_orig, np.zeros(im_orig.shape[:2])[:, :, np.newaxis], axis=2) im_orig[:, :, 3] = im_mask return im_orig def _sim_colour(r1, r2): """ 计算区域颜色直方图交集和 :param r1: 区域 1 :param r2:区域 2 :return: 颜色直方图交集和 """ return sum([min(a, b) for a, b in zip(r1["hist_c"], r2["hist_c"])]) def _sim_texture(r1, r2): """ 计算区域纹理直方图交集和 :param r1: 区域 1 :param r2:区域 2 :return: 颜色直方图交集和 """ return sum([min(a, b) for a, b in zip(r1["hist_t"], r2["hist_t"])]) def _sim_size(r1, r2, imsize): """ 计算图像大小相似度 :param r1: 区域 1 :param r2: 区域 2 :param imsize: 图像size :return: 图像大小相似度 """ return 1.0 - (r1["size"] + r2["size"]) / imsize def _sim_fill(r1, r2, imsize): """ 计算图像填充相似度 :param r1: 区域 1 :param r2: 区域 2 :param imsize: 图像带下 :return: 填充相似度结果 """ bbsize = ( (max(r1["max_x"], r2["max_x"]) - min(r1["min_x"], r2["min_x"])) * (max(r1["max_y"], r2["max_y"]) - min(r1["min_y"], r2["min_y"])) ) return 1.0 - (bbsize - r1["size"] - r2["size"]) / imsize def _calc_sim(r1, r2, imsize): """ 整合区域相似度结果 :param r1: 区域 1 :param r2: 区域 2 :param imsize: 整体相似度结果 :return: """ return _sim_colour(r1, r2) + _sim_texture(r1, r2) + _sim_size(r1, r2, imsize) + _sim_fill(r1, r2, imsize) def _calc_colour_hist(img): """ 在HSV空间计算图像颜色直方图, 输出维度为[BINS, COLOUR_CHANNELS(3)], 参考[uijlings_ijcv2013_draft.pdf]这里bins取值为25 :param img: hsv空间图像 :return: 颜色直方图 """ BINS = 25 hist = np.array([]) for colour_channel in (0, 1, 2): # extracting one colour channel c = img[:, colour_channel] # calculate histogram for each colour and join to the result hist = np.concatenate( [hist] + [np.histogram(c, BINS, (0.0, 255.0))[0]]) # L1 normalize hist = hist / len(img) return hist def _calc_texture_gradient(img): """ 计算纹理梯度, 原始ss方法采用Gaussian导数方法, 此处采用lbp方法 :param img: 输入图像 :return: 和输入图像等大的lbp纹理特征 """ ret = np.zeros((img.shape[0], img.shape[1], img.shape[2])) for colour_channel in (0, 1, 2): ret[:, :, colour_channel] = feature.local_binary_pattern(img[:, :, colour_channel], 8, 1.0) return ret def _calc_texture_hist(img): """ 计算图像每个通道的纹理直方图 :param img: 输入图像 :return: 纹理直方图 """ BINS = 10 hist = np.array([]) for colour_channel in (0, 1, 2): # mask by the colour channel fd = img[:, colour_channel] # calculate histogram for each orientation and concatenate them all # and join to the result hist = np.concatenate([hist] + [np.histogram(fd, BINS, (0.0, 1.0))[0]]) # L1 Normalize hist = hist / len(img) return hist def _extract_regions(img): """ 提取原始图像分割区域 :param img: 带像素标签的4通道图像 :return: 原始分割区域 """ R = {} # get hsv image hsv = color.rgb2hsv(img[:, :, :3]) # step-1 像素位置计数 # 遍历每个像素标签, 若其还没有被分配到一个区域, 就创建一个新的区域并将其添加到字典R中 for y, i in enumerate(img): for x, (r, g, b, l) in enumerate(i): # initialize a new region if l not in R: R[l] = { "min_x": 0xffff, "min_y": 0xffff, "max_x": 0, "max_y": 0, "labels": [l]} # bounding box # 根据该像素的坐标更新该区域的边界框, 即最小和最大的x和y坐标 if R[l]["min_x"] > x: R[l]["min_x"] = x if R[l]["min_y"] > y: R[l]["min_y"] = y if R[l]["max_x"] < x: R[l]["max_x"] = x if R[l]["max_y"] < y: R[l]["max_y"] = y # step-2 计算纹理梯度 tex_grad = _calc_texture_gradient(img) # step-3 计算颜色和纹理直方图 for k, v in R.items(): # colour histogram masked_pixels = hsv[:, :, :][img[:, :, 3] == k] R[k]["size"] = len(masked_pixels / 4) R[k]["hist_c"] = _calc_colour_hist(masked_pixels) # texture histogram R[k]["hist_t"] = _calc_texture_hist(tex_grad[:, :][img[:, :, 3] == k]) return R def _extract_neighbours(regions): """ 提取给定区域之间的相邻关系 :param regions: 输入所有区域 :return: list-所有相交的区域对 """ def intersect(a, b): """ 判断两个区域是否相交 :param a: 区域 a :param b: 区域 b :return: bool-区域是否相交 """ if (a["min_x"] < b["min_x"] < a["max_x"] and a["min_y"] < b["min_y"] < a["max_y"]) or ( a["min_x"] < b["max_x"] < a["max_x"] and a["min_y"] < b["max_y"] < a["max_y"]) or ( a["min_x"] < b["min_x"] < a["max_x"] and a["min_y"] < b["max_y"] < a["max_y"]) or ( a["min_x"] < b["max_x"] < a["max_x"] and a["min_y"] < b["min_y"] < a["max_y"]): return True return False R = regions.items() r = [elm for elm in R] R = r neighbours = [] for cur, a in enumerate(R[:-1]): for b in R[cur + 1:]: if intersect(a[1], b[1]): neighbours.append((a, b)) return neighbours def _merge_regions(r1, r2): """ 区域合并并更新颜色直方图/纹理直方图/大小 :param r1: 区域 1 :param r2: 区域 2 :return: 合并后的区域 """ new_size = r1["size"] + r2["size"] rt = { "min_x": min(r1["min_x"], r2["min_x"]), "min_y": min(r1["min_y"], r2["min_y"]), "max_x": max(r1["max_x"], r2["max_x"]), "max_y": max(r1["max_y"], r2["max_y"]), "size": new_size, "hist_c": ( r1["hist_c"] * r1["size"] + r2["hist_c"] * r2["size"]) / new_size, "hist_t": ( r1["hist_t"] * r1["size"] + r2["hist_t"] * r2["size"]) / new_size, "labels": r1["labels"] + r2["labels"] } return rt def selective_search(im_orig, scale=1.0, sigma=0.8, min_size=50): """ 选择性搜索生成候选区域 :param im_orig: 输入3通道图像 :param scale: 分割参数, 数值越小, 分割越精细 :param sigma: 分割图像前对图像进行高斯平滑的参数 :param min_size: 分割的最小单元, 一般设置10-100间 :return: img-带有区域标签的图像(r, g, b, region), regions-字典{”rect“:(left, top, width, height), "labels":[...]} """ assert im_orig.shape[2] == 3, "3ch image is expected" # 加载图像获取最小分割区域 # 区域标签存储在每个像素的第四个通道 [r, g, b, region] img = _generate_segments(im_orig, scale, sigma, min_size) if img is None: return None, {} imsize = img.shape[0] * img.shape[1] R = _extract_regions(img) # 获取相邻区域对 neighbours = _extract_neighbours(R) # 计算初始相似度 S = {} for (ai, ar), (bi, br) in neighbours: S[(ai, bi)] = _calc_sim(ar, br, imsize) # 进行层次搜索, 直到没有新的相似度可以计算 while S != {}: # 获取两最大相似度区域的下标(i, j) i, j = sorted(list(S.items()), key=lambda a: a[1])[-1][0] # 将最大相似度区域合并为一个新的区域rt t = max(R.keys()) + 1.0 R[t] = _merge_regions(R[i], R[j]) # 标记相似度集合中与(i, j)相关的区域, 并将其移除 key_to_delete = [] for k, v in S.items(): if (i in k) or (j in k): key_to_delete.append(k) # 移除相关区域 for k in key_to_delete: del S[k] # 计算与新区域rt与相邻区域的相似度并添加到集合S中 for k in filter(lambda a: a != (i, j), key_to_delete): n = k[1] if k[0] in (i, j) else k[0] S[(t, n)] = _calc_sim(R[t], R[n], imsize) regions = [] for k, r in R.items(): regions.append({ 'rect': (r['min_x'], r['min_y'], r['max_x'] - r['min_x'], r['max_y'] - r['min_y']), 'size': r['size'], 'labels': r['labels'] }) return img, regions
1.4 ss方法生成的推荐区域示例
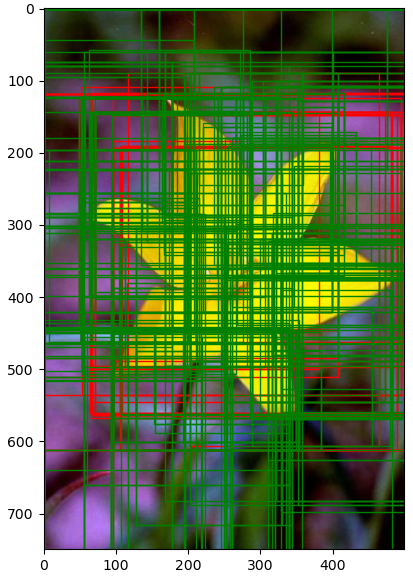
2. 特征提取和分类
RCNN采用CNN作为特征提取器,本文使用Alexnet作为特征提取backbone。
2.1 特征提取和分类流程
2.1.1 数据集准备:
