
分布式计算编程项目三
基于MOM的分布式数据采集及分析系统
1.项目初步目标
利用MOM消息队列技术实现一个分布式数据采集和数据分析系统,具体要求:
1.多个数据采集设备(用不同的设备ID标识,实验时用多个进程模拟)每隔100ms左右就采集一个数据点(可以用正态分布的随机数模拟实现),并作为消息发布
2.一个数据统计分析微服务,针对不同设备分别进行如下数据分析:
- 计算该设备采集的过去N个数据点的均值和方差(N为常量,可设置)
- 计算该设备采集的所有历史数据中的最大值和最小值
- 定时地将分析结果打包成一个新消息并通过MOM发布出去
3.一个实时数据显示微服务:
- 针对不同设备,实时绘制该设备过去一段时间内采集数据的折线图
- 针对不同设备,实时显示该设备采集数据的统计分析结果
2.系统设计和架构
1)系统概述
本系统是一个分布式数据采集和分析系统,旨在通过多个数据采集设备收集数据,进行实时分析,并通过图形界面显示结果。系统由三大核心组成部分构成:
- 数据采集设备:多个独立的设备(模拟为进程),负责定时生成并发送数据。
- 数据统计分析微服务:接收来自采集设备的数据,对数据执行统计分析,包括计算数据的均值、方差以及历史最大值和最小值,并将分析结果重新发布到消息队列。
- 实时数据显示微服务:订阅分析结果,并将这些结果通过图形界面实时显示给用户。
2)技术栈和工具选择
- 消息队列(MOM)技术:使用 Apache ActiveMQ,这是一种高性能的开源消息代理和通信服务器,能够处理高并发的数据传输。
- 数据处理和分析:使用 Java 平台,利用其强大的处理能力及广泛的库支持,进行数据处理和分析计算。
- 数据可视化:采用
tech.tablesaw和Plotly库在 Java 环境中生成动态、交互式的图表。 - 开发环境:使用 IntelliJ IDEA 作为主要的开发IDE,由于其出色的代码管理和支持多种插件的能力,使得开发更加高效。
- 版本控制:为了确保代码的管理效率和团队的协作流畅,我采用了 Git 作为版本控制系统。Git 提供了强大的分支管理功能,支持我们在开发新功能时进行分支隔离,同时也便于进行代码审查和合并。在遇到严重错误时,我利用 Git 的回滚功能(如
git revert和git reset)快速恢复到稳定状态,最大限度地减少了故障对项目进度的影响。
3)详细设计
(1)数据流
系统的数据流开始于各个数据采集设备,每个设备定时生成数据,并通过预定的 ActiveMQ 主题发送。数据统计分析微服务订阅这些主题,接收数据,并进行必要的统计计算。计算完成的结果被发布到另一个主题,由实时数据显示微服务订阅并显示。
(2)接口设计
- 数据采集设备向名为“IDx”的主题发布消息,其中“x”是设备ID。
- 数据统计分析微服务订阅所有设备主题,接收消息,并将处理结果发布到“AnalysisRes”主题。
- 实时数据显示微服务订阅“AnalysisRes”主题,获取分析数据并更新图形界面。
(3)处理逻辑
- 数据采集设备每100毫秒生成一个服从正态分布的随机数据点,使用 Java 的
Random类实现。 - 数据统计分析微服务在接收到足够数量的数据后(由参数 N 定义),计算最近 N 个数据的均值和方差,使用 Java 的流操作进行计算,并持续更新全局的最大值和最小值。
- 实时数据显示微服务使用
tablesaw和Plotly实时绘制数据折线图,并展示最新的统计分析结果。
3.实现
1)代码实现
本项目的实现过程中遇到了几个技术挑战,特别是在性能优化和资源管理方面。
(1) 数据处理的延时问题
