
Datawhale 组队学习😝fun-transformer🎁task01 引言
Datawhale 组队学习 fun-transformer
Datawhale项目链接:https://www.datawhale.cn/learn/summary/87
笔记作者:博客园-岁月月宝贝💫
微信名:有你在就不需要🔮给的勇气
1.Seq2Seq模型简介
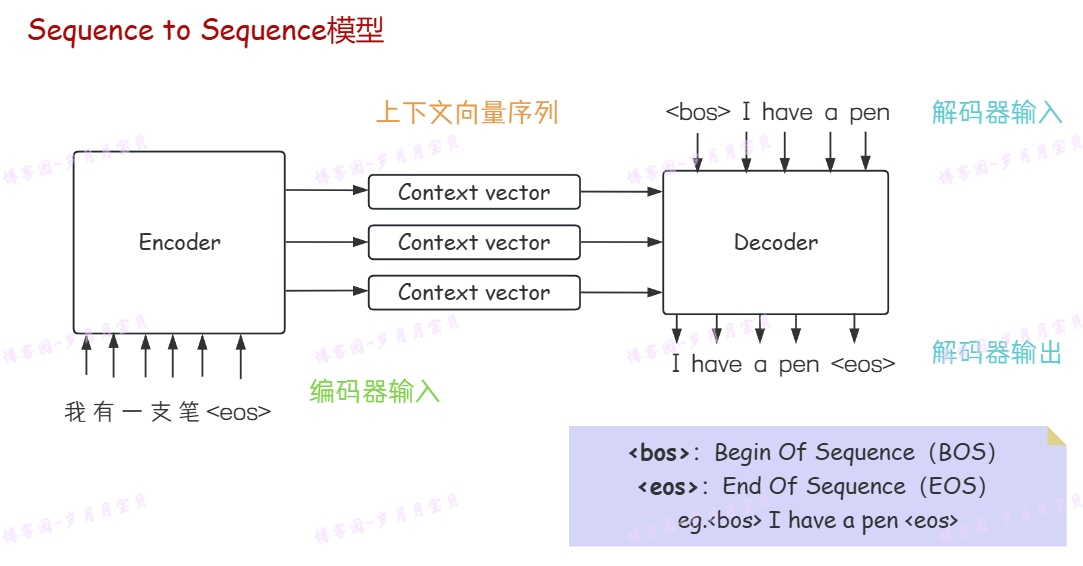
全称:Sequence to Sequence模型
结构:以一个序列为输入,另一个序列为输出(输入输出均为固定长度的向量)
特征:输入序列和输出序列长度可变
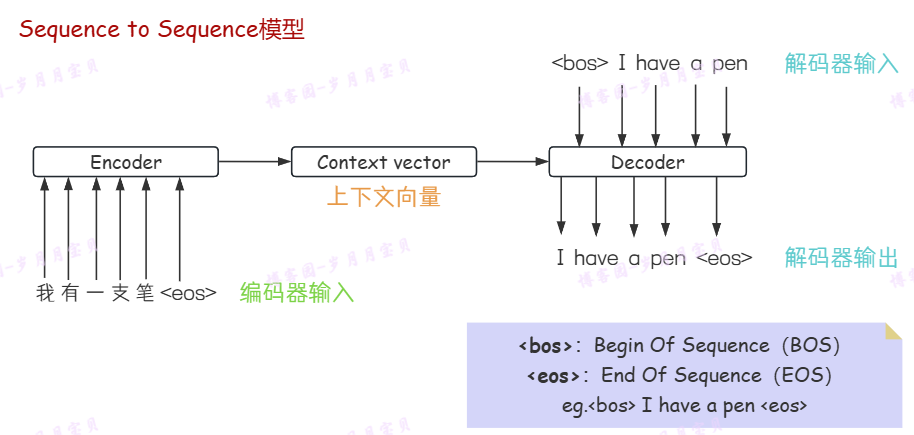
图中BOS和EOS能够辅助模型识别序列的边界,可以在处理可变长度的序列(如上图,输入了5个汉字,输出了4个英文单词)时减少模型对填充(padding)的依赖。
❓上下文向量:编码器将输入序列(例如“我有一支笔”)转换为的包含输入序列的压缩信息的一个固定长度的向量。它能够捕捉输入数据的核心特征和语义。
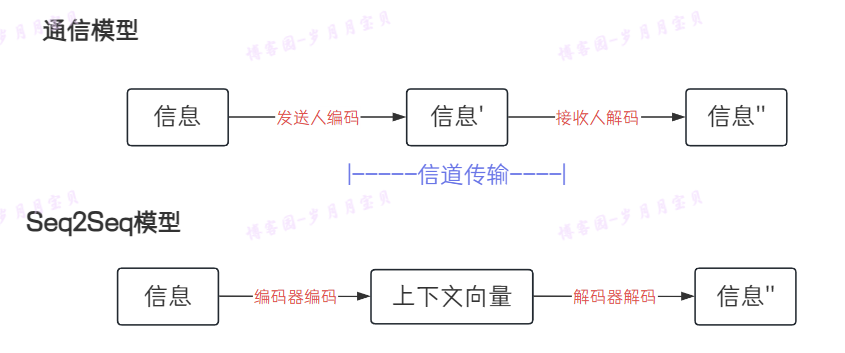
上面是用通信模型辅助大家类比理解哦!
