

你的语言模型实际是一个奖励模型!😁Direct Preference Optimization:Your Language Model🎭is Secretly a Reward Model
直接偏好优化:你的语言模型实际上是一个奖励模型

😎其实每张PPT图下面还有解释的注释,但放上去还要改格式,太多啦!所以就靠大家读论文脑补啦!😘
摘要


1.引言

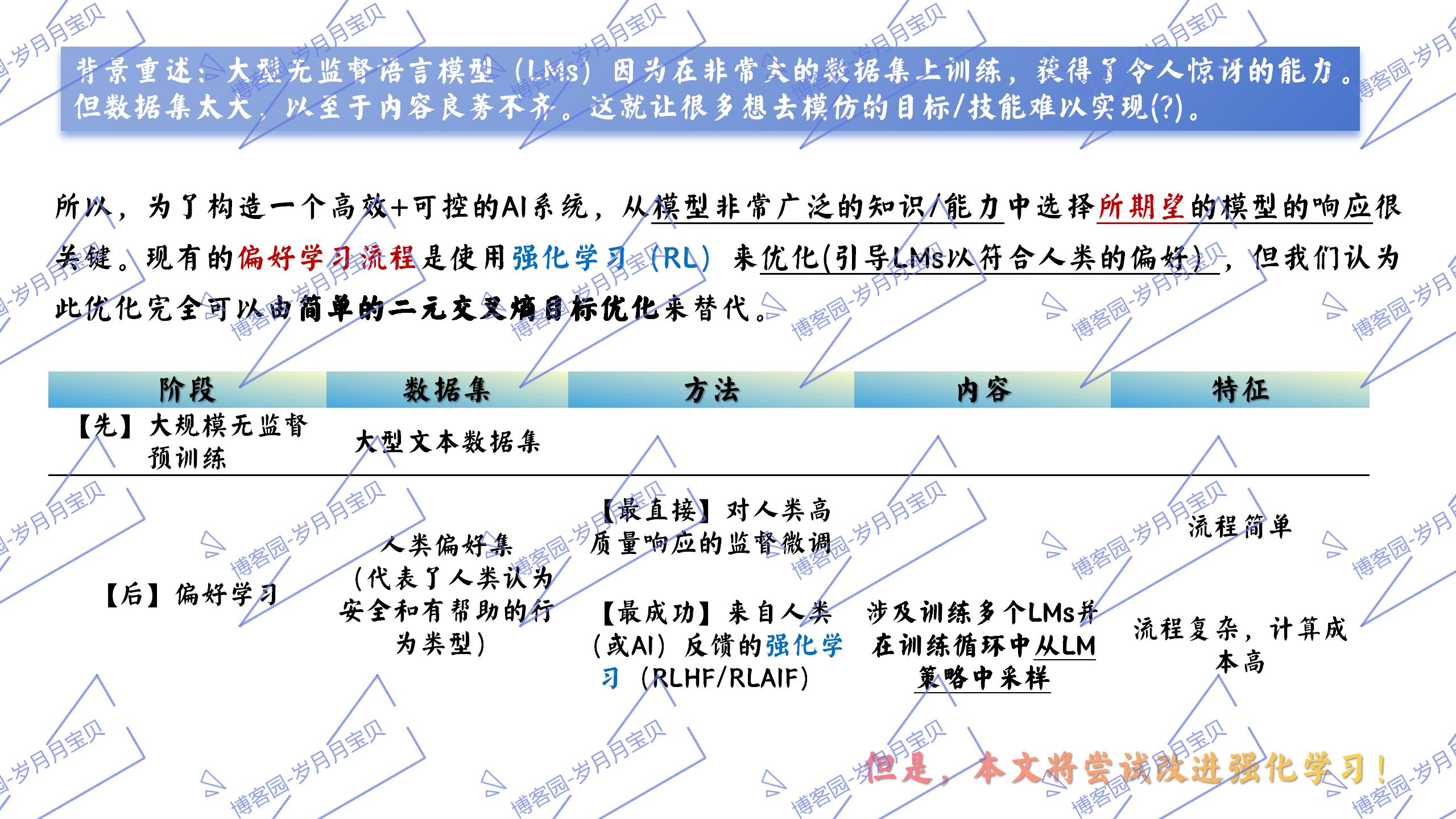

2.相关工作


3.预备知识