在数据分析微服务中,为了保证足够的数据点被收集并分析,我最初直接在消息监听器中进行了数据处理。然而,这导致处理过程阻塞了消息接收,影响了系统的响应速度。为了解决这一问题,我引入了一个2000毫秒的延时(Thread.sleep(2000)),以等待足够的数据积累。这确保了每次分析都基于充分的数据进行,提高了统计结果的准确性。
(2)高频数据生成与发送
对于每个数据采集设备,需要每100毫秒生成并发送一次数据。这一要求对系统的性能提出了挑战,尤其是在多个设备同时运行时。为了管理这种高频任务,我选择了使用 ScheduledExecutorService。这允许我们精确控制任务的执行时间和频率,并且利用线程池有效地管理资源,避免了创建过多线程带来的资源消耗和竞争条件。
实现结果
1.初始状态:
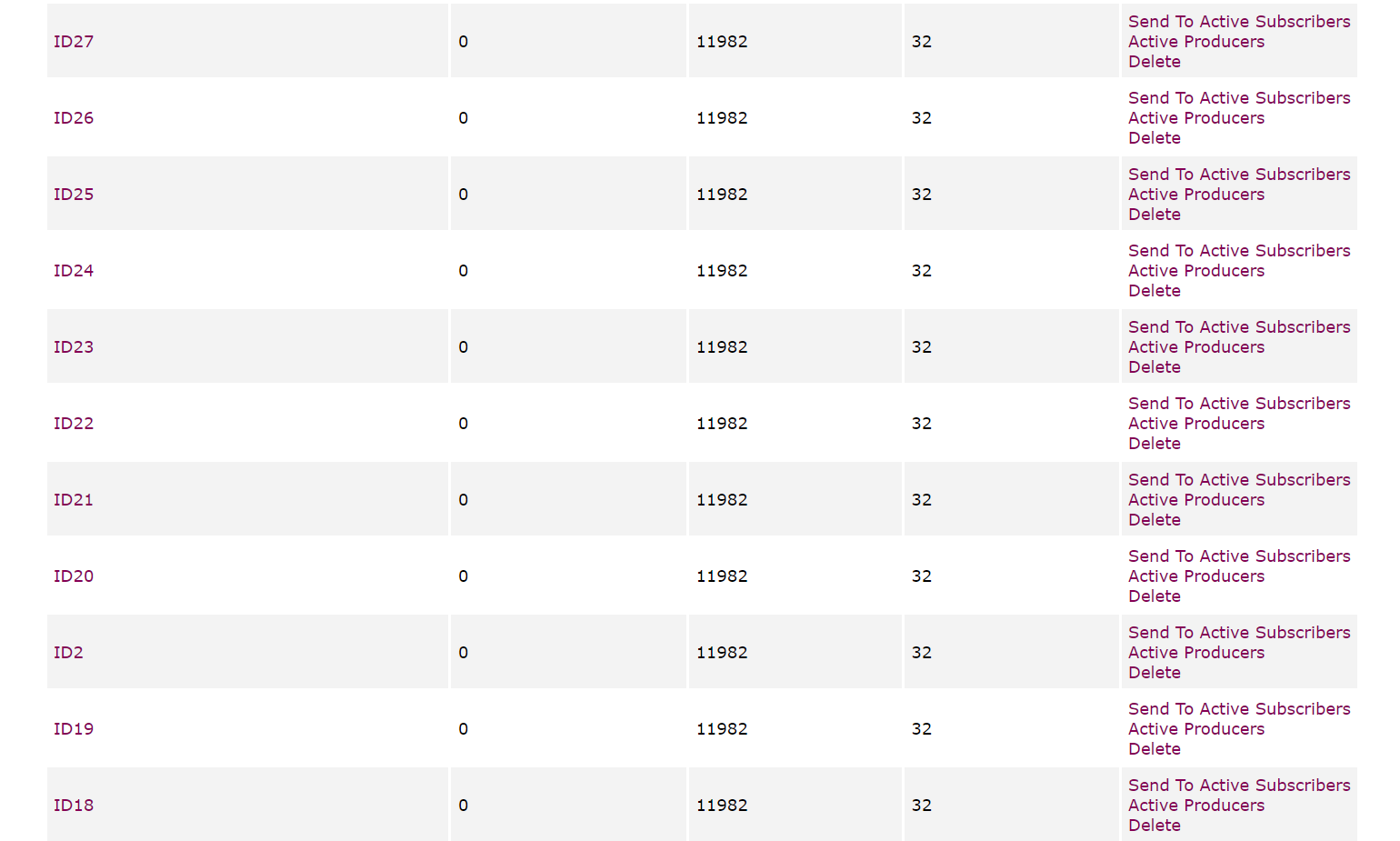
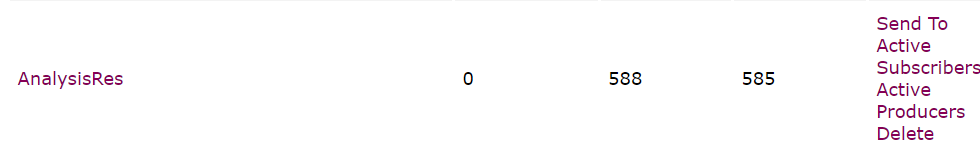
2.Publisher 类模拟了多个数据采集设备,每个设备使用一个唯一的设备ID,并且定时(每100ms)生成正态分布的随机数作为数据点,然后发布这些数据到消息队列中。
Analyzer类通过MyListener1监听器,为每个设备独立进行数据分析,计算过去N个数据点的均值和方差,以及所有历史数据中的最大值和最小值。分析结果被封装成消息再次通过MOM发布。
4.Visualizer 类通过 MyListener2 监听器,实时绘制不同设备采集的数据折线图,并显示统计分析结果。
“图的标题-ID号”对应的号码即为设备号,
5.对应图像演化过程:
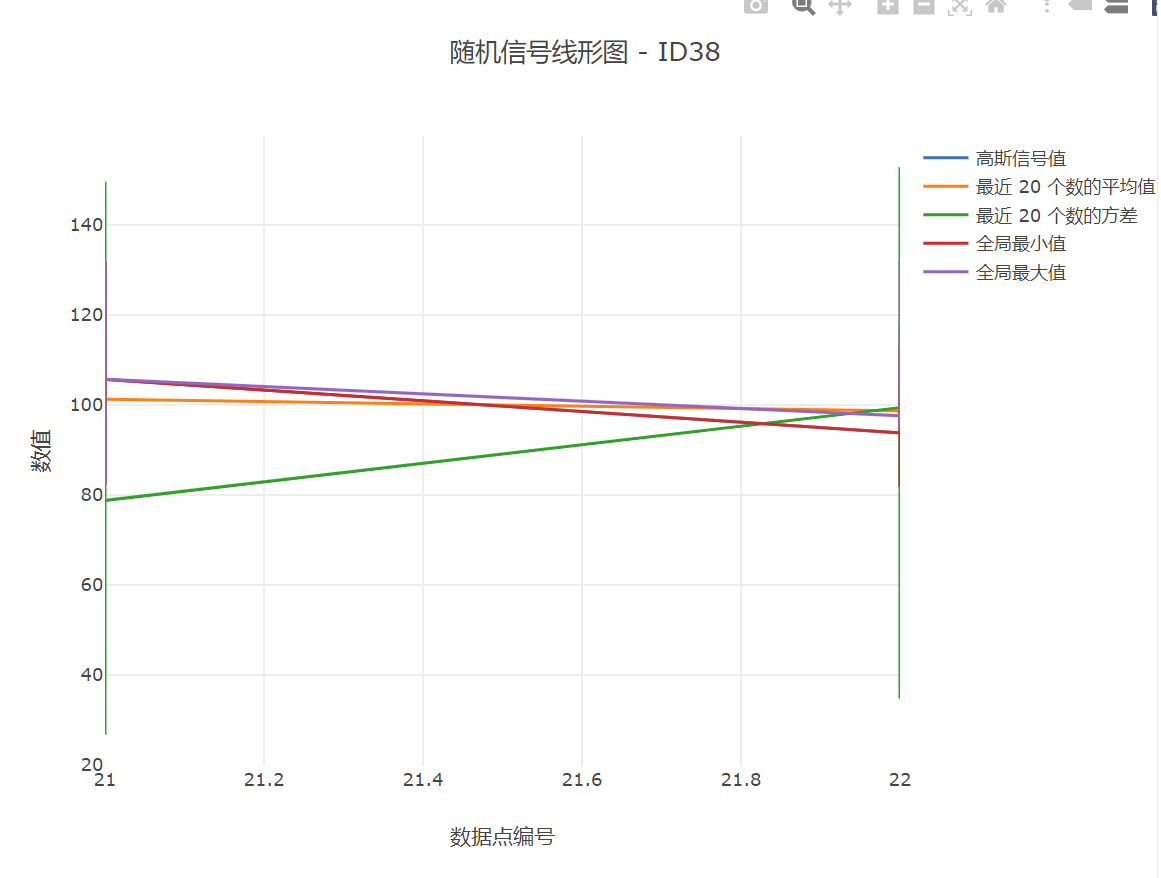
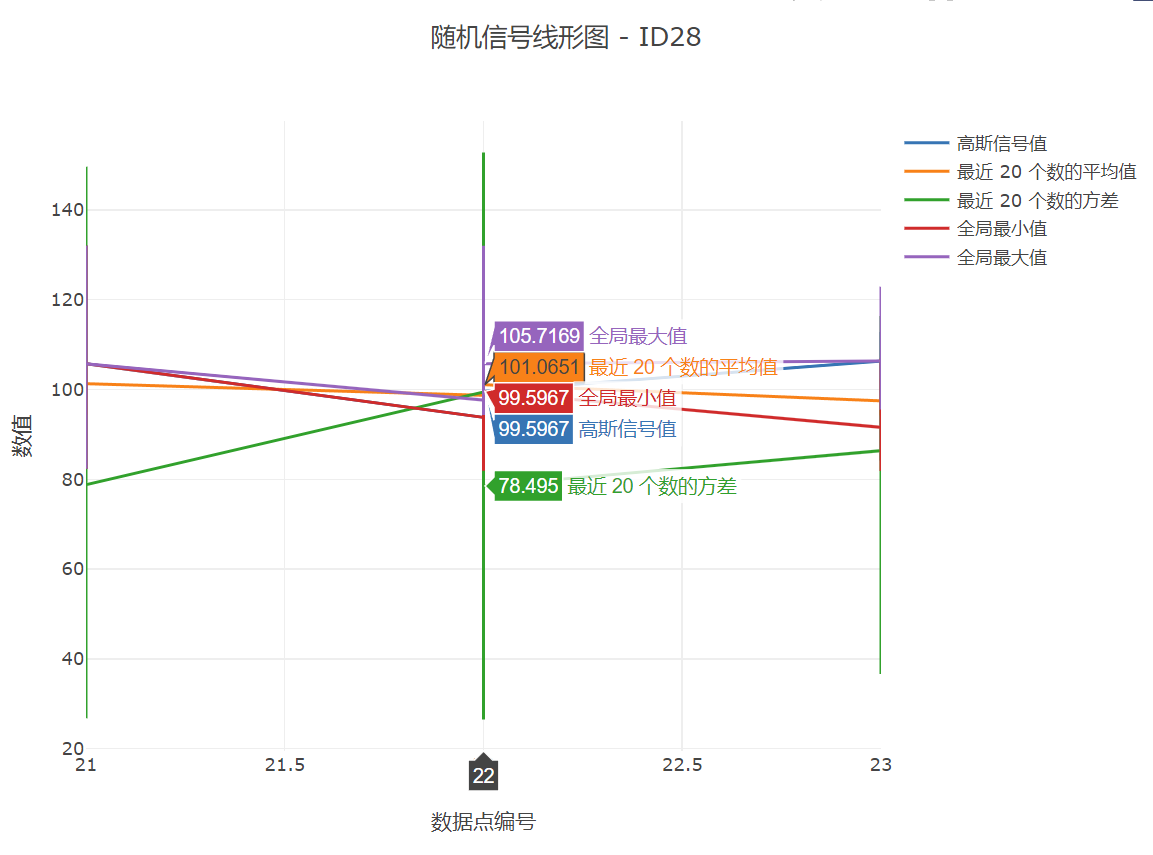
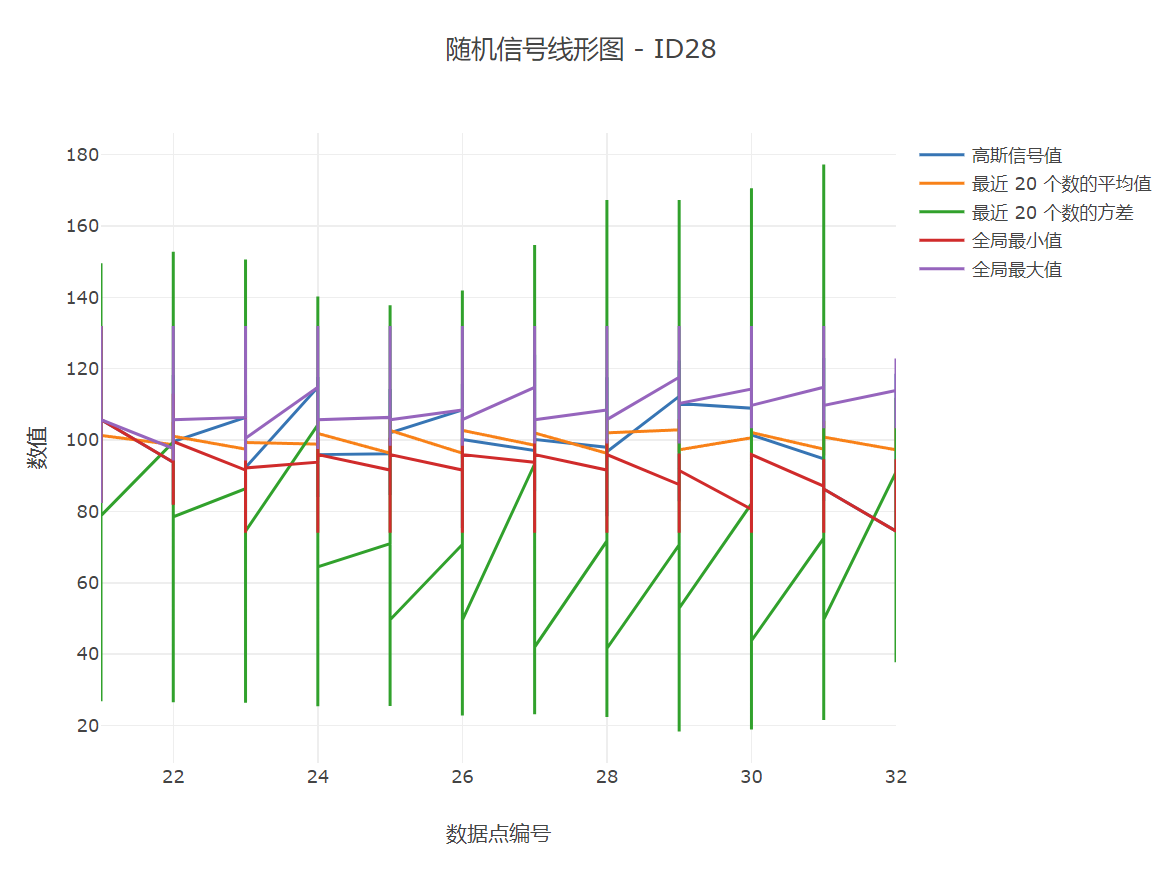
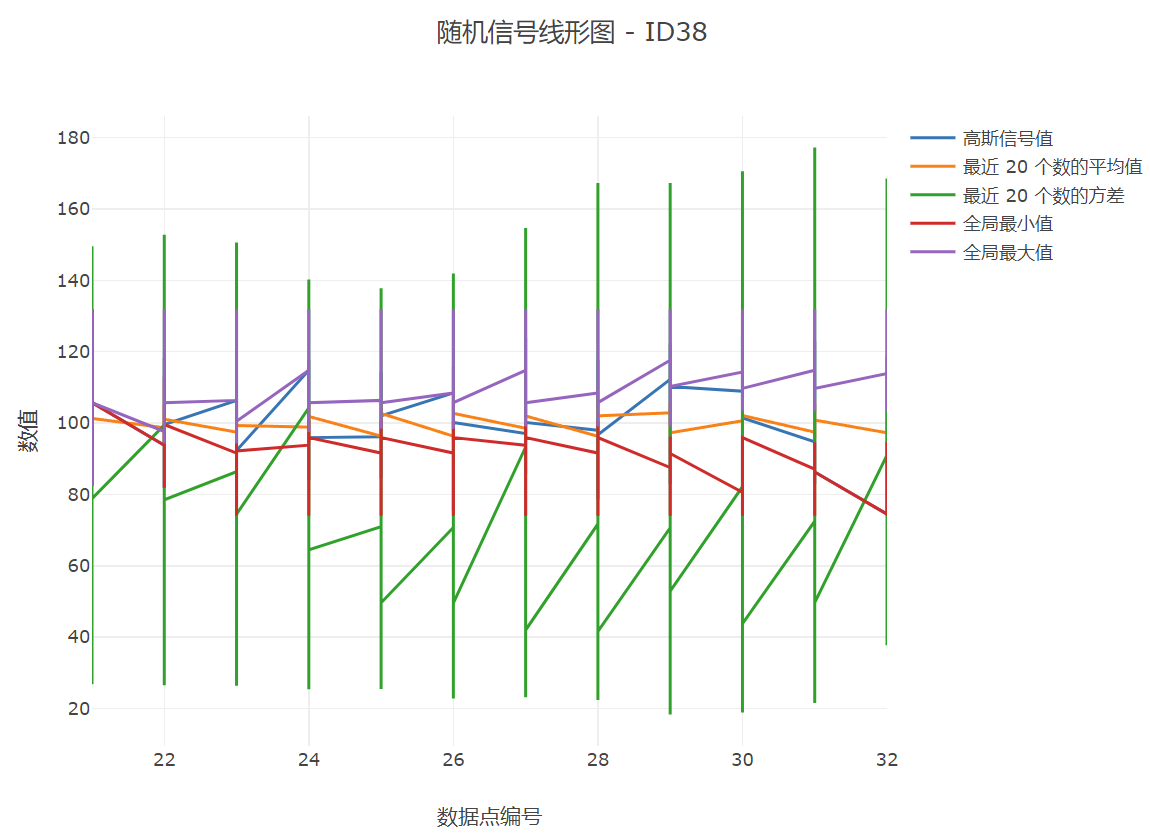
这里的数据点,因为是严格按照时间顺序的,所以也可以看作时间轴。当然,我们可以通过查看网页源代码获取更多信息:
(因为图像就是表的刻画)
6.ActiveMQ结果显示:
下面为我们分析类的结果呈现:

虽然数据显示了正面的变化,但入队远大于出队属于不匹配的增长,可能指出性能瓶颈或配置问题。这需要将来进一步的分析,可能包括深入查看消息处理日志、检查网络延迟、消费者处理能力和消息队列的配置设置。
(这里的“入队”通常指消息被发送到队列中,而“出队”则指消息被消费者接收。)
7.命令行结果呈现(清晰的统计变量)
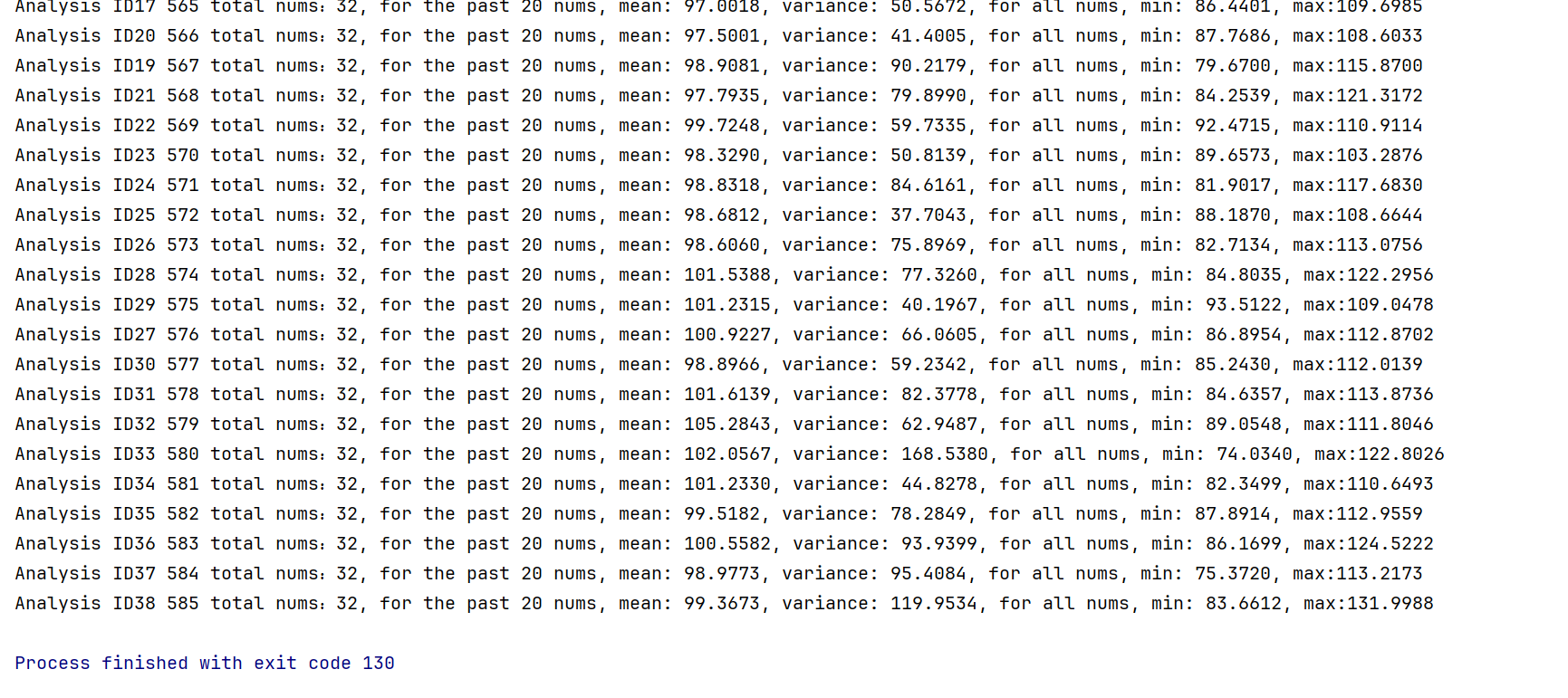
2)功能实现
(1)数据采集设备的模拟
实现了一个 Publisher 类来模拟数据采集设备。每个设备实例使用 ScheduledExecutorService 按照设定的时间间隔(100毫秒)生成一个符合正态分布的随机数,并通过 JMS 发送到相应的消息队列。通过线程池的使用,每个设备的数据生成和发送过程都是独立的,互不干扰,保证了数据的连续性和准确性。
(2)数据统计与分析
Analyzer 类负责订阅设备发送的数据,并进行实时分析。它计算每个设备发来的最近N个数据的均值和方差,同时更新全局的最小值和最大值。这些统计信息每2000毫秒更新一次,并通过一个新的消息发布出去。这里使用延时是为了缓冲数据,确保每次计算时有足够的新数据。
(3)实时数据显示