❓填充:将序列数据转换成目标长度,以便于输入到需要固定长度输入的神经网络中。
填充使用案例:
我们有一个包含单词索引的句子序列&目标长度为5,原始序列为[1, 2, 3](长度为3);此时我们可以使用0填充,使得Padding后的序列为[1, 2, 3, 0, 0](长度为5)
填充使用难题:
1.使得操作更繁琐:eg.在计算损失时可能需要使用掩码(Mask)来忽略这些补零的元素,以免它们影响模型的训练效果。
2.掩码长度未知:eg.机器翻译、语音识别、对话系统等,表示成序列后,其长度事先并不知道。
如何突破先前深度神经网络的局限? Seq2Seq框架应运而生。
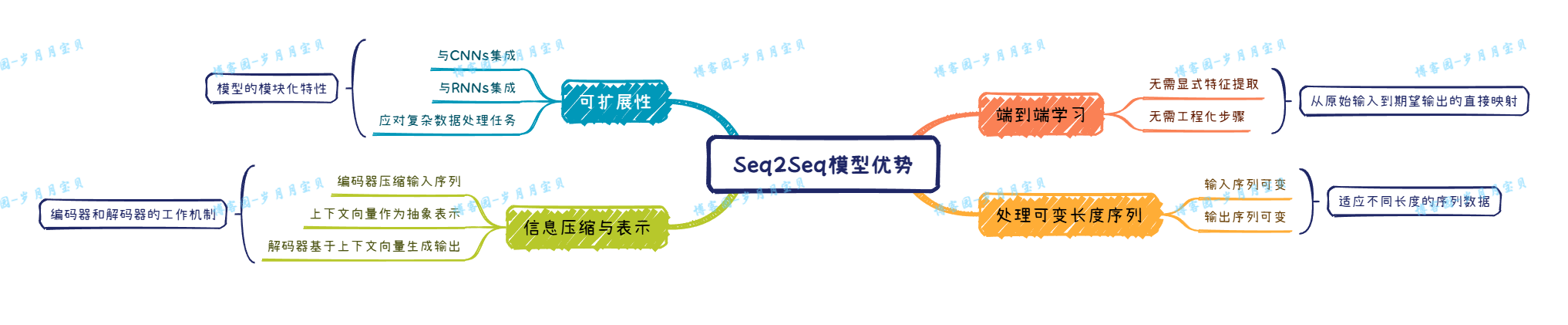
Seq2Seq优点:
Seq2Seq缺点:
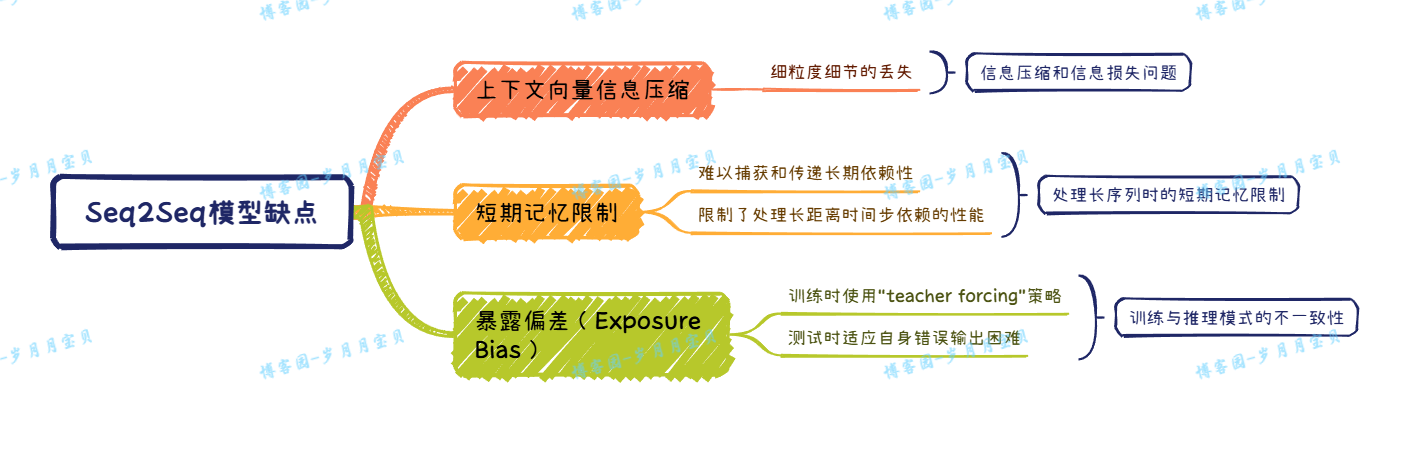
“teacher forcing”策略:在每个时间步提供真实的输出作为解码器的输入
2. Encoder-Decoder模型
以满足“输入序列、输出序列”为目的的Seq2Seq 使用的架构基本都属于Encoder-Decoder 。Seq2Seq 模型是 Encoder-Decoder 架构的一种具体应用 ~
| Encoder 又称作编码器。它的作用是“将现实问题转化为数学问题”。 Decoder 又称作解码器,他的作用是“求解数学问题,并转化为现实世界的解决方案”。 |
💫Encoder-Decoder 模型必备特点:
- 不论输入和输出的长度是什么,中间的“上下文向量 ” 长度都是固定的(这也是它的缺陷,下文会详细说明);
- 根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU )。
LSTM(Long Short-Term Memory)和 GRU(Gated Recurrent Unit)是两种特殊类型的循环神经网络(RNN),它们被设计用来解决标准 RNN 在处理序列数据时面临的长期依赖问题。
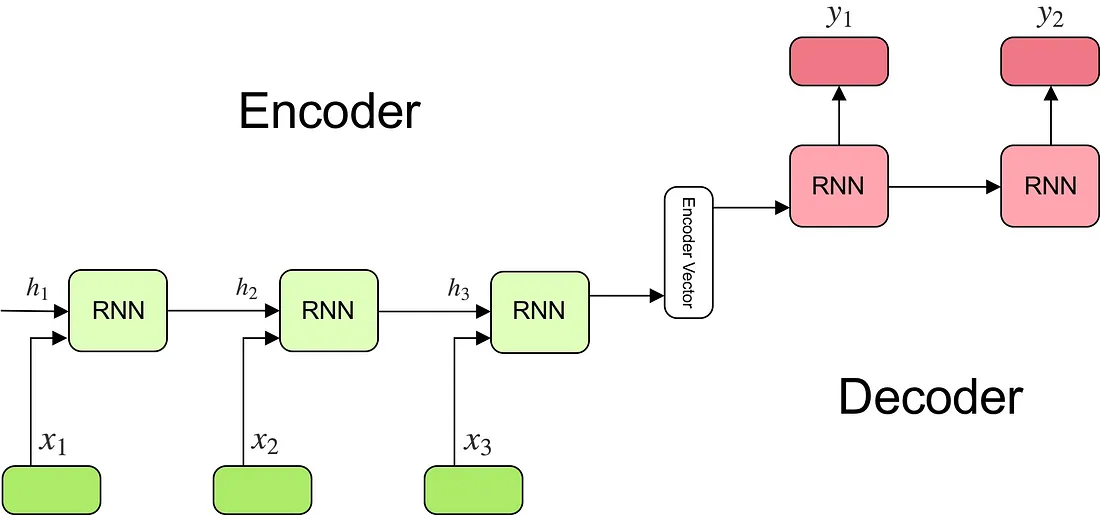
编码器
定义:一个循环神经网络,由多个循环单元堆叠而成。
