3 纯手撸web框架
""" 1.代码过于冗余 2.处理http数据繁杂 """ import socket server = socket.socket() server.bind(('127.0.0.1',8080)) # 端口号尽量使用8000之后的 server.listen(5) while True: conn, addr = server.accept() data = conn.recv(1024) data = data.decode('utf8') print(data) #GET /index HTTP/1.1 target_url = data.split(' ')[1] #/index conn.send(b'HTTP/1.1 200 OK\r\n\r\n') if target_url == '/index': conn.send(b'from index') elif target_url == '/login': conn.send(b'from login') elif target_url == '/func': with open(r'myhtml.html','rb') as f: for line in f: conn.send(line) else: conn.send(b'404 error')
字符转换的另一种方式:
s="hello jango!!!今天是个好日子"
res=bytes(s,"utf8")
print(res)
res1=str(res,"utf8")
print(res1)

复习
__call__ #当对象加括号的时候自动触发函数的执行 __str__ #当打印对象的时候自动触发执行 #返回值必须是字符串类型
wsgiref模块
我们利用wsgiref模块来替换我们自己写的web框架的socket server部分:
from wsgiref.simple_server import make_server def run(request, response): """ :param request:跟请求相关的数据 :param response: 跟响应相关的数据 :return: 返回值就是要给前端浏览器的数据 """ response('200 OK',[]) # print(request) # 自动帮我们处理了所有http协议相关的数据并组织成了一个大字典 target_url = request.get('PATH_INFO') if target_url == '/index': return [b'from index'] elif target_url == '/login': return [b'from login'] return [b'hello world'] if __name__ == '__main__': # 监听127.0.0.1:8080 一旦有请求 立刻将第三个参数加括号调用 server = make_server('127.0.0.1', 8080, run) # 启动服务端 server.serve_forever()
变形优化
针对后缀较多的情况 如何更加优化匹配 from wsgiref.simple_server import make_server def index(): return "index页面" def login(): return "login 页面" def error(): return "404 error" urls=[("/index",index),("/login",login)] def run(request,response): response("200 ok",[]) target_url=request.get("PATH_INFO") func=None for url_tuple in urls: if target_url==url_tuple[0]: func=url_tuple[1] break if func: res=func() else: res=error() return [res.encode('utf8')] if __name__ == '__main__': server=make_server("127.0.0.1",8080,run) server.serve_forever() '''以后新增功能只需要先写一个函数 然后加一组对应关系即可''' 针对同一个py文件内部代码功能繁杂的情况 拆分多个py文件 views.py 专门用于存放核心业务逻辑 urls.py 专门用于存放路径对应关系 templates 专门用于存放html文件 '''以后新增功能只需要views.py写函数 然后urls.py写对应关系即可'''
