201521123071 《JAVA程序设计》第七周学习总结
第7周-集合
1. 本周学习总结
以你喜欢的方式(思维导图或其他)归纳总结集合相关内容。
1.1 Iterator<E> iterator(); //iterator()返回一个实现了Iterator接口的对象,可用该Iterator(迭代器)依次访问集合中的元素
For each循环遍历:(for(String element : C) do sth;)。可以与任何实现了Iterator接口的对象一起工作;任何集合都可使用。
1.2 Set中的对象:不按特定方式排序,无重复对象,最多有一个null元素
HashSet:后台使用HashMap实现,加入的类需复写equals和hashCode
TreeSet:内部使用红黑树实现,为有序集合,支持两种排序方式:Comparable和Comparator
1.3 Queue队列:有方法:
offer();//队列后端加入返回true or false
poll();//取出队头元素相当于出队,若无返回null
peek();//查看队头元素不出队,如没有返回null
1.4 Map:每一个元素都包括一对键对象和值对象,键对象不允许重复,且要覆写equals和hashCode方法
其中有三个视图:
Set<k> keySet();//键集
Collection<k> values();//值集合(不是集)
Set<Map.Entry<K, V>> entrySet();//键/值对集
用法:put();//向集合中加入元素
get();//检索与键对象对应的值对象
2. 书面作业 ArrayList代码分析
1.1 解释ArrayList的contains源代码
答:解释如下:
public boolean contains(Object o) {
return indexOf(o) >= 0;
} //判断动态数组中是否存在元素“o”
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i] == null)
return i;
} //返回第一次当“o == null”时元素的位置
else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
} //返回数组中第一次与“o”一致的元素的位置
return -1; //若数组中没有与“o”相同的元素,则...
}
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size - 1; i >= 0; i--)
if (elementData[i] == null)
return i;
} //返回最后一次当“o == null”时元素的位置
else {
for (int i = size - 1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}//返回数组中最后一次与“o”一致的元素的位置
return -1; //若数组中没有与“o”相同的元素,则返回-1
}
1.2 解释E remove(int index)源代码
答:解释如下:
/**
* 删除指定索引位置index下的元素,返回被删除的元素
*/
public E remove(int index) {
RangeCheck(index); //检查索引范围,具体代码分析见下题
E oldValue = (E) elementData[index];//被删除的元素存到oldValue中
fastRemove(index);
return oldValue;
}
/*
* 删除单个位置的元素,是ArrayList的私有方法
*/
private void fastRemove(int index) {
modCount++;//详解如下所示
int numMoved = size - index - 1;
if (numMoved > 0)//如果删除的不是最后一个元素时
System.arraycopy(elementData, index + 1, elementData, index,numMoved);//删除的元素到最后的元素整块前移
elementData[--size] = null; //将最后一个元素设为null,在下次垃圾收集的时候就会回收掉了
}
modCount:记录ArrayList结构性变化的次数,所谓结构性变化即add(),remove()等操作。在使用迭代器遍历的时候,它可以用来检查列表中的元素是否发生结构性变化(列表元素数量发生改变),主要在多线程环境下需要使用,防止一个线程正在迭代遍历,另一个线程修改了这个列表的结构。
PS:由于还没接触到异常和线程的内容,所以在百度上找了解释,总体上知道它的作用是避免出现异常。
1.3 结合1.1与1.2,回答ArrayList存储数据时需要考虑元素的类型吗?
不需要。因为ArrayList存储数据时可以将元素的类型转换为Object,所以往ArrayList里面添加不同类型的元素是不会出错的。但是当调用ArrayList方法的时候,要传递所有元素都可以正确转型的类型,或者是Object类型,不然的话就会抛出无法转型的异常。
1.4 分析add源代码,回答当内部数组容量不够时,怎么办?
