09 序列化器Serializer 与模型类序列化器ModelSerializer
序列化器的作用 1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型 3. 反序列化,完成数据校验功能
2 序列化器的序列化
2.1 基本使用
from django.db import models # Create your models here. class Book(models.Model): title = models.CharField(max_length=32,default='红') price = models.IntegerField(default='0') # pub_date = models.DateField() # sqlite对日期的处理有问题,换成mysql publish = models.CharField(max_length=32,default='出')
2.1.2 路由urls.py
from app01 import views urlpatterns = [ path('admin/', admin.site.urls), path('books/', views.BookView.as_view()), path('books/<int:pk>', views.BookDetailView.as_view()), ]
2.1.3 视图层views.py
from django.shortcuts import render # Create your views here. # def test(request): # request.session['name']='lqz' #### 查询所有图书的视图类 from rest_framework.views import APIView from app01.models import Book # 绝对导入 # from .models import Book # 相对导入,用了相对导入,当前py文件,不能以脚本形式运行 from .serializer import BookSerializer from rest_framework.response import Response # 针对于某个表模型,总共5个接口 # 获取所有 get # 获取单个 get # 删除单个 delete # 修改单个 update # 新增单个 post # 以后你写的所有接口(跟数据库相关),都是这个5个或这5个的变形 class BookView(APIView): def get(self, request, *args, **kwargs): # 查询出所有图书 books = Book.objects.all() # 把qs对象序列化成字典,使用序列化类完成序列化 # instance=None, 是要序列化的对象(可以是单个对象,可以是多个对象(放到列表或者qs对象),一定要写many=True) # data=empty 反序列化的字典,目前还没用到 print(books) ser = BookSerializer(instance=books, many=True) # 传入要序列化的数据 print(ser.data) # 返回给前端 ser.data 是个字典 # 如果是浏览器,会有一个好看的页面(注册app),如果是postman,就是json格式 return Response(data=ser.data) # 新增 def post(self, request, *args, **kwargs): # 前端传入的数据,在request.data中,是个字典 # 如果不使用序列化类,如何保存 # book=Book(title=request.data.get('title')) # book.save() # 使用序列化类做保存 ser = BookSerializer(data=request.data) # 数据校验:如果是True,表示校验通过,直接保存 if ser.is_valid(): ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写某个方法 return Response(ser.data) # 又做了一次序列化,返回给了前端 else: return Response(ser.errors) class BookDetailView(APIView): def get(self, request, pk): # 查询某一本图书 books = Book.objects.all().filter(pk=pk).first() ser = BookSerializer(instance=books) # 传入要序列化的数据 return Response(data=ser.data) def delete(self, request, pk): # 跟序列化类没有关系 Book.objects.all().filter(pk=pk).delete() return Response() def put(self, request, pk): book = Book.objects.filter(pk=pk).first() ser = BookSerializer(instance=book, data=request.data) # 数据校验:如果是True,表示校验通过,直接保存 if ser.is_valid(): ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写update方法 return Response(ser.data) # 又做了一次序列化,返回给了前端
# 写序列化类 from rest_framework import serializers from .models import Book from rest_framework.exceptions import ValidationError class BookSerializer(serializers.Serializer): # 一定要继承一个序列化的基类 # 写字段,你想序列化哪个字段,就写哪个 title = serializers.CharField(max_length=8, min_length=3) price = serializers.IntegerField() # pub_date = serializers.DateField() publish = serializers.CharField() # 重写create,使它能够支持新增保存 (派生) def create(self, validated_data): # validated_data校验过后的数据 book = Book.objects.create(**validated_data) return book # 一定不要忘了return 对象,否则在视图类中用ser.data 就报错了 # 重写 update 支持修改 def update(self, instance, validated_data): instance.title = validated_data.get('title') instance.price = validated_data.get('price') instance.publish = validated_data.get('publish') instance.save() return instance # validate_字段名 先走字段自己的,再走局部钩子 def validate_title(self, item): print(item) # 校验字段,不能以sb开头 if item.startswith('sb'): raise ValidationError('不能以sb开头') return item # 全局钩子 def validate(self, attrs): # 校验失败,抛异常 if attrs.get('title') == attrs.get('publish'): raise ValidationError('标题和出版社不能一样') return attrs
2.2 常用字段
注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。serializer是独立于数据库之外的存在。
常用字段类型:


2.3 常用字段参数
选项参数:
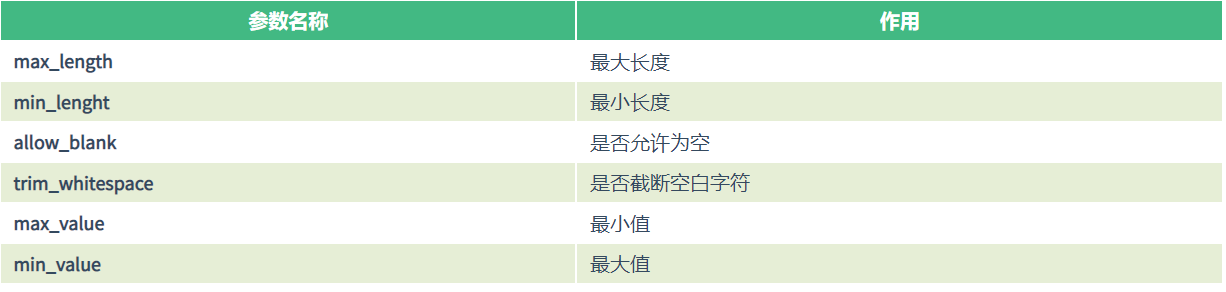
通用参数:
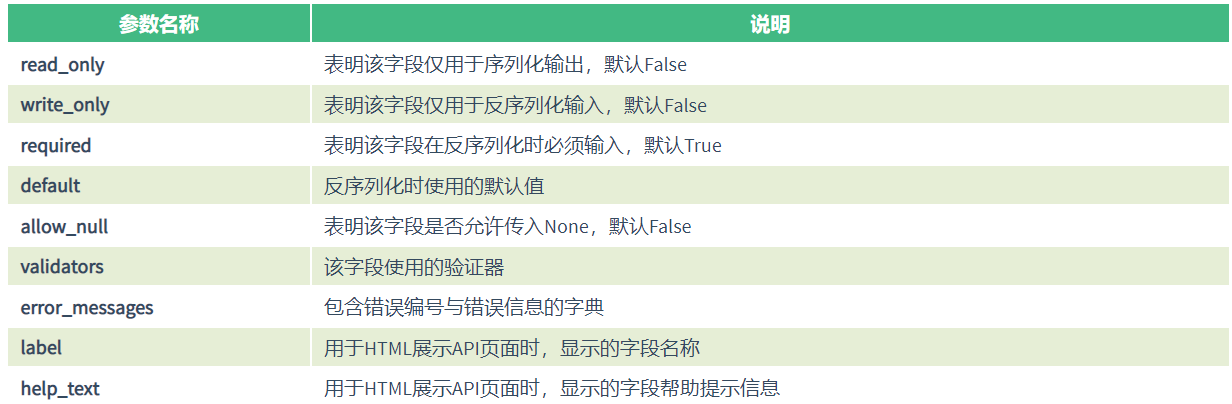
3 序列化器的反序列化
3.1 基本使用(需要重写create,update,见上面)
#新增
def post(self, request, *args, **kwargs): # 前端传入的数据,在request.data中,是个字典 # 如果不使用序列化类,如何保存 # book=Book(title=request.data.get('title')) # book.save() # 使用序列化类做保存 ser = BookSerializer(data=request.data) # 数据校验:如果是True,表示校验通过,直接保存 if ser.is_valid(): ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写某个方法 return Response(ser.data) # 又做了一次序列化,返回给了前端 else: return Response(ser.errors)
#修改
def put(self, request, pk): book = Book.objects.filter(pk=pk).first() ser = BookSerializer(instance=book, data=request.data) # 数据校验:如果是True,表示校验通过,直接保存 if ser.is_valid(): ser.save() # 调用保存,但是有问题,保存不了,一定要在序列化类中重写update方法 return Response(ser.data) # 又做了一次序列化,返回给了前端
3.2 数据校验
# 字段自己校验规则 title = serializers.CharField(max_length=8, min_length=3) # 局部钩子 # validate_字段名 先走字段自己的,再走局部钩子 def validate_title(self, item): print(item) # 校验字段,不能以sb开头 if item.startswith('sb'): raise ValidationError('不能以sb开头') return item # 全局钩子 def validate(self, attrs): # 校验失败,抛异常 if attrs.get('title') == attrs.get('publish'): raise ValidationError('标题和出版社不能一样') return attrs
4 模型类序列化器ModelSerializer
反序列化,正常情况不需要重写 create和update 序列化:跟表模型有对应关系,不需要一个个字段都写了
# class BookModelSerializer(serializers.ModelSerializer): # # 跟某个表模型建立关系 # class Meta: # model = Book # 跟哪个表建立关系 # fields = ['title','price','id','publish'] # 要序列化哪些字段 # # fields = '__all__' # 所有字段都序列化 # # # # 了解 # # exclude=['title'] # 除了某个字段外 # # depth=1 # 表关联 # # # # #重点 # # # read_only 只读,只序列化 # # # write_only # # # 重写某个字段 # title=serializers.CharField(max_length=8,min_length=3) # # # 局部和全局钩子跟之前一模一样 # # def validate_price(self, price): # if not price>100: # raise ValidationError('价格必须大于100') # # return price class BookModelSerializer(serializers.ModelSerializer): # 跟某个表模型建立关系 class Meta: model = Book # 跟哪个表建立关系 fields = ['title', 'price', 'id', 'publish'] # 要序列化哪些字段 # 重点 # 额外给某些字段传参数 # extra_kwargs = { # 'title': {'max_length': 8, 'min_length': 3}, # 'price': {'min_value': 100} # } # read_only 只读,只序列化 # write_only 只写,只做反序列化,这个字段不做序列化 extra_kwargs = { 'title': {'read_only': True}, # 'price': {'write_only': True} }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号