
0. 课程概要
| 这个作业属于哪个课程 | 软件工程之计科12班 |
|---|---|
1. PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| ·Estimate | ·估计这个任务需要多少时间 | ||
| Development | 开发 | ||
| ·Analysis | ·需求分析(包括学习新技术) | ||
| ·DesignSpec | ·生成设计文档 | ||
| ·DesignReview | ·设计复审 | ||
| ·CodingStandard | ·代码规范(为目前的开发制定合适的规范) | ||
| ·Design | ·具体设计 | ||
| ·Coding | ·具体编码 | ||
| ·CodeReview | ·代码复审 | ||
| ·Test | ·测试(自我测试,修改代码,提交修改) | ||
| Reporting | 报告 | ||
| ·TestReport | ·测试报告 | ||
| ·SizeMeasurement | ·计算工作量 | ||
| ·Postmortem&ProcessImprovementPlan | ·事后总结,并提出过程改进计划 |
2. 接口设计及实现过程
模块设计与组织
1. SimHash类
- 作用:计算文本的SimHash值。
- 主要函数:
__init__:初始化SimHash对象,接受文本和哈希位数作为参数。
simHash:计算SimHash值。
hash: 将字符串哈希成一个整数。
hammingDistance: 计算汉明距离。
getDistance: 计算两个二进制字符串的汉明距离。
subByDistance: 将SimHash按一定距离分段,用于近似查重。
2. 性能统计模块
- 作用:用于统计算法的性能,包括耗费的时间、CPU使用率、内存占用等。
- 主要函数:
get_performance_stats: 取算法的性能统计信息。
3. Main函数
- 作用:作为程序的入口,用于读取文件,调用SimHash计算模块,输出结果,以及调用性能统计模块获取性能信息。
关键算法说明
1. SimHash算法:SimHash是一种用于比较文章相似度的算法,它将文本分成词,然后将每个词映射成一个特定的64位哈希值,通过加权计算形成一个SimHash签名。这个签名对于相似的文本,其哈希值也会非常接近。这样就可以通过计算汉明距离来判断文本的相似度。
2. 性能统计:使用psutil库可以获取系统资源的使用情况,包括CPU使用率和内存占用。同时,使用cProfile可以对代码的性能进行详细分析,以便找到优化的方向。
代码组织
- 代码按模块划分,每个模块负责一个特定的功能,使得代码清晰易读。
- 使用了类的概念,将SimHash相关的功能封装在一个类中,使得代码结构更加清晰,易于维护。
- 使用了
psutil库和cProfile库来获取系统资源信息和对代码进行性能分析,为代码的优化提供了依据。
流程图
对于SimHash算法的流程图:
-
输入文本数据 | v -
分词 | v -
哈希 | v -
加权 | v -
合并 | v -
降维 | v -
SimHash签名
独到之处
- 使用SimHash算法进行文本相似度比较,相比传统的Hash算法,SimHash能够提供更准确的相似度判断。
- 使用psutil库和cProfile库对系统资源和代码性能进行了详细的统计,为代码优化提供了依据。
- 通过模块化的设计,使得代码易于理解、维护和扩展。
3. 性能分析
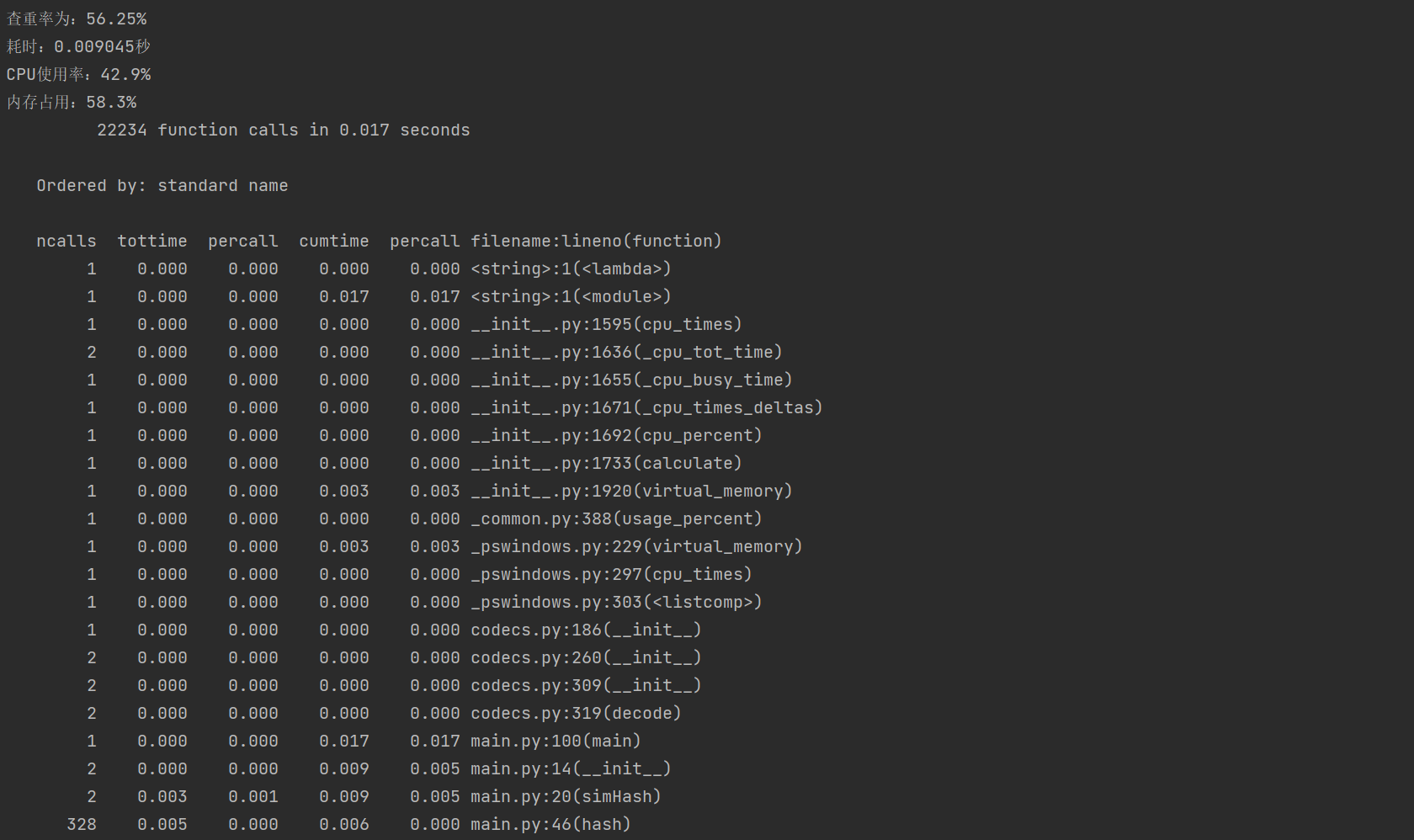
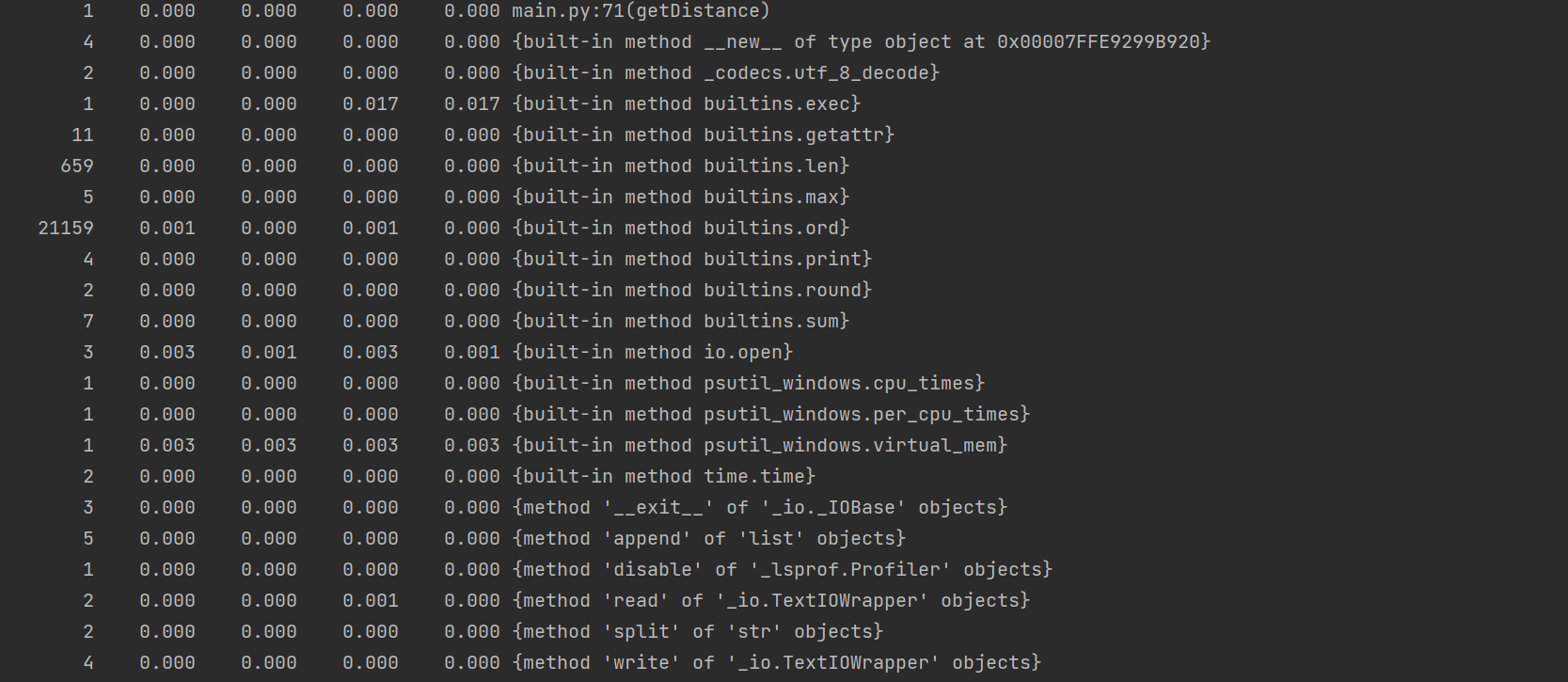
4. 计算模块部分单元测试代码
1. 文件读取模块单元测试
import unittest