a. 基于2flowers数据(带真实边界框标记信息)数据,利用ss方法生成候选区域proposals
b. 根据候选区域与真实边界框的IoU结果,将候选区域分为3类(0为背景label,1和2为物体label)
c. 保存3类候选区图像,并记录label为1和2的物体的边界框信息便于后续回归模型使用
ss方法数据集生成代码:
# SelectiveSearch.py # -*- coding: utf-8 -*- import os import numpy as np import pandas as pd import cv2 as cv import shutil from Utils import cal_IoU from skimage import io import SelectiveSearchCode as Select from multiprocessing import Process, Lock import threading import matplotlib.pyplot as plt import matplotlib.patches as patches class SelectiveSearch: def __init__(self, root, max_pos_regions: int = None, max_neg_regions: int = None, threshold=0.5): """ 采用ss方法生成候选区域文件 :param root: 训练/验证数据集所在路径 :param max_pos_regions: 每张图片最多产生的正样本候选区域个数, None表示不进行限制 :param max_neg_regions: 每张图片最多产生的负样本候选区域个数, None表示不进行限制 :param threshold: IoU进行正负样本区分时的阈值 """ self.source_root = os.path.join(root, 'source') self.ss_root = os.path.join(root, 'ss') self.csv_path = os.path.join(self.source_root, "gt_loc.csv") self.max_pos_regions = max_pos_regions self.max_neg_regions = max_neg_regions self.threshold = threshold self.info = None @staticmethod def cal_proposals(img, scale=200, sigma=0.7, min_size=20, use_cv=True) -> np.ndarray: """ 计算后续区域坐标 :param img: 原始输入图像 :param scale: 控制ss方法初始聚类大小 :param sigma: ss方法高斯核参数 :param min_size: ss方法最小像素数 :param use_cv: (bool) true-采用cv生成候选区域, false-利用源码生成 :return: candidates, 候选区域坐标矩阵n*4维, 每列分别对应[x, y, w, h] """ rows, cols, channels = img.shape if use_cv: # 生成候选区域 ss = cv.ximgproc.segmentation.createSelectiveSearchSegmentation() ss.setBaseImage(img) ss.switchToSelectiveSearchFast() proposals = ss.process() candidates = set() # 对区域进行限制 for region in proposals: rect = tuple(region) if rect in candidates: continue # # 限制区域框形状和大小 # x1, y1, w, h = rect # if w * h < 500: # continue # if w / h > 2 or h / w > 2 or w / cols < 0.05 or h / rows < 0.05: # continue candidates.add(rect) else: # ss方法返回4通道图像img_lbl, 其前三通道为rgb值, 最后一个通道表示该proposal-region在ss方法实现过程中所属的区域标签 # ss方法返回字典regions, regions['rect']为(x, y, w, h), regions['size']为像素数, regions['labels']为区域包含的对象的类别标签 img_lbl, regions = Select.selective_search(im_orig=img, scale=scale, sigma=sigma, min_size=min_size) candidates = set() for region in regions: # excluding same rectangle with different segments if region['rect'] in candidates: continue # # 限制区域框形状和大小 # x1, y1, w, h = rect # if w * h < 500: # continue # if w / h > 2 or h / w > 2 or w / cols < 0.05 or h / rows < 0.05: # continue candidates.add(region['rect']) candidates = np.array(list(candidates)) return candidates def save(self, num_workers=1, method="thread"): """ 生成目标区域并保存 :param num_workers: 进程或线程数 :param method: 多进程-process或者多线程-thread :return: None """ self.info = pd.read_csv(self.csv_path, header=0, index_col=None) # label为0存储背景图, label不为0存储带目标图像 categories = list(self.info['label'].unique()) categories.append(0) for category in categories: folder = os.path.join(self.ss_root, str(category)) os.makedirs(folder, exist_ok=True) index = self.info.index.to_list() span = len(index) // num_workers # 使用文件锁进行后续文件写入, 防止多进程或多线程由于并发写入出现的竞态条件, 即多个线程或进程同时访问和修改同一资源时,导致数据不一致或出现意外的结果 # 获取文件锁,确保只有一个进程或线程可以执行写入操作。