面条拌拆分
基于wsgiref模块撸web框架
from wsgiref.simple_server import make_server from urls import urls from views import error def run(request,response): response("200 ok",[]) target_url=request.get("PATH_INFO") func=None for url_tuple in urls: if target_url==url_tuple[0]: func=url_tuple[1] break if func: res=func() else: res=error() return [res.encode('utf8')] if __name__ == '__main__': server=make_server("127.0.0.1",8080,run) server.serve_forever()
urls.py
from views import * urls=[("/index",index), ("/login",login)]
views.py
def index(): return "index页面" def login(): return "login 页面" def error(): return "404 error"
实现连接展示html页面内容
def index(): # return "index页面" with open(r'templates/index.html','r',encoding='utf8') as f: return f.read() <body> <h1>index页面</h1> </body>
动静态网页
动态网页 数据不是直接写死在html页面上的 而是动态获取(后端)
静态网页 数据是直接写死在页面上的
使用我们自己写的web框架 完成一个动态页面的返回
get_time
def get_time(request): ctime=datetime.now().strftime("%Y-%m-%d %X") with open(r"templates/get_time.html","r",encoding='utf8') as f: data=f.read() data=data.replace("dsfbgfn",ctime) #替换 return data <h1>dsfbgfn</h1>
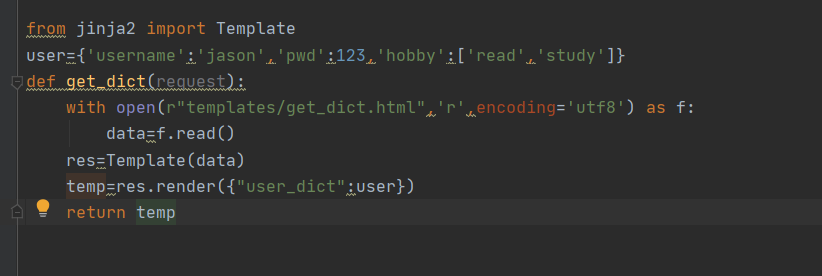
jinja2模块
上面的代码实现了一个简单的动态,我完全可以从数据库中查询数据,然后去替换我html中的对应内容,然后再发送给浏览器完成渲染。 这个过程就相当于HTML模板渲染数据。 本质上就是HTML内容中利用一些特殊的符号来替换要展示的数据。 我这里用的特殊符号是我定义的,其实模板渲染有个现成的工具:
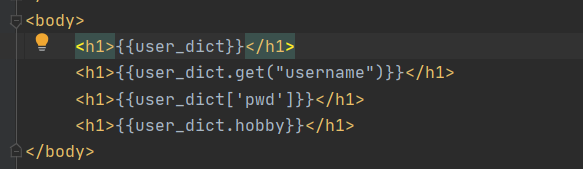
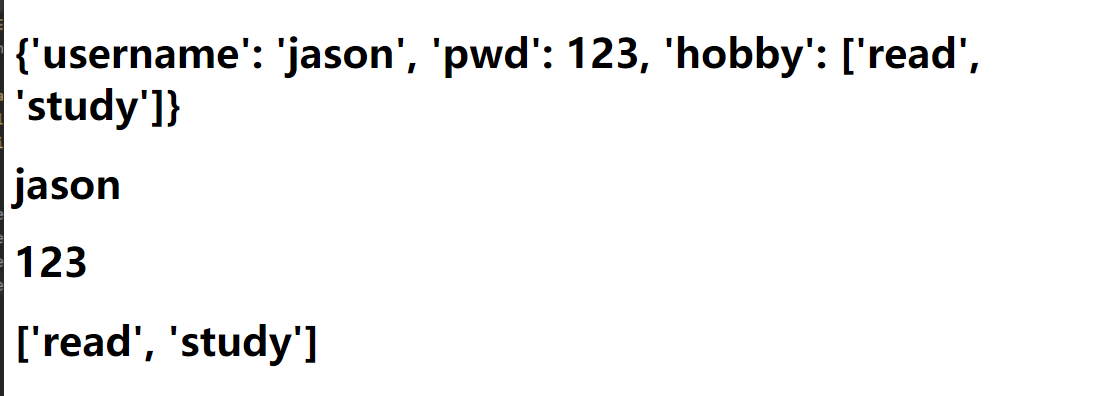
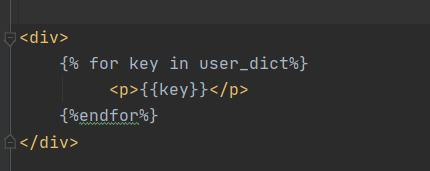
该模块提供了"模板语法" 支持后端给html页面传递数据并且支持后端语法 pip3 install jinja2 <h1>{{user_dict}}</h1> <h1>{{user_dict['username']}}</h1> <h1>{{user_dict.get('pwd')}}</h1> <h1>{{user_dict.hobby}}</h1> <div> {% for key in user_dict%} <p>{{ key }}</p> {% endfor %} </div>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号