
SPARK学习笔记
SPARK系统架构
Hadoop虽然已成为大数据技术的事实标准,最主要的缺陷是其MapReduce计算模型延迟过高以及磁盘IO开销大,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。
SPARK相比于Hadoop的优势,
1)Spark提供了内存计算, 大大减少了IO开销,中间结果直接放到内存中,带来了更高的迭代运算效率;
2)Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
几个重要的概念:
RDD:弹性分布式数据集(Resilient Distributed Dataset),是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
DAG:Directed Acyclic Graph(有向无环图),反映RDD之间的宽(父RDD的一个分区对应多个子RDD分区)窄(父RDD的一个分区只对应一个子RDD分区)依赖关系;
Executor:是运行在工作节点(Worker Node)上的一个进程,负责运行任务,并为应用程序存储数据;
应用:用户编写的Spark应用程序;
任务:运行在Executor上的工作单元;
作业:一个作业包含多个RDD及作用于相应RDD上的各种操作;
阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”。
结构设计
Spark运行架构包括集群资源管理器(Cluster Manager)、运行作业任务的工作节点(Worker Node)、每个应用的任务控制节点(Driver)和每个工作节点上负责具体任务的执行进程(Executor)。其中,集群资源管理器可以是Spark自带的资源管理器,也可以是YARN或Mesos等资源管理框架。
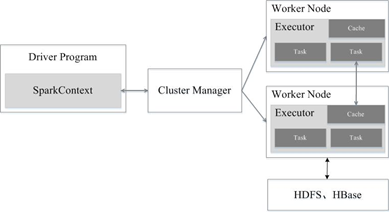
基本运行流程
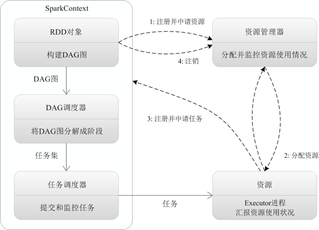
1. 我们从Client提交一个Spark应用,然后需要为这个应用构建起基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext,由SparkContext负责和资源管理器(Cluster Manager)的通信以及进行资源的申请、任务的分配和监控等。SparkContext会向资源管理器注册并申请运行Executor的资源;
2. 资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上;
3. SparkContext根据RDD的依赖关系构建DAG图,DAG图提交给DAG调度器(DAGScheduler)进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器(TaskScheduler)进行处理;Executor向SparkContext申请任务,任务调度器将任务分发给Executor运行,同时,SparkContext将应用程序代码发放给Executor;
4. 任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
Spark运行模式
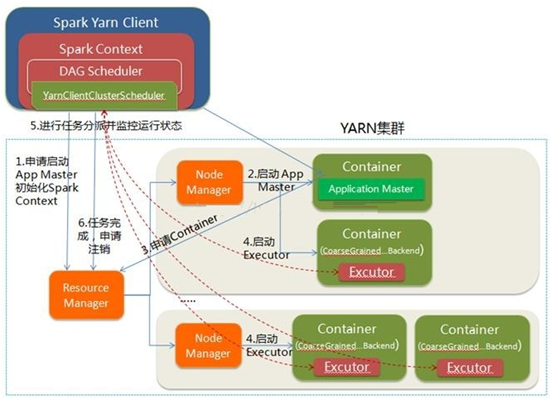
YARN-Client
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开,适用于交互和调试,也就是希望快速地看到application的输出。
在Yarn-client中,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。因为Driver在客户端,所以可以通过webUI访问Driver的状态,默认是http://hadoop1:4040访问,而YARN通过http:// hadoop1:8088访问
其流程如下:
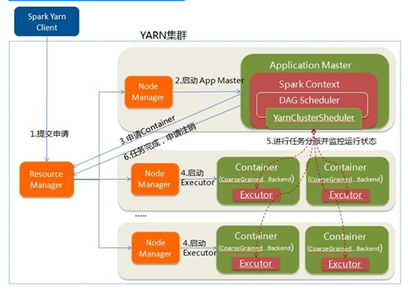
Yarn-Cluster
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业,适用于生产环境。
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;
第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况,下图是yarn-cluster模式。
RDD
RDD:是弹性分布式数据集(Resilient Distributed Dataset)指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用,并且同一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
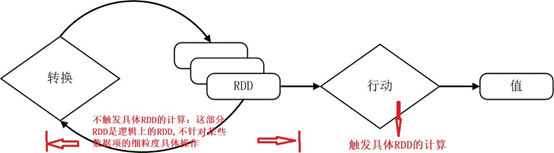
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action 用于执行计算并指定输出的形式,接受RDD但是返回非RDD而是输出一个值或结果如count、collect等)和“转换”(Transformation 指定RDD之间的相互依赖关系,接受RDD并返回RDD如map、filter、groupBy、join等)两种类型。
RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
Dependencies依赖关系
建立RDD的依赖关系,主要rdd之间是宽窄依赖的关系,具有窄依赖关系的rdd可以在同一个stage中进行计算。
RDD 的 Transformation 函数中不同的操作会使得不同RDD中的分区会产生不同的依赖,RDD中的依赖关系分为窄依赖(Narrow Dependency 父RDD的分区:子RDD的分区=N:1)与宽依赖(Wide Dependency 父RDD的分区:子RDD的分区=M:N)。窄依赖跟宽依赖的区别是是否发生 shuffle(洗牌) 操作.宽依赖会发生 shuffle 操作. 窄依赖是子 RDD的各个分片(partition)不依赖于其他分片,能够独立计算得到结果,宽依赖指子 RDD 的各个分片会依赖于父RDD 的多个分片,所以会造成父 RDD 的各个分片在集群中重新分片。所以shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤.
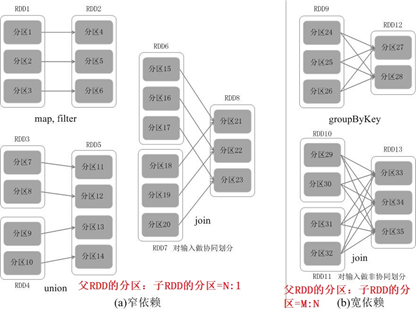
如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。
Stage阶段的划分
spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
根据RDD分区的依赖关系划分阶段

比如,分区7通过map操作生成的分区9,可以不用等待分区8到分区9这个转换操作的计算结束,而是继续进行union操作,转换得到分区13,这样流水线执行大大提高了计算的效率。
由上面可知,把一个DAG图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集合。每个任务集合会被提交给任务调度器(TaskScheduler)进行处理,由任务调度器将任务分发给Executor运行。
参考文章

