从网络架构方面简析循环神经网络RNN
一、前言
1.1 诞生原因
在普通的前馈神经网络(如多层感知机MLP,卷积神经网络CNN)中,每次的输入都是独立的,即网络的输出依赖且仅依赖于当前输入,与过去一段时间内网络的输出无关。但是在现实生活中,许多系统的输出不仅依赖于当前输入,还与过去一段时间内系统的输出有关,即需要网络保留一定的记忆功能,这就给前馈神经网络提出了巨大的挑战。除此之外,前馈神经网络难以处理时序数据,比如视频、语音等,因为时序数据的序列长度一般是不固定的,而前馈神经网络要求输入、输出的维度都是固定的,不能任意改变。出于这两方面的需求,循环神经网络RNN应运而生。
1.2 简介
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元既可以如同前馈神经网络中神经元那般从其他神经元那里接受信息,也可以接收自身以前的信息。且和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构。
1.3 与前馈神经网络的差异
就功能层面和学习性质而言,循环神经网络也有异于前馈神经网络。前馈神经网络多用于回归(Regression)和分类(Classification),属于监督学习(Supervised learning);而循环神经网络多用于回归(Regression)和生成(Generation),属于无监督学习(Unsupervised learning)。
二、网络架构
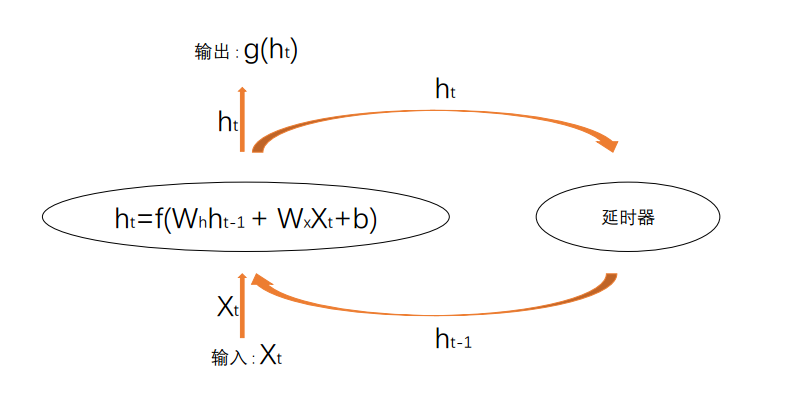
上图所示为RNN的一个神经元模型。给定一个序列长度为T的输入序列![]() ,在t时刻将该序列中的第t个元素xt送进网络,网络会结合本次输入xt及上一次的 “ 记忆 ” ht-1,通过一个非线性激活函数f()(该函数通常为tanh或relu),产生一个中间值ht(学名为隐状态,Hidden States),该值即为本次要保留的记忆。本次网络的输出为ht的线形变换,即g(ht),其中g()为简单的线性函数。
,在t时刻将该序列中的第t个元素xt送进网络,网络会结合本次输入xt及上一次的 “ 记忆 ” ht-1,通过一个非线性激活函数f()(该函数通常为tanh或relu),产生一个中间值ht(学名为隐状态,Hidden States),该值即为本次要保留的记忆。本次网络的输出为ht的线形变换,即g(ht),其中g()为简单的线性函数。
由于循环神经网络具有时序性,因此其网络架构可以从空间和时间两方面进行了解。
为方便理解,特以此情景举例:假设目前正在训练一个RNN,用于生成视频。训练用的train_data为1000段等长度的视频,划分的batch_size为10,即每次送给网络10段视频。假设每段视频都有50帧,每帧的分辨率为2X2。在此训练过程中,不需要外界给label,将某帧图片input进RNN时,下一帧图片即为label。
2.1 空间角度
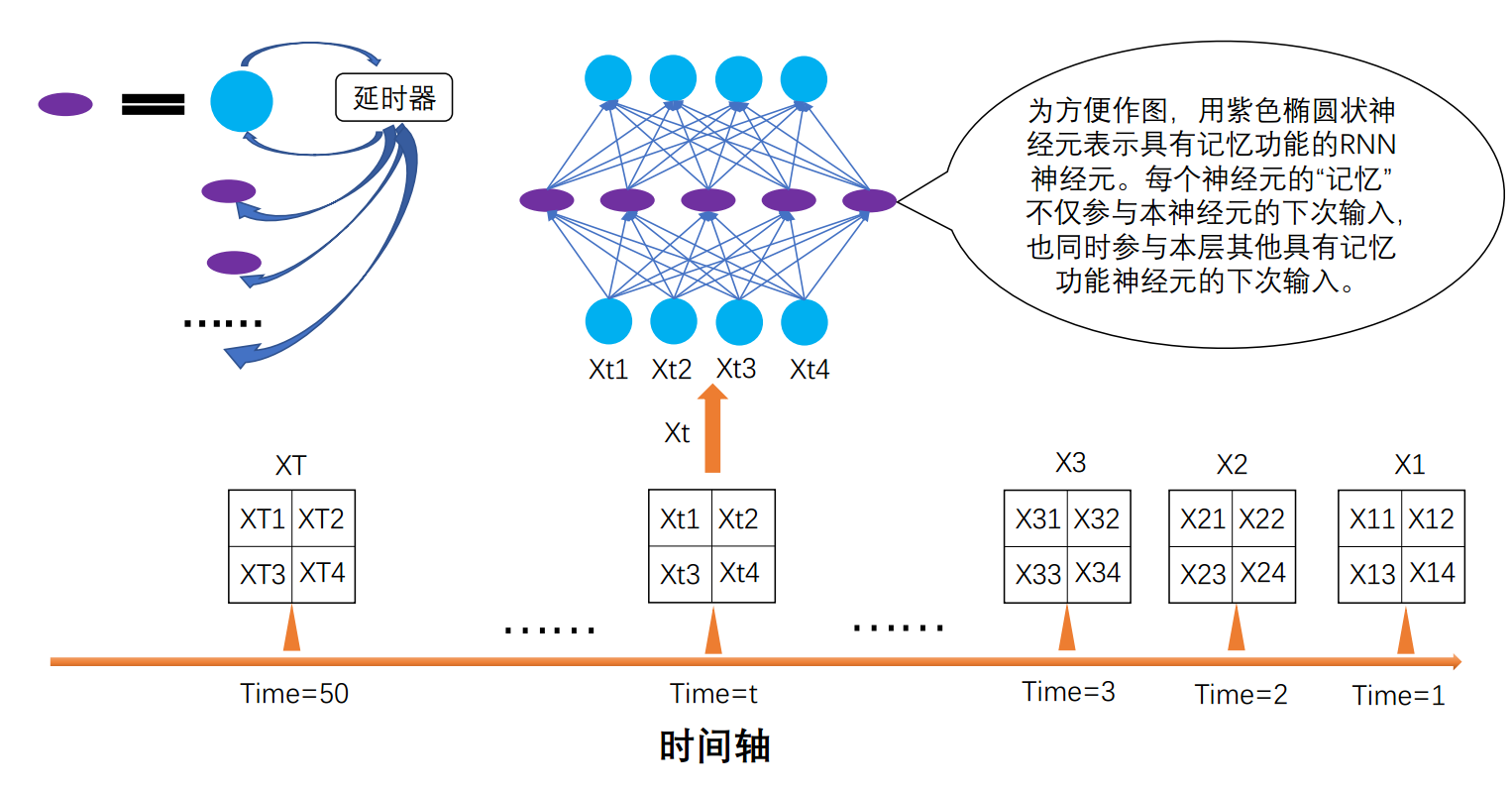
在本例中,一个序列长度为T的输入序列即一段50帧视频,其中的x1,x2,x3...x50分别对应着第一帧图片、第二帧图片、第三帧图片......到第五十帧图片。随着时间的推移,依次将每帧图片送进网络,在每个时刻,只送进一帧图片,同时生成一帧图片。该网络架构如下图所示。就如普通的前馈神经网络一般,除了输入输出层的维度固定外,隐藏层的维度及层数都是可以自主设计的。这里假设只有一个隐藏层,该层有5个神经元。需要注意的是,每个具有记忆功能的神经元中所存储的隐状态h,不仅参与本神经元的下次输入,还同时参与本层其他具有记忆功能神经元的下次输入。
2.2 时间角度
从空间角度观察整个网络,可将网络视为1个4X5X4的循环神经网络RNN,其中隐藏层的5个神经元是具有记忆功能的;从时间角度展开整个网络,可将网络视为50个4X5X4的多层感知机MLP,每个MLP隐层神经元不仅向该MLP的下一层输出,同时还向下一个MLP中与之层数对应的所有神经元输出(下图为求清晰表示,将其化简为一对一,但实质上是一对多),该输出即为隐状态h。由于隐状态需要在MLP之间从前向后传递,因此这50个MLP只能依次运算,不能并行运算。

