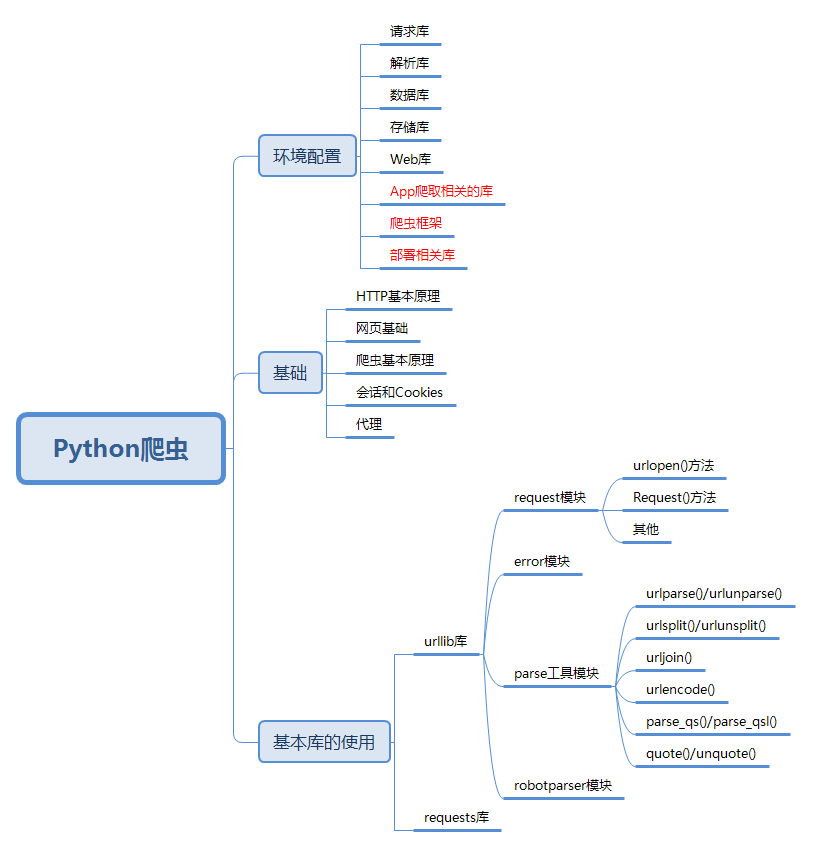
Python爬虫学习笔记(一)——urllib库的使用
前言
我买了崔庆才的《Python3网络爬虫开发实战》,趁着短学期,准备系统地学习下网络爬虫。在学习这本书的同时,通过博客摘录并总结知识点,同时也督促自己每日学习。本书第一章是开发环境的配置,介绍了爬虫相关的各种库以及如何安装,这里就跳过了。第二章是爬虫基础,都是些基本知识点,也跳过。从第三章开始认真记录学习路径。
urllib库的使用
urllib库是python内置的HTTP请求库,包含四个模块,接下来我将分别记录四大模块的功能和应用
request模块
它是最基本的HTTP请求模块,可以用来模拟发送请求
一、urlopen()方法
这个方法可以发起最基本的请求,同时带有处理授权验证、重定向、浏览器Cookies等内容的功能。
关于返回的对象,可以先看看下面的代码。
import urllib.request
response = urllib.request.urlopen("http://www.python.org")
print(response.status)
print(response.getheaders())
print(response.read())
上面代码中的response是一个HTTPResponse类型的对象,主要包含read()、readinto()、getheader(name)、getheaders()、fileno()等方法,以及msg、version、status、reason、debuglevel、closed等属性。基本上如同字面能理解方法和属性的含义,其中常用的几个再提一下。read()方法可以得到返回的网页内容,status属性可以得到状态码。
此外,urlopen()方法还可以传递一些参数,如下
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
二、Request()方法
Request可以说是对urlopen的补充,可以在请求中添加Headers等信息。基本用法如下:
import urllib.request
request = urllib.request.Request('http://python.org')
response = urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
接下来看看Request可以传递怎样的参数
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
其中origin_req_host参数指的是请求方的host名称或者IP地址,method参数指的是请求使用的方法(GET、POST、PUT等)
三、高级用法
Handler类的一些常用子类有下面几个:
1、HTTPDefaultErrorHandler:处理HTTP响应错误
2、HTTPRedirectHandler:处理重定向
3、HTTPCookieProcessor:处理Cookies
4、ProxyHandler:设置代理
5、HTTPPasswordMgr:管理密码
6、HTTPBasicAuthHandler:管理认证
$ 验证 $
验证用户名和密码是爬虫经常面对的,这里贴上部分验证代码
p = HTTPPasswordMgrWithDefaultRealm()
p.add_password(None, url, username, password)
auth_handler = HTTPBasicAuthHandler(p)
opener = build_opener(auth_handler)
result = opener.open(url)
html = result.read().decode('utf-8')
print(html)
$ 代理 $
proxy_handler = ProxyHandler({
'http': http_url,
'https': https_url
})
opener = build_opener(proxy_handler)
$ Cookies $
获取Cookies
import http.cookiejar, urllib.request
cookie = http.cookiejar.CookieJar()
cookie = http.cookiejar.LWPCookieJar()
# 以上两个二选一
handler = urllib.request.HTTPCookieProcessor(cookie)
opener = urllib.request.build_opener(handler)
response = opener.open(url)
cookie.save(ignore_discard=True, ignore_expires=True)
读取本地Cookies
cookies = http.cookiejar.LWPCookieJar()
cookie.load(filename, ignore_discard=True, ignore_expires=True)
error模块
error模块定义了由request模块产生的异常,暂时用的不多,所以我只是粗略看了一下。
1、URLError类
2、HTTPError类
parse模块
这个模块主要用来解析链接
1、urlparse()/urlunparse():URL的识别和分段及其对立方法
标准链接格式:scheme://netloc/path;params?query#fragment
2、urlsplit()/urlunsplit():类似上一个,区别是不单独解析params这部分
3、urljoin():链接的解析、拼合与合成
4、urlencode():将字典类型序列化为URL参数
5、parse_qs()/parse_qsl():将参数转化为字典/元组组成的列表
6、quote()/unquote():将内容转化为URL编码的格式及其对立方法
robotparser模块
分析网站的Robots协议,略
思维导图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号