在完成写入操作后,释放文件锁,允许其他进程或线程进行写入。防止过程中出现错误或者空行等情况 lock = Lock() # 多进程生成图像 if "process" in method.lower(): print("=" * 8 + "开始多进程生成候选区域图像" + "=" * 8) processes = [] for i in range(num_workers): if i != num_workers - 1: p = Process(target=self.save_proposals, kwargs={'lock': lock, 'index': index[i * span: (i + 1) * span]}) else: p = Process(target=self.save_proposals, kwargs={'lock': lock, 'index': index[i * span:]}) p.start() processes.append(p) for p in processes: p.join() # 多线程生成图像 elif "thread" in method.lower(): print("=" * 8 + "开始多线程生成候选区域图像" + "=" * 8) threads = [] for i in range(num_workers): if i != num_workers - 1: thread = threading.Thread(target=self.save_proposals, kwargs={'lock': lock, 'index': index[i * span: (i + 1) * span]}) else: thread = threading.Thread(target=self.save_proposals, kwargs={'lock': lock, 'index': index[i * span: (i + 1) * span]}) thread.start() threads.append(thread) for thread in threads: thread.join() else: print("=" * 8 + "开始生成候选区域图像" + "=" * 8) self.save_proposals(lock=lock, index=index) return None def save_proposals(self, lock, index, show_fig=False): """ 生成候选区域图片并保存相关信息 :param lock: 文件锁, 防止写入文件错误 :param index: 文件index :param show_fig: 是否展示后续区域划分结果 :return: None """ for row in index: name = self.info.iloc[row, 0] label = self.info.iloc[row, 1] # gt值为[x, y, w, h] gt_box = self.info.iloc[row, 2:].values im_path = os.path.join(self.source_root, name) img = io.imread(im_path) # 计算推荐区域坐标矩阵[x, y, w, h] proposals = self.cal_proposals(img=img) # 计算proposals与gt的IoU结果 IoU = cal_IoU(proposals, gt_box) # 根据IoU阈值将proposals图像划分到正负样本集 boxes_p = proposals[np.where(IoU >= self.threshold)] boxes_n = proposals[np.where((IoU < self.threshold) & (IoU > 0.1))] # 展示proposals结果 if show_fig: fig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6)) ax.imshow(img) for (x, y, w, h) in boxes_p: rect = patches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1) ax.add_patch(rect) for (x, y, w, h) in boxes_n: rect = patches.Rectangle((x, y), w, h, fill=False, edgecolor='green', linewidth=1) ax.add_patch(rect) plt.show() # loc.csv用于存储带有目标图像的boxes_p边界框信息 loc_path = os.path.join(self.ss_root, "ss_loc.csv") # 将正样本按照对应label存储到相应文件夹下, 并记录bbox的信息到loc.csv中用于后续bbox回归训练 num_p = num_n = 0 for loc in boxes_p: num_p += 1 crop_img = img[loc[1]: loc[1] + loc[3], loc[0]: loc[0] + loc[2], :] crop_name = name.split("/")[-1].replace(".jpg", "_" + str(num_p) + ".jpg") crop_path = os.path.join(self.ss_root, str(label), crop_name) with lock: # 保存的ss区域仍然为[x, y, w, h] with open(loc_path, 'a', newline='') as fa: fa.writelines([crop_path, ',', str(loc[0]), ',', str(loc[1]), ',', str(loc[2]), ',', str(loc[3]), '\n']) fa.close() io.imsave(fname=crop_path, arr=crop_img, check_contrast=False) if self.max_pos_regions is None: continue if num_p == self.max_pos_regions: break # 将负样本按照存储到"./0/"文件夹下, 其bbox信息对于回归训练无用, 故不用记录 for loc in boxes_n: num_n += 1 crop_img = img[loc[1]: loc[1] + loc[3], loc[0]: loc[0] + loc[2], :] crop_name = name.split("/")[-1].replace(".jpg", "_" + str(num_n) + ".jpg") crop_path = os.path.join(self.ss_root, "0", crop_name) io.imsave(fname=crop_path, arr=crop_img, check_contrast=False) if self.max_neg_regions is None: continue if num_n == self.max_neg_regions: break print("{name}: {num_p}个正样本, {num_n}个负样本".format(name=name, num_p=num_p, num_n=num_n)) if __name__ == '__main__': data_root = "./data" ss_root = os.path.join(data_root, "ss") if os.path.exists(ss_root): print("正在删除{}目录下原有数据".format(ss_root)) shutil.rmtree(ss_root) print("正在利用选择性搜索方法创建数据集: {}".format(ss_root)) select = SelectiveSearch(root=data_root, max_pos_regions=None, max_neg_regions=40, threshold=0.5) select.save(num_workers=os.cpu_count(), method="thread")
2.1.2 预训练:在17-flowers数据集上对Alexnet模型进行分类训练,获得pretrain模型,使之适应当前的任务
2.1.3 分类模型训练:基于3类候选区域图像,对pretrain模型进行微调,生成微调后的classify模型
2.1.4 特征提取:上面生成的classify模型也是Alexnet结构,去除所有全连接层,classify.features(img)的输出结果即所需特征
2.2 模型结果
2.2.1 预训练模型结果示例:

2.2.2 分类模型结果示例:

3. 候选框位置修正
使用线性回归模型对候选框位置进行修正,流程如下:
a. 将2.1.1中生成的label为1和2的图像输入classify模型,获得对应的图像特征作为回归模型输入
b. 将上述图像对应的边界框与真实边界框的偏移值作为回归模型的label
c. 基于特征和偏移值训练regress模型
各阶段模型训练代码:
# Train.py import os import matplotlib.pyplot as plt import numpy as np import pandas as pd from torch.utils.data import DataLoader import torch from torch import nn from torchvision import transforms from torch.optim.lr_scheduler import StepLR import Utils def train(data_loader, network, num_epochs, optimizer, scheduler, criterion, device, train_rate=0.8, mode="classify"): """ 模型训练 :param data_loader: 数据dataloader :param network: 网络结构 :param num_epochs: 训练轮次 :param optimizer: 优化器 :param scheduler: 学习率调度器 :param criterion: 损失函数 :param device: CPU/GPU :param train_rate: 训练集比例 :param mode: 模型类型, 预训练-pretrain, 分类-classify, 回归-regression :return: None """ os.makedirs('./model', exist_ok=True) network = network.to(device) criterion = criterion.to(device) best_acc = 0.0 best_loss = np.inf print("=" * 8 + "开始训练{mode}模型".format(mode=mode.lower()) + "=" * 8) batch_num = len(data_loader) train_batch_num = round(batch_num * train_rate) train_loss_all, val_loss_all, train_acc_all, val_acc_all = [], [], [], [] for epoch in range(num_epochs): train_num = val_num = 0 train_loss = val_loss = 0.0 train_corrects = val_corrects = 0 for step, (x, y) in enumerate(data_loader): x, y = x.to(device), y.to(device) # 模型训练 if step < train_batch_num: network.train() y_hat = network(x) loss = criterion(y_hat, y) optimizer.zero_grad() loss.backward() optimizer.step() # 计算每个batch的loss结果与预测正确的数量 label_hat = torch.argmax(y_hat, dim=1) # 预训练/分类模型计算loss和acc, 回归模型只计算loss if mode.lower() == 'pretrain' or mode.lower() == 'classify': train_corrects += (label_hat == y).sum().item() train_loss += loss.item() * x.size(0) train_num += x.size(0) # 模型验证 else: network.eval() with torch.no_grad(): y_hat = network(x) loss = criterion(y_hat, y) label_hat = torch.argmax(y_hat, dim=1) if mode.lower() == 'pretrain' or mode.lower() == 'classify': val_corrects += (label_hat == y).sum().item() val_loss += loss.item() * x.size(0) val_num += x.size(0) scheduler.step() # 记录loss和acc变化曲线 train_loss_all.append(train_loss / train_num) val_loss_all.append(val_loss / val_num) if mode.lower() == 'pretrain' or mode.lower() == 'classify': train_acc_all.append(100 * train_corrects / train_num) val_acc_all.append(100 * val_corrects / val_num) print("Mode:{} Epoch:[{:0>3}|{}] train_loss:{:.3f} train_acc:{:.2f}% val_loss:{:.3f} val_acc:{:.2f}%".format( mode.lower(), epoch + 1, num_epochs, train_loss_all[-1], train_acc_all[-1], val_loss_all[-1], val_acc_all[-1] )) else: print("Mode:{} Epoch:[{:0>3}|{}] train_loss:{:.3f} val_loss:{:.3f}".format( mode.lower(), epoch + 1, num_epochs, train_loss_all[-1], val_loss_all[-1] )) # 保存模型 # 预训练/分类模型选取准确率最高的参数 if mode.lower() == "pretrain" or mode.lower() == "classify": if val_acc_all[-1] > best_acc: best_acc = val_acc_all[-1] save_path = os.path.join("./model", mode + ".pth") # torch.save(network.state_dict(), save_path) torch.save(network, save_path) # 回归模型选取损失最低的参数 else: if val_loss_all[-1] < best_loss: best_loss = val_loss_all[-1] save_path = os.path.join("./model", mode + ".pth") # torch.save(network.state_dict(), save_path) torch.save(network, save_path) # 绘制训练曲线 if mode.lower() == "pretrain" or mode.lower() == "classify": fig_path = os.path.join("./model/", mode + "_curve.png") plt.subplot(121) plt.plot(range(num_epochs), train_loss_all, "r-", label="train") plt.plot(range(num_epochs), val_loss_all, "b-", label="val") plt.title("Loss") plt.legend() plt.subplot(122) plt.plot(range(num_epochs), train_acc_all, "r-", label="train") plt.plot(range(num_epochs), val_acc_all, "b-", label="val") plt.title("Acc") plt.legend() plt.tight_layout() plt.savefig(fig_path) plt.close() else: fig_path = os.path.join("./model/", mode + "_curve.png") plt.plot(range(num_epochs), train_loss_all, "r-", label="train") plt.plot(range(num_epochs), val_loss_all, "b-", label="val") plt.title("Loss") plt.legend() plt.tight_layout() plt.savefig(fig_path) plt.close() return None def run(train_root=None, network=None, batch_size=64, criterion=None, device=None, train_rate=0.8, epochs=10, lr=0.001, mode="classify", show_fig=False): """ 模型训练 :param train_root: 待训练数据路径 :param network: 模型结构 :param batch_size: batch size :param criterion: 损失函数 :param device: CPU/GPU :param train_rate: 训练集比率 :param epochs: 训练轮次 :param lr: 学习率 :param mode: 模型类型 :param show_fig: 是否展示训练结果 :return: None """ # 判断transform参数文件是否存在 transform_params_path = "./model/pretrain_transform_params.csv" if mode == "pretrain" else "./model/classify_transform_params.csv" exist = os.path.exists(transform_params_path) if not exist: print("正在计算{}模型归一化参数...".format(mode)) transform_params = Utils.cal_norm_params(root=train_root) pf = pd.DataFrame(transform_params) pf.to_csv(transform_params_path, header=False, index=False) else: transform_params = pd.read_csv(transform_params_path, header=None, index_col=None).values transform_params = [x[0] for x in transform_params] # transforms数据预处理 transform = transforms.Compose([transforms.ToTensor(), transforms.Resize((227, 227)), transforms.Normalize(mean=transform_params[0: 3], std=transform_params[3: 6])]) # 判断模型是否已经存在 model_path = "./model/" + mode + ".pth" exist = os.path.exists(model_path) if not exist: print("目标路径下不存在{}模型".format(mode)) # 预训练和分类模型直接加载数据文件 if mode == "pretrain" or mode == "classify": optimizer = torch.optim.SGD(params=network.parameters(), lr=lr, momentum=0.9, weight_decay=0.1) scheduler = StepLR(optimizer, step_size=5, gamma=0.5) train_set = Utils.DataSet(root=train_root, transform=transform) train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True) # 模型训练 train(data_loader=train_loader, network=network, num_epochs=epochs, optimizer=optimizer, scheduler=scheduler, criterion=criterion, device=device, train_rate=train_rate, mode=mode) # 回归模型需利用分类模型计算特征, 作为模型输入 else: # 加载分类模型 classifier = torch.load("./model/classify.pth") # 加载回归任务数据文件 ss_csv_path = "./data/ss/ss_loc.csv" gt_csv_path = "./data/source/gt_loc.csv" print("正在利用微调分类模型计算特征作为回归模型的输入...") train_set = Utils.RegressDataSet(ss_csv_path=ss_csv_path, gt_csv_path=gt_csv_path, network=classifier, device=device, transform=transform) train_loader = DataLoader(train_set, batch_size=32, shuffle=True) print("已完成回归模型数据集创建") # 定义线性回归模型并初始化权重 regressor = nn.Sequential(nn.AdaptiveAvgPool2d((6, 6)), nn.Flatten(), nn.Linear(256 * 6 * 6, 4)) nn.init.xavier_normal_(regressor[-1].weight) optimizer = torch.optim.SGD(params=regressor.parameters(), lr=lr, momentum=0.9, weight_decay=0.0005) scheduler = StepLR(optimizer, step_size=10, gamma=0.5) # 训练回归模型 train(data_loader=train_loader, network=regressor, num_epochs=epochs, optimizer=optimizer, scheduler=scheduler, criterion=criterion, device=device, train_rate=0.8, mode="regress") # 图像显示训练结果 if show_fig: if mode != "regress": Utils.show_predict(dataset=train_set, network=network, device=device, transform=transform, save=mode) else: print("目标路径下已经存在{}模型".format(mode)) if show_fig: network = torch.load(model_path) # 加载数据文件 train_set = Utils.DataSet(root=train_root, transform=transform) if mode != "regress": Utils.show_predict(dataset=train_set, network=network, device=device, transform=transform, save=mode) return if __name__ == "__main__": if not os.path.exists("./data/ss"): raise FileNotFoundError("数据不存在, 请先运行SelectiveSearch.py生成目标区域") device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') criterion = [nn.CrossEntropyLoss(), nn.MSELoss()] model_root = "./model" os.makedirs(model_root, exist_ok=True) # 在17flowers数据集上进行预训练 pretrain_root = "./data/source/17flowers/jpg" pretrain_net = Utils.Alexnet(pretrained=True, num_classes=17) run(train_root=pretrain_root, network=pretrain_net, batch_size=128, criterion=criterion[0], device=device, train_rate=0.8, epochs=15, lr=0.001, mode="pretrain", show_fig=True) # 在由2flowers生成的ss数据上进行背景/物体多分类训练 classify_root = "./data/ss" classify_net = torch.load("./model/pretrain.pth") classify_net.classifier[-1] = nn.Linear(in_features=4096, out_features=3) run(train_root=classify_root, network=classify_net, batch_size=128, criterion=criterion[0], device=device, train_rate=0.8, epochs=15, lr=0.001, mode="classify", show_fig=True) # 在由2flowers生成的ss物体数据进行边界框回归训练 run(batch_size=128, criterion=criterion[1], device=device, train_rate=0.8, epochs=50, lr=0.0001, mode="regress", show_fig=False)
4. 预测