细节:每个单元通过依次处理输入序列中的一个元素,生成一个上下文向量。这个上下文向量汇总了输入序列的全部信息,它通过在单元间传递当前元素的信息,逐步构建对整个序列的理解。
工作流程:
- 输入文本的词嵌入
在Seq2Seq模型的初始阶段,输入文本(例如一个句子)通过一个嵌入层(embedding layer)进行转换。这一层将每一个词汇映射成一个高维空间中的稠密向量,这些向量携带了这些词汇的语义信息。这个过程称为词嵌入(word embedding),它使得模型能够捕捉到词汇之间的内在联系和相似性。 - 基于RNN的序列处理
随后,这些经过嵌入的向量序列被送入一个基于循环神经网络(RNN)的结构中,该结构可能由普通的RNN单元、长短期记忆网络(LSTM)单元或门控循环单元(GRU)组成。RNN的递归性质允许它处理时序数据,从而捕捉输入序列中的顺序信息和上下文关系。在每个时间步,RNN单元不仅处理着当前词汇的向量,还结合了来自前一个时间步的隐藏状态信息。 - 生成上下文向量
经过一系列时间步的计算,RNN的最后一个隐藏层输出被用作整个输入序列的表示,这个输出被称为“上下文向量(context vector)”。上下文向量是一个固定长度的向量,它通过汇总和压缩整个序列的信息,有效地编码了输入文本的整体语义内容。这个向量随后将作为Decoder端的重要输入,用于生成目标序列。

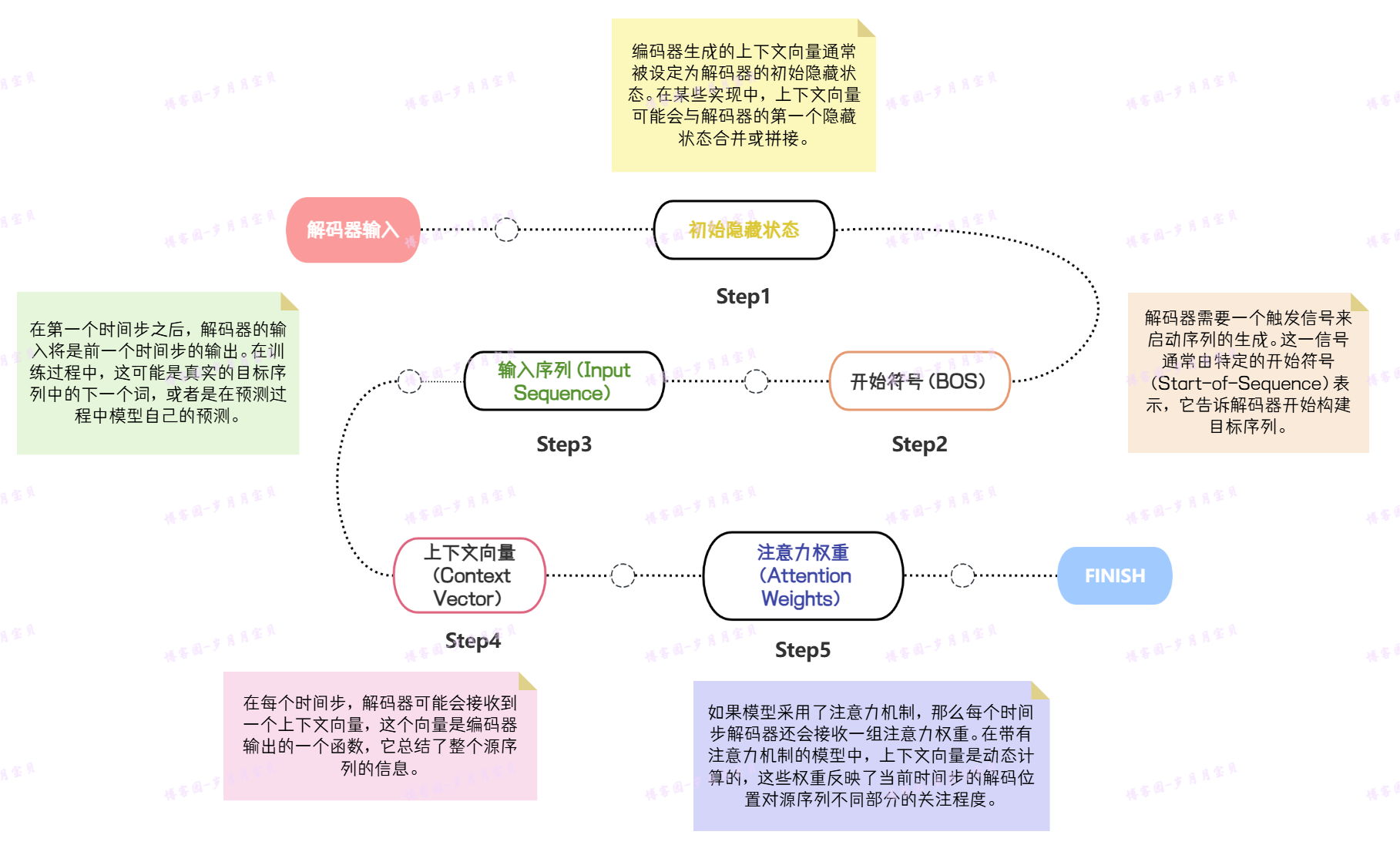
解码器
定义:采用循环神经网络(RNN)的一个架构,接收编码器输出的上下文向量作为其初始输入,并依次合成目标序列的各个元素。
工作流程:
1.初始化参数:
在开始训练之前,解码器及其相关输出层的参数需要被初始化。
- eg1.权重(Weights):连接不同神经网络层的参数,决定层与层之间信息的传递方式。。
- eg2.偏置(Biases):在神经网络层中加入的固定值,用于调节激活函数的输出。
👍参数的初始化通常涉及对它们赋予随机的小数值,以防止网络在训练初期对特定输出产生偏好。
常用的初始化策略包括Xavier初始化(适用于Sigmoid或Tanh激活函数)和He初始化(通常用于ReLU激活函数),这两种方法旨在维持各层激活值和梯度的大致稳定性,从而优化训练过程。
2.目标序列合成:
编码器完成上下文向量的生成后,解码器便开始目标序列的合成过程。
Seq2Seq模型的训练过程