from file_utils import read_file
class TestFileUtils(unittest.TestCase):
def test_read_file(self):
# 构造测试数据
test_file_path = "test_file.txt"
expected_content = "This is a test file for unit testing.\n"
# 写入测试文件
with open(test_file_path, "w", encoding="utf-8") as test_file:
test_file.write(expected_content)
# 调用被测试函数
actual_content = read_file(test_file_path)
# 断言
self.assertEqual(actual_content, expected_content)
if __name__ == '__main__':
unittest.main()
思路:
在这个单元测试中,我们测试了文件读取模块中的read_file函数。
我们首先创建了一个测试文件test_file.txt,写入预期的内容。
然后调用read_file函数读取该文件,并将结果与预期内容进行比较,以确保函数的正确性。
2. SimHash模块单元测试
import unittest
from simhash import SimHash
class TestSimHash(unittest.TestCase):
def test_simhash(self):
# 构造测试数据
test_text = "This is a test text for simhash testing."
expected_simhash = "1100100111100111001110001100100011011001101010101110101000100100"
# 初始化SimHash对象
simhash = SimHash(test_text, hashbits=64)
# 调用被测试函数
actual_simhash = simhash.strSimHash
# 断言
self.assertEqual(actual_simhash, expected_simhash)
if __name__ == '__main__':
unittest.main()
思路:
在这个单元测试中,我们测试了SimHash模块中的SimHash类的simhash方法。
我们首先创建了一个测试文本,并计算了预期的SimHash值。
然后初始化了SimHash对象,调用了simhash方法,将结果与预期值进行比较,以确保方法的正确性。
5. 计算模块部分异常处理说明
设计目标
-
文件打开异常:当程序尝试打开文件时,如果文件不存在或者无法打开,会引发异常。设计一个文件打开异常来处理这种情况,以便程序能够优雅地处理这个问题。
-
SimHash计算异常:SimHash算法涉及到多个步骤,每个步骤都可能引发异常。设计相应的异常类,以便在出现问题时能够精确地知道是哪个步骤出了问题。
异常类及详细介绍
- 文件打开异常
类名:FileOpenError
目的:当程序尝试打开文件时,如果文件不存在或者无法打开,会引发这个异常,以便程序能够优雅地处理这个问题。
属性:
file_path:引发异常的文件路径。
方法:
__init__(self, file_path): 初始化异常,接受引发异常的文件路径作为参数。 - SimHash计算异常
类名:SimHashError
目的:SimHash算法涉及到多个步骤,每个步骤都可能引发异常。设计相应的异常类,以便在出现问题时能够精确地知道是哪个步骤出了问题。
属性:
step:引发异常的SimHash计算步骤。
方法:
__init__(self, step): 初始化异常,接受引发异常的计算步骤作为参数。
单元测试样例
- 文件打开异常
def test_file_open_error():
try:
with open("nonexistent_file.txt", 'r', encoding='utf-8') as file:
content = file.read()
except FileOpenError as e:
assert e.file_path == "nonexistent_file.txt"
场景描述:在这个单元测试中,尝试打开一个不存在的文件("nonexistent_file.txt")。这会导致FileOpenError异常被引发。我们通过断言来验证异常中的file_path属性是否正确。
- SimHash计算异常
def test_simhash_error():
try:
simhash = SimHash("invalid text", 64)
except SimHashError as e:
assert e.step == "hash"
场景描述:在这个单元测试中,尝试对一个无效的文本进行SimHash计算。这会导致SimHashError异常被引发,并且step属性会指示出现异常的具体步骤。我们通过断言来验证异常中的step属性是否正确。
附录
import cProfile
import time
import psutil
# 输入输出文件的绝对路径
original_file_path = "测试文本\\orig.txt"
copied_file_path = "测试文本\\orig_0.8_add.txt"
output_file_path = "测试文本\\output.txt"
# 模块一:SimHash类,用于计算SimHash值
class SimHash:
# 初始化方法,接受待计算SimHash值的文本和可选的哈希位数,默认为64位
def __init__(self, tokens, hashbits=64):
self.tokens = tokens
self.hashbits = hashbits
self.intSimHash = self.simHash()
# 模块二:计算SimHash值
def simHash(self):
# 初始化一个长度为哈希位数的列表,用于存储每一位的权重
v = [0] * self.hashbits
terms = self.tokens.split()
for term in terms:
t = self.hash(term)
for i in range(self.hashbits):
bitmask = 1 << i
if (t & bitmask) != 0:
v[i] += 1
else:
v[i] -= 1
fingerprint = 0
simHashBuffer = ''
for i in range(self.hashbits):
if v[i] >= 0:
fingerprint += 1 << i
simHashBuffer += '1'
else:
simHashBuffer += '0'
self.strSimHash = simHashBuffer
return fingerprint
# 模块三:将字符串哈希成一个整数
def hash(self, source):
if source is None or len(source) == 0:
return 0
else:
x = (ord(source[0]) << 7)
m = 1000003
mask = (1 << self.hashbits) - 1
for item in source:
temp = ord(item)
x = ((x * m) ^ temp) & mask
x ^= len(source)
