8 explain句式与隔离级别
一、explain句式
什么是explain?
explain就是帮助我们查看SQL语句属于哪种扫描
1.explain命令使用方法
mysql> explain select name,countrycode from city where id=1;
即explain+sql语句;
2.查询数据的方式
(1)全表扫描
啥时候用全表扫描?
1,业务确实要获取所有数据
2,不走索引导致的全表扫描(没索引,索引创建有问题,语句有问题)
在explain语句结果中type为ALL
不走索引 一行行查找数据 效率极低
生产中,mysql在使用全表扫描时的性能是极其差的,所以MySQL尽量避免出现全表扫描
(2)索引扫描
走索引 加快数据查询 建议书写该类型SQL
常见的索引扫描的类型
1)index
2)range
3)ref
4)eq_ref
5)const
6)system
7)null
从上到下,性能从最差到最好,我们认为至少要达到range级别
详解索引类型(了解)
index:Full Index Scan,index与ALL区别为index类型只遍历索引树。
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。
mysql> alter table city add index idx_city(population);
mysql> explain select * from city where population>30000000;
ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行。
mysql> alter table city drop key idx_code;
mysql> explain select * from city where countrycode='chn';
mysql> explain select * from city where countrycode in ('CHN','USA');
mysql> explain select * from city where countrycode='CHN' union all select * from city where countrycode='USA';
eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件A
join B
on A.sid=B.sid
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
如将主键置于where列表中,MySQL就能将该查询转换为一个常量
mysql> explain select * from city where id=1000;
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
mysql> explain select * from city where id=1000000000000000000000000000;
不走索引情况(起码记忆四条及以上)
1.没有查询条件,或者查询条件没有建立索引
2.查询结果集是原表中的大部分数据(25%以上)
3.索引本身失效,统计数据不真实
4.查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+,-,*等)
5.隐式转换导致索引失效
eg:字段是字符类型 查询使用整型
6.<> ,not in 不走索引
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit、or或in尽量改成union
7.like "%_" 百分号在最前面不走
8.单独引用联合索引里非第一位置的索引列
索引的创建会加快数据的查询速度 但是一定程度会拖慢数据的插入和删除速度
详解(了解):
- 1.没有查询条件,或者查询条件没有建立索引
|
|
|
|
select * from table;
|
|
|
select * from tab where 1=1;
|
在业务数据库中,特别是数据量比较大的表,是没有全表扫描这种需求。
1)对用户查看是非常痛苦的。
2)对服务器来讲毁灭性的。
3)SQL改写成以下语句:
|
|
|
|
|
|
|
select * from table;
|
|
|
|
|
|
selec * from tab order by price limit 10;
|
|
|
|
|
|
|
|
|
select * from table where name='zhangsan';
|
|
|
1、换成有索引的列作为查询条件
|
|
|
2、将name列建立索引
|
- 2.查询结果集是原表中的大部分数据,应该是25%以上
mysql> explain select * from city where population>3000 order by population;
1)如果业务允许,可以使用limit控制。
2)结合业务判断,有没有更好的方式。如果没有更好的改写方案就尽量不要在mysql存放这个数据了,放到redis里面。
- 3.索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
重建索引就可以解决 - 4.查询条件使用函数在索引列上或者对索引列进行运算,运算包括(+,-,*等)
|
|
|
|
错误的例子:select * from test where id-1=9;
|
|
|
正确的例子:select * from test where id=10;
|
- 5.隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
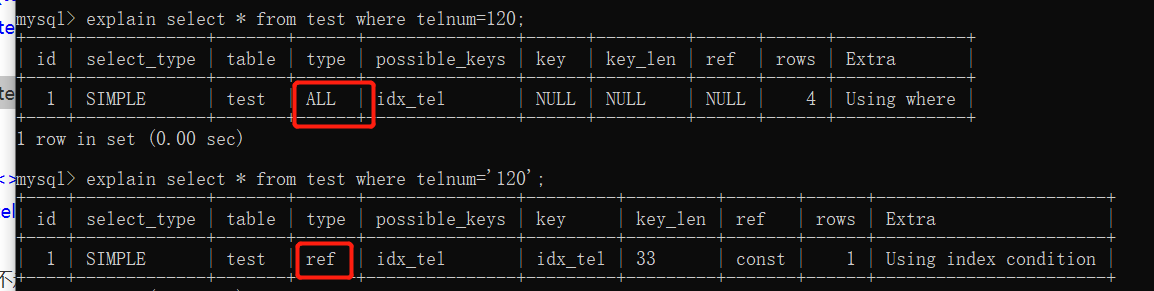
- 6. <> ,not in 不走索引
|
mysql> select * from tab where telnum <> '1555555';
|
|
|
mysql> explain select * from tab where telnum <> '1555555';
|
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit
or或in尽量改成union
|
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119');
|
|
|
#改写成
|
|
|
EXPLAIN SELECT * FROM teltab WHERE telnum='110'
|
|
|
UNION ALL
|
|
|
SELECT * FROM teltab WHERE telnum='119'
|
- 7.like "%_" 百分号在最前面不走
|
#走range索引扫描
|
|
|
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%';
|
|
|
#不走索引
|
|
|
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110';
|
%linux%类的搜索需求,可以使用Elasticsearch -------> ELK
- 8.单独引用联合索引里非第一位置的索引列
|
CREATE TABLE t1 (id INT,NAME VARCHAR(20),age INT ,sex ENUM('m','f'),money INT);
|
|
|
ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex);
|
|
|
DESC t1
|
|
|
SHOW INDEX FROM t1
|
|
|
#走索引的情况测试
|
|
|
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 AND sex='m';
|
|
|
#部分走索引
|
|
|
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30;
|
|
|
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND sex='m';
|
|
|
#不走索引
|
|
|
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=20
|
|
|
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=30 AND sex='m';
|
|
|
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex='m';
|
二、隔离级别
在SQL标准中定义了四种隔离级别,每一种级别都规定了一个事务中所做的修改
InnoDB支持所有隔离级别
set transaction isolation level 级别
1.read uncommitted(未提交读)
事务中的修改即使没有提交,对其他事务也都是可见的,事务可以读取未提交的数据,这一现象也称之为"脏读"
2.read committed(提交读)
大多数数据库系统默认的隔离级别
一个事务从开始直到提交之前所作的任何修改对其他事务都是不可见的,这种级别也叫做"不可重复读"
3.repeatable read(可重复读) # MySQL默认隔离级别
能够解决"脏读"问题,但是无法解决"幻读"
所谓幻读指的是当某个事务在读取某个范围内的记录时另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录会产生幻行,InnoDB和XtraDB通过多版本并发控制(MVCC)及间隙锁策略解决该问题
4.serializable(可串行读)
强制事务串行执行,很少使用该级别
更多:
https://www.cnblogs.com/Dominic-Ji/p/15560680.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号