JSOUP 暴力爬取实验
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.13.1</version>
</dependency>
下面用这个工具来暴力获取一个视频网站,各种视频的基本信息
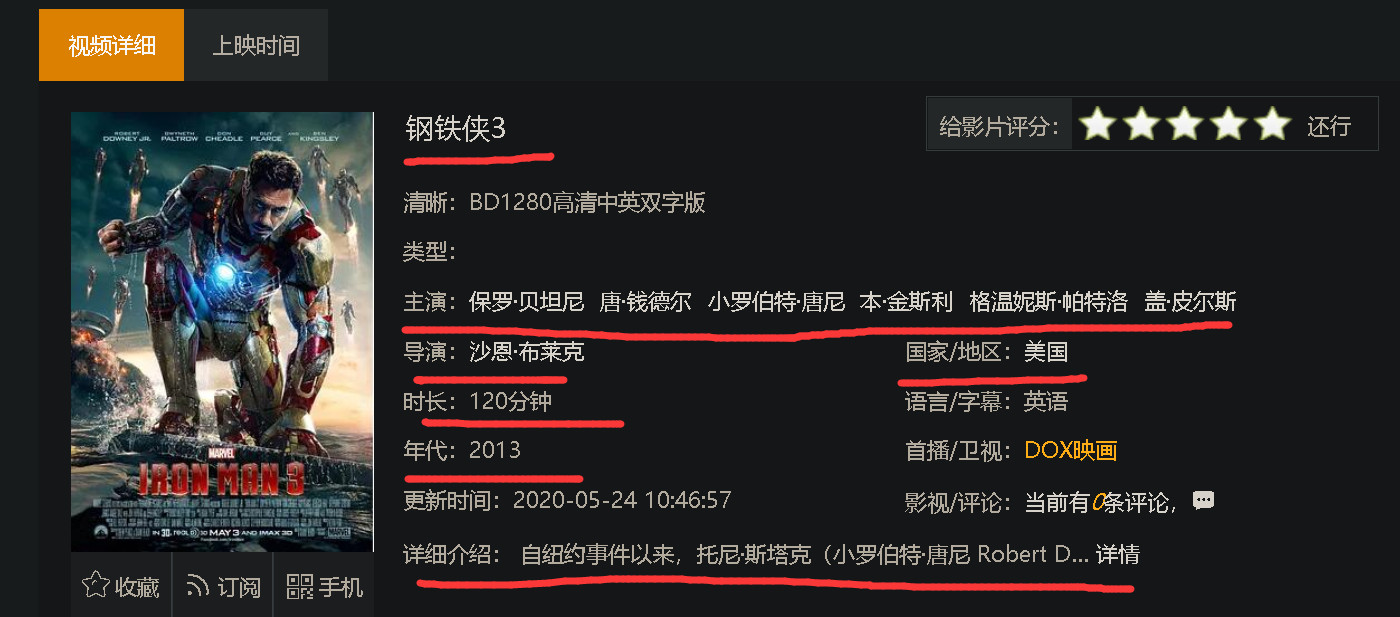
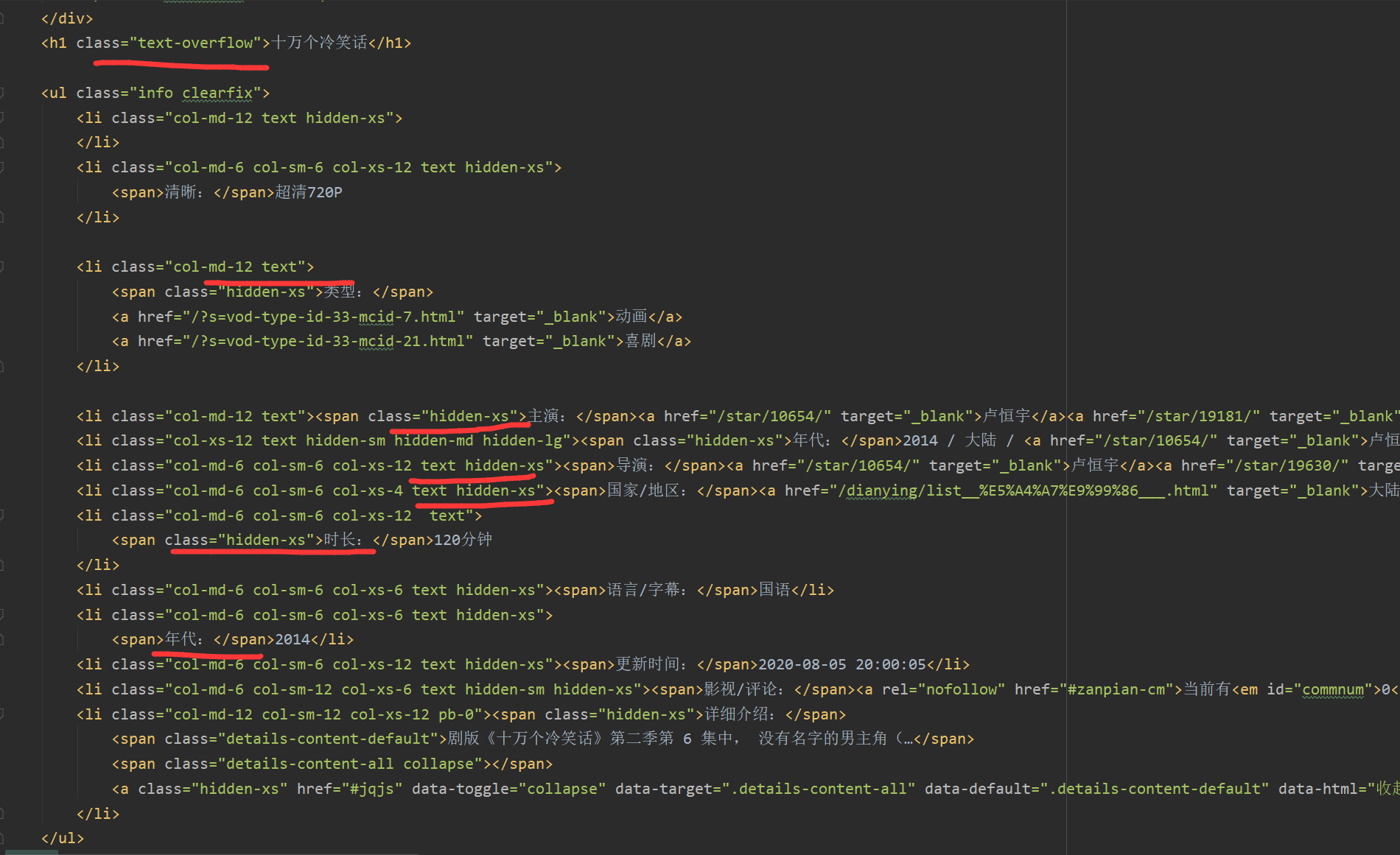
建立获取信息的实体类,以便后期可以存入数据库
package cn.haidnor.movie;
import lombok.Data;
import java.util.List;
@Data
public class Movie {
// URL
private String url;
// 影片名
private String name;
// 年代
private String years;
// 国家
private String country;
// 时长
private String minute;
// 类型
private List<String> types;
// 导演
private List<String> director;
// 主演
private List<String> performers;
// 详细信息
private String details;
}
编写爬取工具
package cn.haidnor.movie;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.List;
/**
* 全视频爬虫解析
* https://www.qsptv.net/
*
* @author haidnor
*/
public class QsptvReptile {
private static final int TIMEOUT = 8000;
private static int ip = 0;
/**
* 获取影片url资料
*
* @param url 视频连接
* @return Movie
*/
public Movie getMovie(String url,int id) throws Exception {
ip++;
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36")
.header("x-forwarded-for","1423" + ip + "")
.timeout(TIMEOUT).get();
Movie movie = new Movie();
// 设置 URL
movie.setUrl(url);
// 影片信息根元素
Element root = doc.getElementById("zanpian-score");
if (root == null) {
return movie;
}
// 影片名称
Element name = root.getElementsByTag("h1").get(0);