答:使用ensureCapacity()方法扩容,add源代码中扩容部分,分析如下:
/**
* 当数组的容量不够存放新加入的元素时,则使用该方法扩容
*/
public void ensureCapacity(int minCapacity) {
modCount++;//上题有解释
int oldCapacity=elementData.length;//获取数组大小(即当前数组的容量)
if (minCapacity > oldCapacity) { //在数组满了,又有新元素加入的情况下,执行扩容操作
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3) / 2 + 1;//新容量为旧容量的1.5倍+1
if (newCapacity < minCapacity)//如果扩容后的新容量还是没有传入的所需的最小容量大或等于(主要发生在addAll(Collection<? extends E> c)中)
newCapacity = minCapacity; //将新容量设为最小容量
elementData = Arrays.copyOf(elementData, newCapacity); //复制新容量
}
}
1.5 分析private void rangeCheck(int index)源代码,为什么该方法应该声明为private而不声明为public?
答:分析如下:
/**
* 检查索引index是否超出size-1
*/
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException("Index:"+index+",Size:"+size);//抛出异常
}
这里对index进行了索引检查,是为了将异常内容写的详细一些并且将检查的内容缩小(index<0||index>=size,这里的size是指已存储元素的个数)。
由此可知,这是程序内部自动检查的方法,不能被外界篡改,所以应该使用private而不是public
2. HashSet原理
2.1 将元素加入HashSet(散列集)中,其存储位置如何确定?需要调用那些方法?
答:一不小心百度到了答案,理解了一遍之后整理如下:
在往HashSet存入元素的时候,它首先得调用hashCode方法得到元素对应的哈希码值,然后将哈希码值进行计算,算出元素在哈希表的位置。如果算出来的位置要是没有值,那么毫无疑问直接将元素添加到哈希表中。如果算出来的位置上有值,就调用equals方法比较已存在的值与要加入的元素的值,如果比较结果为真,那么元素相同,HashSet不允许元素重复,则不能添加。如果比较结果为假,那么就添加进哈希表(通过散列冲突的解决办法解决)。
2.2 选做:尝试分析HashSet源代码后,重新解释1.1
答:解释如下:
/**
* 当且仅当此set包含一个满足(o==null ? e==null : o.equals(e))的e元素时,返回true。
* 调用HashMap的containsKey返回映射是否包含对(key)的映射关系
* 再调用containsKey方法中的的getEntry返回是否存在(key)
* HashSet的所有元素就是通过HashMap的key来保存的
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean containsKey(Object key) {
return getEntry(key) != null;
} //如果此映射包含对于指定键(key)的映射关系,则返回true
final Entry<K,V> getEntry(Object key) { //通过key获取一个value
int hash = (key == null) ? 0 : hash(key.hashCode());//如果key为null,则hash为0,否则用hash函数预处理
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { //得到对应的hash值的桶,如果这个桶不是,就通过next获取下一个桶
Object k;
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}//如果hash值相等,并且key相等则证明这个桶里的东西是我们想要的
return null; //所有桶都找遍了,没找到想要的,所以返回null
}
3. ArrayListIntegerStack题集jmu-Java-05-集合之5-1 ArrayListIntegerStack
3.1 比较自己写的ArrayListIntegerStack与自己在题集jmu-Java-04-面向对象2-进阶-多态、接口与内部类中的题目5-3自定义接口ArrayIntegerStack,有什么不同?(不要出现大段代码)
5-1:
class ArrayListIntegerStack implements IntegerStack{
private List<Integer> list;
public ArrayListIntegerStack() {
list = new ArrayList<Integer>();
}
5-3:
class ArrayIntegerStack implements IntegerStack {
private Integer[] arr;
private int top=0;
public ArrayIntegerStack(int n) {
arr=new Integer[n];
}
由以上代码可以看出,这两个实验最大的区别在于他们使用的存储数据的方式。5-3的使用了普通数组,其存储空间有限,适合在已知数据长度时使用,5-1的使用了动态数组,它具有容量扩充性,在定义的时候不需要规定长度,可以在使用时随意伸缩数组长度,比较适合我们平时的使用需求。
3.2 简单描述接口的好处.