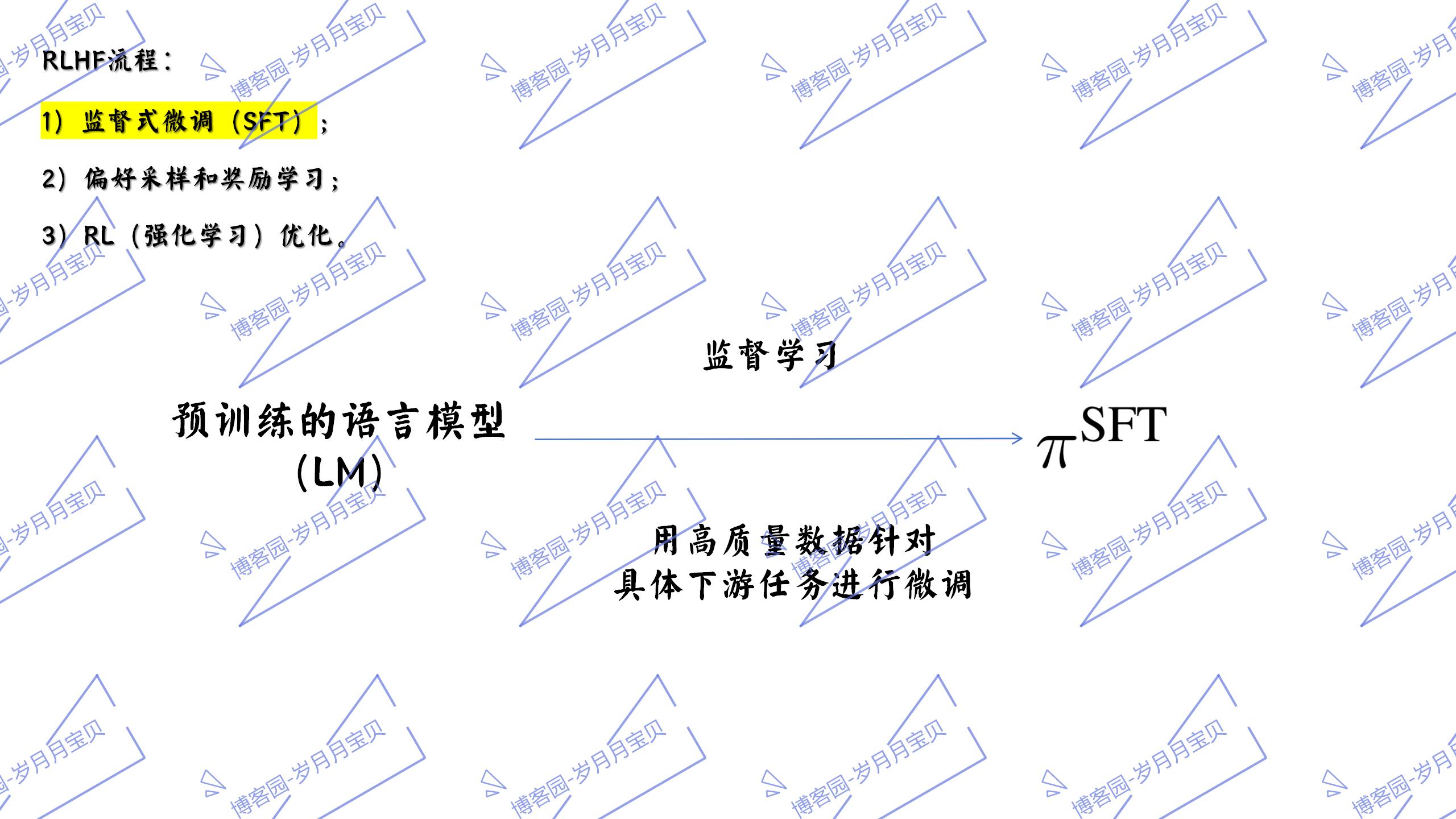


4.直接偏好优化



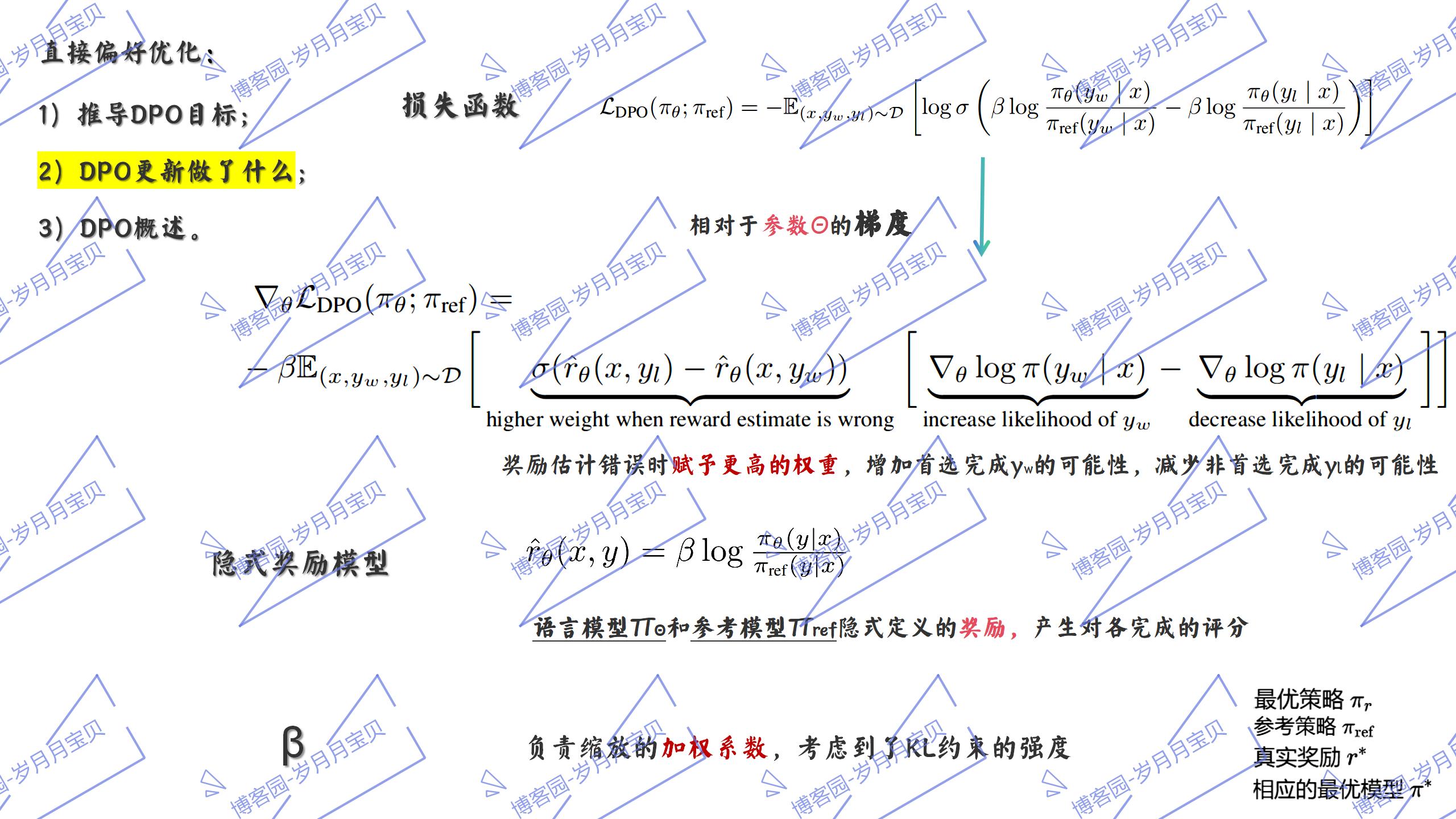