下面是一个小故事💖,讲得瑕不掩瑜,大家可以一听~
训练Seq2Seq模是一个复杂的过程,为方便你理解,需要你暂时扮演一名老师,教一个学生(解码器)如何根据一本故事书(源序列)来复述故事。这个过程可以这样进行:
🐣1. 准备数据
【数据预处理】首先,你需要把故事书的内容翻译成学生能理解的词汇表(分词),并为每个词汇分配一个编号,同时在故事的开始和结束加上特殊的标记(编码),告诉学生何时开始和结束复述。
【批量处理】然后,你把这些故事分成几个小部分,每次给学生讲一个小故事,这样他们可以同时学习多个故事
🐣2. 初始化模型参数
【解码器RNN】学生的大脑就像一个初始状态,需要学习如何理解和复述故事(初始化解码器的权重和偏置)。
【输出层】学生的嘴巴就像一个输出层,需要学习如何将大脑中的故事转换成语言表达出来(初始化输出层的权重和偏置,通常是一个全连接层,用于将解码器的隐藏状态映射到目标词汇的概率分布)。
👉3. 编码器处理
【运行编码器】你先给学生讲一遍故事,让他们理解故事的情节和要点,这些信息被总结成一个简短的笔记(通过编码器RNN处理源序列,得到最后一个隐藏状态或使用注意力机制来生成上下文向量)。
🔄4. 解码器训练过程
【初始化隐藏状态】学生开始复述前,先看看你给他们的笔记(使用编码器的最后一个隐藏状态或上下文向量来初始化解码器的隐藏状态)。
【时间步迭代】
- 输入:学生首先根据你给的开头标记(
) 开始复述,然后根据他们自己的记忆或者你给的提示(教师强制 Teacher Forcing)来继续。 - 解码器RNN:学生的大脑根据当前的输入和之前的记忆来决定下一步该说什么(根据当前时间步的输入和前一时间步的隐藏状态,计算当前时间步的隐藏状态)。
- 输出层:学生尝试用语言表达出他们大脑中的故事(将当前时间步的隐藏状态通过输出层,得到一个概率分布,表示当前时间步预测的目标词汇)。
- 损失计算:你评估学生复述的故事和你讲的故事之间的差异,通常是通过比较他们说的词汇和你期望的词汇(计算预测的概率分布和实际目标词汇之间的损失,通常使用交叉熵损失)。
👈5. 反向传播和参数更新
【计算梯度】学生根据你的反馈来调整他们的记忆和学习方法(对损失函数进行反向传播,计算模型参数的梯度)。
【参数更新】学生通过不断的练习来改进他们的复述技巧(根据计算出的梯度,更新解码器的权重和偏置)。