循环神经网络独特的神经元结构赋予其记忆功能,但有得有失,该结构也造成其在处理时序数据时不能进行并行运算。目前推动算法进步的一大助力就是算力,而RNN却无法充分利用算力,这也是一部分人不太看好其前景的原因。
三、pytorch demo 实现
对一段正弦函数进行离散采样作为输入,利用RNN生成滞后的正弦函数采样值。实现环境:Colab。
引入必要头文件。
1 import torch.nn as nn 2 import torch 3 import numpy as np 4 import matplotlib.pyplot as plt 5 %matplotlib inline
采样获取input及label,并可视化。
1 # 制定画布大小 2 plt.figure(figsize=(8, 5)) 3 4 # 每个batch中数据个数 5 num = 20 6 7 # 生成数据 8 time_steps = np.linspace(0, np.pi, num+1) 9 data = np.sin(time_steps) 10 data = data.reshape((num+1, 1)) 11 12 x = data[0:num, :] # 除了最后一个数据外的所有其他数据 13 y = data[1:num+1, :] # 除了第一个数据外的所有其他数据 14 15 # 可视化数据 16 plt.plot(time_steps[1:num+1], x, 'r.', label='input_x') 17 plt.plot(time_steps[1:num+1], y, 'b.', label='output_y') 18 19 plt.legend(loc='best') 20 plt.show()

通过torch.nn.RNN及torch.nn.fc自定义网络模型。
1 # 自定义网络 2 class myRNN(nn.Module): 3 def __init__(self, input_size, output_size, hidden_dim, n_layers): 4 super(myRNN, self).__init__() 5 self.hidden_dim = hidden_dim # 隐藏层节点个数 6 self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True) # rnn层 7 self.fc = nn.Linear(hidden_dim, output_size) # 全连接层 8 9 def forward(self, x, hidden): 10 batch_size = x.shape[0] 11 # 生成预测值和隐状态,预测值传向下一层,隐状态作为记忆参与下一次输入 12 r_out, hidden = self.rnn(x, hidden) 13 r_out = r_out.view(-1, self.hidden_dim) 14 output = self.fc(r_out) 15 16 return output, hidden
实例化模型,并指定超参数、损失函数和优化器。
1 # 指定超参数 2 input_size = 1 3 output_size = 1 4 hidden_dim = 32 5 n_layers = 1 6 7 # 实例化模型 8 rnn = myRNN(input_size, output_size, hidden_dim, n_layers) 9 10 # 指定损失函数和优化器,学习率设定为0.01 11 loss = nn.MSELoss() 12 optimizer = torch.optim.Adam(rnn.parameters(), lr=0.01)
定义训练并打印输出的函数。
