Multi-Heads Attention参数量计算
单头与多头注意力结构如下:
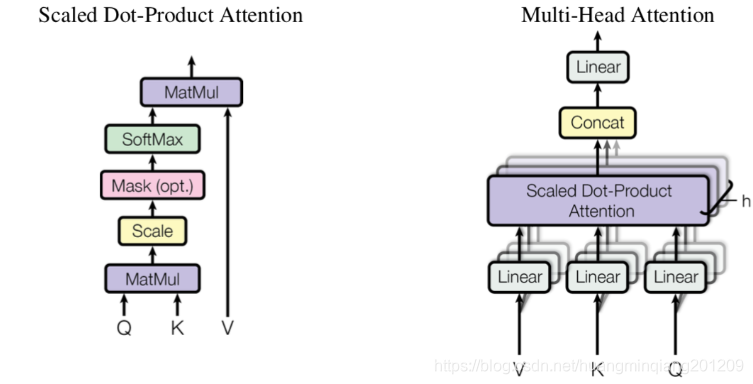
Q,K,V是输入的三个句子词向量
h=12,12个头
由下图知
最后把12个头concat后又进行线性变换,用到参数

Self Attention
- 对于 Self Attention,
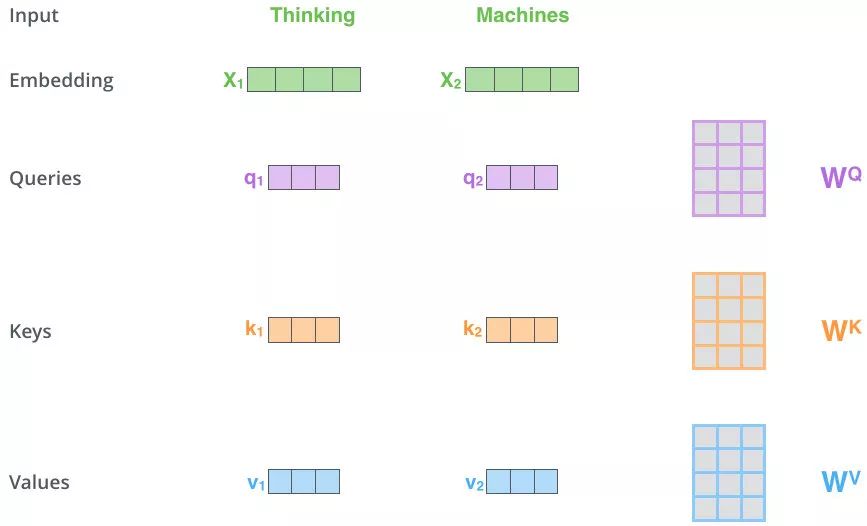
- 上图操作:两个单词 Thinking 和 Machines。通过线性变换,即
- MatMul
-
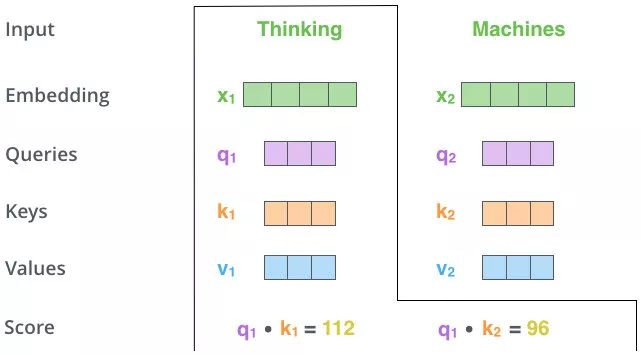
-
上图操作:向量
-
- Scale+Softmax
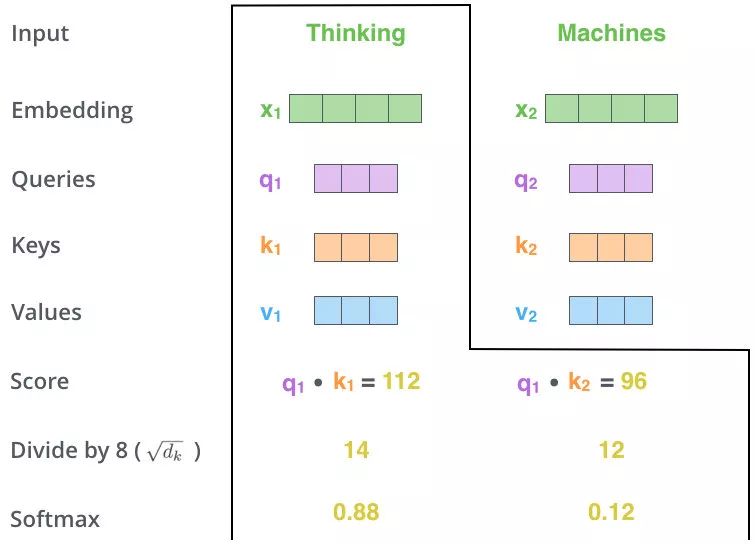
- 对得分规范,除以
- 元素方差很大(分布的方差大,分布集中在绝对值大的区域),在数量级较大时, softmax 将几乎全部的概率分布都分配给了最大值对应的标签,由于某一维度的数量级较大,进而会导致 softmax 未来求梯度时会消失