Visualizer 类订阅分析结果的主题,并使用 tablesaw 和 Plotly 实时绘制数据折线图。该过程中,我们为每种类型的数据(如值、均值、方差等)设置了不同的图表系列,以便用户能够清楚地看到各种统计信息的变化趋势。
4.测试
1)测试策略
为了全面验证系统的功能和性能,我采取了以下测试策略:
(1)单元测试
- 对系统中的关键功能模块(如数据生成、消息发送、数据接收和处理等)进行单元测试。
- 使用JUnit框架进行自动化测试,确保每个方法按照预期工作。
(2)集成测试
- 测试各个组件(数据采集设备、数据分析服务和数据显示服务)之间的接口和数据流。
- 通过模拟真实的使用场景,测试系统在接收、处理和显示数据时的整体性能和稳定性。
2)测试结果与分析
在初期测试中,发现所有设备生成的数据图均呈直线,这提示我们数据变化不够显著。进一步分析后,确认原因如下:
-
方差设置问题:初步设置的方差过小,导致生成的数据点变化不明显。通过调整方差参数,增加数据的波动性,以更真实地模拟实际环境中的数据波动。
-
数据发送方式:最初的串行发送方式导致了数据处理的瓶颈。我优化了
Publisher的实现,引入了并行处理机制,使用ScheduledExecutorService管理独立的发布任务,有效改善了数据处理和发送效率。
图表显示
- 在调整了方差和并行处理机制后,测试图表显示出了明显的数据波动,与预期更为吻合。
- 分析微服务成功计算并发布了每个设备的数据均值、方差、最大值和最小值。
这些测试和调整验证了系统的可靠性和有效性。系统现能够在高负荷下稳定运行,及时准确地展示数据分析结果。
5.性能评估
1)基于测试数据的系统性能
经过一系列的性能测试,我评估了系统在不同负载和配置下的表现。测试结果表明,系统能够有效处理高频率的数据传输。通过引入 ScheduledExecutorService,系统优化了任务调度,降低了延迟,并保持了高吞吐量,特别是在多个数据采集设备同时工作时。
2)可能的改进措施
尽管当前系统性能稳定,但以下几点改进可以进一步增强系统的可用性和效率:
- 负载平衡:随着设备数量的增加,可以引入更复杂的负载平衡策略,以优化资源使用和提高响应速度。
- 数据压缩:对发送的数据进行压缩,以减少网络传输的数据量,进一步提高传输效率。
- 优化数据结构:探索使用更高效的数据结构来存储和处理大量数据点,例如使用并发集合来提高多线程操作的性能。
6.讨论和反思
1)项目中遇到的问题及解决策略
- 消息队列的选择与配置:选择 ActiveMQ 是基于其广泛的社区支持和出色的性能记录。通过调整消息队列的配置,我们能够支持高频率的消息传输和大量客户端的连接。
在使用 Apache ActiveMQ 作为消息队列系统的过程中,支持高频率的消息传输和处理大量客户端连接的能力是通过优化其配置 activemq.xml来实现的。
1. 调整连接设置
-
增加连接限制:默认情况下,ActiveMQ 的连接数可能有限制,通过调整
maximumConnections和prefetchPolicy可以增加并发连接的数量和每次连接预取的消息数量。这样做可以确保在高并发场景下,连接不会成为瓶颈。<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
2. 优化消息存储
-
异步发送和持久化:在配置文件中启用异步发送和异步持久化,可以显著提高消息处理速度,尤其是在高负载情况下。这通过减少消息发送和存储时的等待时间,允许更快的消息吞吐率。