if (name != null) {
movie.setName(name.text());
}
// 年代
Element years = root.getElementsByClass("col-md-6 col-sm-6 col-xs-6 text hidden-xs").get(1);
if (years != null) {
years.getElementsByTag("span").remove();
movie.setYears(years.text());
}
// 国家
Element country = root.getElementsByClass("col-md-6 col-sm-6 col-xs-4 text hidden-xs").get(0).getElementsByTag("a").get(0);
if (country != null) {
movie.setCountry(country.text());
}
// 时长
Element minute = root.getElementsByClass("col-md-6 col-sm-6 col-xs-12 text").get(0);
if (minute != null) {
minute.getElementsByTag("span").remove();
movie.setMinute(minute.text());
}
// 类型
Elements types = root.getElementsByClass("col-md-12 text").get(0).getElementsByTag("a");
if (types != null) {
List<String> type = new ArrayList<String>();
for (Element element : types) {
type.add(element.text());
}
movie.setTypes(type);
}
// 主演
Elements performers = root.getElementsByClass("col-md-12 text").get(1).getElementsByTag("a");
if (performers != null) {
List<String> performer = new ArrayList<String>();
for (Element element : performers) {
performer.add(element.text());
}
movie.setPerformers(performer);
}
// 导演
Elements directors = root.getElementsByClass("col-md-6 col-sm-6 col-xs-12 text hidden-xs").get(1).getElementsByTag("a");
if (directors != null) {