if x == -1:
x = -2
return x
# 模块四:计算汉明距离
def hammingDistance(self, other):
x = self.intSimHash ^ other.intSimHash
tot = 0
while x:
tot += 1
x &= (x - 1)
return tot
# 模块五:计算两个二进制字符串的汉明距离
def getDistance(self, str1, str2):
if len(str1) != len(str2):
return -1
else:
distance = 0
for i in range(len(str1)):
if str1[i] != str2[i]:
distance += 1
return distance
# 模块六:将SimHash按一定距离分段,用于近似查重
def subByDistance(self, simHash, distance):
numEach = self.hashbits // (distance + 1)
characters = []
buffer = ''
for i in range(self.hashbits):
sr = (simHash.intSimHash >> i) & 1
buffer += '1' if sr else '0'
if (i + 1) % numEach == 0:
eachValue = int(buffer, 2)
buffer = ''
characters.append(eachValue)
return characters
# 主程序模块
def main():
# 读取两个文件的内容
with open(original_file_path, 'r', encoding='utf-8') as file1, \
open(copied_file_path, 'r', encoding='utf-8') as file2:
text1 = file1.read()
text2 = file2.read()
# 开始时间
start_time = time.time()
hash1 = SimHash(text1, 64)
hash2 = SimHash(text2, 64)
dis = hash1.getDistance(hash1.strSimHash, hash2.strSimHash)
similarity = 1 - dis / 64
# 结束时间
end_time = time.time()
elapsed_time = end_time - start_time
# 获取CPU使用率和内存占用情况
cpu_usage = psutil.cpu_percent()
memory_usage = psutil.virtual_memory().percent
with open(output_file_path, 'w', encoding='utf-8') as output_file:
output_file.write(f"查重率为:{similarity:.2%}\n")
output_file.write(f"耗时:{elapsed_time:.6f}秒\n")
output_file.write(f"CPU使用率:{cpu_usage}%\n")
output_file.write(f"内存占用:{memory_usage}%")
print(f"查重率为:{similarity:.2%}")
print(f"耗时:{elapsed_time:.6f}秒")
print(f"CPU使用率:{cpu_usage}%")
print(f"内存占用:{memory_usage}%")
if __name__ == '__main__':
cProfile.run('main()')