如上我们获得了classify模型用于提取图像特征和分类,regress模型用于计算边界框偏移值,接下来可以进行目标预测。
4.1 预测流程
a. 利用ss方法生成候选区域proposals,记录对应的边界框信息
b. 将proposals输入classify模型获取分类标签,分类标签为0则该区域为背景,否则为物体
c. 提取标签不为0的区域的图像特征,并将其送入regress模型,获取预测的边界框偏移值
d. 选取L1范数最小的偏移值,将最小偏移值与其对应的边界框位置相加,作为最终的预测结果
预测阶段代码:
# Predict.py import os import torch from torchvision import transforms from SelectiveSearch import SelectiveSearch import Utils import numpy as np import pandas as pd from skimage import io def predict(im_path, classifier, regressor, transform, device): """ 回归模型预测 :param im_path: 输入图像路径 :param classifier: 分类模型 :param regressor: 回归模型 :param transform: 预处理方法 :param device: CPU/GPU :return: None """ classifier = classifier.to(device) regressor = regressor.to(device) # 计算proposal region img = io.imread(im_path) save_name = im_path.split(os.sep)[-1] proposals = SelectiveSearch.cal_proposals(img=img) boxes, offsets = [], [] for box in proposals: with torch.no_grad(): crop = img[box[1]: box[1] + box[3], box[0]: box[0] + box[2], :] crop_tensor = transform(crop).unsqueeze(0).to(device) # 分类模型检测有物体, 才进行后续回归模型计算坐标偏移值 out = classifier(crop_tensor) if torch.argmax(out).item(): features = classifier.features(crop_tensor) offset = regressor(features).squeeze(0).to(device) offsets.append(offset) boxes.append(torch.tensor(box, dtype=torch.float32, device=device)) if boxes is not None: offsets, boxes = torch.vstack(offsets), torch.vstack(boxes) # 以坐标偏移的L1范数最小作为最终box选择标准 index = offsets.abs().sum(dim=1).argmin().item() boxes = boxes[index] + offsets[index] Utils.draw_box(img, np.array(boxes.unsqueeze(0).cpu()), save_name=save_name) else: Utils.draw_box(img, save_name=save_name) return None if __name__ == "__main__": device = torch.device('cuda:0') # 加载分类模型和回归模型 classifier_path = './model/classify.pth' classifier = torch.load(classifier_path) regressor_path = './model/regress.pth' regressor = torch.load(regressor_path) classifier.eval() regressor.eval() # transforms数据预处理 transform_params_path = "./model/classify_transform_params.csv" transform_params = pd.read_csv(transform_params_path, header=None, index_col=None).values transform_params = [x[0] for x in transform_params] transform = transforms.Compose([transforms.ToTensor(), transforms.Resize((227, 227)), transforms.Normalize(mean=transform_params[0: 3], std=transform_params[3: 6])]) root = "./data/source/17flowers" for roots, dirs, files in os.walk(root): for file in files: if not file.endswith(".jpg"): continue img_path = os.path.join(roots, file) predict(im_path=img_path, classifier=classifier, regressor=regressor, transform=transform, device=device)
4.2 预测结果


三、算法缺点
相较于传统算法,RCNN检测精度得到了极大的提高,速度也得到了一定提升,但是仍然不能适应实时检测任务,原因如下:
a. 使用ss方法生成候选目标区域较慢
b. 生成的候选区域太多(原文中每张图像约2k个区域),每个区域均需要计算特征,存在大量重复计算
c. 分类、特征提取和边界框回归独立进行,效率低
四、数据和代码
本文中数据和详细代码实现请移步:https://github.com/jchsun1/RCNN
Reference:
- https://blog.csdn.net/zhangyoufei9999/article/details/80406423
- [pytorch] RCNN物体检测的简化实现(d2l-香蕉数据集)_pytorch实现rcnn_故你,的博客-CSDN博客
本文至此结束,如有疑惑欢迎留言交流。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号