List<String> director = new ArrayList<String>();
for (Element element : directors) {
director.add(element.text());
}
movie.setDirector(director);
}
// 影片详细信息
Element element = doc.getElementsByClass("details-content").last();
if (element != null) {
StringBuilder details = new StringBuilder(element.text());
int indexOf = details.lastIndexOf("全视频TV");
CharSequence charSequence = details.subSequence(0, indexOf);
movie.setDetails(charSequence.toString());
}
// 下载封面图片
Element picture = doc.getElementsByClass("video-pic").get(0);
StringBuilder style = new StringBuilder(picture.attr("style"));
String pictureUrl = style.substring(style.indexOf("(") + 1,style.indexOf(")"));
downloadPicture(pictureUrl,id);
return movie;
}
/**
* 下载图片
* @param pictureUrl
*/
static void downloadPicture(String pictureUrl,int id) throws Exception {
String filePath = "D:/picture";
File file = new File(filePath + "/" + id + ".jpg");
URL url = new URL(pictureUrl);
URLConnection connection = url.openConnection();
connection.setRequestProperty("User-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36");
connection.setRequestProperty("x-forwarded-for","143" + ip + "");
InputStream inputStream = connection.getInputStream();
DataInputStream dataInputStream = new DataInputStream(inputStream);
FileOutputStream fileOutputStream = new FileOutputStream(file);
