
20145322 《信息安全系统设计基础》第7周学习总结(二)
20145322《信息安全系统设计基础》第7周学习总结(二)
教材学习内容总结
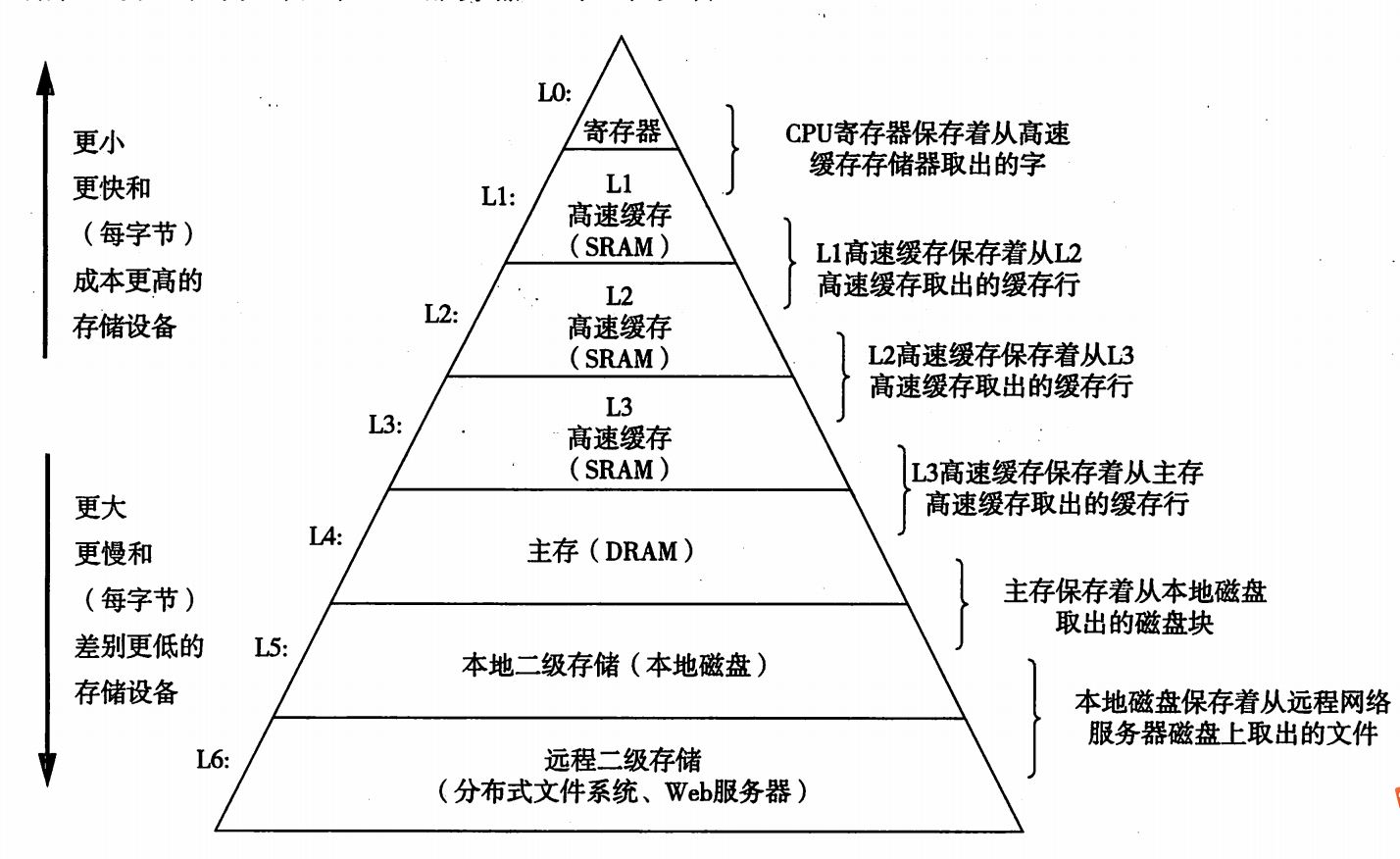
存储器结构本质:
可以从存储器层次结构中看出,每一级都是下一级的缓存,例如L1是L2的缓存。
缓存命中与不命中:
程序需要K+1层的数据d,先读K层,若有,缓存命中,若K层没有,则从K+1层中拷贝到K层,若K层已满,则根据替换策略来选择牺牲块进行替换(驱逐),切拷贝过来的块会保持在K层等待之后的访问。
缓存不命中分为:
冷缓存:空的缓存,不命中种类成为强制性不命中或者冷不命中。
放置策略会引起冲突不命中(映射到同一个缓存块的块间总是发生不命中)
当工作集的大小超过缓存的大小时,就会发生容量不命中(缓存太小)
缓存管理:
某种逻辑将缓存划分为快,在不同层之间传送,判断命中与否。如:编译器管理寄存器文件。