5.DPO的理论分析








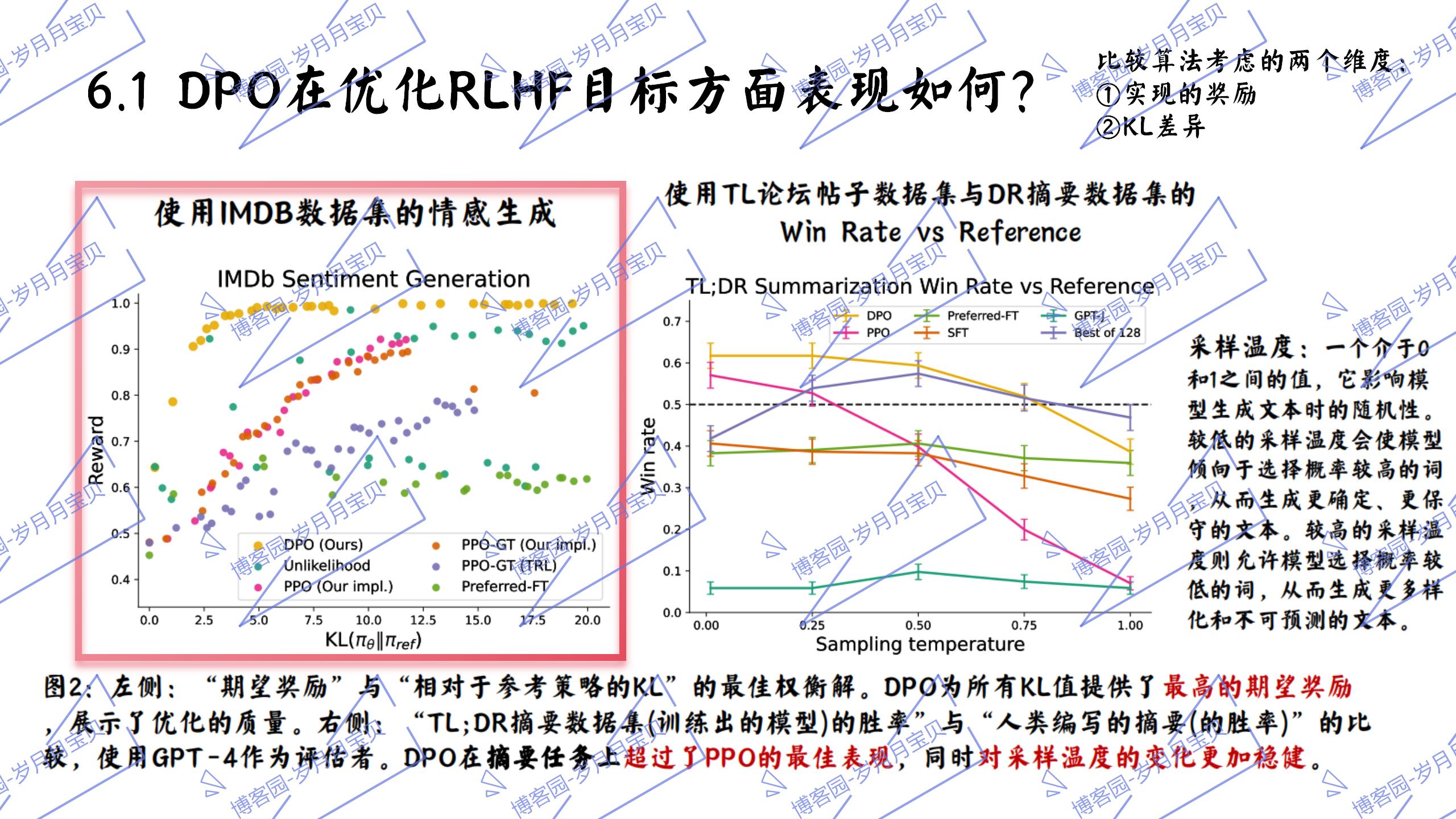
6.实验