<policyEntry queue=">" producerFlowControl="true" memoryLimit="1mb"> <pendingQueuePolicy> <fileQueueCursor/> </pendingQueuePolicy> </policyEntry>
3. 内存管理
-
调整内存限制:为 ActiveMQ 设置适当的内存限制,确保它有足够的资源处理消息,同时避免消耗过多系统内存影响其他应用。同时,合理配置内存溢出策略,防止在极端情况下系统崩溃。
<systemUsage> <systemUsage> <memoryUsage> <memoryUsage limit="512 mb"/> </memoryUsage> <storeUsage> <storeUsage limit="2 gb"/> </storeUsage> <tempUsage> <tempUsage limit="1 gb"/> </tempUsage> </systemUsage> </systemUsage>
优化调度策略
-
调度支持:在 ActiveMQ 中启用定时和延迟消息的支持,这可以帮助应用更灵活地处理消息发送逻辑,例如在非高峰时段处理非紧急信息,从而平滑负载。
<broker xmlns="http://activemq.apache.org/schema/core" schedulePeriodForDestinationPurge="10000">
通过上述配置的调整和优化(重启 ActiveMQ 服务以使这些更改生效), ActiveMQ 实例将能够更好地处理高频率的消息传输和大量的客户端连接。这些调整帮助确保消息系统在面对高负载和大规模操作时的性能和稳定性,是实现高效消息传输系统的关键部分。
- 线程安全和性能优化:在
Publisher中使用ScheduledExecutorService确保了并发数据生成的线程安全,同时优化了性能,避免了线程过多带来的系统资源耗尽。
在 Publisher 类中,使用了 ScheduledExecutorService 来定时发送数据。这是一个有效管理线程和提高资源使用效率的做法。使用线程池而不是为每一个任务创建新的线程可以减少因线程创建和销毁带来的开销和资源消耗,同时还可以防止因创建无限多的线程而耗尽系统资源。
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(n);
在这段代码中,newScheduledThreadPool(n) 创建一个固定数量的线程池,其中 n 是预定的线程数,通常与数据采集设备的数量相等。这些线程将被复用来执行后续的定时任务。
javaCopy codefor (Publisher publisher : publishers) {
scheduler.scheduleAtFixedRate(() -> {
try {
publisher.sendNum(mu, sigma);
} catch (JMSException e) {
e.printStackTrace();
}
}, 0, 100, TimeUnit.MILLISECONDS);
}
在这个循环中,每个 Publisher 实例都安排了一个定时任务,这些任务将在一个固定的时间间隔(每100毫秒)执行。使用 ScheduledExecutorService 允许所有这些任务共享一个预设数量的线程,而不是为每个任务创建一个新的线程。这样不仅可以保证高效的任务执行,也避免了创建过多线程可能导致的内存溢出或CPU过载等问题。
通过这种方式,减少了线程创建和销毁的开销,防止了因过多线程而耗尽系统资源,提供了更稳定的线程管理机制,可以平滑地处理峰值负载.