通用的高速缓存存储器结构:
如图:
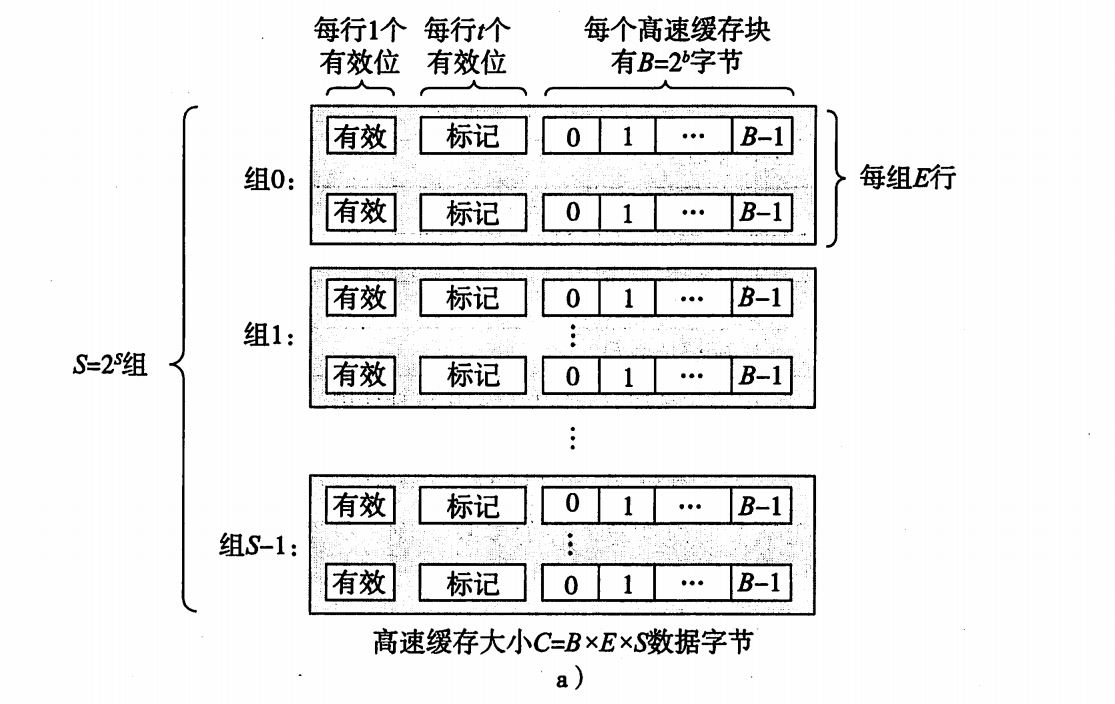
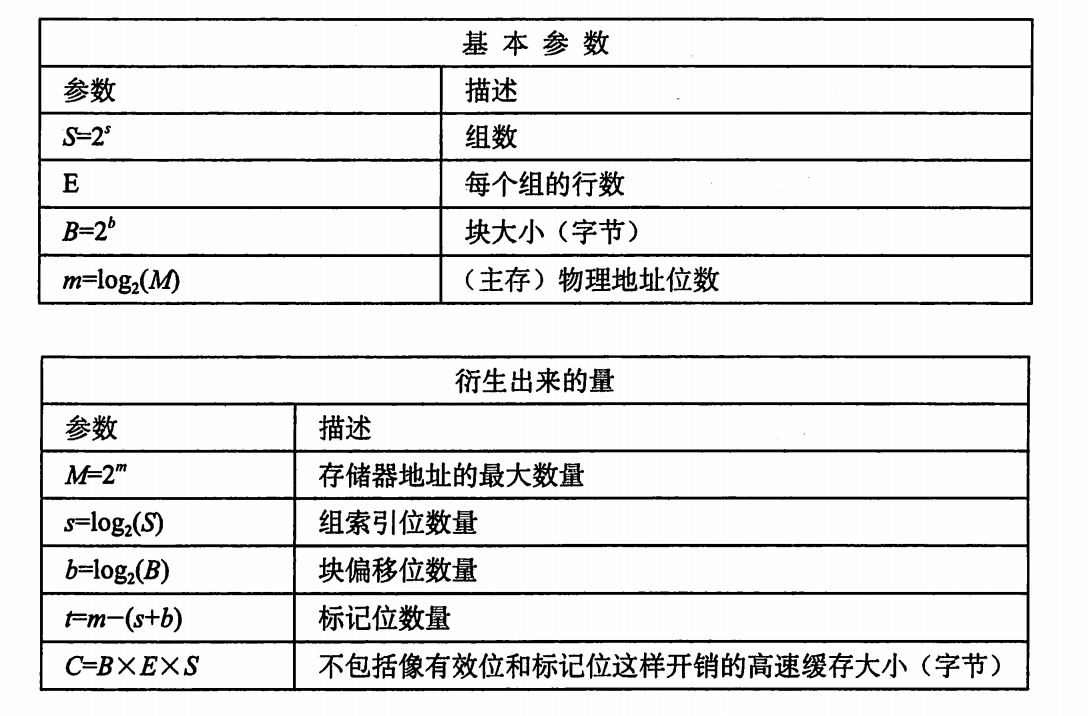
每个存储器地址有m位,一个机器的高速缓存被组织成一个有S个高速缓存组的数组,每个组包含E个高速缓存行,每个行由B字节的数据块、一个有效位以及一个标记位组成。
高速缓存的结构可以用元组(S,E,B,m)来描述,高速缓存的大小C=SEB。
每个存储器有2^m个地址,,其中m个地址被划分为t个标记位,s个索引组和b个块偏位移。
直接映射高速缓存:
如图:
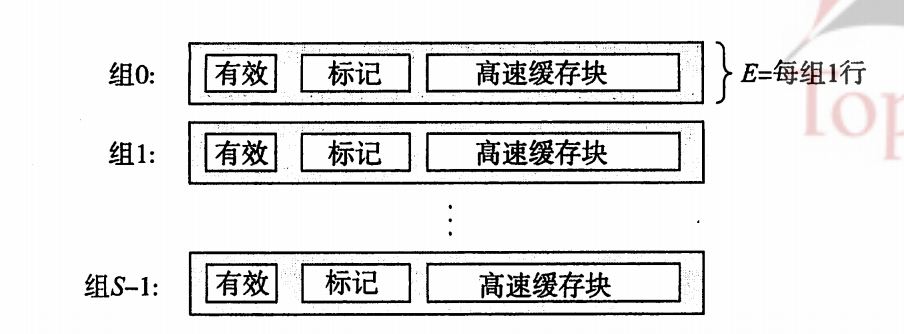
每个组只有一行的高速缓存。
直接映射高速缓存中的组选择:
高速缓存从w的地址中间抽取出s个组索引位。
直接映射高速缓存中的行匹配:
确定是否有字w的一个拷贝存储在组i包含的一个高速缓存行中。
直接映射高速缓存中的字选择:
快偏移提供了所需要的字的第一个字节的偏移。
直接映射高速缓存中不命中时的行替换:
替换策略是用新取出的行替换当前的行。
综合:
运行中的直接映射高速缓存。
直接映射高速缓存中的冲突不命中:
当程序访问大小为2的幂的数组时,直接映射高速缓存中通常会发生冲突不命中,高速缓存反复地加载和驱逐相同的高速缓存块的组(抖动)。
解决:在每个数组的结尾放B字节的填充。
全相联高速缓存:
由一个包含所有高速缓存行的组(E=C/B)组成的。
全相联高速缓存中的组选择:只有一个组,所以地址中没有组索引位。
全相联高速缓存中的行匹配和字选择:与组相联高速缓存相同。
写命中:
直写:立即将w的高速缓存块写回到紧接着的低一层中。
写回:尽可能的推迟存储器更新,只有当替换算法要驱逐更新过的块时,才把它写回紧接着的低一层中。
写不命中:
写分配:加载相应的第一层中的块到高速缓存中,然后更新这个高速缓存块。
非写分配:避开高速缓存,直接把这个字写到第一层中。
教材学习中的问题和解决过程
1 一开始不理解P413中读1地址为什么是高速缓存命中,误以为地址1在组1中,后来根据图6-32(下图)所示可得地址0和1在组0,读地址0的字之后组0有效位变为1,然后地址1的标志位和此时组0标志位相符,所以缓存命中。
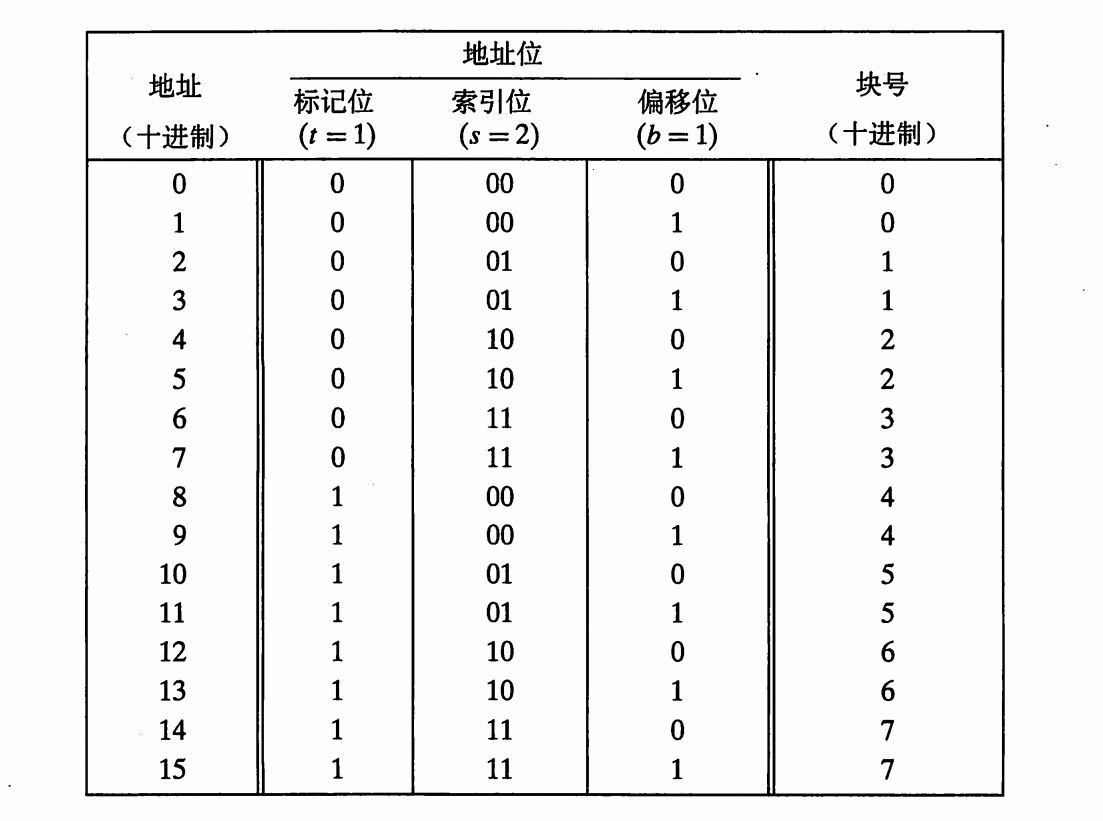
注:地址0和1在块0中,而块0在组0中,所以第二次缓存命中。
2 P415刚开始不能理解为什么每个数组后面加B个字节就可以修真抖动问题,后来发现其实是自己想多了,其实很简单,抖动是因为冲突不命中,即在同一个组内发生冲入,解决如下图:
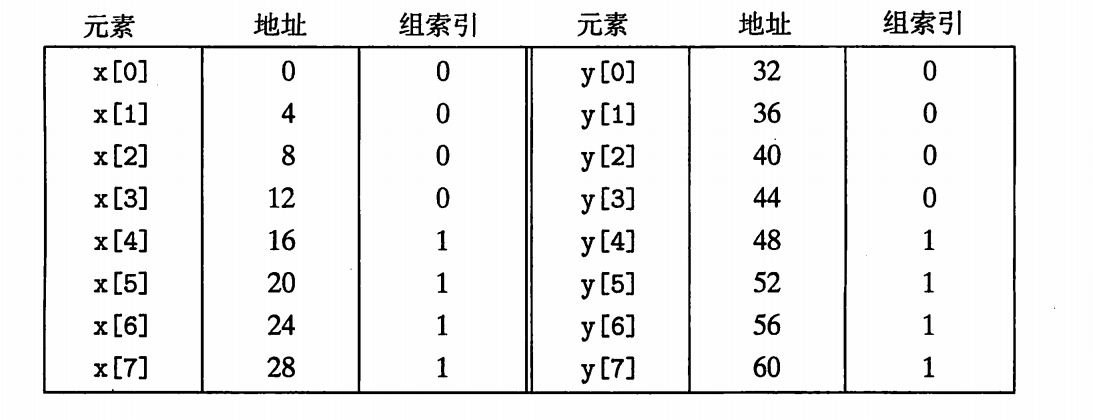
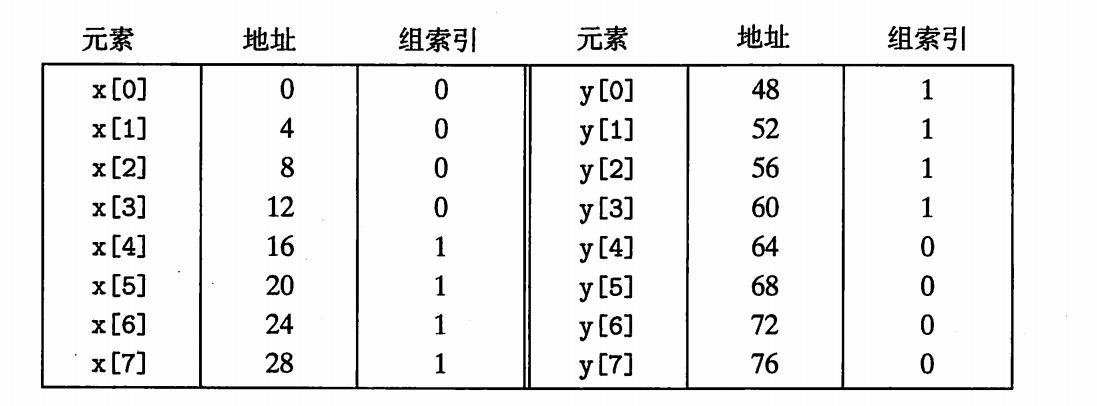
解决:左图和右图,区别在于Y元素的地址从哪开始读,因为Y元素紧跟X元素被引用,右图Y元素一开始被索引到组1,和X元素不同组,所以避免了冲突不命中。
其他(感悟、思考等,可选)
有时候停留在一个简单的知识点上太久,效率低,学习的时候应该更加集中注意力,才能对被一些简单的问题犯迷糊。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 100/100 | 1/1 | 13/20 | |
| 第二周 | 100/200 | 1/2 | 15/38 | |
| 第三周 | 100/300 | 1/3 | 20/60 | |
| 第五周 | 70/370 | 2/5 | 30/90 | |
| 第六周 | 200/570 | 2/7 | 40/90 | |
| 第七周 | 0/570 | 2/9 | 30/120 |