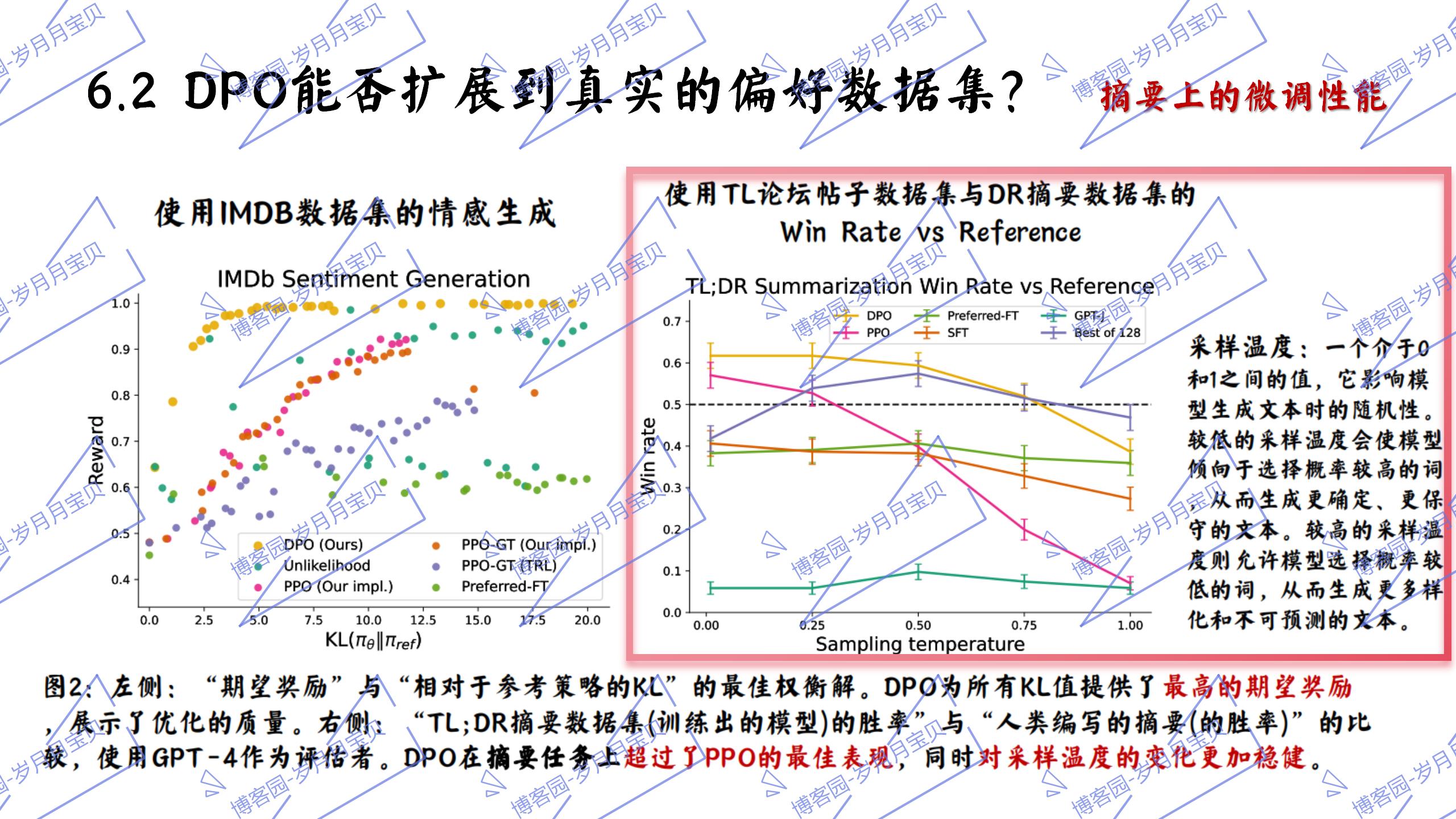
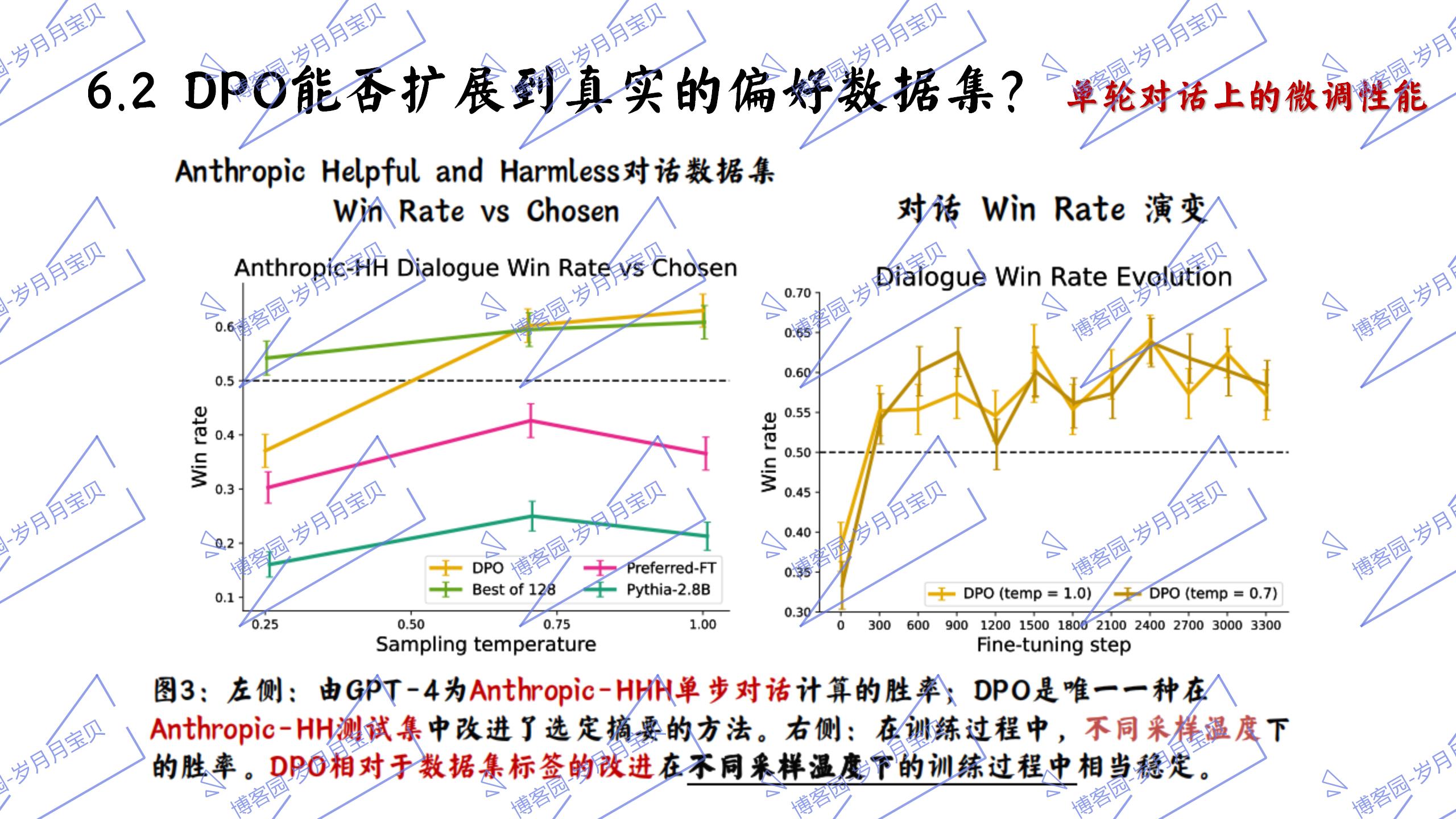


7.讨论

终


