Bidirectional 双向编码器
13.1.BERT公认的里程碑
-
BERT 的意义在于:从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
-
近年来优秀预训练语言模型的集大成者:
- 参考了 ELMO 模型的双向编码思想、
- 借鉴了 GPT 用 Transformer 作为特征提取器的思路、
- 采用了 word2vec 所使用的 CBOW 方法
-
BERT 和 GPT 之间的区别:
- GPT:GPT 使用 Transformer Decoder 作为特征提取器、具有良好的文本生成能力,然而当前词的语义只能由其前序词决定,并且在语义理解上不足
- BERT:使用了 Transformer Encoder 作为特征提取器,并使用了与其配套的掩码训练方法。虽然使用双向编码让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强
-
单向编码和双向编码的差异,以该句话举例 “今天天气很{},我们不得不取消户外运动”,分别从单向编码和双向编码的角度去考虑 {} 中应该填什么词:
- 单向编码:单向编码只会考虑 “今天天气很”,以人类的经验,大概率会从 “好”、“不错”、“差”、“糟糕” 这几个词中选择,这些词可以被划为截然不同的两类
- 双向编码:双向编码会同时考虑上下文的信息,即除了会考虑 “今天天气很” 这五个字,还会考虑 “我们不得不取消户外运动” 来帮助模型判断,则大概率会从 “差”、“糟糕” 这一类词中选择
13.2.BERT 的结构:强大的特征提取能力
- 如下图所示,我们来看看 ELMo、GPT 和 BERT 三者的区别

- ELMo 使用自左向右编码和自右向左编码的两个 LSTM 网络,分别以
- GPT 使用 Transformer Decoder 作为 Transformer Block,以
- BERT 也是一个标准的预训练语言模型,它以
- BERT 和 ELMo 的区别在于使用 Transformer Block 作为特征提取器,加强了语义特征提取的能力;
- BERT 和 GPT 的区别在于使用 Transformer Encoder 作为 Transformer Block,并且将 GPT 的单向编码改成双向编码,也就是说 BERT 舍弃了文本生成能力,换来了更强的语义理解能力。
BERT 的模型结构如下图所示:
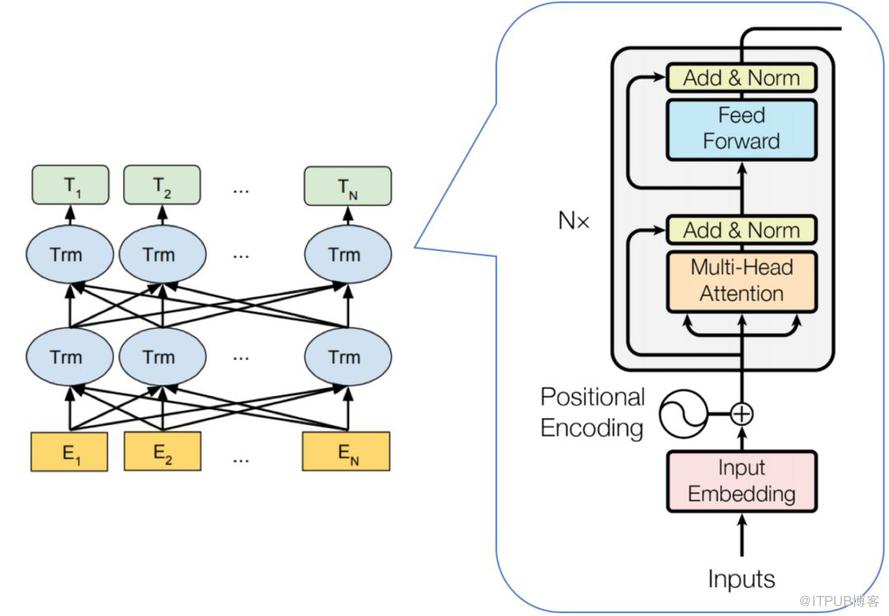
从上图可以发现,BERT 的模型结构其实就是 Transformer Encoder 模块的堆叠。在模型参数选择上,论文给出了两套大小不一致的模型。
L=12,H=768,A=12,总参数量为1.1亿(可在单GPU上运行)
L=24,H=1024,A=16,总参数量为3.4亿(需要在TPU上运行)
其中 L 代表 Transformer Block 的层数;H 代表特征向量的维数(此处默认 Feed Forward 层中的中间隐层的维数为 4H);A 表示 Self-Attention 的头数,使用这三个参数基本可以定义 BERT的量级。
BERT 参数量级的计算公式:
-
- 两个全连接层
- 惯用的全连接层大小设置
- 两个全连接层
-
- W1=W2=W3(d_{model},
`- *3 - *block(12)
- W1=W2=W3(d_{model},
-
- 有
- 三个地方用到了LayerNorm层
- Embedding层后
- Multi-Head Attention后
- Feed-Forward后
- 有


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