接口是一系列方法的声明与特征的集合,把方法的特征和方法的实现分割开来,因此,这些方法可以在不同的地方被不同的类实现,而这些实现可以具有不同的功能,使用起来很方便,省事。其次,接口弥补了类不能多继承的缺点,一个类可以实现多个接口,一个接口也可以在多个类上实现。
4. Stack and Queue
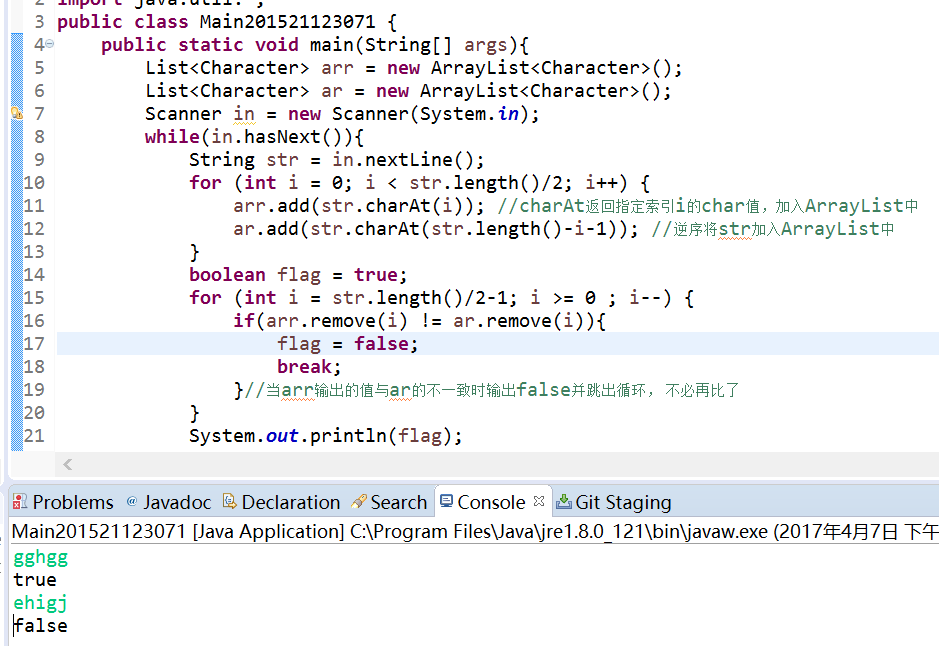
4.1 编写函数判断一个给定字符串是否是回文,一定要使用栈,但不能使用java的Stack类(具体原因自己搜索)。请粘贴你的代码,类名为Main你的学号。
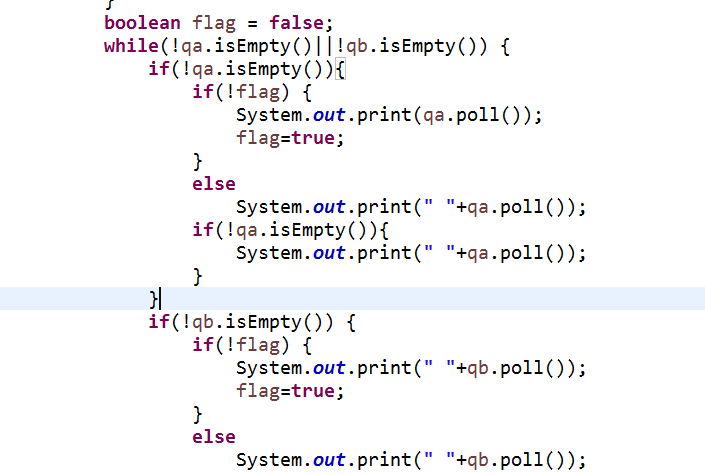
4.2 题集jmu-Java-05-集合之5-6,银行业务队列简单模拟。(不要出现大段代码)
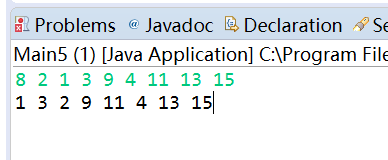
5. 统计文字中的单词数量并按单词的字母顺序排序后输出。题集jmu-Java-05-集合之5-2,统计文字中的单词数量并按单词的字母顺序排序后输出 (不要出现大段代码)
5.1 实验总结
部分代码如下:
Set<String> set = new TreeSet<String>();//这里使用了TreeSet作为容器收集数据,主要是为了后面的对象的排序