-
异常处理:我们实施了相关的异常处理策略,尤其是针对网络或JMS服务的异常,确保了系统在出现故障时可以稳定运行。
public void sendNum(double mu, double sigma) throws JMSException { try { double num = Math.sqrt(sigma) * random.nextGaussian() + mu; TextMessage message = session.createTextMessage(String.valueOf(num)); producer.send(message); } catch (JMSException e) { e.printStackTrace(); throw e; } }目前直接的异常处理主要体现在
try-catch块的使用,尤其是在网络通信和消息处理部分。这些处理确保了在发生异常(如网络故障、消息格式错误等)时,系统能够捕获异常并作出响应,而不会导致整个应用崩溃。未来考虑进行错误日志记录、异常分类处理以及消息队列持久化。 -
Publisher持续运行:另外,我们为publisher加入了一项每秒检测它是否需要中断的循环,保证它无意外均可持续运行;
-
最大值/最小值判断简化:我们还优化了最大值/最小值的判断方法,并赋予max与min合适的初值。
-
JMS 消息确认模式:我选择了CLIENT_ACKNOWLEDGE消息确认模式,这允许应用程序在确认前进行适当的处理,确保只有处理成功的消息才被确认。
2)学习到的知识
- 深入理解了 MOM 和 JMS 的工作原理及其在分布式系统中的应用。
- 掌握了并发编程的关键技术,包括线程安全和线程池的使用。
- 学习了数据可视化技术,特别是如何在 Java 中实现动态和交互式图表。
3)未来的工作
未来计划探索使用更高效的消息队列技术,如 Apache Kafka,并对数据处理算法进行优化,以支持更大规模的数据分析。
7.结论
本项目成功实现了一个分布式数据采集和分析系统,满足了高频数据采集、实时数据分析和动态数据显示的需求。项目不仅加深了对分布式系统、消息中间件和并发编程的理解,也提升了在实际应用中处理和可视化大规模数据的能力。
附:课堂尝试
1.ActiveMQ安装:通过官网https://activemq.apache.org/components/classic/download/我记得它只有两个稳定版本,我下载的是最新的稳定版本,然后解压安装包到D盘里。

2.然后我们查看它依赖的JDK版本,接着发现自己没有JDK17(其实是从Active MQ的如下报错中摸索出来的:UnsupportedClassVersionError: org/apache/activemq/console/Main has been compiled by a more recent version of the Java Runtime (class file version 61.0), this version of the Java Runtime only recognizes class file versions up to 52.0 )
3.所以接着去Java Downloads | Oracle完成了它的下载,然后配置好了用户变量与环境变量(开始我是写脚本操作的,但是发现setx修改path时可能会出现路径过长截断的问题,所以不如手动修改),这个还要注意把你使用的JDK版本优先排到Path的前面。另外,从java 9开始,JDK就包括了JRE了,所以不用单独安装JRE。
4.在命令提示符中使用 echo %JAVA_HOME% 和 echo %PATH% 来验证环境变量是否正确设置,也可以运行 java -version 来检查当前哪个版本的 Java 是活跃的.
5.现在Active MQ已经被安装到了一个没有中文的路径中了,然后注意!不能运行最开始看到的.bat文件,要进入win64目录下运行里面的bat文件,双击即可运行.
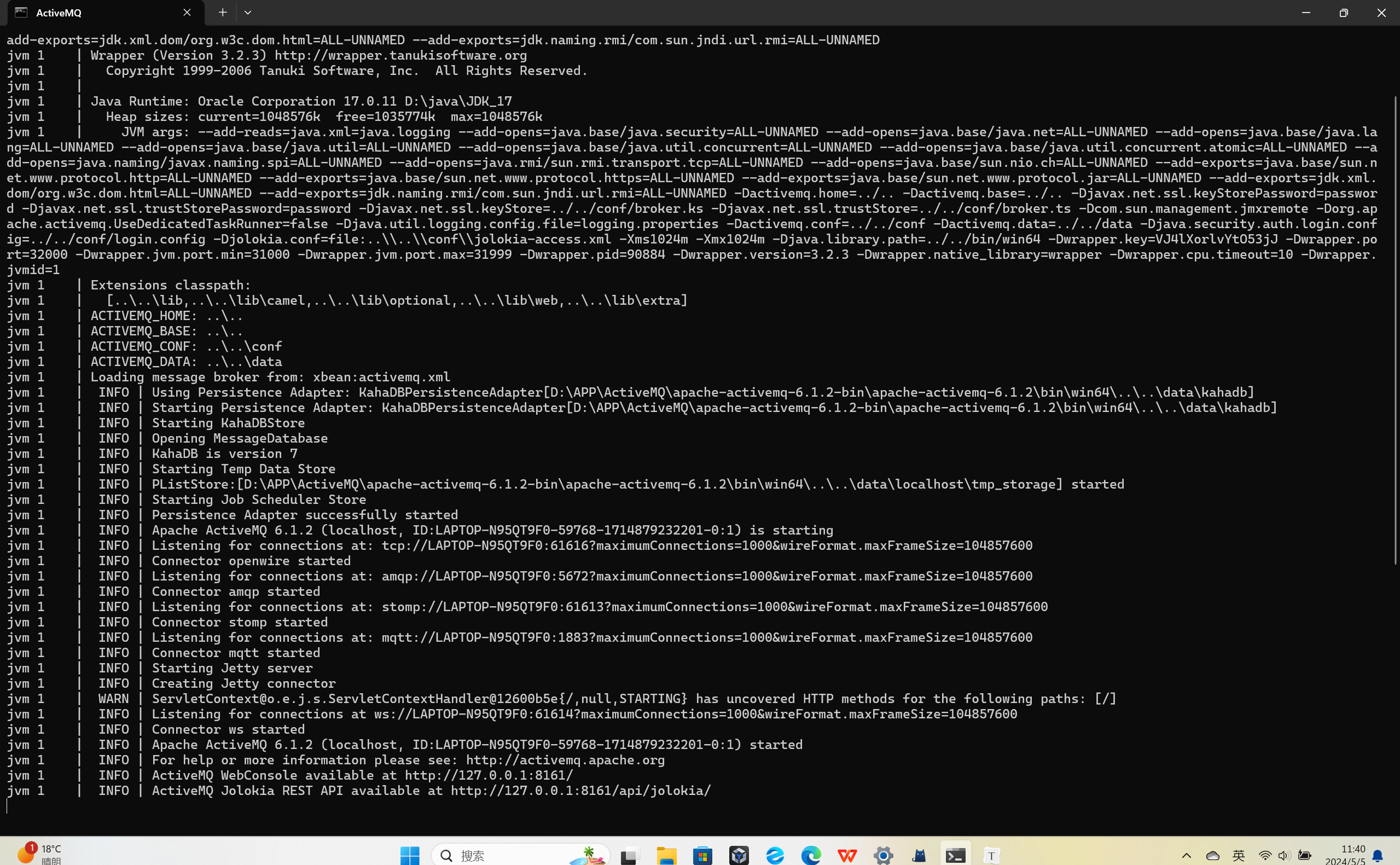
6.运行概况(注意正确的打开是不会闪退的,然后让他一直保持在哪里,不用关这个框):
7.然后在任一浏览器中输入http://127.0.0.1:8161/admin/ ,可以看到以下信息:
(用户名和密码都是admin)
这里还能看到使用这个消息中间件目前历时21min;
点击Queues可以看到目前的入队出队信息:
目前没有入队出队信息.
8.接着,退出软件只需要在ActiveMQ界面输入'Ctrl+C'即可退出,它会问你"是否终止批处理文件",你输入'Y'表示同意,即可正常退出.