- MatMul
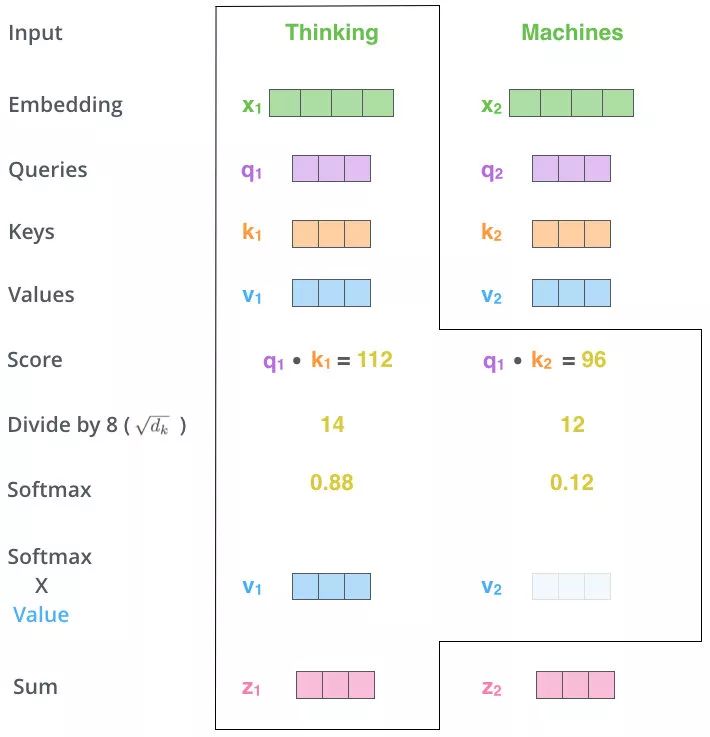
- 用得分比例[0.88,0.12]乘以[
注:
在Self-Attention机制中,除以根号下( d_k ) 是为了解决点积运算带来的数值稳定性问题,而 ( d_k ) 的具体来源如下:
1. ( d_k ) 的定义
( d_k ) 是 查询(Query)和键(Key)向量的维度,具体而言:
- 输入分割:在多头注意力(Multi-Head Attention)中,输入向量会被分割为多个头(Heads),每个头的查询和键向量的维度即为 ( d_k )。
- 计算公式:假设输入的总维度为 ( d_{\text{model}} ),头的数量为 ( h ),则每个头的维度为:
[
d_k = \frac{d_{\text{model}}}{h}
]
例如,若 ( d_{\text{model}} = 512 )、( h = 8 ),则 ( d_k = 64 )。
2. 为何需要除以 ( \sqrt{d_k} )?