Iterator<String> i = set.iterator();
int sum = 0;//计数器,通过计数实现十个对象的输出
boolean flag = true;//状态标示值,通过状态的转变实现输出的继续与停止
while (i.hasNext()==flag ) {//这里的hasNext()是set接口 下的一个方法,当还有可读对象时返回true,我也就是利用了这一点来实现了输出的停止
if (sum == 9) {
flag = false;
}
sum += 1;
System.out.println(i.next());
}
在这个实验中,最主要的问题在于如何输出set中的部分值,虽然知道可以用Iterator解决,可是具体的使用也并不是很清晰。所以在百度的帮助下,我才想到了使用计数器sum以及状态标示值flag来实现部分输出,具体分析如上所示。
6. 选做:加分考察-统计文字中的单词数量并按出现次数排序,题集jmu-Java-05-集合之5-3,统计文字中的单词数量并按出现次数排序(不要出现大段代码)
6.1 伪代码
答:
while(in.hasNext()){
for (int i = 0; i < str.length; i++) {
if(tm.containsKey(s)){ //如果map中已经存在s的话
int num = tm.get(s);
tm.put(s, num+1);
}
else tm.put(s, 1);
//循环将str的值赋给s,然后加入到map,如果map已经有了s,则num+1;否则对应的值对象为1
}
if(st.equals("!!!!!")) { break;}
}
list.addAll(tm.keySet());
for (int i = 1; i < list.size(); i++) {
for (int j = 0; j < list.size()-i; j++) {
if(tm.get(j) > tm.get(j+1)){
list.set(j, list.get(j+1));
list.set(j+1, key);
} //通过冒泡进行值对象排序,每个键对象对应的map的值对象通过get()得到
}
}
6.2 实验总结
因为我只做出来了一半,所以我也只能总结一半了,有关于这个伪代码的解析在上面已经分析了。