ByteArrayOutputStream output = new ByteArrayOutputStream();
byte[] buffer = new byte[128];
int length;
while ((length = dataInputStream.read(buffer)) > 0) {
output.write(buffer, 0, length);
}
fileOutputStream.write(output.toByteArray());
output.close();
fileOutputStream.close();
dataInputStream.close();
}
public static void main(String[] args) throws Exception {
Movie movie = new QsptvReptile().getMovie("https://www.qsptv.net/show-2169.html",2169);
}
}
获取的元素需要自己去查看 HTML 来选择
开始爬取数据,这里开20个线程来获取数据
package cn.haidnor.movie;
public class Reptile implements Runnable {
// 资源最小值 1
private int index = 100;
// 资源最大值 83877
private int max = 9000;
static String urlPrefix = "https://www.qsptv.net/show-";
static String urlPostfix = ".html";
@Override
public void run() {
while (index <= max) {
String url = null;
try {
synchronized (this) {
url = urlPrefix + index + urlPostfix;
index++;
}
Movie movie = new QsptvReptile().getMovie(url, index);
System.out.println(movie);
} catch (Exception e) {
System.err.println("GET FAILED: " + url);
}
}
}
public static void main(String[] args) {
Reptile reptile = new Reptile();
for (int i = 0; i < 20; i++) {
new Thread(reptile).start();
}
}
}
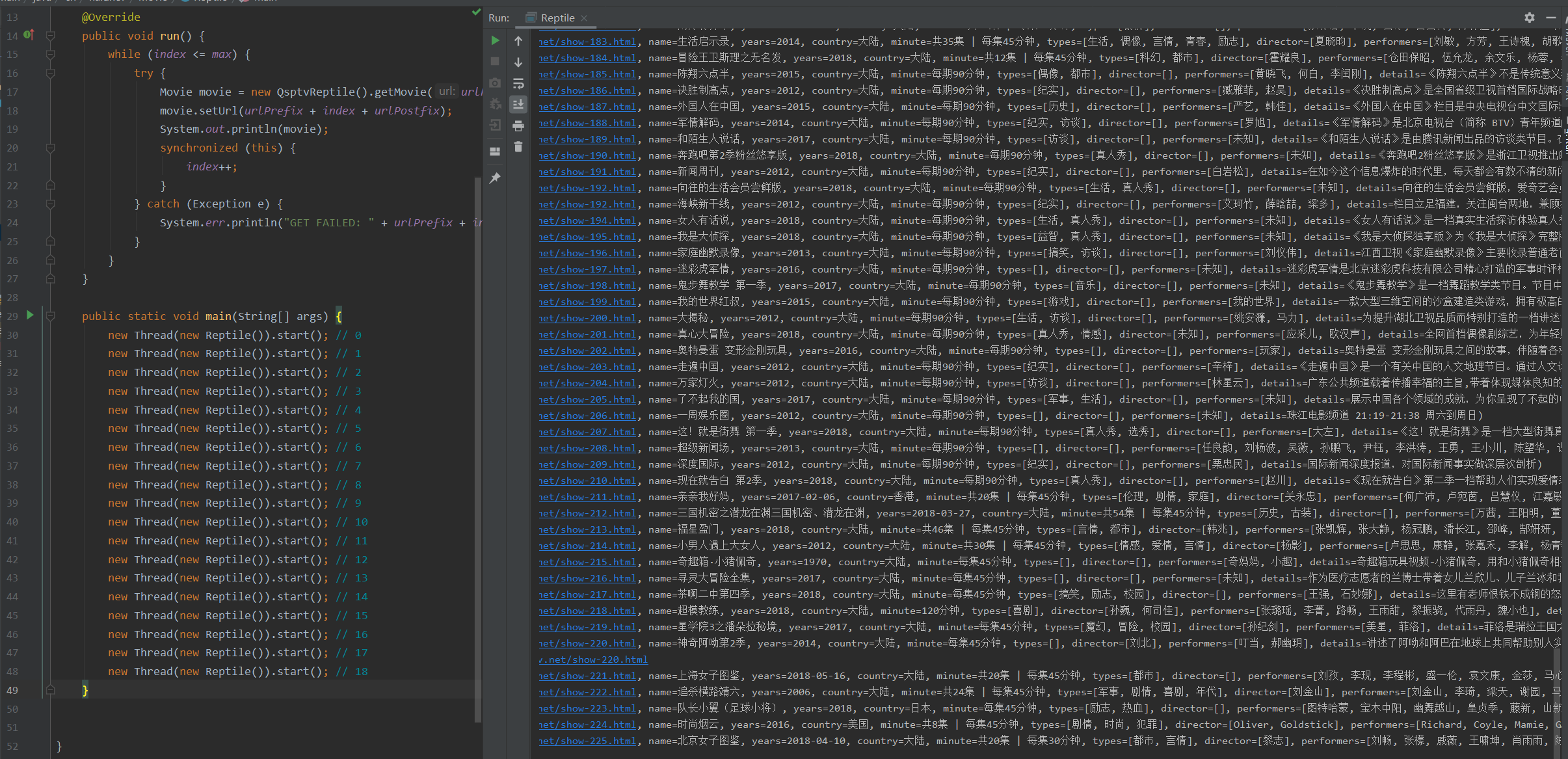
可见获取数据的速度是非常快的。这个就是不做好网络安全的后果。服务器的压力会非常大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号