-
点积的方差问题:
当两个独立随机变量 ( Q ) 和 ( K ) 的每个维度均值为0、方差为1时,它们的点积 ( Q \cdot K = \sum_{i=1}^{d_k} Q_i K_i ) 的方差为 ( d_k )。
若 ( d_k ) 较大,点积值的方差会显著增大,导致softmax后的分布过于尖锐(大部分概率集中在少数位置),进而引发梯度消失问题。 -
缩放点积:
通过将点积结果除以 ( \sqrt{d_k} ),点积的方差被调整为1,使梯度更稳定,模型更容易训练。
3. 数学推导
假设 ( Q ) 和 ( K ) 的每个元素服从均值为0、方差为1的分布:
[
\text{Var}(Q_i) = \text{Var}(K_i) = 1, \quad \text{Cov}(Q_i, K_j) = 0 \quad (i \neq j)
]
则点积的方差为:
[
\text{Var}(Q \cdot K) = \mathbb{E}\left[ \left( \sum_{i=1}^{d_k} Q_i K_i \right)^2 \right] = \sum_{i=1}^{d_k} \mathbb{E}[Q_i^2 K_i^2] = d_k \cdot \mathbb{E}[Q_i^2] \mathbb{E}[K_i^2] = d_k
]
除以 ( \sqrt{d_k} ) 后:
[
\text{Var}\left( \frac{Q \cdot K}{\sqrt{d_k}} \right) = \frac{d_k}{d_k} = 1
]
4. 实际例子
场景:输入维度 ( d_{\text{model}} = 512 ),头数 ( h = 8 ),则 ( d_k = 64 )。
- 计算注意力分数:
[
\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{64}} \right) V
]
这里 ( \sqrt{64} = 8 ),通过除以8缩放点积值。
5. 代码验证
以PyTorch实现为例:
import torch
d_model = 512
h = 8
d_k = d_model // h # 64
# 随机生成Q和K(假设均值为0,方差为1)
Q = torch.randn(10, d_k) # 10个查询向量,每个维度64
K = torch.randn(10, d_k) # 10个键向量,每个维度64
# 计算未缩放的注意力分数
scores_raw = torch.matmul(Q, K.T) # 形状 (10, 10)
print("未缩放的方差:", scores_raw.var().item()) # 接近 d_k=64
# 计算缩放后的注意力分数
scores_scaled = scores_raw / torch.sqrt(torch.tensor(d_k, dtype=torch.float))
print("缩放后的方差:", scores_scaled.var().item()) # 接近1
输出结果:
未缩放的方差: 64.12
缩放后的方差: 1.02
总结
- ( d_k ) 的来源:多头注意力中每个头的查询和键向量的维度,( d_k = d_{\text{model}} / h )。
- 除以 ( \sqrt{d_k} ):通过缩放点积结果,控制方差为1,避免梯度消失,提升训练稳定性。
在Transformer模型中,缩放点积注意力机制背后的数学原理可以通过以下步骤解释:
1. 未缩放点积的方差推导
假设查询向量Q和键向量K的每个元素独立服从标准正态分布(均值为0,方差为1),即:
[ Q_i, K_j \sim \mathcal{N}(0, 1) ]
点积 ( Q \cdot K^\top ) 的每个元素实际上是两个向量的内积:
[ \text{score}{ij} = \sum^{d_k} Q_{i,d} \cdot K_{j,d} ]
方差计算:
-
每个乘积项 ( Q_{i,d} \cdot K_{j,d} ) 的方差:
[
\text{Var}(Q_{i,d} \cdot K_{j,d}) = \text{Var}(Q_{i,d}) \cdot \text{Var}(K_{j,d}) = 1 \cdot 1 = 1
]
因为Q和K独立,且均值为0。 -
总共有 ( d_k ) 个独立项相加,总方差为:
[
\text{Var}(\text{score}_{ij}) = d_k \cdot 1 = d_k
]
因此,未缩放的注意力分数方差为 ( d_k )。
2. 缩放后的方差推导
为了控制方差,将点积除以 ( \sqrt{d_k} ):
[ \text{score}{ij}^{\text{scaled}} = \frac{\text{score}{ij}}{\sqrt{d_k}} ]
方差计算:
- 缩放后的方差为:
[
\text{Var}\left(\frac{\text{score}{ij}}{\sqrt{d_k}}\right) = \frac{1}{d_k} \cdot \text{Var}(\text{score}) = \frac{d_k}{d_k} = 1
]
因此,缩放后的注意力分数方差为1。
3. 代码验证
在代码中:
Q和K是独立生成的标准正态分布张量(均值为0,方差为1)。- 未缩放的注意力分数方差接近 ( d_k = 64 )(代码输出为64.12)。
- 缩放后的方差接近1(代码输出为1.02)。
4. 物理意义
- 未缩放的方差问题:当 ( d_k ) 较大时,点积的方差会显著增大,导致Softmax函数的输入值过大,进入梯度饱和区(梯度接近0)。
- 缩放的作用:通过除以 ( \sqrt{d_k} ),将方差稳定到1,确保Softmax的梯度有效传播。
数学公式总结
[
\text{Var}(Q \cdot K^\top) = d_k, \quad \text{Var}\left(\frac{Q \cdot K^\top}{\sqrt{d_k}}\right) = 1
]
这一缩放操作是Transformer模型稳定训练的关键设计之一。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