在这里主要想总结的是map的用法,真的要灵活使用,keySet();get(key);containsKey()等等,这些都是可以将value和key单独抽出来进行操作,以及和list等的转换。然后剩下的一半是value相同时对key降序排列,大概知道要怎么写这个代码,但是实际上写的时候又无从下手,我再琢磨琢磨。
7. 面向对象设计大作业-改进
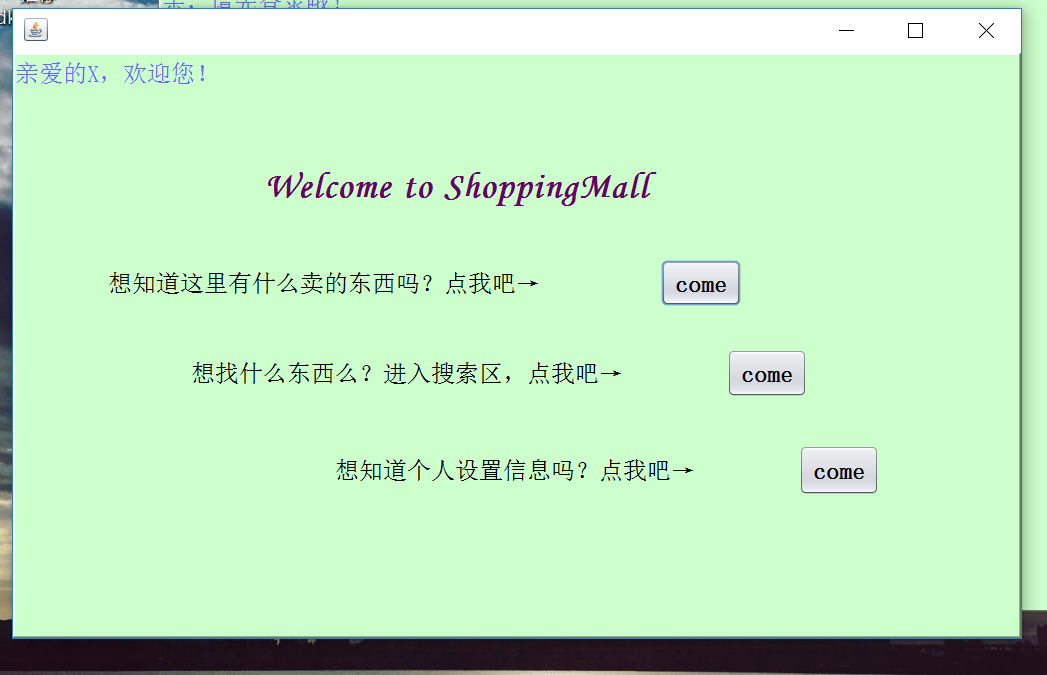
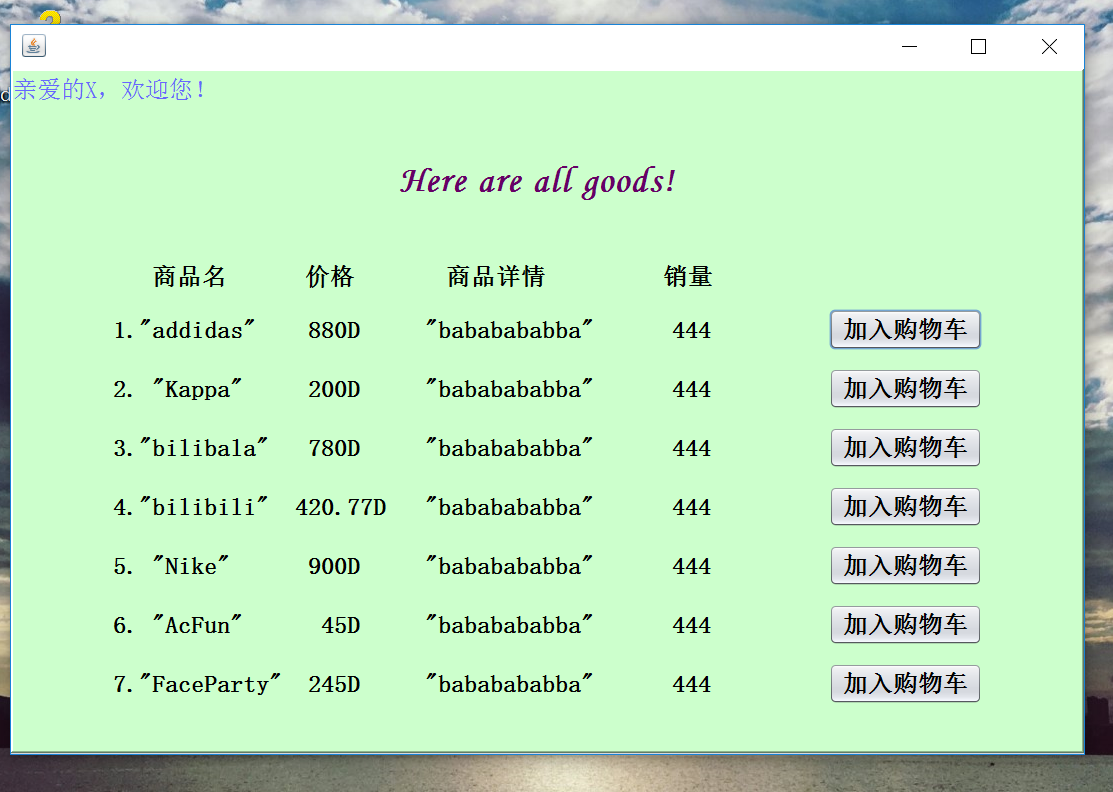
7.1 完善图形界面(说明与上次作业相比增加与修改了些什么)
7.2 使用集合类改进大作业
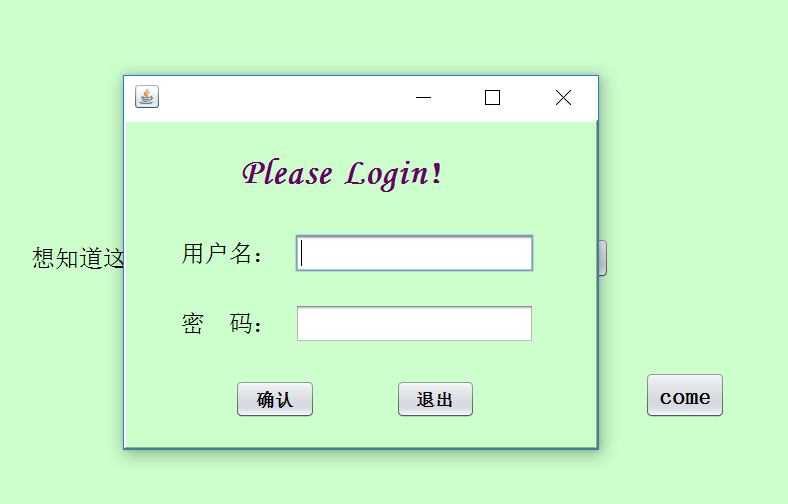
这次稍微完善了一下数据的显示,之前的那个太小了;还有就是美化了整体的界面;还有就是之前的一些设计不大合理,然后这次就改得更人性化一点。
截图如下:




3. 码云上代码提交记录及PTA实验总结
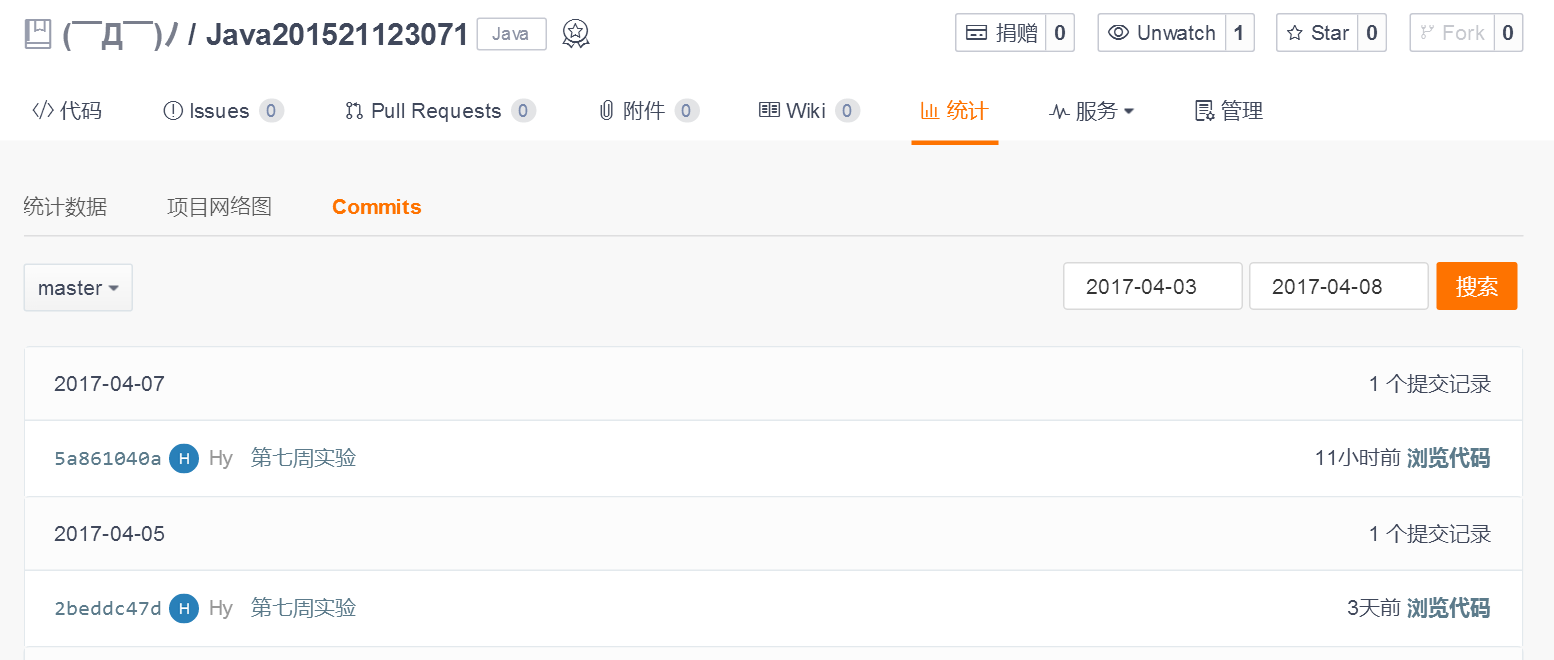
3.1. 码云代码提交记录
在码云的项目中,依次选择“统计-Commits历史-设置时间段”, 然后搜索并截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号