🔄6. 循环训练
【多个epoch】学生需要反复练习,多次复述不同的故事,直到他们能够熟练地复述任何故事(模型收敛)。
👌7.评估和调优:
【验证集评估】定期让学生在新的故事(验证集)上测试他们的复述能力。
【超参数调优】根据学生的表现,调整教学的方法,比如改变练习的难度或频率(学习率、批次大小)。
通过这个过程,学生(解码器)学会了如何根据你提供的笔记(上下文向量)来复述故事(生成目标序列)。在实际训练中,教师强制(Teacher Forcing)等技巧可以帮助学生更快地学习,而梯度裁剪(Gradient Clipping)等技术可以防止他们在学习过程中过度自信或偏离正确的路径。
Encoder-Decoder 的工作原理
下面是一个小故事😻,讲得瑕不掩瑜,大家可以一听~
想象一下,你有一个翻译笔,它能够把一种语言翻译成另一种语言。
编码器(Encoder)的工作: 这个翻译笔的第一步是“阅读”你输入的句子。它一个词一个词地看,一边看一边记下重要的信息。当它看完整个句子后,它会把所有重要的信息总结成一个简短的笔记,这个笔记就是我们说的“上下文向量”。
解码器(Decoder)的工作:接下来,翻译笔开始根据这个句子来生成新的句子。它从第一个词开始,可能是“开始”的标志,然后根据这个标志和笔记来猜测下一个词是什么。每猜对一个词,它就继续猜下一个,直到它觉得句子翻译完成了,可能是遇到了“结束”的标志。
这个过程就像是一个人根据记忆来复述一个故事,一边回忆一边讲述,直到故事讲完。解码器(Decoder)每次都是根据它之前说的词和那个总结的笔记(上下文向量)来决定接下来该说什么。
Encoder-Decoder 的应用
| 维度 | 案例 | 说明 |
|---|---|---|
| 文本 – 文本 | 机器翻译、对话机器人、诗词生成、代码补全、文章摘要 | “文本 – 文本” 是最典型的应用,因其输入序列和输出序列的长度可能会有较大的差异。——Google 发表的用 Seq2Seq做机器翻译的论文《Sequence to Sequence Learning with Neural Networks》 |