(为什么我没有使用'activemq start'命令?因为报错:无法将“activemq”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保 路径正确,然后再试一次。CommandNotFoundException )
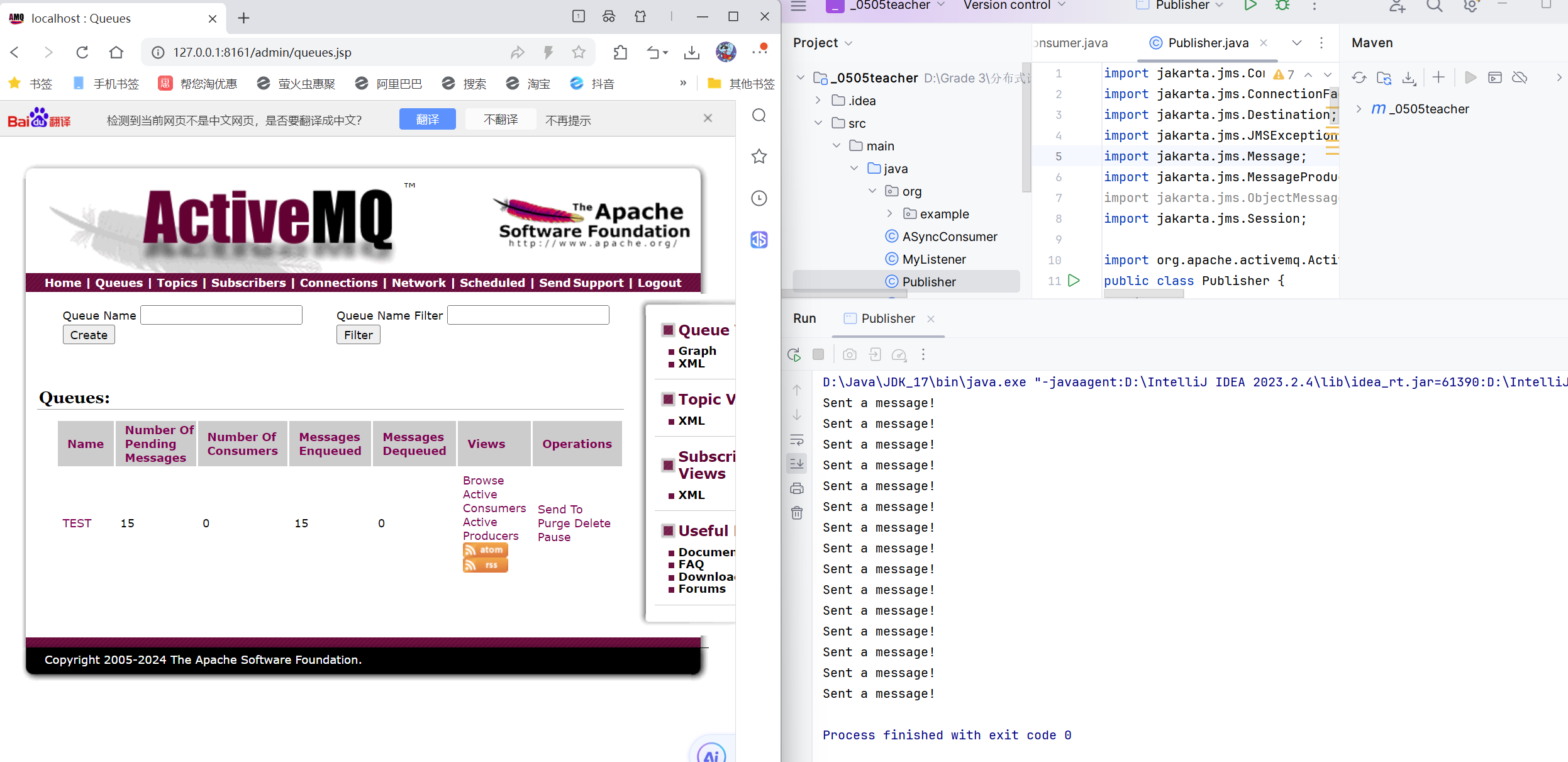
1.queue-基于队列
 jar包两个问题:
jar包两个问题:
1.传递依赖的关系:
JAVA->a.jar->b.jar,
2.版本的问题:
jar版本的问题:2.0的jar包环境变量可能会移动到原来的里面,使得新的老的程序不能同时运行.
解决方法:Maven(重点是采用它导入版本匹配不冲突的依赖,但是注意选择怎样的依赖不太会影响import包的导入,在代码中直接alt+enter就可以了)
通过pom.xml文件:
step1:clean
step2:compile(会自动分析,从中央仓库里下载jar包,并且只是临时把它配置到你的环境变量里)
step3:打包
step4:运行一些自动化的单元测试
里面还可以补充工程设计的源程序都放到了哪个子目录了,你的子目录结构是什么(默认的则不用写)
Maven配置时比较好的是有一个中央仓库:
老师的命令行方法:

编译后多了class文件:
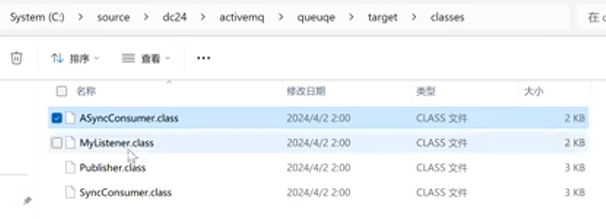

所以,多了一个叫Test的队列:

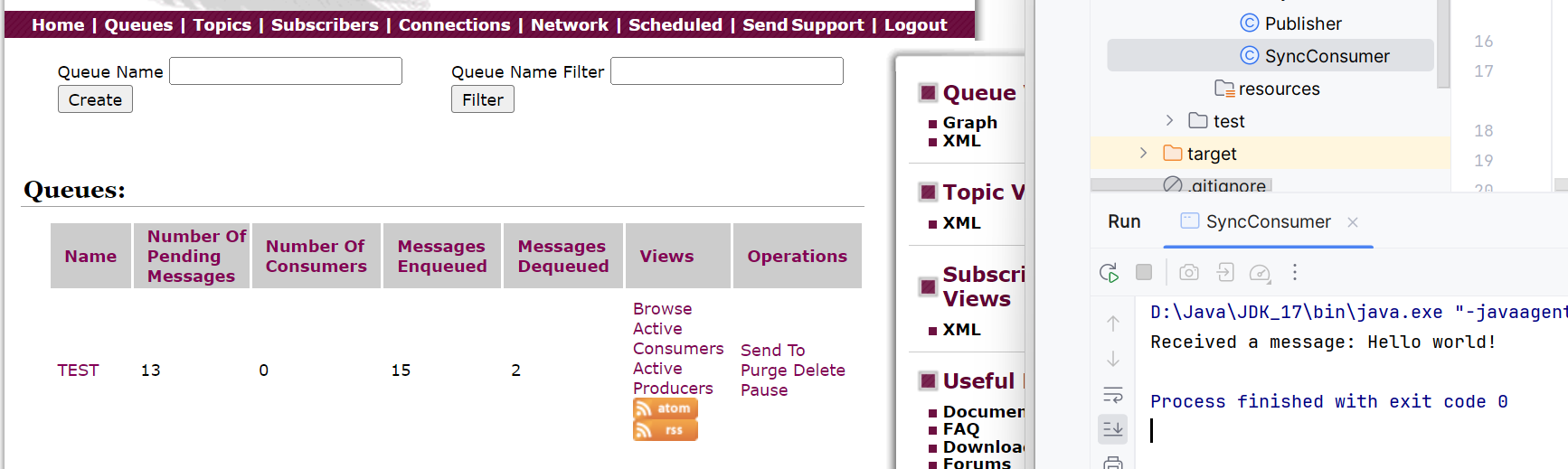
下面我们运行的是同步接收消息:


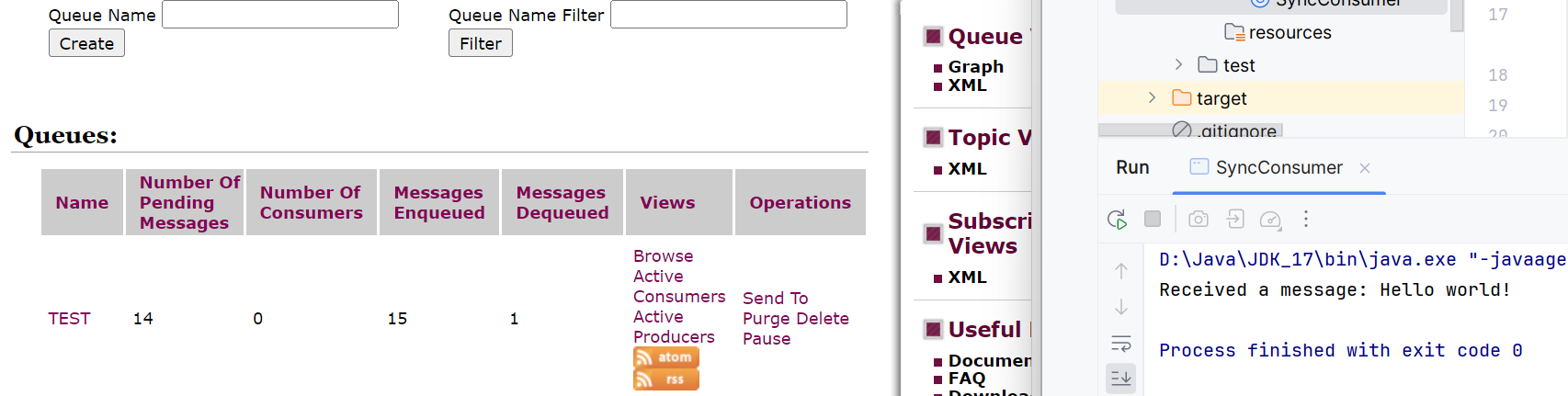
下面是异步:

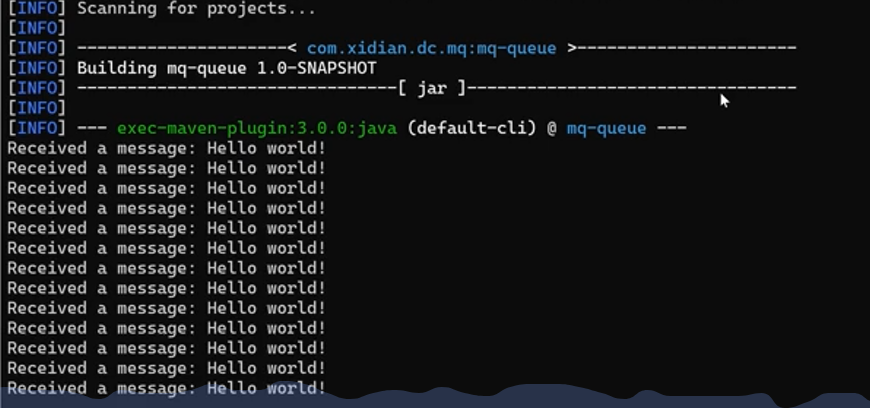
因为队列里面目前有13个消息,它会主动触发onMessage触发13次,接着因为就没有消息了,就暂停到
里面了,

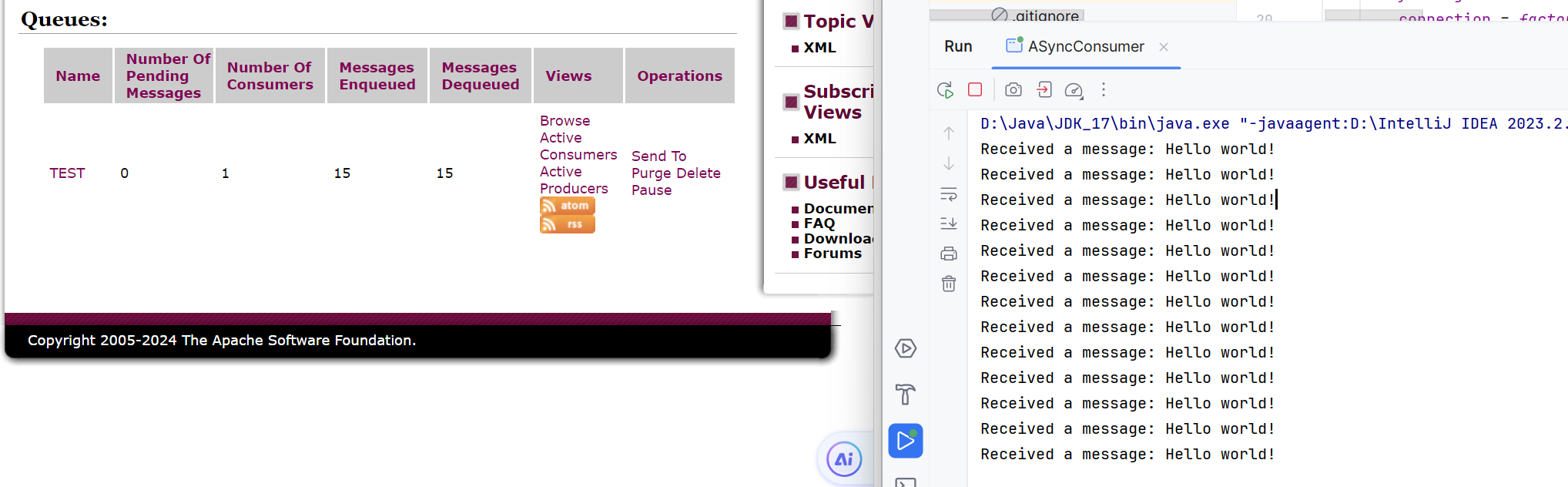
看下面的图,悬而未决的消息为0,有15个消息入队,然后有15个消息出队