1 def train(rnn, n_steps, print_every): 2 3 # 记忆初始化 4 hidden = None 5 loss_list = [] 6 for batch_i,step in enumerate(range(n_steps)): 7 optimizer.zero_grad() # 梯度清零 8 # 生成训练数据 9 time_steps = np.linspace(step*np.pi, (step+1)*np.pi, num+1) 10 data = np.sin(time_steps) 11 data = data.reshape((num+1, 1)) 12 13 x = data[0:num, :] # 除了最后一个数据外的所有其他数据 14 y = data[1:num+1, :] # 除了第一个数据外的所有其他数据 15 16 x_tensor = torch.from_numpy(x).unsqueeze(0).type('torch.FloatTensor') 17 y_tensor = torch.from_numpy(y).type('torch.FloatTensor') 18 19 prediction, hidden = rnn(x_tensor, hidden) # 生成预测值和隐状态 20 hidden = hidden.data 21 loss_rate = loss(prediction, y_tensor) # 计算损失 22 loss_rate.backward() # 误差反向传播 23 optimizer.step() # 梯度更新 24 loss_list.append(loss_rate) 25 26 27 if batch_i%print_every == 0: 28 plt.plot(time_steps[1:num+1], x, 'r.', label='input') 29 plt.plot(time_steps[1:num+1], prediction.data.numpy().flatten(), 'b.', label='predicte') 30 plt.show() 31 32 x = np.linspace(0, n_steps, n_steps) 33 plt.plot(x, loss_list, color='blue', linewidth=1.0, linestyle='-', label='loss') 34 plt.legend(loc='upper right') 35 plt.show() 36 37 return rnn
训练模型并打印输出。
1 n_steps = 100 2 print_every = 25 3 trained_rnn = train(rnn, n_steps, print_every)
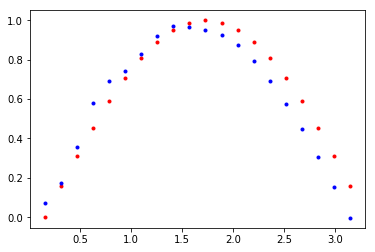
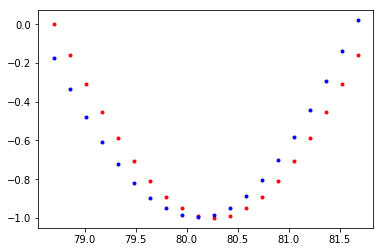
从左到右、自上而下,分别是训练25、50、75和100次后的模型效果。
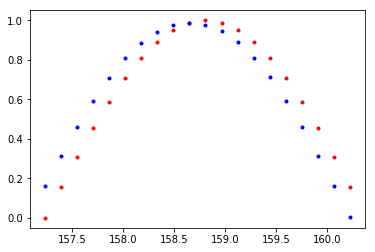

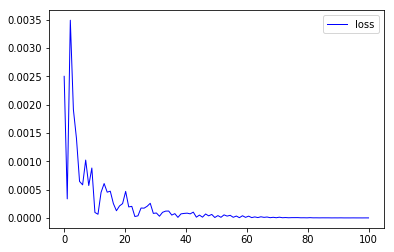
参考资料:
邱锡鹏老师《神经网络与深度学习》: https://nndl.github.io/
优达学城pytorch学习课程: https://github.com/udacity/deep-learning-v2-pytorch
慕课手记——RNN架构详解: http://www.imooc.com/article/details/id/31105
pytorch官方手册: https://pytorch.org/docs/stable/nn.html#recurrent-layers
博客主页:https://www.cnblogs.com/HL-space/
欢迎转载,转载请注明出处。
出错之处,敬请交流、雅正!
创作不易,您的 " 推荐 " 和 " 关注 " ,是给我最大的鼓励!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号