| 音频 – 文本 | 语音识别 | 语音识别也有很强的序列特征,比较适合 Encoder-Decoder 模型。——Google 发表的使用 Seq2Seq做语音识别的论文《A Comparison of Sequence-to-Sequence Models for Speech Recognition》 |
| 图片 – 文本 | 图像描述生成 | 通俗的讲就是“看图说话”,机器提取图片特征,然后用文字表达出来。这个应用是计算机视觉和 NLP 的结合。——图像描述生成的论文《Sequence to Sequence – Video to Text》 |
Encoder-Decoder 的缺陷
因为Encoder(编码器)和 Decoder(解码器)之间只有一个固定长度的“上下文向量 ”来传递信息,所以当输入信息太长时,“解压”不一定能完全恢复,会丢失掉一些信息。
3. Attention 的提出与影响
Attention的发展历程
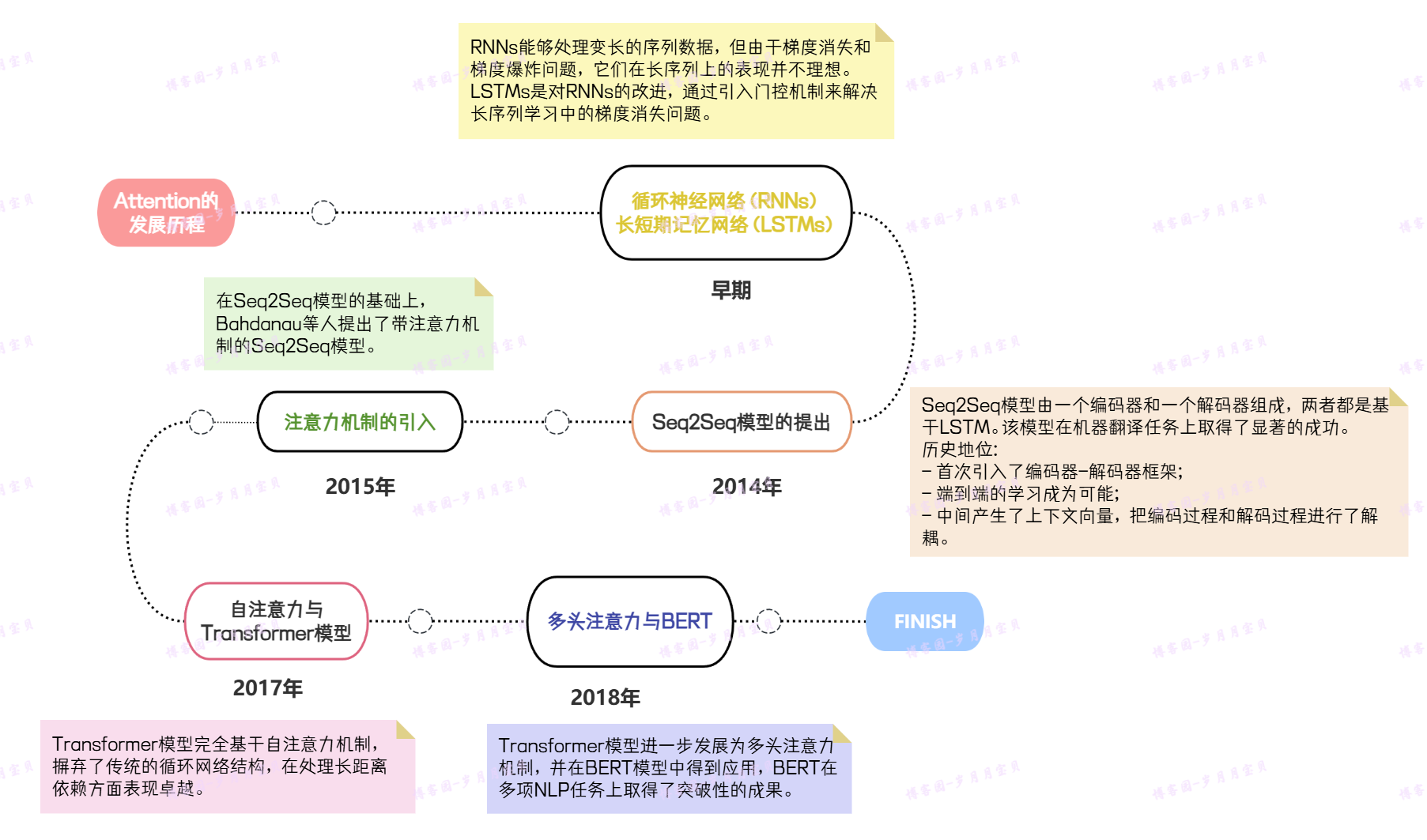
上图为历史,下图为当今~
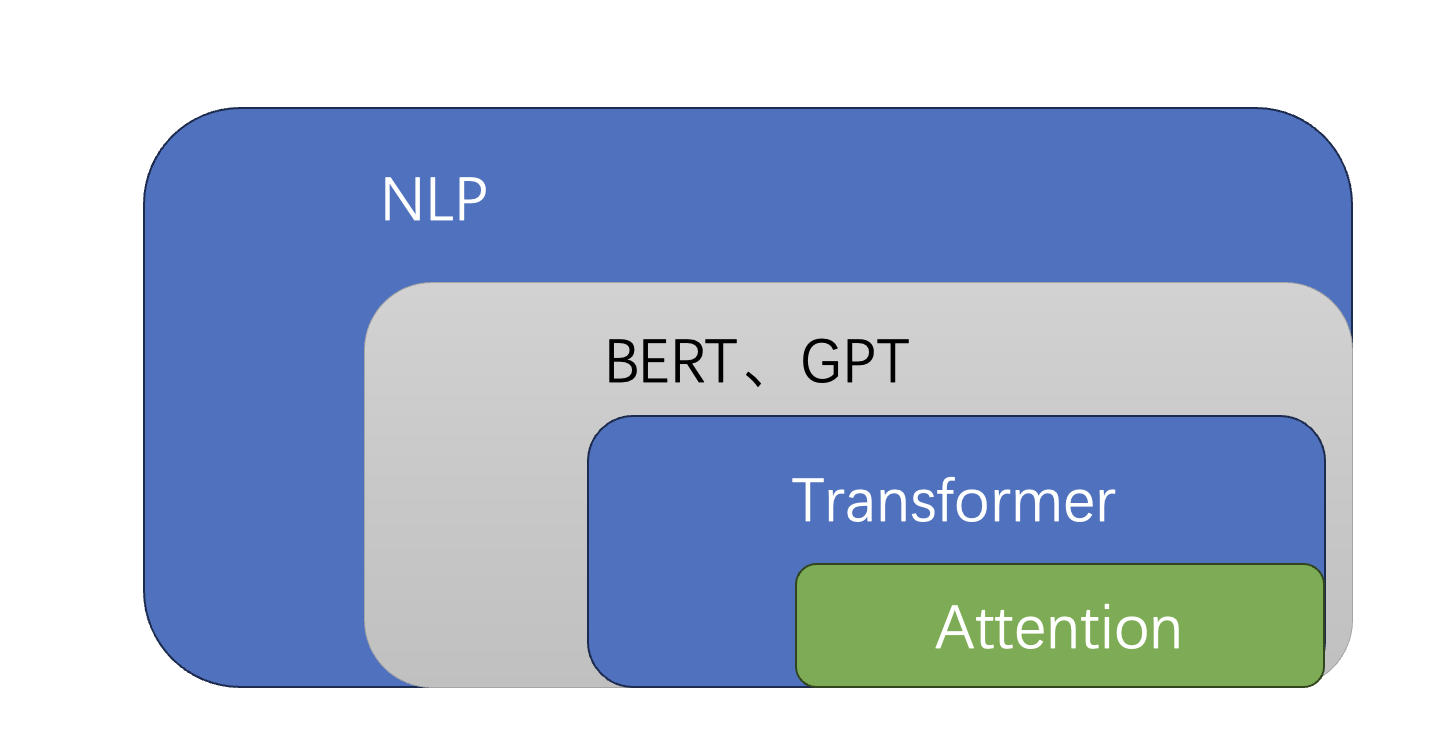
Attention的N种类型
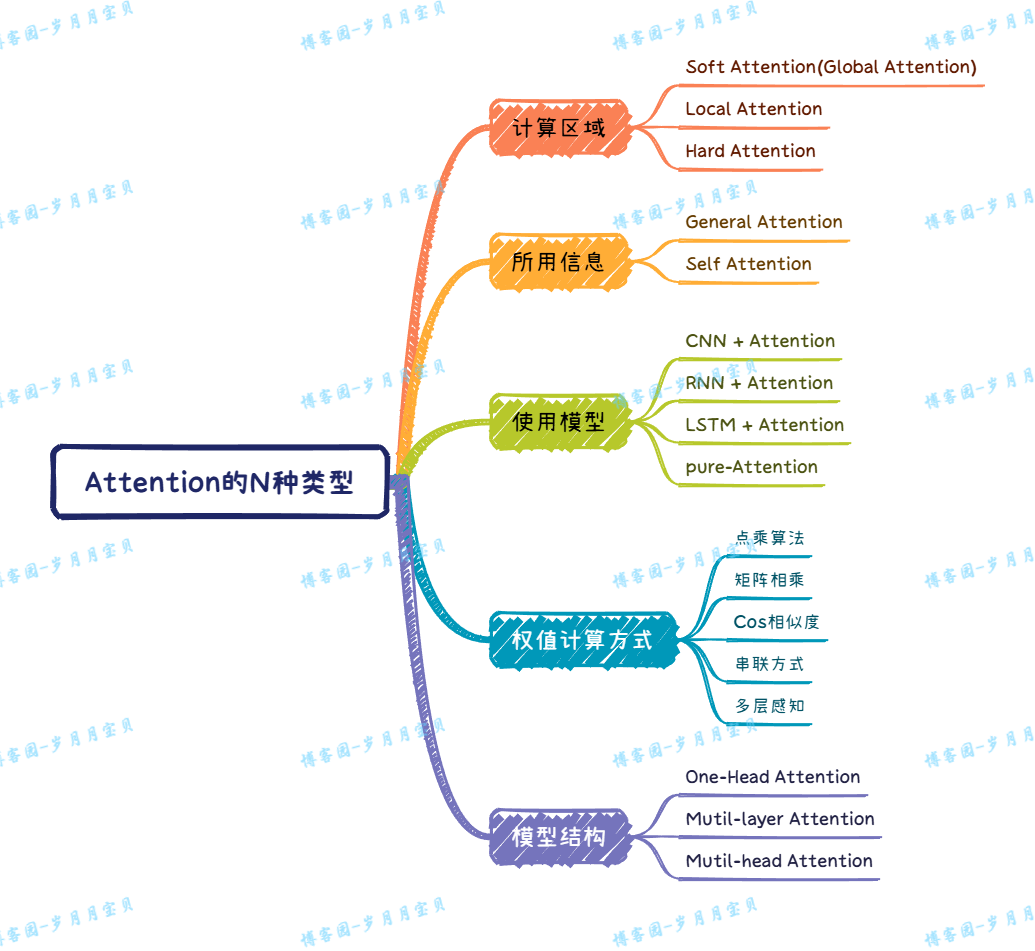
Attention 解决信息丢失问题
Attention模型的特点是 Encoder 不再将整个输入序列编码为固定长度的“向量C” ,而是编码成一个向量(Context vector)的序列(“C1”、“C2”、“C3”),解决“输入信息过长,信息丢失”的问题。
这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。
Attention 的核心工作
Attention 的核心工作是“关注重点”。在特定场景下,解决特定问题时:
- 场景:信息量大,包含有效信息和噪声。
- 问题:算力和资源有限,无法同时处理所有信息。
这可以类比我们看看远处物体时注意不到近处、看近处物体远处模糊的视觉系统:将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。

Attention 的3大优点
- 参数少:模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