基于队列的就讲完了,下面是基于主题的
2.Topic-基于主题
cls
mvn clean
mvn compile
然后这里先运行消费者程序

他这里卡到这里了,(因为消息队列中没有消息了)只能再启动一个终端(在同一个目录上再启动一下终端,,但不是一个终端)
开始单运行ASyncConsumer时只显示:
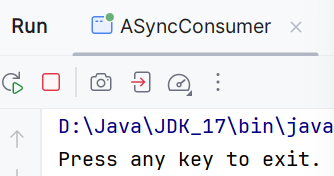
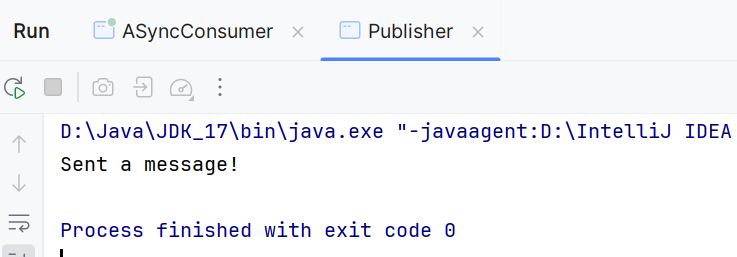
接着运行Publisher:
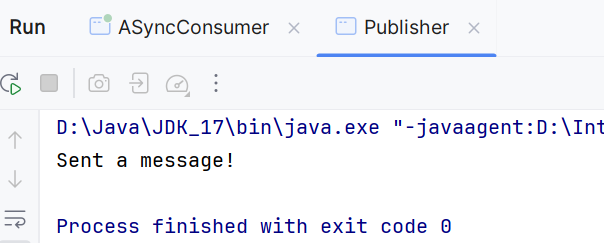
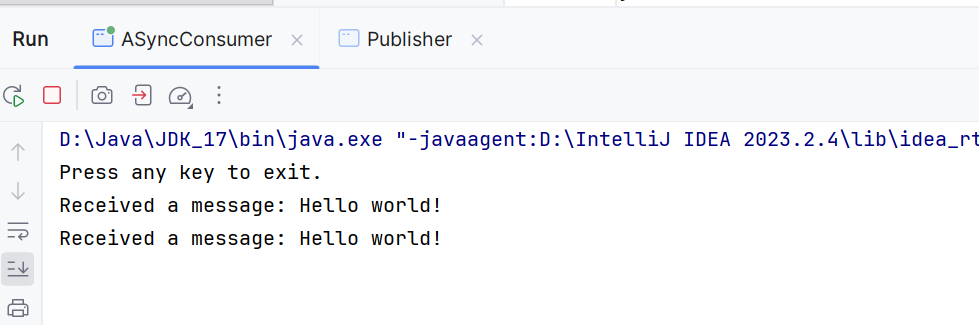
再转到ASyncConsumer会发现:
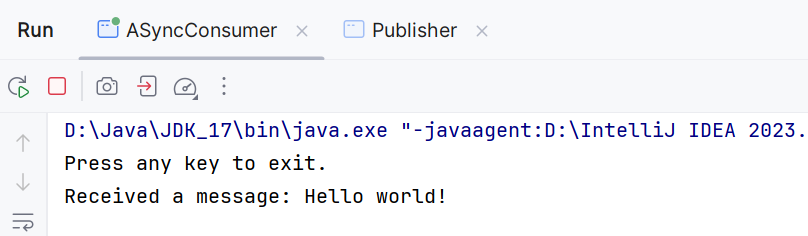
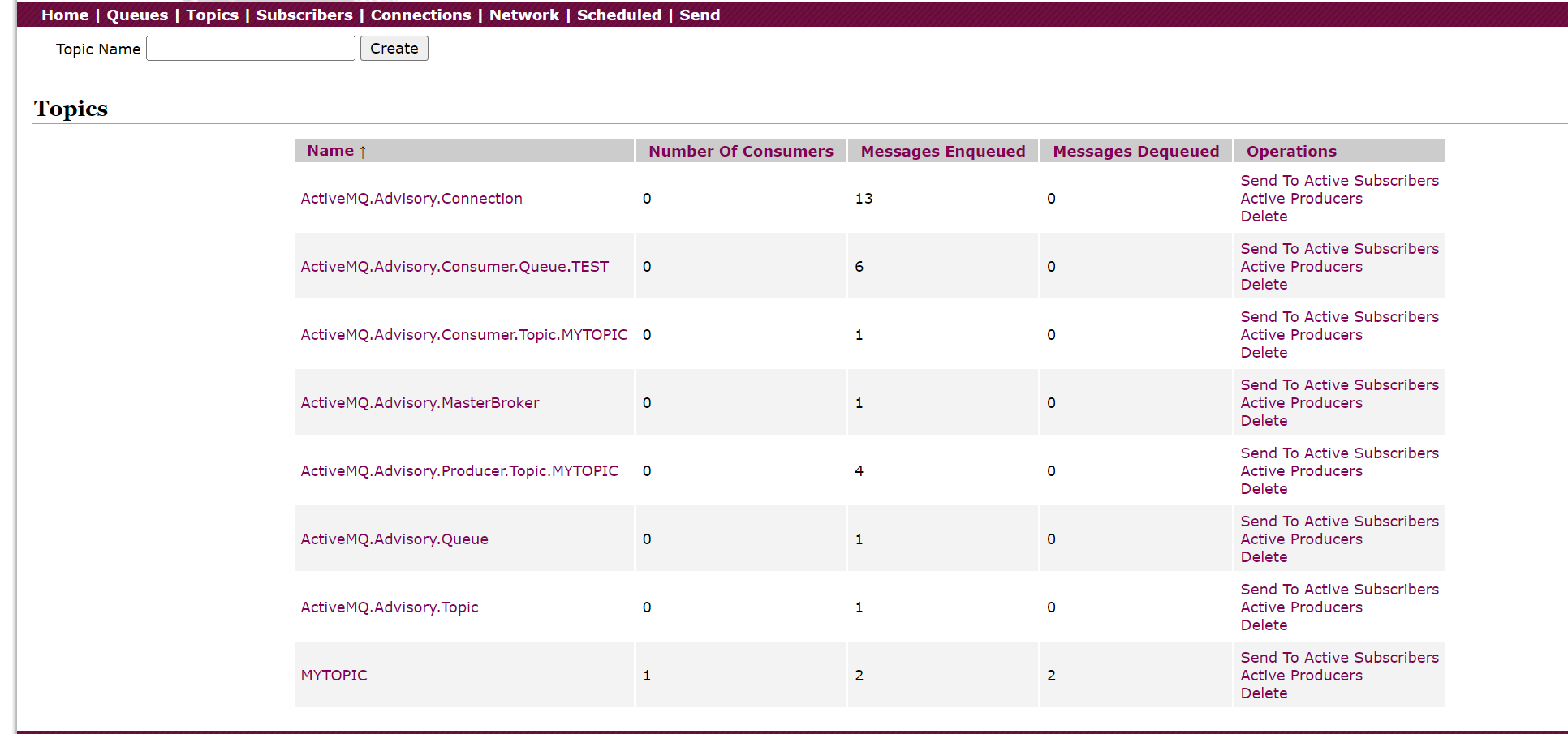
然后我们打开http://127.0.0.1:8161/admin/topics.jsp
最后一行的MYTOPIC就是我们创建的:

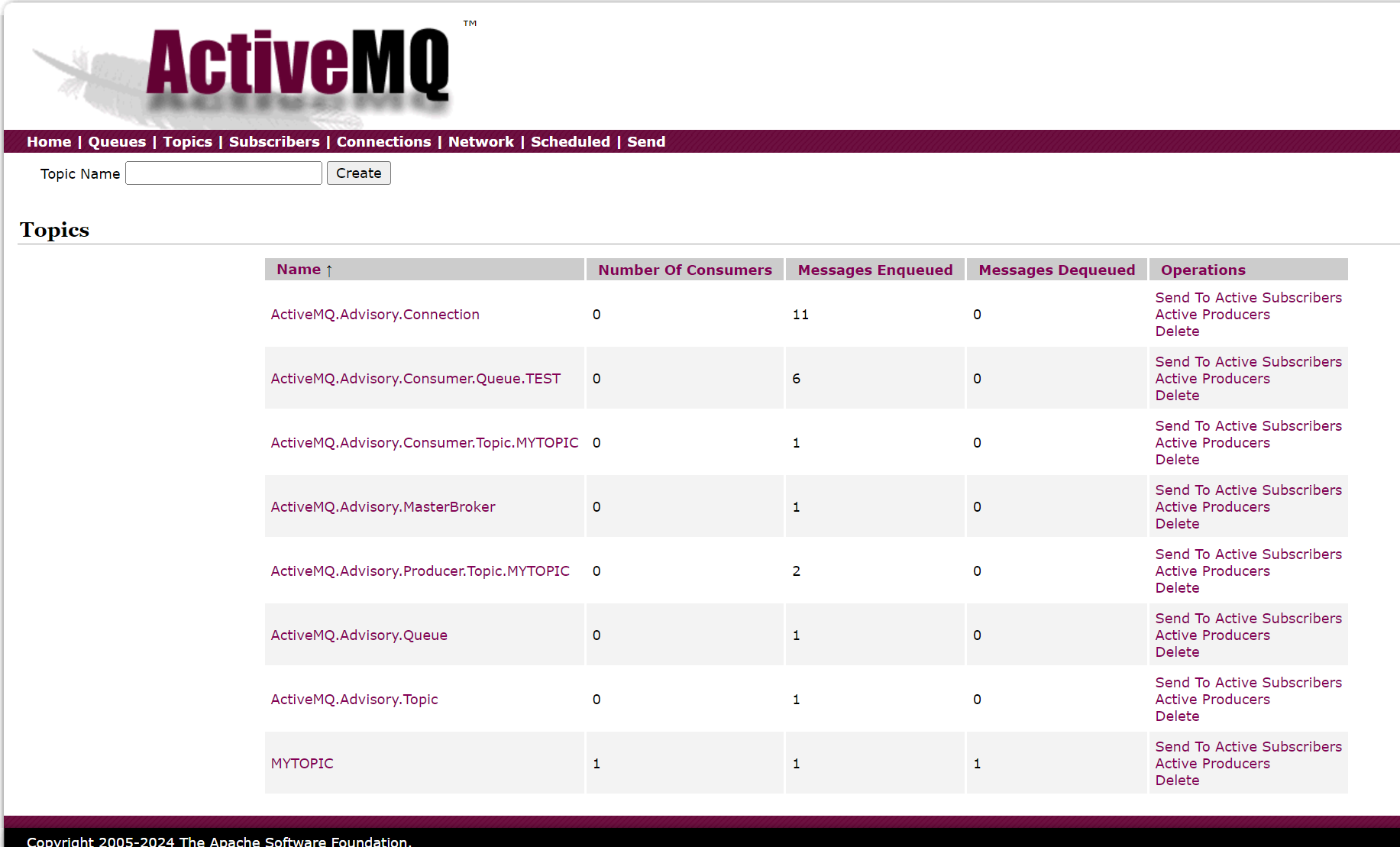
我们再发一条:
然后异步接收器也收到了:
然后下面这个最后一行MYTOPIC又加了1
参考链接
分布式计算实验4 随机信号分析系统_import tech.tablesaw.plotly.plot; import tech.tabl-CSDN博客
西电计科分布式第四次作业设计说明_西电分布式计算作业-CSDN博客
董放/基于ActiveMq消息队列实现分布式随机信号分析系统 - 码云 - 开源中国 (gitee.com)
一文详解设备ID的那些事儿-腾讯云开发者社区-腾讯云 (tencent.com)
Device ID(设备标识符),设备ID有什么用? - 知乎 (zhihu.com)
相关知识补充
