Python爬虫学习笔记(七)——Ajax
介绍
Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。这是一种利用JS在保证页面不被刷新、页面链接不变的情况下与服务器交换数据并更新部分网页的技术。例如微博的下滑页面,这就是通过Ajax获取新数据并呈现的过程。
正文
Ajax的基本原理就不详细讲解了,大致步骤分为三步:发送请求、解析内容、渲染网页。这里主要讲一下分析方法
首先借助浏览器的开发者工具,chorme的快捷键是F12,切换到network选项卡,这就是观察的界面了。
Ajax其实有特殊的请求类型,叫作xhr,拿微博举例:
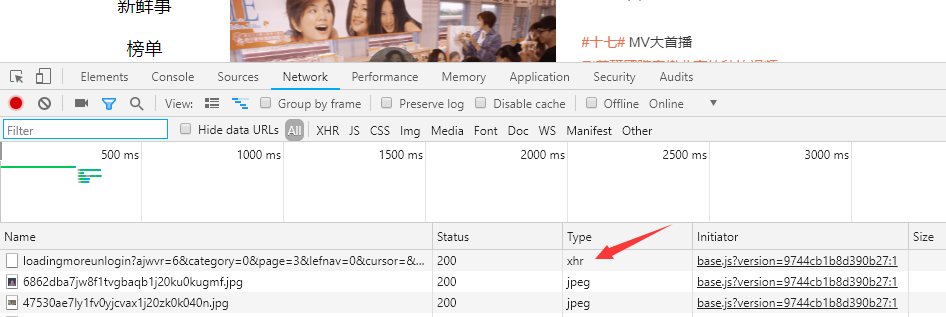
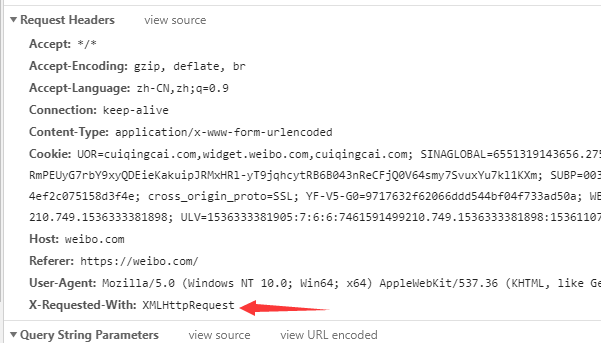
点击这个请求,可以查看这个请求的详细信息,如Request Headers、URL和Response Headers等信息。其中Request Headers中有一个信息为X-Requested-With,这就标记了此请求是Ajax请求,如图所示:
随后点击一下Preview,即可看到响应的内容,为JSON格式。Response选项卡中可以观察到真实的返回数据。
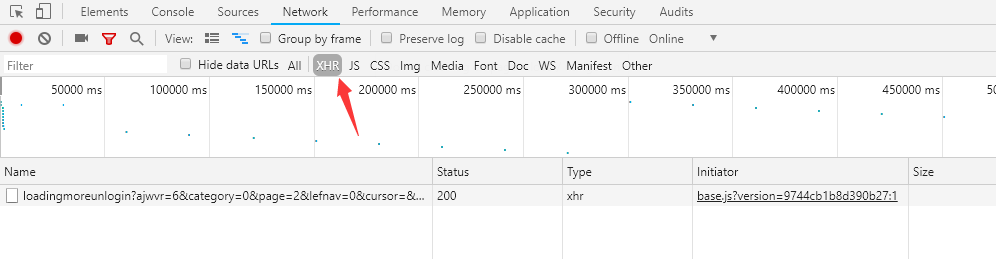
接下来,用chorme的筛选功能选出所有的Ajax请求。然后不断滑动页面就可以看到一个个Ajax请求,只需要用程序模拟这些请求,就可以轻松提取我们所需要的信息了。
总结
了解了Ajax的分析方法之后,就可以爬取了。具体操作明天再继续,今天忙了一天,有点累。打算明天再做一个小项目,但暂时没考虑好做什么。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号