- 速度快:Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
- 效果好:在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。但是它被Attention解决啦!😝
4.友链
-
Attention用于NLP的一些小结:https://zhuanlan.zhihu.com/p/35739040
-
遍地开花的 Attention,你真的懂吗?https://zhuanlan.zhihu.com/p/77307258
-
B站李沐老师关于深度学习讲解:https://space.bilibili.com/1567748478
5.辅助实验-理解词嵌入
概念解释:
假设我们有一个简单的词汇表,包含以下四个词:{“猫”,“狗”,“爱”,“跑”}。在词嵌入之前,这些词可能只是用数字索引来表示,例如:
“猫” = 0 “狗” = 1 “爱” = 2 “跑” = 3
这种表示方式没有包含词汇的语义信息。
现在,我们使用词嵌入将这些词映射到一个三维空间中(实际上,词嵌入通常是更高维度的,因为这样可以更准确地捕捉词汇的复杂语义关系。这里为了简化说明,使用三维)。每个词汇将会有一个对应的稠密向量,例如:
“猫” = [0.3, 0.4, 0.25] “狗” = [0.35, 0.45, 0.3] “爱” = [0.8, 0.8, 0.8] “跑” = [0.1, 0.2, 0.6]
这些向量在多维空间中的位置是根据词汇的语义相似性来确定的。例如,“猫”和“狗”在语义上比较接近,所以它们在三维空间中的向量可能也比较接近。而“爱”和“跑”可能在语义上与“猫”和“狗”有较大的差异,因此它们在空间中的位置也会相对较远。
这种稠密向量的表示方式使得词汇之间的关系可以通过向量之间的距离或角度来度量。例如,如果我们计算“猫”和“狗”的向量之间的距离,我们会发现它们比“猫”和“爱”的向量之间的距离要近,这反映了“猫”和“狗”在语义上的相似性。
对应代码:
import numpy as np
import matplotlib.pyplot as plt
# plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] #matplotlib字体显示
plt.rcParams['font.sans-serif'] = ['SimSun'] #matplotlib
from mpl_toolkits.mplot3d import Axes3D
# 定义词汇及其对应的三维向量
words = ["猫", "狗", "爱", "跑"]
vectors = [[0.3, 0.4, 0.25], [0.35, 0.45, 0.3], [0.8, 0.8, 0.8], [0.1, 0.2, 0.6]]
# 将嵌套列表转换为numpy数组
vectors = np.array(vectors)
# 创建3D图形
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
# 为每个词汇及其向量绘图
scatter = ax.scatter(vectors[:, 0], vectors[:, 1], vectors[:, 2],
c=['blue', 'green', 'red', 'purple'], s=100)
# 为每个点添加标签
for i, word in enumerate(words):
ax.text(vectors[i, 0], vectors[i, 1], vectors[i, 2], word, size=15, zorder=1)
# 设置图形属性
ax.set_xlabel('X 轴', fontsize=14)
ax.set_ylabel('Y 轴', fontsize=14)
ax.set_zlabel('Z 轴', fontsize=14)
# 移除坐标轴的数字标签
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_zticklabels([])
# 设置背景颜色和网格线
ax.set_facecolor('white')
ax.grid(True)
# 显示图形
plt.show()
结果图:
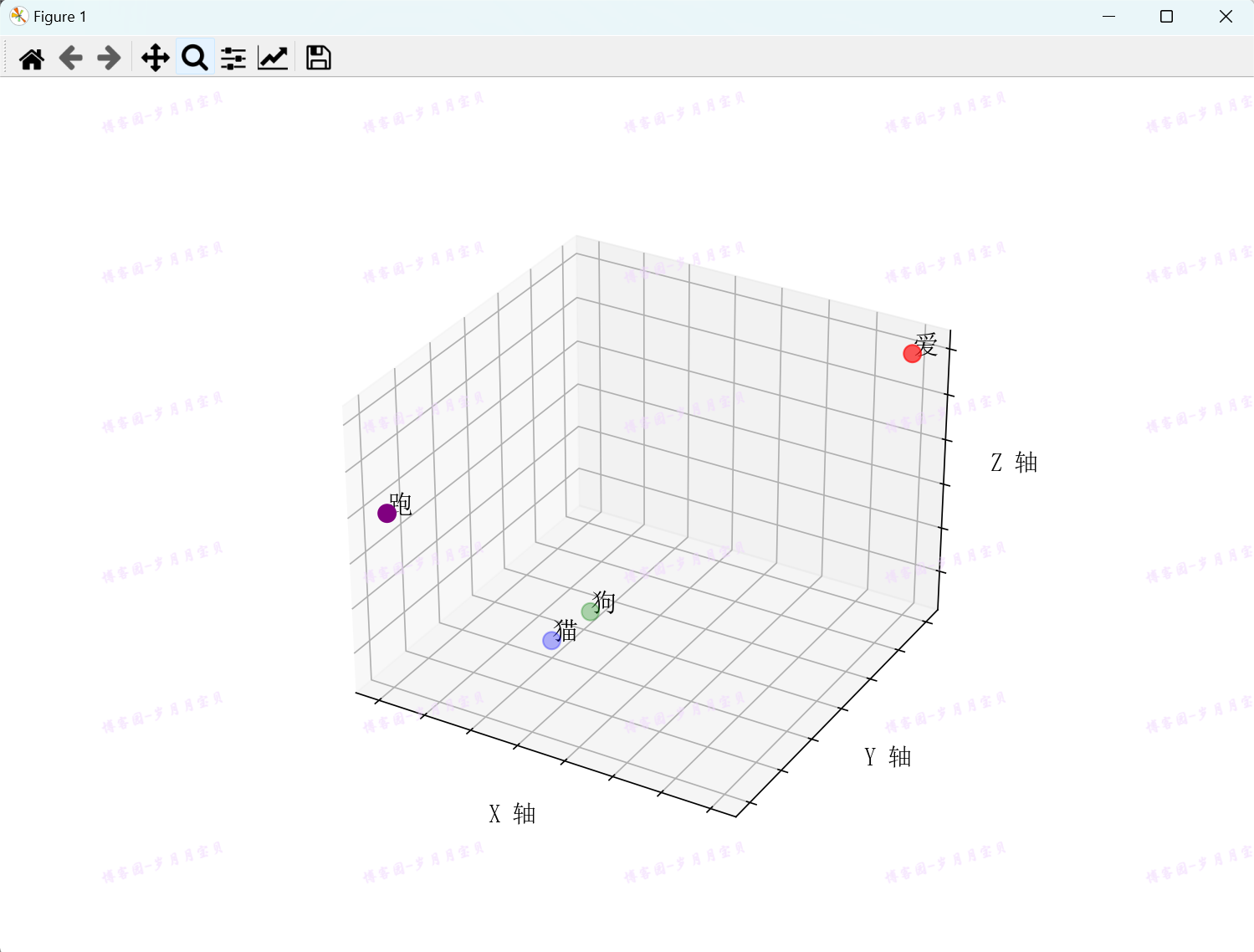
确实猫和狗更近呢🐈
下次见!期待你的推荐和关注!🎉


 浙公网安备 33010602011771号
浙公网安备 33010602011771号