MOM (Message-Oriented Middleware) 是一种软件或硬件基础设施,支持应用程序的数据交换和通信。通过MOM,应用程序可以通过异步消息交换数据,而无需进行直接的连接或交互。MOM 的核心优势在于它提供了一个稳定、可靠且通常是跨平台的消息传递系统,允许数据在分布式系统中安全流动。
基本概念
- 消息:在MOM中,消息是数据交换的基本单位。消息可以包括纯文本、编码的文件或其他数据。
- 消息队列:消息队列是临时保存消息的容器,直到它们被发送到最终目的地。队列帮助管理大量产生的消息,并确保它们按照发送顺序到达。
- 生产者(Producer):生产者是创建并发送消息到消息队列中的应用程序或进程。
- 消费者(Consumer):消费者是从消息队列中接收和处理消息的应用程序或进程。
常见模式
- 点对点(Point-to-Point):在这种模式下,消息被发送到特定的队列,每个消息只有一个消费者。生产者和消费者之间没有时间依赖性,消费者可以在任何时间处理消息。
- 发布/订阅(Pub/Sub):在发布/订阅模型中,消息发送到一个主题,而不是队列。任何订阅了该主题的消费者都可以接收消息。这适用于广播消息给多个接收者的情况。
主要优势
- 解耦应用组件:生产者和消费者不需要知道对方的存在,可以独立开发和扩展。
- 异步通信:生产者无需等待消费者的响应即可继续处理其他任务,提高了系统的效率和吞吐量。
- 弹性和容错性:MOM可以处理和缓冲突发的消息流量,确保在消费者或网络出现问题时消息不会丢失。
实现技术
- Apache ActiveMQ:是一个开源的、多协议的、基于Java的消息代理,广泛用于企业应用。
- RabbitMQ:基于Erlang开发,支持多种消息协议,非常适合高吞吐量的场景。
- Apache Kafka:初衷是处理更大规模的数据流,适用于需要大量数据处理和实时性的应用。
应用场景
- 金融服务:在交易系统中处理和传输大量交易指令。
- 电子商务:用于处理订单、库存更新和用户通知。
- 物联网(IoT):在设备间传输数据,支持远程监控和管理。
MOM的这些特性使其成为构建现代、高效和可靠分布式系统的关键技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号